
【次世代動画トラッキングAI】MetaのCoTracker3を徹底解説
2024年10月17日にMetaが新たなAIモデルをリリースしました!
CoTracker3は従来のポイントトラッカーに比べ、1,000分の1のデータ量で結果を返し、標準的なベンチマークでは、従来のポイントトラッカーよりもスコアを上回っています。
本記事ではCoTracker3について紹介して、最後にgoogle colaboratoryで実装する方法を解説します。本記事を最後まで読むことで、CoTracker3を使うことができるようになります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
CoTracker3の概要
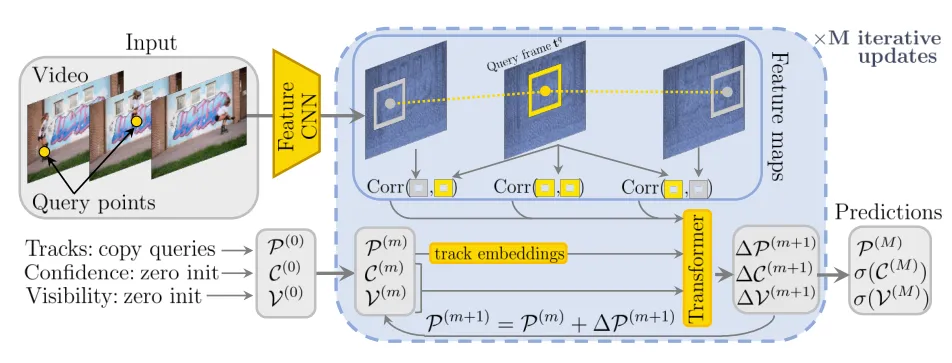
CoTracker3は、最先端のポイントトラッカーであり、新しいトラッキングモデルと半教師あり学習によって、動画内の任意のポイントを追跡できます。
CoTracker3はこの新しいモデルと学習方法により、教師モデルを使用して擬似ラベルを生成することで、アノテーションのない実際の動画を学習に使うことが可能です。
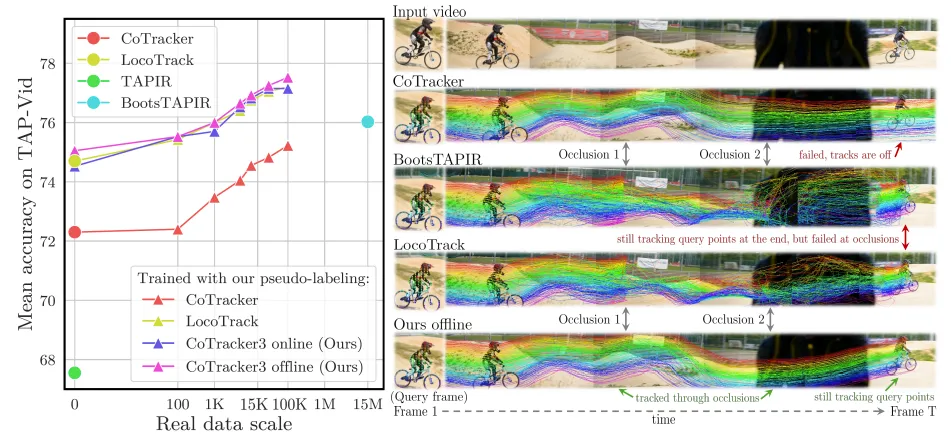
以前のポイントトラッカーからいくつかのコンポーネントを削除または簡素化し、よりシンプルでより小さなアーキテクチャを実現。CoTracker3の学習スキームは、従来の手法よりはるかにシンプルで、1,000分の1のデータ量でより良い結果を達成します。
CoTracker3の特徴
CoTracker3は最先端のポイントトラッカーですが、3つの特徴があります。
- シンプルなアーキテクチャとデータ効率
- オクルージョンに対するロバスト性
- 半教師あり学習
それぞれを順に解説します。
シンプルなアーキテクチャとデータ効率
CoTracker3は、従来のトラッカーと比較して、よりシンプルで効率的なアーキテクチャを採用しています。
具体的には、BootsTAPIRやLocoTrackといった最新のトラッカーで採用されているグローバルマッチングステージを削除し、相関特徴の処理にはシンプルなMLPを使用しています。
これらの簡素化により、CoTracker3はCoTrackerと比較してパラメータ数が1/2に削減され、処理速度は最速のトラッカーであるLocoTrackよりも27%高速化されています。
また、CoTracker3は、従来の手法よりもはるかに少ないデータで学習することが可能。具体的には、15,000本の実際の動画でファインチューニングしたCoTracker3オンラインバージョンは、1,500万本の動画で学習したBootsTAPIRを上回る性能を示しています。
オクルージョンに対するロバスト性
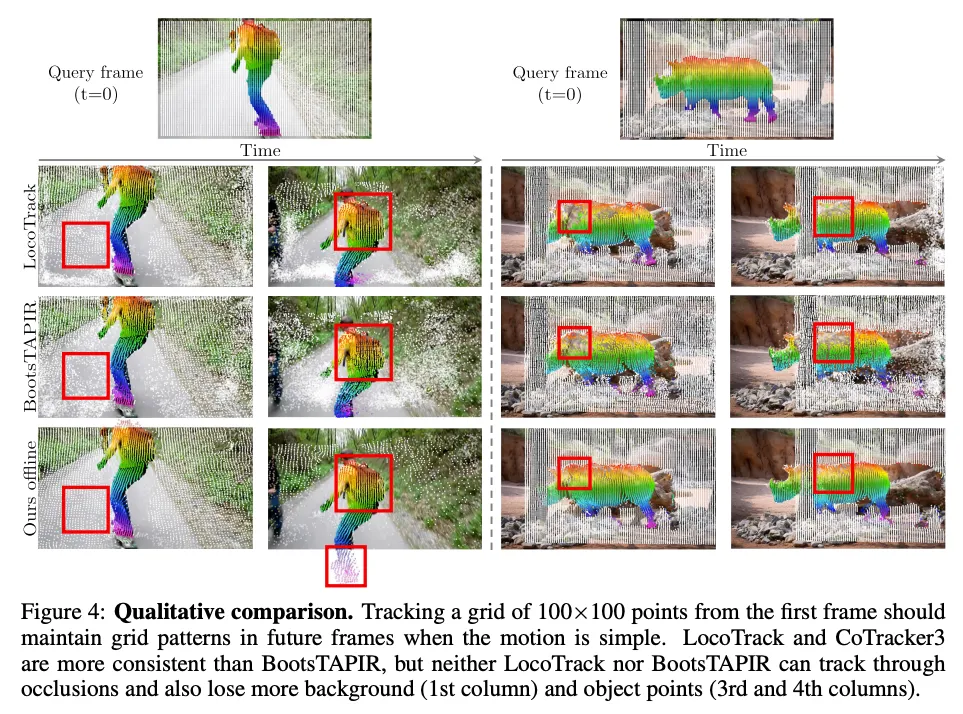
CoTracker3は、オクルージョンされたポイントも正確に追跡できるという特徴があります。これは、複数のポイントを共同で追跡するクロス-トラックアテンション機構を採用しているためです。
※オクルージョン:視点から見ている物体が他の物体によって部分的または完全に隠れる状態
クロス-トラックアテンション機構により、可視ポイントの位置に基づいて、オクルージョンされたポイントの位置を推測することが可能になります。
特に、オフラインバージョンは、すべての動画フレームに一度にアクセスできるため、オクルージョンされた軌跡をより効果的に補間できるため、オンラインバージョンよりもオクルージョンされたポイントの追跡精度が高くなることが可能です。
半教師あり学習
CoTracker3は、アノテーションのない実際の動画を学習に利用できる半教師あり学習を採用しています。
具体的には、既存のトラッカーを教師モデルとして使用し、実際の動画に擬似ラベルを生成。そして、これらの擬似ラベルを用いてCoTracker3をファインチューニングします。
この学習方法のメリットは次の4つです。
●ノイズを含む大量のデータセットから学習できるため、生徒モデルは教師モデルよりも優れた性能を達成できる可能性がある。
●実際の動画から学習することで、合成データと実際のデータとの間の分布のずれを軽減できる。
