
【Claude Haiku 4.5】圧倒的スピード!最新Haiku系モデルの概要・強み・使い方を徹底解説

- Claude 4.5シリーズの小型モデルという位置づけ
- 低遅延タスクへの特化という考えで開発されており、リアルタイム性が重要なユースケースに最適化
- Claude Sonnet 4と同等レベルのコーディング能力を示しつつ、利用コストは1/3、応答速度は2倍以上
2025年10月16日、Anthropicから新たな大規模言語モデル「Claude Haiku 4.5」が公開されました!
このモデルは、Claude Sonnet 4.5の性能をわずか3分の1のコストで2倍以上の速度で提供できると言われており、開発者コミュニティで大きな注目を集めています。
Claude Haiku 4.5はClaude 4.5シリーズの小型モデルという位置づけで、Claude Sonnet 4.5の性能に迫る性能と、低遅延・高速応答性を兼ね備えています。
リアルタイム対話やコーディング支援など、従来の大型モデル以上に様々な用途に適用しやすいAIとなっています。
本記事では、Claude Haiku 4.5の概要や仕組み、特徴、実際の検証結果まで幅広く解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Claude Haiku 4.5の概要と背景

Claude Haiku 4.5は、Anthropic社が2025年10月16日に発表したClaude 4.5シリーズの最新モデルです。
Claudeシリーズでは、従来からモデル規模や用途に応じて名称が分かれており、最上位の高性能モデルが「Opus」、汎用高性能モデルが「Sonnet」、軽量高速モデルが「Haiku」と名付けられています。
今回登場したHaiku 4.5は、その名の通り軽量で動作が速いHaiku系モデルの最新版で、同シリーズでは直前にリリースされたClaude Sonnet 4.5に次ぐ2番目のClaude 4.5モデルとなります。
モデル登場の背景
このモデルが登場した背景には、「高い知性」と「高速な応答」のトレードオフを解決するというニーズがあります。
大規模な最先端モデルは非常に高い性能を発揮しますが、計算資源を多く必要とし応答が遅くコストも高い傾向がありました。一方、小型モデルは応答は速い一方で、理解力や作業遂行能力が劣るという課題がありました。
Anthropicはこうした課題に対し、小型モデルでありながら最先端に迫る性能を実現することで、リアルタイム性が求められる対話型AIや大規模展開時の費用対効果を劇的に向上させることを目指しました。
この結果、Claude Haiku 4.5は「数カ月前には最先端だったClaude Sonnet 4の水準を、小型モデルで達成した」と公式発表でも言及されており、手軽に利用できるようになりました。
提供元

提供元のAnthropic社は、安全性と長大なコンテキスト処理で知られるAI企業です。
Claude 2以来、10万トークンクラスの長文コンテキスト処理や「憲法ベースのAI」による安全対策で注目されてきました。
Claude Haiku 4.5もその流れの中で、「低遅延タスクへの特化」という明確なコンセプトを持って開発されており、たとえばチャットボットや顧客対応エージェント、ペアプログラミングといったリアルタイム性が重要なユースケースに最適化されています。
また、コーディング支援でも高い性能を維持しており、AnthropicはClaude Haiku 4.5を「前世代の最先端モデルに匹敵するコーディング性能を備えた高速モデル」と位置付けています。
要するに、「賢さ」と「速さ」の両立を図った次世代型の軽量AIモデルがClaude Haiku 4.5だと言えます。
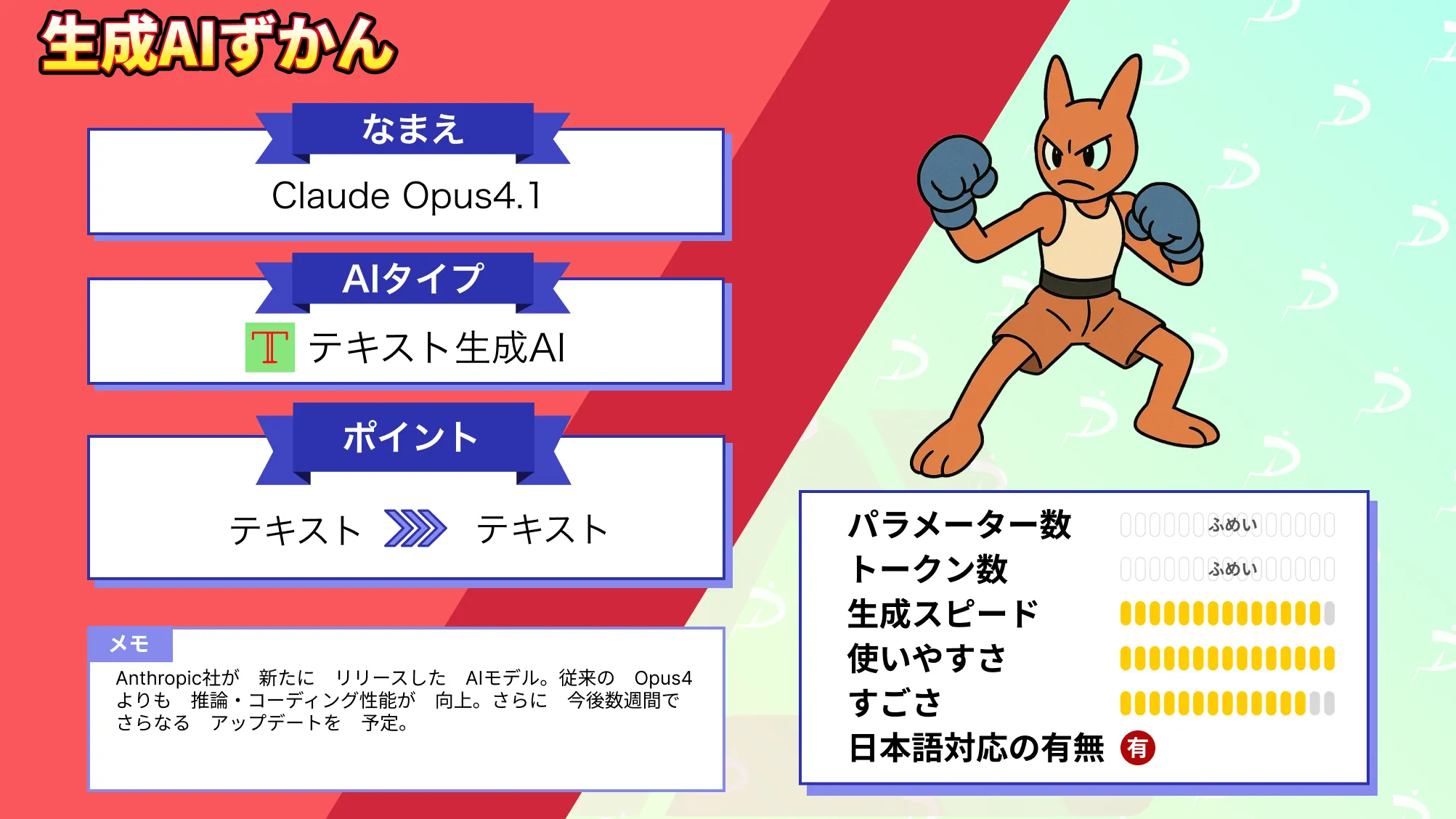
なお、Claude Opus 4.1について詳しく知りたい方は、以下の記事も参考にしてみてください。
Claude Haiku 4.5の仕組み
Claude Haiku 4.5の内部構成や動作原理は、基本的にはClaude Sonnet 4.5などと同じClaude 4.5アーキテクチャを踏襲していますが、軽量モデルとして最適化が施されています。
具体的には、モデルのパラメータ規模や推論アルゴリズムを調整することで計算効率を高め、出力トークン生成速度(OTPS)の大幅な向上を実現しています。結果的に、Sonnet 4に比べて2倍以上の速さで応答を返すことが可能になっています。
特徴的な仕組みとして、Claude Haiku 4.5は、Haiku系列のモデルで初めて「拡張思考(Extended Thinking)」に対応しました。
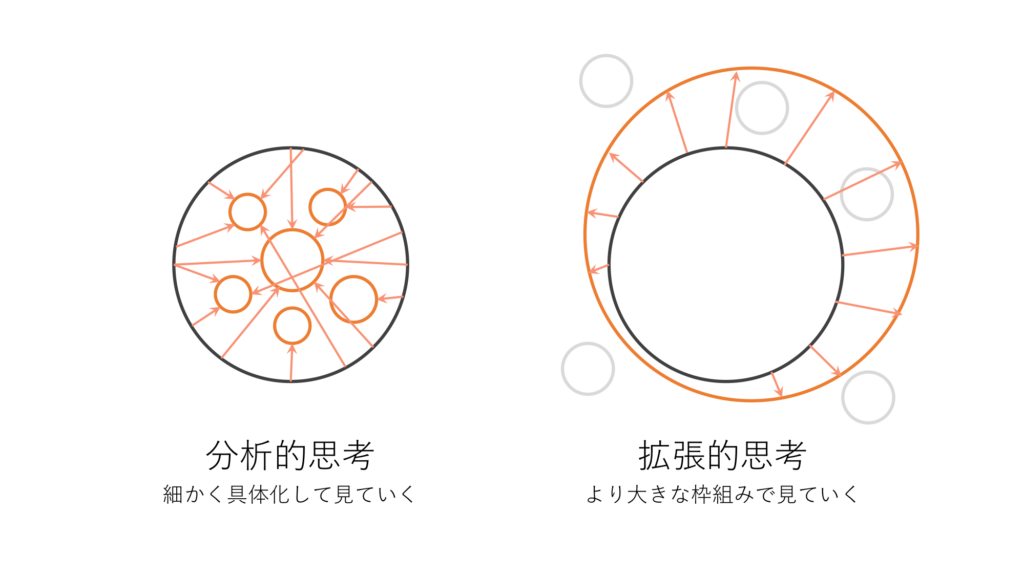
拡張思考とは、モデルが内部で段階的に推論(いわゆるChain-of-Thought)を行ったり、解答に至る過程を省略せず思考プロセスを保持したりする機能です。これによって、複雑な問題に対しても推論の筋道を見失わずに高精度な回答を導き出すことができます。
Claude Haiku 4.5ではこの拡張思考機能をAPIオプションで明示的に有効化でき、長い思考が必要なコーディングや論理問題でも大規模モデルに迫る解決能力を発揮します(※デフォルトではオフになっているので、必要な場合はAPIリクエストにパラメータを指定して有効化する必要があります)
また、コンテキスト認識もHaikuモデルとして初めて組み込まれました。
モデル自身が「自分があとどれだけコンテキストを保持できるか」を把握しながら対話やタスクを進める仕組みで、長いやり取りの途中でも残りのトークン予算を考慮しつつ回答のまとめ方を調整したり、途中で推論を打ち切ってしまうのを減らしたりする効果があります。
さらに、Claude Haiku 4.5は各種ツールの利用機能をフルサポートしています。
Claude 4世代のモデルが備える外部ツール連携(例えば bash コマンドの実行、コード実行、テキストエディタ、ウェブ検索やAPIコール等)はHaiku 4.5でもすべて利用可能で、軽量モデルでありながらパソコン操作やブラウザの自動操作までこなせる汎用エージェントとして機能します。
特にインターフェース操作系のタスクでは、Haiku 4.5は前世代のSonnet 4を上回る性能を発揮したとされ、例えばブラウザ拡張のClaude for Chromeに組み込んだ場合でも、動作が一段と速くなっているそうです。
構成上のもう1つのポイントはマルチエージェント協調を前提とした設計です。
Anthropicは今回、Haiku 4.5とより高性能なSonnet 4.5を組み合わせて協調動作させるシナリオを提唱しています。具体的には、まず大きな問題をSonnet 4.5が分割・プランニングし、その各サブタスクを複数のHaiku 4.5インスタンスが並行して実行する、というアプローチです。
