
【DeepSeek-OCR】テキストを画像に変換して圧縮処理?最新OCRモデルを徹底解説
- DeepSeek-AI発の最新OCRモデル
- テキスト文書をいったん画像に変換し、画像から文章を読み取ることでテキストを圧縮して処理
- 圧縮率10倍程度までは実用上問題ない精度で、ほぼ元の文章をそのまま取得可能
2025年10月20日、DeepSeek-AIは3.8億パラメータ規模の視覚と言語を組み合わせた新しいOCRモデル「DeepSeek-OCR」を発表しました!
DeepSeek-OCRは、コンテキストの光学的圧縮と呼ばれる革新的な手法で、長大なテキスト文書をいったん画像に変換し、その画像から文章を読み取ることでテキストを圧縮して処理するという特徴があります。
従来は、言語モデルに数万トークンもの長文を与えると計算量やコストが膨大になりがちでした。
しかし、DeepSeek-OCRでは、文章を「画像」という形で認識し、視覚トークンに変換してからテキスト復元するため、モデルが処理するトークン数を劇的に削減できます。
そこで本記事では、DeepSeek-OCRの概要や性能、使い方まで徹底的に解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
DeepSeek-OCRの概要

DeepSeek-OCRは、光学的なコンテキスト圧縮を実現するために設計されたエンドツーエンドのOCR・ドキュメント解析モデルです。
このモデルは大きく2つのコンポーネントから構成されており、まず高解像度の画像入力を少数の視覚トークンに圧縮する「DeepEncoder」と、続いてその視覚トークン列から元のテキストを復元する「DeepSeek-3B-MoE」というデコーダ(Mixture-of-Experts型の言語モデル)で動作します。
DeepEncoder(約3.8億パラメータ)は、局所的な画像特徴抽出にSAMベースのウィンドウ注意機構を組み込み、さらに中間に16×圧縮の二層CNNを挟むことで、1024×1024ピクセルの画像を4096パッチから256個程度のトークンに大幅圧縮します。
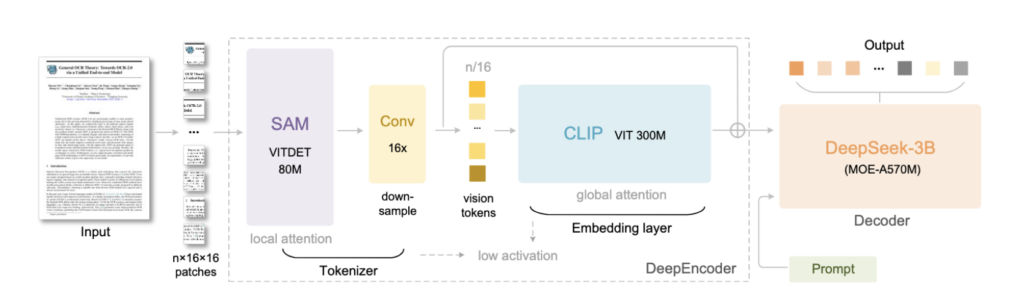
また、グローバルな文脈把握にはCLIP-Large由来の注意機構を採用し、高解像度画像でも少数トークンに情報凝縮できるよう工夫されています。
これら視覚トークンを受け取るデコーダ側は総パラメータ30億(推論時に有効なのは約5億7千万)で、64個のエキスパートから各ステップ6個を動的利用するMoE構造を持ち、軽量ながら効率よくテキスト再構成を行います。
このアーキテクチャによって、DeepSeek-OCRはテキスト文書の内容を「画像」に変換してから読み取るという従来にないアプローチをとっています。
特に長大な文書を扱う際に、テキストをそのまま処理するより遥かに少ないトークン数で同等の情報を表現することが可能になっています。
例えば、通常2,000~5,000トークンを要するような文章ボリュームでも、画像にレンダリングすれば、200~400個程度の視覚トークンで表現可能となり、約10分の1に圧縮できる計算になります。


DeepSeek-OCRの性能
DeepSeek-OCRの性能は、公開された技術報告やベンチマーク結果から非常に高い水準にあることが確認されています。
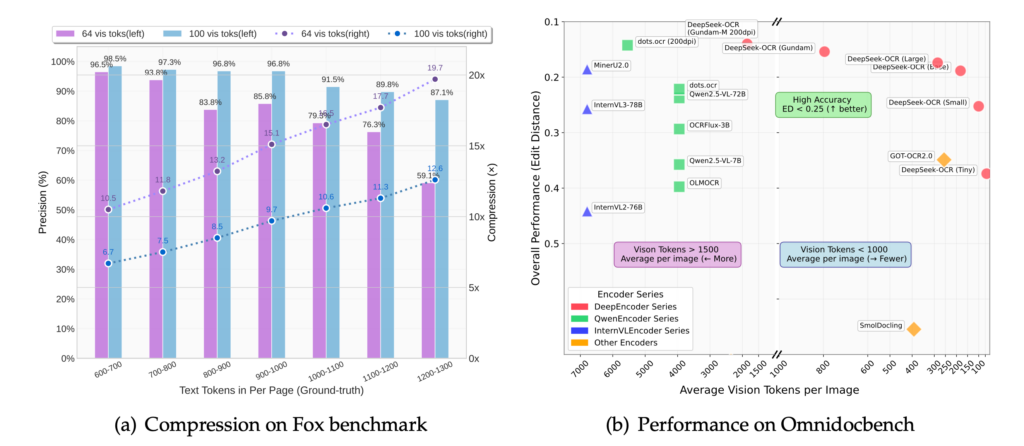
まず、Foxベンチマーク(圧縮率ごとのOCR精度を測定するテスト)では、テキストトークン数に対する視覚トークン数の比率が約10倍程度であれば97%近い精度で原文を完全復元できると報告されています。
具体的には、100個の視覚トークンで600~700語のページを処理した場合、約6.7倍の圧縮に対して98.5%というほぼロスレスな精度を達成し、900~1000語でも96.8%の精度を維持しています。
一方、圧縮率をさらに高めて64個の視覚トークン(Tinyモード)で1200~1300語を読ませた場合でも59.1%の精度が残っており、圧縮率20倍近くでも過半の情報を保持できているのは注目に値します。
これらの結果から、本モデルは、圧縮率10倍程度までは実用上問題ない精度(ほぼ元の文章をそのまま取得可能)であり、20倍近く極端に圧縮した場合でも一定の可読性を担保できることがわかります。
また、OmniDocBenchという実践的なドキュメントOCRベンチマークでの比較では、DeepSeek-OCRは極めて高い効率で既存モデルに匹敵・凌駕する性能を示しています。
研究チームの報告によると、Smallモード(視覚トークン100個)で既に従来の高性能モデルGOT-OCR 2.0(約256トークン使用)を上回る精度を達成し、Largeモード(400トークン前後)では最先端のSOTAに肩を並べる水準に達しています。