●アンサンブル/投票効果により、擬似アノテーションのノイズを低減できる。
●生徒モデルは、タスクの異なる側面で優れている可能性のある、異なる教師の長所を継承できる。
CoTracker3は、上記の3つの特徴に加えて、オンラインとオフラインの両方のバージョンを提供していることも特徴的です。オンラインバージョンは、入力動画を逐次処理し、ポイントを前方だけに追跡するため、リアルタイム処理に適しています。
一方、オフラインバージョンは、動画全体を単一のウィンドウとして処理するため、前方と後方の両方向にポイントを追跡することができ、オクルージョンされたポイントの追跡精度が向上します。

複数の教師モデルを使うメリット
CoTracker3では、トレーニングに複数の教師モデルが使われていますが、複数の教師モデルを使用するメリットは次の4つが挙げられます。
- 多様なデータからの学習による汎化性能の向上
- 擬似ラベルのノイズ低減による学習の安定化
- 教師モデルの長所の継承
- 実データと合成データのギャップの軽減
多様なデータからの学習による汎化性能の向上
複数の教師モデルは、それぞれ異なる強みと弱みを持っているため、生成される擬似ラベルも多様性を持つことになります。
生徒モデルは、これらの多様な擬似ラベルから学習することで、特定の教師モデルに偏ることなく、より汎化性能の高いモデルを学習できます。
擬似ラベルのノイズ低減による学習の安定化
教師モデルが生成する擬似ラベルは、必ずしも完璧ではありません。ノイズが含まれている可能性もあります。
複数の教師モデルを用いることで、それぞれの教師モデルが生成する擬似ラベルを組み合わせることで、ノイズの低減ができ、より正確な擬似ラベルを得ることができます。
教師モデルの長所の継承
生徒モデルは、複数の教師モデルから学習することで、それぞれの教師モデルの長所を継承可能。
例えば、ある教師モデルはオクルージョンされたポイントの追跡に優れており、別の教師モデルは高速な動きの追跡に優れているとします。生徒モデルは、これらの教師モデルから学習することで、両方のタスクに優れた性能を発揮するモデルが可能です。
実データと合成データのギャップの軽減
CoTracker3のトレーニングでは、まず合成データを用いて事前学習を行い、その後、教師モデルが生成した擬似ラベルを用いて実データでファインチューニングを行います。
複数の教師モデルを用いることで、より多くの実データから学習ができるため、実データと合成データのギャップを効果的に軽減することができます。
CoTracker3のライセンス
CoTracker3はCC BY-NC 4.0ライセンスです。そのため、主に金銭的利益を得ることを目的とした商用利用はできません。
また、配布することは可能ですが、その際には非商用利用かつ元のクリエイターのクレジットを表示する必要があります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ❌ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ❌ (別途申請が必要) |
| 私的使用 | ⭕️ |
なお、高解像度の深度マップをたった0.3秒で生成が可能なDepth Proについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

CoTracker3の使い方
ここからは実際にCoTracker3をgoogle colaboratoryで実装します
GitHubにgoogle colaboratoryのサンプルコードが掲載されているので、そちらを参考に実装します。
google colaboratoryでCoTracker3の実装
GPUを使用しますが、動画のサイズによっては無料版のGoogle Colaboratoryでも実行可能です。
公開されているサンプルコードで実装した時のgoogle colaboratory環境は以下です
■PythonのバージョンPython 3.8以上
■使用ディスク量29.4GB
■GPU RAMの使用量8.4GB
■システムRAMの使用量3.1 GB
GitHubのクローンはこちら
!git clone https://github.com/facebookresearch/co-tracker
%cd co-tracker