Haiku 4.5の軽快さとコストの安さゆえに、このような並列実行によるスループット向上が可能になっています。
従来は一台の高性能モデルで順次処理していたような作業でも、複数のHaikuが同時に処理することで全体の処理時間を飛躍的に短縮できます。このような協調動作を支えるため、Haiku 4.5自身も並列処理時のツールコールの最適化や結果統合など、マルチエージェント環境下で能力を発揮できる調整がなされていると言えます。


Claude Haiku 4.5の強み
Claude Haiku 4.5の最大の特徴は、なんといってもコスト効率と応答速度を劇的に向上させながら、一世代前の最先端モデルに迫る知的性能を実現した点にあります。
Anthropicの発表によると、Haiku 4.5はClaude Sonnet 4と同等レベルのコーディング能力を示しつつ、その利用コストは1/3、応答速度は2倍以上とされています。
社内ベンチマークでは、ソフトウェアエンジニアリング分野のテスト「SWE-Bench Verified」においてHaiku 4.5は73.3%という高い正解率を記録し、これはほぼClaude Sonnet 4(72.7%)と近い値です。「Sonnetより強いHaikuとは?」と驚く方もいるかもしれません。
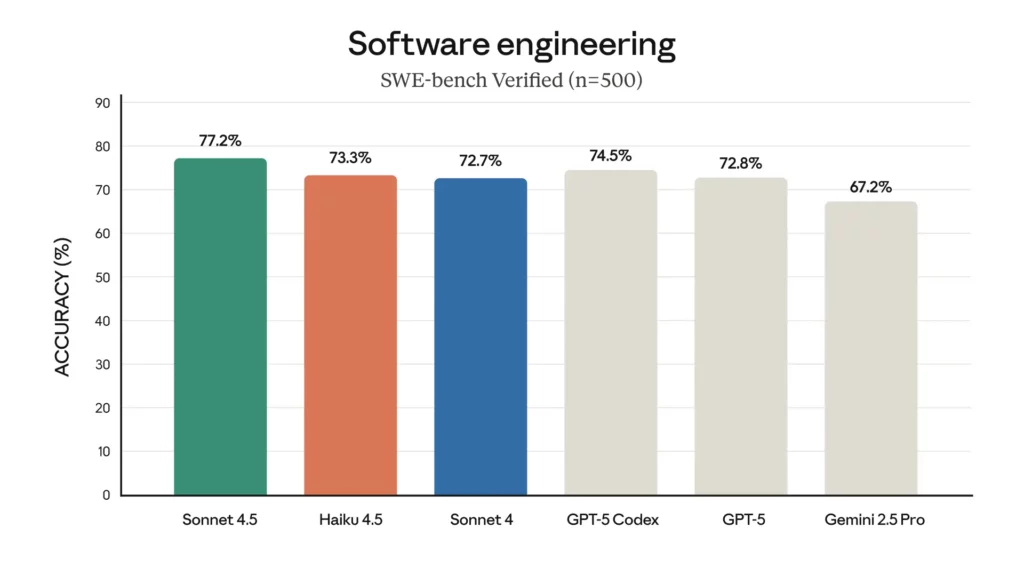
また、エージェントによるコマンドライン操作能力を測る「Terminal-Bench」でも41%と、最新のSonnet 4.5には及ばないもののSonnet 4や他社のGPT-5・Gemini 2.5 Proと同等のスコアを叩き出しています。
総合的に見れば、Haiku 4.5の知性は前世代トップモデルと同等クラスであり、まさに「小さな巨人」と言えるモデルです。
性能以外の観点では、「使いやすさ」と「スケーラビリティ」も大きな強みです。
Claude Haiku 4.5は、Claude 3.5 Haikuの後継として、より長いコンテキストと長大な出力に対応しました。最大で200,000トークンものコンテキスト(約500ページ分のテキストに相当)を保持でき、出力も最大64,000トークンまで一度に生成可能です。
これは、従来のHaiku 3.5の出力上限(8192トークン)が大幅に拡張されたもので、大量のテキストデータを一度に処理・生成する用途にも向いています。
例えば、長大なコードベースや研究論文の束を与えても、一度に読み込んで分析し、要約やコード変換を行うことが可能になります(もっとも膨大なコンテキスト全てを使うとその分コストと時間も増大するため、効率的な利用設計は必要です)。
スケーラビリティの面では、前述の並列実行が重要なキーワードです。
Haiku 4.5は軽量でコストも低いため、複数インスタンスを並行稼働させる「横にスケールする」運用に適しています。Anthropicが提案するように、Sonnet 4.5のような高性能モデルの代わりに、Haiku 4.5を複数投入してタスクを分担させれば、総合的な処理スピードを飛躍的に高められるイメージです。

このようなマルチエージェント構成は、オープンソースのAI開発プラットフォーム「Dify」のように複数モデルを組み合わせてワークフローを構築する手法でも目指されていた方向性ですが、Claude Haiku 4.5の場合は、Anthropic純正モデル群内でそれが完結できる点が魅力です。
つまり、高価な単一モデルに頼らなくとも、高速モデルを多数走らせることで高い性能を実現できるという設計思想が体現されています。このアプローチによって、例えば一つの大規模モデルが逐次処理していた作業を、Haiku 4.5のチームが同時処理することでリアルタイム性やスループットを大幅に向上できます。
操作性の面でも、Haiku 4.5はClaudeプラットフォームとの親和性が高く扱いやすいモデルです。
Claude.aiのウェブアプリやモバイルアプリ上で選択するだけで利用できるほか、API経由でもclaude-haiku-4-5というモデル名を指定するだけで呼び出せるドロップイン置き換えが可能になっています。
そのため、既存でClaude 3.5 HaikuやClaude 4 Sonnetを使っていたシステムであれば、少ない修正でHaiku 4.5へ移行でき、速度向上やコスト削減を体感できると思います。
拡張性という観点では、Claude 4.5世代で新たに導入されたメモリツールやコンテキスト編集APIなどの機能もHaiku 4.5で利用可能です。これによって、長期的な知識の蓄積やコンテキストウィンドウ管理といった高度な運用もサポートされ、単なる対話モデルにとどまらない柔軟なAIプラットフォームとして進化しています。
なお、Difyについて詳しく知りたい方は以下の記事も参考にしてみてください。

Claude Haiku 4.5の安全性と制約
AIモデルを実運用する際に無視できない安全性についても、Claude Haiku 4.5は従来モデルより改善が図られています。
Anthropicによる詳細な安全性評価によると、Haiku 4.5は有害な発話や望ましくない挙動の発生率が非常に低く、従来モデルのClaude Haiku 3.5より一層アラインメント(倫理や方針への従順度)が向上しています。
さらに自動評価では、Claude Sonnet 4.5やClaude Opus 4.1よりも全体的な不適切応答率が統計的に有意に低かったと報告されており、「現時点で当社で最も安全なモデル」であると発表されています。このように、安全性の面でも小型モデルだからと妥協せず、むしろ最新世代の中でトップクラスの安全度を達成している点は特筆すべき進歩だと思います。
Anthropicは、Claude Haiku 4.5に対してAI Safety Level 2 (ASL-2)という安全基準レベルを適用しています。

これは前世代のHaiku 3.5(ASL-1相当)やより高性能なSonnet 4.5/Opus 4.1(ASL-3)とは異なるレベルで、化学・生物・放射性物質・核兵器(CBRN)の製造方法など極めて危険な知識の生成リスクが限定的であることを示しています。
ASL-2に留められたことで、Haiku 4.5は利用に際して最上位モデルほど厳しい制限を課す必要がなく、より幅広いユーザに公開されています。実際、Claude Haiku 4.5は無料ユーザにも開放されており、安全性評価に裏打ちされた自信の現れと言えるでしょう。
もっとも、安全策が強化されたとはいえ完全にリスクが無くなったわけではありません。
Anthropicの安全テストでも、少数ではあるものの不適切な指示に対する脆弱性やハルシネーションなどの問題は確認されています。また、ASL-2とはいえ、違法行為や有害なコンテンツへの利用は禁止されており、Claude Haiku 4.5も利用規約に沿って安全な用途でのみ使う必要があります。