DeepSeek-OCRのライセンス
DeepSeek-OCRはMITライセンスで公開されています。
MITライセンスは、オープンソースソフトウェアの中でも非常に寛容なライセンス形態で、ソフトウェアの使用や改変、再配布を含め幅広い利用を無償かつ無制限に許可するものです。
DeepSeek-OCRの場合、研究コードからモデルの重みまで全てがGitHubやHugging Faceで公開されており、個人から企業まで誰でも自由に入手して利用できます。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
DeepSeek-OCRの料金
DeepSeek-OCRはオープンソースプロジェクトであり、その利用自体に公式の料金プランや使用料は発生しません。
モデルのコードと学習済みウェイトはGitHubおよびHugging Face上で無償公開されており、誰でもダウンロードして手元の環境で実行できます。したがって、ソフトウェア利用にあたってDeepSeek側に支払う費用は一切ありません。
DeepSeek-OCRの使い方
DeepSeek-OCRは、GitHubやHugging Faceでコードやドキュメントが整備されているので、比較的スムーズに試すことができます。以下ではTransformers経由と、vLLM経由の2通りの使い方をご紹介します。
Transformers経由での使い方
まず環境準備として、PythonとPyTorchを適切なバージョンで用意します。本モデルの開発環境はPython 3.12.9 + CUDA 11.8 + PyTorch 2.6.0でテストされています。なので、まずは同等の環境を作成し、依存ライブラリをインストールしましょう。
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
cd DeepSeek-OCR
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
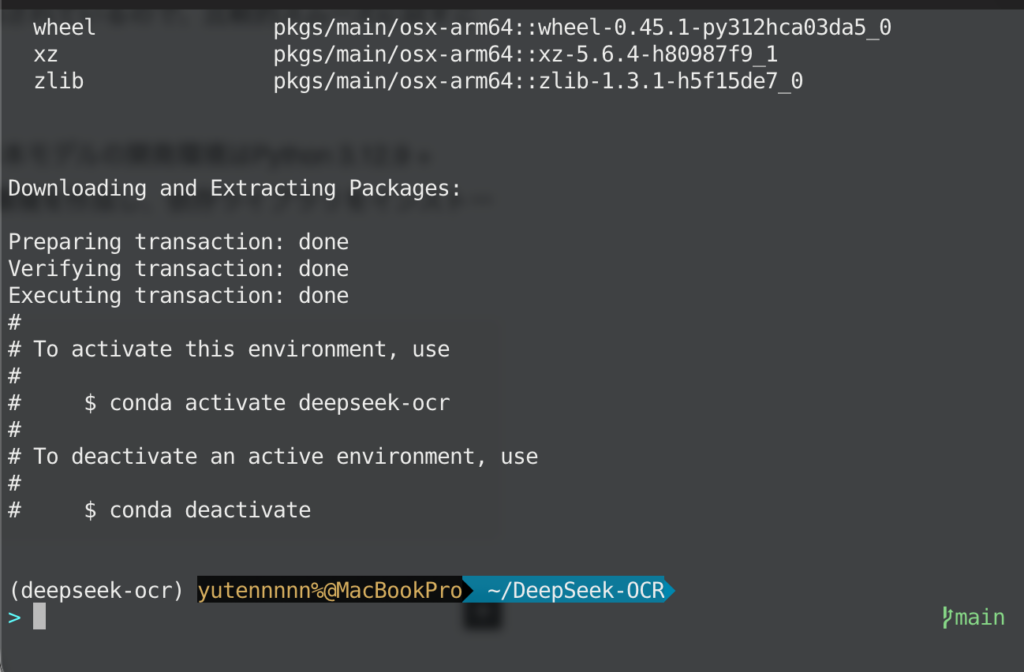
上記のように仮想環境ができたら、下記コマンドで必要パッケージをインストールします。
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
Windowsの方は問題なく実行できるかと思いますが、PyTorchはmacOS Intel(x86_64) 向けの配布を 2.2 系で終了しており、2.3 以降(今回必要な2.6も)のホイールは存在しないので、以下のコマンドを実行しましょう。
# macOS (Intel) ではこれで OK。index-url は付けない
pip install "torch==2.2.2" "torchvision==0.17.2" "torchaudio==2.2.2"
ここまで設定できたら、Hugging Face Transformers経由で、1枚の画像からテキスト化までを行う最小コードは以下の通りです。画像ファイル(例:your_image.jpg)を用意して実行してください。
# Windows用
from transformers import AutoModel, AutoTokenizer
import torch, os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
model_name = "deepseek-ai/DeepSeek-OCR"
# モデルとトークナイザを読み込み(remote code を信頼)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True,
)
# 推論モード + GPU + bfloat16
model = model.eval().cuda().to(torch.bfloat16)
# 画像 → Markdown 変換を指示
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = "your_image.jpg" # 入力画像
output_path = "outputs" # 生成物の保存先ディレクトリ
# Gundamモード例(高密度ページ向けの自動タイル+全体ビュー)
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path=output_path,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True,
test_compress=True,