!pip install -e .
!pip install opencv-python matplotlib moviepy flow_vis
!mkdir checkpoints
%cd checkpoints
!wget https://huggingface.co/facebook/cotracker3/resolve/main/scaled_offline.pthライブラリのインポートはこちら
%cd ..
import os
import torch
from base64 import b64encode
from cotracker.utils.visualizer import Visualizer, read_video_from_path
from IPython.display import HTMLビデオの読み込みはこちら
video = read_video_from_path('./assets/apple.mp4')
video = torch.from_numpy(video).permute(0, 3, 1, 2)[None].float()動画の表示はこちら
def show_video(video_path):
video_file = open(video_path, "r+b").read()
video_url = f"data:video/mp4;base64,{b64encode(video_file).decode()}"
return HTML(f"""<video width="640" height="480" autoplay loop controls><source src="{video_url}"></video>""")
show_video("./assets/apple.mp4")モデルの読み込みと初期化はこちら
from cotracker.predictor import CoTrackerPredictor
model = CoTrackerPredictor(
checkpoint=os.path.join(
'./checkpoints/scaled_offline.pth'
)
)GPUのチェックはこちら
if torch.cuda.is_available():
model = model.cuda()
video = video.cuda()トラッキングの実施はこちら
pred_tracks, pred_visibility = model(video, grid_size=30)トラッキング結果の可視化はこちら
vis = Visualizer(save_dir='./videos', pad_value=100)
vis.visualize(video=video, tracks=pred_tracks, visibility=pred_visibility, filename='teaser');トラッキングしている動画の表示はこちら
show_video("./videos/teaser.mp4")GPUのメモリは動画の長さやgrid_sizeなどによって異なるので、OutOfMemoryErrorが出る場合には変更してみてください。


CoTracker3でさまざまな動画のトラッキングを検証
CoTracker3は遮蔽物で見えなくなった場所も憶測しながら見失わないように追跡したり、柔らかい素材のものも追跡することができるとされています。
そこで、本記事では、遮蔽物で見えなくなった場所もトラッキングできるのか、柔らかい素材のものも追跡できるのか検証していきます。
どちらの動画も/co-tracker内のフォルダに含まれているので、パス名を変更すればOKです。
もしも自分の持っている動画もしくは別のサイトでダウンロードした動画を使いたい場合には、google colaboratoryにアップロードしてパス名を変更すれば使えます。
まずは遮蔽物で見えなくなった場所もトラッキングできるかです。これは手でぬいぐるみを動かしている動画を読み込ませていきます。
GitHubのクローンはこちら
!git clone https://github.com/facebookresearch/co-tracker
%cd co-tracker
!pip install -e .