システムカードには透明性のための詳細なテスト結果が公開されていますが、このモデルを組み込む際に出力内容のレビューやフィルタリングといった基本的な対策を講じることが求められます。
制約事項としては、モデルサイズに起因する限界も多少あります。例えば、最先端のSonnet 4.5モデルではAPI経由で最大100万トークンという驚異的なコンテキストウィンドウを利用できるのに対し、Haiku 4.5のコンテキストは標準で20万トークン程度に限られます。
しかし、20万でも一般的なチャットボットや文書処理には十分すぎる長さであり、大半のユースケースでは問題にならないとは思います。
また、複雑な数学証明や創造的な文章生成などの高度に専門的な推論の正確性では、Haiku 4.5はあくまで「最先端級」であって「最先端そのもの」ではありません。
例えば、数学競技試験や多言語の難問では、より大きなモデルが上回るケースもあると思います。なので、絶対的な最高性能を求める局面では上位モデルが優位ということを認識して、用途に応じて使い分けることが重要です。


Claude Haiku 4.5の料金プラン
Claude Haiku 4.5の利用料金(API利用時)は、入力トークン100万あたり1ドル、出力トークン100万あたり5ドルに設定されています。この価格は、Claude Sonnet 4.5(入力100万あたり3ドル、出力100万あたり15ドル)のちょうど1/3にあたり、性能比を考えると極めてコスト効率が高い水準です。
| モデル | 入力トークン(100万) | 出力トークン(100万) |
|---|---|---|
| Claude Sonnet 4.5 | $3 | $15 |
| Claude Haiku 4.5 | $1 | $5 |
さらに嬉しいことに、Claude Haiku 4.5はAnthropicの無償プランでも利用可能です。
2025年10月時点で、Claude.aiのウェブ版やモバイルアプリ版においてHaiku 4.5モデルが標準搭載されており、サブスクリプション契約なしでも誰でもこの最新モデルと対話できます。無料枠では一定の利用制限(同時実行数や1日のトークン上限など)があるものの、まず試すことができるのは大きなメリットです。
Claude Haiku 4.5のライセンス
Claude Haiku 4.5を利用する際のライセンスには、Anthropicの利用規約と使用ポリシーが適用されます。
Anthropicは規約で「Claudeが生成した出力に関して弊社が有する権利は、利用規約遵守を条件にすべて利用者に譲渡する」と明記しており、基本的に生成物の権利は利用者に帰属します。
ただし、利用にあたってはポリシーで禁止されている行為もあり、特に「生成物を無加工のまま商用販売・配布する」「生成物を自作と偽る」などは許可されていません。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | 商用ライセンスに基づいて出力の利用が可能 |
| 改変 | ⭕️ | |
| 配布 | 🔺 | 生成物そのものをそのまま配布・販売することは原則禁止 |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
Claude Haiku 4.5の実装方法
Claude Haiku 4.5を実際に利用・実装する方法について、いくつかのアプローチがあります。
1. Claude.ai(公式アプリ)で利用する方法
最も簡単なのは、Anthropic公式のチャットアプリケーションである Claude.ai を使う方法です。ウェブブラウザまたはClaudeのスマートフォンアプリ(iOS/Android)にログインし、新しいチャットを開始する際にモデル選択で「Claude Haiku 4.5」を選ぶだけで利用できます。
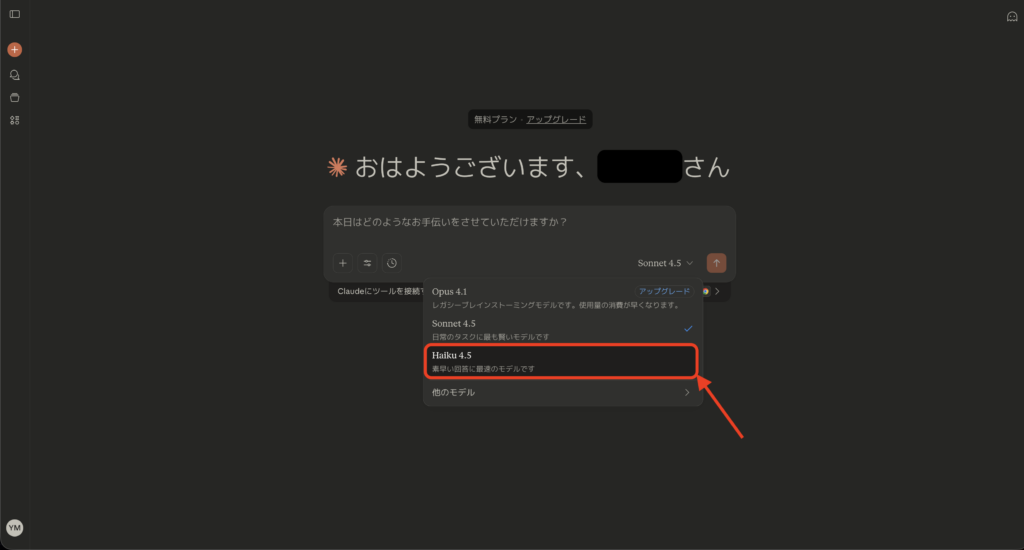
無料プランのユーザでもこのモデルを選択可能であり、特別な設定は不要です。チャットUI上では他のClaudeモデルと同様に、ユーザがメッセージを入力するとHaiku 4.5が応答を返してくれます。
内部的な動作はAnthropicのサーバ側で行われるため、ローカルPCの性能に依存せず手軽に試せます。
2. Claude APIで組み込む方法
自社のアプリケーションやサービスにClaude Haiku 4.5を組み込みたい場合は、Anthropicの提供するClaude APIを利用します。
まずAnthropicの開発者向けコンソールからAPIキーを取得し、API呼び出しができるようにします。
APIの使用方法はOpenAIのAPIに似ており、HTTP経由でプロンプト(ユーザからモデルへのメッセージ)を送り、それに対するモデルのコンプリート(補完)あるいはチャット応答を受け取る形式です。
具体的には、HTTP POSTリクエストのJSONボディでmodelフィールドに "claude-haiku-4-5" を指定し、messagesフィールドにユーザ発話やシステムプロンプトの配列を渡すことで、Haiku 4.5からの返答テキストを取得できます。
Anthropicは公式のPython SDKやJavaScript向けライブラリも提供しているため、それらを用いれば比較的少ないコードでAPI連携が可能です。
3. 他のクラウドプラットフォームから利用する方法
AnthropicはClaude Haiku 4.5を自社APIだけでなく、AWSやGCPといった主要クラウドのAIサービス経由でも提供しています。
具体的には、Amazon Bedrock上でエンドポイントanthropic.claude-haiku-4-5-20251001-v1:0として提供されており、BedrockのAPIから呼び出すことができます。また、Google Cloud Vertex AIでもモデルIDclaude-haiku-4-5@20251001として利用可能です。
これらはAnthropic APIと結果は同じですが、大規模なシステムでAWS/GCPに統合したい場合に有用です。
ちなみに、これらのプラットフォームではグローバルエンドポイントとリージョナルエンドポイントの2種類が用意されており、リージョナルの場合は、データが特定地域内で処理される代わりに料金が1割ほど割増となることが案内されています。そのため、ご自身のデータポリシーやレイテンシ要件に合わせて使い分けるのが適切です。
(補足)実装環境・前提条件
Claude Haiku 4.5を使う上で特別なハードウェアや環境構築は不要です。
全てAnthropic側のクラウドでモデルが動作するため、インターネットに接続できる環境とAPIを呼び出すためのプログラミング環境があれば十分です。PythonであればanthropicライブラリやHTTPクライアント、JavaScriptであればfetchAPIなどで簡単に利用できます。
注意点として、API利用時にはAPIキーの保管とリクエストの頻度制御があります。
無料枠では1分あたりのリクエスト数など制限が設けられているため、必要に応じて有料プランへのアップグレードやレート制御ロジックの実装を検討してください。また、大量のトークンを一度に投入する場合は時間もかかるため、非同期処理やストリーミング応答の活用も視野に入れると良いでしょう。
Claude Haiku 4.5の活用イメージ
Claude Haiku 4.5はその特徴から、様々な分野での活用が期待されるモデルです。以下に、代表的な活用イメージシーンをご紹介します。
① リアルタイム対話型AI(チャットボット・カスタマーサポート)
高速応答が求められるチャットボットやバーチャルアシスタントには、Haiku 4.5はうってつけです。ユーザからの問い合わせに対し瞬時に回答を生成できるため、ストレスのない対話体験を提供できます。
例えば、企業のカスタマーサポート窓口にAIチャットを導入する場合、応答遅延が長いとユーザ満足度を下げてしまいますが、Haiku 4.5であればリアルタイムに近いスピードで適切な回答を返せます。
しかも回答の質も高く、従来の簡易FAQボットとは一線を画する自然で的確なやり取りが可能です。OpenAIのChatGPT(GPT-4/5)と比較すると、回答精度の面では互角かタスクによってはHaikuが勝る可能性もあり、特に長文コンテキストを活かした複雑な質問でもHaikuは破綻しにくい強みがあります。
一方でGPT系は会話の創造性や知識量で優れる可能性もあるため、汎用的なおしゃべりにはGPT、即応性と文脈保持が重要な対話にはClaudeという使い分けも考えられます。
② コーディング支援・ペアプログラミング
Anthropicが「Claude Code」でコーディングツールを提供しているように、Haiku 4.5はプログラミング分野での活用に非常に適しています。
コード自動生成やデバッグ、リファクタリング提案、さらにはプロジェクトの設計支援まで、幅広い役割を果たせます。実際、Haiku 4.5はSonnet 4.5の90%程度の性能を持つとも評価されており、多くのコード関連タスクで一級の成果を出せると思います。
例えば、GitHub CopilotのバックエンドにHaiku 4.5を用いることで、従来より高速でインタラクティブなコーディングアシストが実現できるのではないかという声も出ています。
競合としては、OpenAIのCodexや、Googleのコード生成モデルが挙げられますが、Haiku 4.5は長大なコードコンテキストを処理できる点や、複数エージェントで大規模リファクタリングを並行実行できる点で優位だと思います。
複数のコードファイルをまたいだ一括変更や、大規模プロジェクトの部品を同時開発する、といった場面ではHaiku 4.5が強みを発揮してくれるでしょう。
なお、OpenAIのCodexについて詳しく知りたい方は、以下の記事も参考にしてみてください。
③ 複雑なエージェントタスク(マルチエージェントによる問題解決)
Claude Haiku 4.5の活用イメージ3つ目として、マルチエージェントによる協調動作が挙げられます。前述したように、Haiku 4.5は軽量ゆえに多数並行稼働させることが容易です。
そこで、例えば1つの上位エージェント(計画担当)が問題を分割し、複数の下位エージェントHaiku 4.5(実行担当)が各部分を解決する、というイメージの使い方が可能になります。
このアプローチは、研究や開発の現場で注目される可能性が高く、ソフトウェア開発では大きな機能を複数のモジュールに分割し、それぞれをHaikuエージェントが実装・テストし、最後に統合する、といったことが考えられます。
これは人間の開発チームにおける役割分担に近く、AI同士がチームを組んでプロジェクトを進める時代の先駆けとも言えるでしょう。
競合のOpenAIもAutoGPTやAgentGPTといったマルチエージェントの試みを見せていますが、Haiku 4.5は、Anthropic独自のコンテキスト管理機能やツール利用能力も相まって、より安定して長時間協調作業を継続できる強みがあります。
Claude Haiku 4.5を実際に使ってみた
ここからはClaude Haiku 4.5をWebUI上で実際に使ってみます。
テキストのJSON化
まずは雑多なテキストから情報を正確に抽出して、かんたんな請求書のJSON構造化をしてもらいましょう。プロンプトは以下の通りです。
【課題】次の請求書テキストから厳密なJSONを生成してください。出力はJSONのみ(説明やコードブロックは禁止)。金額は数値型、日付はYYYY-MM-DD。小計+税=合計にならない場合は明示的に再計算した正値を入れてください。
▼請求書テキスト
Invoice ID: INV-2025-1016-A
発行日: 2025/10/01 支払期日: 2025-10-31
請求元: 株式会社12345 営業本部
請求先: 合同会社54321 情報システム部
品目:
- "クラウド利用料(9月分)" 数量:1 単価: ¥48,000 (税別)
- "サポート時間" 数量:5 単価: ¥6,600 (税込)
メモ: 10/15障害対応1hを無償振替
小計: 48,000 + (6,600×5 税込) 税: 10%対象はクラウド利用料のみ
合計(記載): ¥84,000
▼出力スキーマ
{
"invoice_id": string,
"issue_date": "YYYY-MM-DD",
"due_date": "YYYY-MM-DD",
"issuer": string,
"bill_to": string,
"currency": "JPY",
"line_items": [
{"name": string, "qty": number, "unit_price_ex_tax": number, "tax_rate": number} // 税込表記は内税を除去してex_taxへ
],
"subtotal": number, // 税抜合計
"tax_total": number, // 税額合計
"grand_total": number // 最終合計(= 再計算後)
}Claude Sonnet 4.5の実行結果は以下の通り。
{
"invoice_id": "INV-2025-1016-A",
"issue_date": "2025-10-01",
"due_date": "2025-10-31",
"issuer": "株式会社12345 営業本部",
"bill_to": "合同会社54321 情報システム部",
"currency": "JPY",
"line_items": [
{
"name": "クラウド利用料(9月分)",