!pip install opencv-python matplotlib moviepy flow_vis
!mkdir checkpoints
%cd checkpoints
!wget https://huggingface.co/facebook/cotracker3/resolve/main/scaled_offline.pthライブラリのインポートはこちら
%cd ..
import os
import torch
from base64 import b64encode
from cotracker.utils.visualizer import Visualizer, read_video_from_path
from IPython.display import HTMLビデオの読み込みはこちら
video = read_video_from_path('/content/co-tracker/gradio_demo/videos/teddy.mp4')
video = torch.from_numpy(video).permute(0, 3, 1, 2)[None].float()動画の表示はこちら
def show_video(video_path):
video_file = open(video_path, "r+b").read()
video_url = f"data:video/mp4;base64,{b64encode(video_file).decode()}"
return HTML(f"""<video width="640" height="480" autoplay loop controls><source src="{video_url}"></video>""")
show_video("/content/co-tracker/gradio_demo/videos/teddy.mp4")モデルの読み込みと初期化はこちら
from cotracker.predictor import CoTrackerPredictor
model = CoTrackerPredictor(
checkpoint=os.path.join(
'./checkpoints/scaled_offline.pth'
)
)GPUのチェックはこちら
if torch.cuda.is_available():
model = model.cuda()
video = video.cuda()トラッキングの実施はこちら
pred_tracks, pred_visibility = model(video, grid_size=30)トラッキング結果の可視化はこちら
vis = Visualizer(save_dir='./videos', pad_value=100)
vis.visualize(video=video, tracks=pred_tracks, visibility=pred_visibility, filename='teaser');トラッキングしている動画の表示はこちら
show_video("./videos/teaser.mp4")次にクッションを使ってトラッキングをしていきます。
GitHubのクローンはこちら
!git clone https://github.com/facebookresearch/co-tracker
%cd co-tracker
!pip install -e .
!pip install opencv-python matplotlib moviepy flow_vis
!mkdir checkpoints
%cd checkpoints
!wget https://huggingface.co/facebook/cotracker3/resolve/main/scaled_offline.pthライブラリのインポートはこちら
%cd ..
import os
import torch
from base64 import b64encode
from cotracker.utils.visualizer import Visualizer, read_video_from_path
from IPython.display import HTMLビデオの読み込みはこちら
video = read_video_from_path('/content/co-tracker/gradio_demo/videos/pillow.mp4')
video = torch.from_numpy(video).permute(0, 3, 1, 2)[None].float()動画の表示はこちら
def show_video(video_path):
video_file = open(video_path, "r+b").read()
video_url = f"data:video/mp4;base64,{b64encode(video_file).decode()}"
return HTML(f"""<video width="640" height="480" autoplay loop controls><source src="{video_url}"></video>""")
show_video("/content/co-tracker/gradio_demo/videos/pillow.mp4")モデルの読み込みと初期化はこちら
from cotracker.predictor import CoTrackerPredictor
model = CoTrackerPredictor(
checkpoint=os.path.join(
'./checkpoints/scaled_offline.pth'
)
)GPUのチェックはこちら
if torch.cuda.is_available():
model = model.cuda()
video = video.cuda()トラッキングの実施はこちら
pred_tracks, pred_visibility = model(video, grid_size=30)トラッキング結果の可視化はこちら
vis = Visualizer(save_dir='./videos', pad_value=100)
vis.visualize(video=video, tracks=pred_tracks, visibility=pred_visibility, filename='teaser');トラッキングしている動画の表示はこちら
show_video("./videos/teaser.mp4")従来のトラッキングでは、遮蔽物に隠れてしまったり、物体が重なったりしていると正確にトラッキングすることが難しかったです。
しかし、CoTracker3は物体が重なっていても、素材にも左右されないため非常に使いやすいモデルだと思います。今後の発展が非常に楽しみです。
なお、ドラッグ操作だけで画像編集できるAIツール【InstantDrag】について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事では、CoTracker3について紹介をしました。
特に、CoTracker3の優れたオクルージョン耐性や効率的なデータ利用により、これまで追跡が難しかったシーンでも高精度なトラッキングが可能です。さらに、リアルタイムでの処理能力も向上しており、さまざまな業界での幅広い応用が期待されています。
従来は物体が重なってしまうと正確なトラッキングが困難だった環境でも、CoTracker3はその性能を発揮できるでしょう。ぜひ本記事を参考に、CoTracker3を活用してみてください!
最後に
いかがだったでしょうか?
動画トラッキングを用いて、強固なセキュリティ対策を実現したり、映画やVFXでリアルなエフェクトを付加するなど、さまざまな用途で活用できます。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。