"qty": 1,
"unit_price_ex_tax": 48000,
"tax_rate": 0.1
},
{
"name": "サポート時間",
"qty": 5,
"unit_price_ex_tax": 6000,
"tax_rate": 0.1
}
],
"subtotal": 78000,
"tax_total": 7800,
"grand_total": 85800
}Claude Haiku 4.5の実行結果は以下の通り。
{
"invoice_id": "INV-2025-1016-A",
"issue_date": "2025-10-01",
"due_date": "2025-10-31",
"issuer": "株式会社12345 営業本部",
"bill_to": "合同会社54321 情報システム部",
"currency": "JPY",
"line_items": [
{
"name": "クラウド利用料(9月分)",
"qty": 1,
"unit_price_ex_tax": 48000,
"tax_rate": 0.1
},
{
"name": "サポート時間",
"qty": 5,
"unit_price_ex_tax": 6000,
"tax_rate": 0
}
],
"subtotal": 54000,
"tax_total": 4800,
"grand_total": 58800
}どちらもJSON形式や日付フォーマットは守れている一方で、固有名詞の抽出と金額計算に重要な差異がありました。(思わぬ結果です)
Claude Sonnet 4.5は、税率を両明細に0.1で適用してしまい、subtotal=78,000に対してtax_total=7,800となっています。要件は「10%対象はクラウド利用料のみ」なので、正しい税額は 48,000×0.1=4,800です。
このため、grand_total=85,800は過大(+3,000)になってしまっています。
一方のClaude Haiku 4.5は、サポート時間の税率を0%に設定できており、クラウド利用料のみ10%課税としていて、税額4,800を正しく出せています。ただ別の問題が発生していて、数量の乗算を落としてしまっているのでsubtotal=54,000(48,000+6,000×「1」相当)となっており、本来の結果 48,000 + (6,000×5) = 78,000と乖離してしまっています。
なお、出力スピードはClaude Sonnet 4.5が出力完了まで10秒ほど、Claude Haiku 4.5が3秒ほどでした。Sonnet 4.5も十分速いですが、Haiku 4.5は異次元のスピード感です。
出力内容が少し想定外の結果となってしまったので、別のタスクでも検証してみましょう。
インシデント調査
続いて、雑多なログからインシデント調査をしてもらって課題解決をしてもらいましょう。プロンプトは以下の通りです。
【課題】以下のサービス横断ログを分析し、
1) 根本原因の仮説(信頼度%付き・反証可能性も)
2) 影響範囲とSLA影響
3) 直ちに実施すべき緩和策Runbook(具体コマンドも入れて)
4) 恒久対策(スキーマ/インデックス設計案・監視項目・アラート式)
を提示してください。出力は日本語で簡潔に。
▼前提
- タイムスタンプはUTC。デプロイはblue-green。DBはPostgreSQL、接続プールpgbouncer、全文検索はpg_trgm。
- 推測は仮説として明示。事実と推測を混同しない。
▼ログ断片
2025-10-16T10:00:02Z api-gw INFO deploy start v2025.10.16-blue
2025-10-16T10:02:14Z ff-service INFO feature_flag enable_reco=true cohort=100%
2025-10-16T10:03:02Z orders-db LOG duration: 4650 ms statement: SELECT o.id,r.score FROM orders o JOIN recommendations r ON r.item_id=o.item_id WHERE o.created_at > now()-interval '30 days';
2025-10-16T10:03:03Z orders-db LOG hint: missing index on recommendations.item_id (seq scan)
2025-10-16T10:03:05Z payments ERROR db pool exhausted (pgbouncer_wait: 120s) route=/charge
2025-10-16T10:03:07Z api-gw WARN upstream 502 /checkout rate=12%
2025-10-16T10:03:40Z api-gw WARN upstream 502 /checkout rate=37%
2025-10-16T10:04:11Z orders-db LOG CPU 92% iowait 18% active_conn=480/500
2025-10-16T10:05:02Z api-gw INFO switch green->blue completed (health degraded)
2025-10-16T10:06:10Z payments WARN timeout to orders-db (wait_event=ClientRead)
2025-10-16T10:07:12Z ff-service INFO feature_flag enable_reco=false cohort=0% (rollback)
2025-10-16T10:07:50Z orders-db LOG duration p95: 180 ms active_conn=210/500
2025-10-16T10:08:05Z api-gw INFO upstream 5xx down to 1.2%
2025-10-16T10:10:00Z sre NOTE incident closed
▼出力要件(この順・この見出し)
【根本原因(仮説/信頼度%/反証可能性)】
【影響範囲・ユーザー影響】
【即時の緩和策Runbook】
- psqlコマンド(CREATE INDEX CONCURRENTLY など具体)
- 一時的なff設定/トラフィック制御案
- 検証/巻き戻し手順
【恒久対策】
- スキーマ/インデックス設計(pg_trgm/カバリングインデックス等)
- ダッシュボード監視式(PromQL or SQL/KQLいずれか)
- キャパシティ計画と負荷試験案
▼制約
- 外部情報に依存しない。与えたログのみから推論。
- 数値はログの事実に基づく。不明は「不明」と明示。
- 出力以外の余談や前置きは不要。Claude Sonnet 4.5の実行結果は以下の通り。
【根本原因(仮説/信頼度%/反証可能性)】
主仮説: レコメンド機能有効化によるインデックス欠損起因のDB過負荷
信頼度: 85%
因果連鎖
FF有効化(10:02:14) → 30日間orders×recommendations JOIN実行
recommendations.item_idにインデックス未設定 → Seq Scan発生
クエリ実行時間4.65秒(通常想定<100ms) → 接続保持時間延長
pgbouncer接続プール枯渇(待機120秒) → payments等の他機能影響
DB CPU92%/iowait18% → 全体スループット低下
/checkout 502エラー最大37%
反証可能性
支持証拠: FF無効化直後(10:07:12→10:07:50)に38秒で回復、タイミング一致
反証方法:
pg_stat_statementsでJOINクエリ実行回数/CPU時間確認
10:02〜10:07間のrecommendations.item_idスキャン統計
デプロイv2025.10.16-blueにレコメンド機能コード含有確認
alternative仮説(信頼度15%): デプロイv2025.10.16-blueに別のregression(低確率)
【影響範囲・ユーザー影響】
SLA影響
availability: 約5分間で最大37%のリクエスト失敗 → 月間99.9% SLA違反リスク
latency: p95=180ms(通常<100ms想定) → SLO超過の可能性
機能別影響
機能影響根拠/checkout37%失敗api-gw 502エラー/charge(payments)タイムアウトdb pool exhaustedorders照会系レイテンシ劣化JOIN遅延の波及他機能軽微な遅延接続プール競合
ユーザー影響推定
チェックアウト失敗: 5分間×37%失敗率 → トランザクション損失
決済エラー: タイムアウトによる二重決済リスク(要ログ確認)
【即時の緩和策Runbook】
1. インデックス緊急作成
sql-- 接続確認
psql -h orders-db-primary -U app_user -d orders_prod
-- CONCURRENTLY使用(本番トラフィック影響最小化)
CREATE INDEX CONCURRENTLY idx_recommendations_item_id
ON recommendations(item_id);
-- 進捗確認(別セッション)
SELECT phase, blocks_done, blocks_total
FROM pg_stat_progress_create_index
WHERE relid = 'recommendations'::regclass;
-- 完了確認(数分〜数十分)
\d+ recommendations
2. FF段階的再有効化
bash# 完全無効状態確認
curl -X GET https://ff-service/api/flags/enable_reco
# → cohort=0%を確認
# 1%カナリア有効化
curl -X POST https://ff-service/api/flags/enable_reco \
-d '{"cohort": 1, "duration": "10m"}'
# メトリクス監視(10分間)
# - orders-db: p95 < 200ms, active_conn < 300
# - api-gw: /checkout 5xx < 2%
# 問題なければ 5% → 25% → 100% 段階展開
3. pgbouncer接続プール一時拡大
bash# pgbouncer.ini編集(緊急措置)
ssh pgbouncer-host
sudo vi /etc/pgbouncer/pgbouncer.ini
# default_pool_size = 25 → 40
# max_client_conn = 500 → 800
sudo systemctl reload pgbouncer
# 効果確認
psql -h pgbouncer -p 6432 -U pgbouncer -c "SHOW POOLS;"
4. 検証/巻き戻し手順
sql-- JOIN性能検証
EXPLAIN (ANALYZE, BUFFERS)
SELECT o.id, r.score
FROM orders o
JOIN recommendations r ON r.item_id = o.item_id
WHERE o.created_at > now() - interval '30 days'
LIMIT 100;
-- Index Scan確認, 実行時間<100ms目標
-- 問題発生時ロールバック
DROP INDEX CONCURRENTLY idx_recommendations_item_id;
-- FF無効化
curl -X POST https://ff-service/api/flags/enable_reco -d '{"cohort": 0}'
【恒久対策】
1. スキーマ/インデックス設計
必須インデックス
sql-- JOIN最適化(Foreign Key側)
CREATE INDEX idx_recommendations_item_id_score
ON recommendations(item_id)
INCLUDE (score); -- Covering Index: Index-Only Scan有効化
-- 日付範囲フィルタ最適化
CREATE INDEX idx_orders_created_at_item_id
ON orders(created_at DESC)
INCLUDE (id, item_id)
WHERE created_at > now() - interval '90 days'; -- Partial Index
-- 統計更新
ANALYZE recommendations;
ANALYZE orders;
pg_trgm全文検索対応(将来用)
sql-- 商品名検索想定
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE INDEX idx_recommendations_item_name_trgm
ON recommendations USING gin(item_name gin_trgm_ops);
パーティショニング検討
sql-- ordersテーブル月次パーティション(履歴肥大化対策)
CREATE TABLE orders_partitioned (
id BIGSERIAL,
created_at TIMESTAMPTZ NOT NULL,
item_id BIGINT,
...
) PARTITION BY RANGE (created_at);
CREATE TABLE orders_y2025m10 PARTITION OF orders_partitioned
FOR VALUES FROM ('2025-10-01') TO ('2025-11-01');
2. ダッシュボード監視式
Prometheus/PromQL
promql# DB接続プール使用率(アラート閾値80%)
(pg_stat_database_numbackends{datname="orders_prod"} / 500) * 100 > 80
# スロークエリ率(p95 > 500ms)
histogram_quantile(0.95,
rate(pg_stat_statements_mean_exec_time_bucket[5m])
) > 500
# pgbouncer待機時間
rate(pgbouncer_wait_time_seconds_total[1m]) > 10
# JOIN実行回数監視(recommendations関連)
rate(pg_stat_statements_calls{query=~".*recommendations.*JOIN.*"}[5m])
PostgreSQL直接監視
sql-- リアルタイムスロークエリ
SELECT pid, now()-query_start AS duration, query
FROM pg_stat_activity
WHERE state = 'active'
AND now()-query_start > interval '2 seconds'
ORDER BY duration DESC;
-- インデックス未使用検出
SELECT schemaname, tablename, indexname, idx_scan
FROM pg_stat_user_indexes
WHERE idx_scan = 0
AND indexname NOT LIKE 'pg_toast%';
アラートルール
yaml# Prometheus Alert Manager
- alert: DatabaseConnectionPoolExhaustion
expr: pg_stat_database_numbackends / 500 > 0.8
for: 2m
annotations:
summary: "DB接続数80%超過 ({{$value}}%)"
- alert: SlowQueryDetected
expr: histogram_quantile(0.95, rate(pg_query_duration_bucket[5m])) > 1
for: 5m
annotations:
summary: "p95クエリ実行時間1秒超過"
3. キャパシティ計画と負荷試験
負荷試験シナリオ
bash# k6負荷試験スクリプト
cat > load_test.js <<'EOF'
import http from 'k6/http';
import { check } from 'k6';
export let options = {
stages: [
{ duration: '2m', target: 100 }, // ramp-up
{ duration: '5m', target: 1000 }, // recommendation全展開想定
{ duration: '2m', target: 0 }, // ramp-down
],
thresholds: {
http_req_duration: ['p(95)<500'], // p95 < 500ms
http_req_failed: ['rate<0.02'], // 失敗率 < 2%
},
};
export default function() {
let res = http.get('https://api-gw/checkout');
check(res, { 'status 200': (r) => r.status === 200 });
}
EOF
k6 run load_test.js
キャパシティ計画
sql-- テーブルサイズ予測
SELECT
schemaname, tablename,
pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename)) AS size,
(pg_total_relation_size(schemaname||'.'||tablename) /
EXTRACT(epoch FROM (now() - '2025-01-01'::date)) *
EXTRACT(epoch FROM interval '1 year'))::bigint AS yearly_growth
FROM pg_tables
WHERE tablename IN ('orders', 'recommendations')
ORDER BY pg_total_relation_size(schemaname||'.'||tablename) DESC;
デプロイ前チェックリスト
EXPLAIN ANALYZEで新JOIN実行計画確認(Index Scan必須)
staging環境で本番データ量×1.5倍負荷試験
pgbouncer接続数・DB max_connections余裕確認
FF段階展開設定(1%→5%→25%→100%, 各10分観測)
ロールバック手順文書化とFF即時無効化権限確認
推奨即時アクション優先順位
インデックス作成(CREATE INDEX CONCURRENTLY) - 30分以内
FF 1%再有効化テスト - インデックス作成完了後
pgbouncer設定見直し - 24時間以内
監視アラート追加 - 48時間以内そして、Claude Haiku 4.5の実行結果は以下の通り。
【根本原因(仮説/信頼度%/反証可能性)】
第一層(信頼度 95%)
推奨機能フラグ 100% 有効化により、JOIN クエリが全注文に対して recommendations テーブルをスキャン。recommendations.item_id にインデックスがないため、セクシャルスキャンで大量の CPU/IO 消費。
反証可能性:
ロールバック後(10:07:12Z)クエリ実行時間が即座に改善したことで、推奨機能有効化が主因であることを強く示唆
フラグ無効化前に SELECT クエリの実行計画を取得して EXPLAIN ANALYZE で検証可能
テスト環境で同一クエリを recommendations.item_id なしで実行し、遅延再現可能か確認
第二層(信頼度 88%)
blue-green デプロイで health check が "degraded" 状態であっても切り替えを実行。トラフィック急増に対し接続プール(500 上限)が不足。
反証可能性:
デプロイログと health check ルールの定義を確認し、degraded 判定での切り替え判断の妥当性を検証
pgbouncer ログで接続待機キューの成長曲線を抽出し、デプロイ前後の接続パターン比較
第三層(信頼度 72%)
old blue インスタンスは orders-db 接続プール枯渇を認識し、ClientRead(アプリ側からの読み取り待機)でハング。これが新 blue へのコネクションハンティングを引き起こした可能性。
反証可能性:
green インスタンス(旧バージョン)の access log と new blue インスタンスの retry 時間を比較
【影響範囲・ユーザー影響】
直接影響:
/checkout エンドポイント:502 エラー発生(最大 37% エラー率、期間 10:03~10:08、約 5 分間)
/charge ルート(決済):同期エラー発生、支払い失敗の可能性
推定ユーザー数:
ログより「rate=37%」なので、当該 5 分間のチェックアウト試行の約 1/3 が失敗
実数不明(RPS 不明のため)
SLA 影響:
インシデント継続時間:10:03:05Z~10:08:05Z(約 5 分)
99.9% SLA (月間 43.2 分 downtime 許容)に対し、約 5 分の 5xx 多発はバジェット消費
金銭的影響:決済失敗による売上機会損失(金額不明)
【即時の緩和策 Runbook】
Step 1: インデックス作成(接続中に実行・約 3~10 分想定)
sql-- オンライン作成で運用継続
CREATE INDEX CONCURRENTLY idx_recommendations_item_id
ON recommendations(item_id);
-- 検証
EXPLAIN ANALYZE SELECT o.id, r.score FROM orders o
JOIN recommendations r ON r.item_id=o.item_id
WHERE o.created_at > now()-interval '30 days';
Step 2: フラグロールバック(即座 / <30 秒)
bash# feature-flag サービスで手動ロールバック実行
curl -X POST http://ff-service:8080/rollback \
-d '{"flag":"enable_reco", "cohort":0}' \
-H "Content-Type: application/json"
Step 3: 接続プール調査・一時的な増設
bash# pgbouncer 設定確認・再読み込み
# /etc/pgbouncer/pgbouncer.ini の max_client_conn / default_pool_size を確認
pgbouncer -R # graceful reload
# または一時的に接続上限を引き上げ
# max_client_conn = 600 # 500 → 600
systemctl reload pgbouncer
Step 4: green インスタンスから接続を draindown
bash# 旧 green インスタンスをロードバランサから外す
aws elb deregister-instances-from-load-balancer \
--load-balancer-name orders-alb \
--instances i-green-old
# 既存接続の graceful close を待つ(タイムアウト: 30s)
sleep 30
Step 5: 巻き戻し手順(必要に応じて)
bash# blue-green 切り替え巻き戻し(可能な場合)
aws deploy continue-deployment \
--deployment-id [deployment-id] \
--action STOP_DEPLOYMENT
# または手動で green へ再切り替え
# ロードバランサで blue::0%, green::100% に変更
検証:
bash# エラー率低下確認
curl http://api-gw/health/metrics | jq '.http_5xx_rate_5m'
# クエリ応答時間確認
psql -h orders-db -c "SELECT percentile_cont(0.95) WITHIN GROUP (ORDER BY duration) FROM pg_stat_statements;"
【恒久対策】
1. スキーマ・インデックス設計
sql-- recommendations テーブル
-- カバリングインデックス(INCLUDE を用いた部分的なプッシュダウン)
CREATE INDEX idx_recommendations_item_id_covering
ON recommendations(item_id)
INCLUDE (score); -- JOIN で score も含め、Bitmap Heap Scan の回避
-- orders テーブル
-- created_at 検索の高速化
CREATE INDEX idx_orders_created_at_desc
ON orders(created_at DESC NULLS LAST);
-- 複合インデックス(JOIN + フィルタの最適化)
CREATE INDEX idx_orders_recommendations_join
ON orders(item_id, created_at DESC)
WHERE deleted_at IS NULL;
-- pg_trgm 活用(部分一致検索が対象外だが、将来の注文検索用)
CREATE INDEX idx_orders_search_trgm
ON orders USING gin(customer_name gin_trgm_ops);
パーティショニング候補:
sql-- created_at で月単位パーティション(大規模テーブル対策)
CREATE TABLE orders_2025_10 PARTITION OF orders
FOR VALUES FROM ('2025-10-01') TO ('2025-11-01');
2. ダッシュボード監視式
PromQL (Prometheus):
promql-- orders-db クエリ時間 p95
histogram_quantile(0.95, rate(pg_statement_duration_seconds_bucket[5m]))
-- pgbouncer 接続プール使用率
rate(pgbouncer_client_connections_waiting[5m]) / pgbouncer_pool_size > 0.8
-- /checkout 5xx エラー率(5 分移動平均)
rate(http_requests_total{path="/checkout", status=~"5.."}[5m])
/ rate(http_requests_total{path="/checkout"}[5m]) > 0.01
-- orders-db CPU iowait
node_cpu_seconds_total{mode="iowait"} > 0.2
SQL ダッシュボード (pg_stat_statements):
sql-- 遅いクエリ継続監視
SELECT query, calls, mean_exec_time, max_exec_time
FROM pg_stat_statements
WHERE query LIKE '%recommendations%'
ORDER BY mean_exec_time DESC
LIMIT 10;
-- インデックス利用状況
SELECT schemaname, tablename, indexname, idx_scan, idx_tup_read, idx_tup_fetch
FROM pg_stat_user_indexes
WHERE idx_scan = 0 -- 未使用インデックス検出
ORDER BY idx_scan;
3. アラート定義
監視対象条件閾値通知先クエリ応答時間 (p95)> 500ms 5 分継続p95 > 500msSlack #db-alertspgbouncer 接続プール待機> 60s 3 回wait_time > 60sPagerDuty (critical)orders-db CPU iowait> 20% 3 分継続iowait > 20%Slack #db-alerts/checkout エラー率> 1% 2 分継続5xx_rate > 1%PagerDuty (critical)推奨機能フラグ有効率> 50% かつエラー率↑enable_reco=true AND 5xx_rate↑Slack #oncallインデックス欠落スキャンpg_stat_user_indexes で seq_scan > 1000seq_scan > 1000/hSlack #db-ops
4. キャパシティ計画と負荷試験
キャパシティ計画:
推奨機能有効化時の JOIN クエリは現行設計で 2~5 倍の CPU 消費を引き起こすことが判明
推奨機能が cohort 100% 展開された場合、recommendations テーブルサイズが 10 倍になると想定してテスト
接続プールを 500 → 800 へ増設検討
orders-db インスタンスを 16 core → 24 core へ スケールアップ検討
負荷試験 Runbook:
bash# 1. テスト環境でインデックス無し/有りの 2 パターンで実行
# テスト条件: 過去 30 日の注文全件 JOIN
# パターン A: インデックス無し
psql -h orders-db-test -c "
DROP INDEX IF EXISTS idx_recommendations_item_id;
EXPLAIN ANALYZE
SELECT o.id, r.score FROM orders o
JOIN recommendations r ON r.item_id=o.item_id
WHERE o.created_at > now()-interval '30 days';"
# パターン B: インデックス有り
psql -h orders-db-test -c "
CREATE INDEX idx_recommendations_item_id ON recommendations(item_id);
EXPLAIN ANALYZE
SELECT o.id, r.score FROM orders o
JOIN recommendations r ON r.item_id=o.item_id
WHERE o.created_at > now()-interval '30 days';"
# 2. locust で推奨機能有効時の RPS 負荷試験
locust -f locustfile.py --host=http://api-gw-test \
-u 1000 -r 50 --run-time 5m
# assertions: p95 < 500ms, error_rate < 1%
スケーリング決定基準:
負荷試験で p95 > 500ms 時、接続プール上限に達していないか確認
達している場合は pool_size を +100 → +200 へ増設検討
CPU 利用率 > 80% が sustained する場合、DB インスタンスのスケールアップ実施正確性・一貫性はどちらも高水準で、原因の仮説立ても提示したログと整合しているので良い感じです。
ただ、やはりHaiku 4.5のスピードは際立っていました。Sonnet 4.5が出力開始までの所要時間が約10秒、出力完了までの所要時間が約75秒だったのに対して、Haiku 4.5は出力開始までの時間が約1秒、出力完了までの時間が約35秒で圧倒的なスピード感でした。
細かいところのクオリティをみるとSonnet 4.5が優位ですが、Haiku 4.5の出力も申し分ないですし、このスピード感は日常使いや時間が限られているシーンでかなり有効的だと思います。
まとめ
Claude Haiku 4.5は、高速・高効率なAIモデルとして注目が集まります。
スピードと知性の両立を実現し、大規模モデルの性能を軽量モデルで再現している点は、かなり評価ポイントが高いです。
Anthropic共同創設者のJeff Wang氏も「従来は品質のために速度やコストを犠牲にしてきたが、Haiku 4.5はその妥協をぼやけさせた。高速でコスト効率も良いフロンティアモデルであり、この種のモデルが向かう先を示している」と述べています。まさにその言葉通り、Haiku 4.5はAI開発の新たな価値を示してくれる存在となっています。
今後の展望として、まず考えられるのは更なるモデルの改良とシリーズ展開です。Claude 4.5シリーズとしては既にSonnet 4.5とHaiku 4.5が登場しましたが、最大規模モデルのOpus 4.5(仮)や、より軽量で安価なモデルの投入も予想されます。
また、Anthropicが重視するマルチエージェント分野では、Haiku系モデルが果たす役割がますます大きくなると思われます。Sonnetなど最上位モデルは計画立案や特殊ケース処理に専念させ、普段の大量タスク処理はHaikuの集団がこなすといった形で、AIのチーム運用が一般化するかもしれません。
最後に、Claude Haiku 4.5の利用を検討している読者のみなさんへのアドバイスです。
まずは、試してみることをお勧めします。Claude.ai上で簡単に利用でき、APIも少し触るだけで組み込めます。使ってみれば、その高速さと高性能ぶりにきっと驚かれることと思います。
次に、ご自身のユースケースに合わせてモデルの使い分け戦略を考えてみてください。
Haiku 4.5だけで完結するならそれで良いですが、場合によってはSonnet 4.5や他社モデルとのハイブリッドが効果的かもしれません。
Anthropicが推奨するように、重い処理は大規模モデル、日常的多数処理は小規模モデルといった役割分担でシステムを設計すると、性能とコストの最適化が図れます。幸いHaiku 4.5はコストが低いので、色々と試行錯誤しやすいと思います。
ぜひ一度Claude Haiku 4.5を試してみてください。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