)# mac用
# run_dpsk_ocr_mac.py
from transformers import AutoModel, AutoTokenizer
import torch, os
model_name = "deepseek-ai/DeepSeek-OCR"
image_file = "test.jpg" # 入力画像
output_path = "/Users/yutennnnn/DeepSeek-OCR/outputs" # 出力先
# 1) モデル読み込み(flash-attn 等のCUDA専用指定は付けない)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
use_safetensors=True,
).eval()
# 2) デバイスを選択(M1/M2/M3 なら mps、無ければ cpu)
device = "mps" if torch.backends.mps.is_available() else "cpu"
model = model.to(device)
# 3) dtype:まずは安定の float32。速さが欲しければ試験的に float16 へ
# (未実装opがあると落ちることがあるので最初は float32 が無難)
dtype = torch.float32
model = model.to(dtype)
# 4) プロンプト(Markdown化の例)
prompt = "<image>\n<|grounding|>Convert the document to markdown."
# 5) 軽め設定で(重ければ 512、速さが欲しければ 1024)
os.makedirs(output_path, exist_ok=True)
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path=output_path,
base_size=640, # Tiny/Small 相当で軽くしておきます
image_size=640,
crop_mode=False, # まずネイティブ解像度。高密度紙面なら True にしてタイル化
save_results=True,
test_compress=True,
)
print("Done. See:", output_path)上記の通りmacOSではCUDAを使わずに基本的にCPU実行となるので、環境次第ではかなり実行に時間がかかる可能性があります。
モード(解像度とトークン数)の選び方
DeepSeek-OCRは、用途に応じてモードを切替えられます。
解像度の例として Tiny(512×512 / 64 vision tokens), Small(640×640 / 100), Base(1024×1024 / 256), Large(1280×1280 / 400) が用意されていて、より高密度な紙面にはGundamが適しています。Transformers経由で指定する場合は、基本的には base_size / image_size と crop_mode の組み合わせでモード相当の設定ができます(上記のコードはGundamの例です)
vLLM経由での使い方
DeepSeek-OCRは、同梱されている「vLLM向けスクリプト」を使うと大量ページや長いPDFでも高速に回すことができます。
まずはPython環境を用意しましょう。公式では「cuda11.8 + torch2.6.0」が前提にされています。インストールコマンドは次のとおりです。
# リポジトリ取得と仮想環境
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
cd DeepSeek-OCR
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
# PyTorch(CUDA 11.8向け)と依存パッケージ、vLLM、FlashAttention を導入
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
# vLLM 0.8.5 の whl を取得してから(READMEのリンク先にあります)、パスを指定してインストール
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
ここで注意ですが、PyTorchはmacOS Intel(x86_64) 向けの配布を 2.2 系で終了しており、2.3 以降(今回必要な2.6も)のホイールは存在しないので、macOS環境の場合は、Transformers経由で実行するようにしましょう。
次に、vLLM用の設定ファイルを1か所だけ修正します。
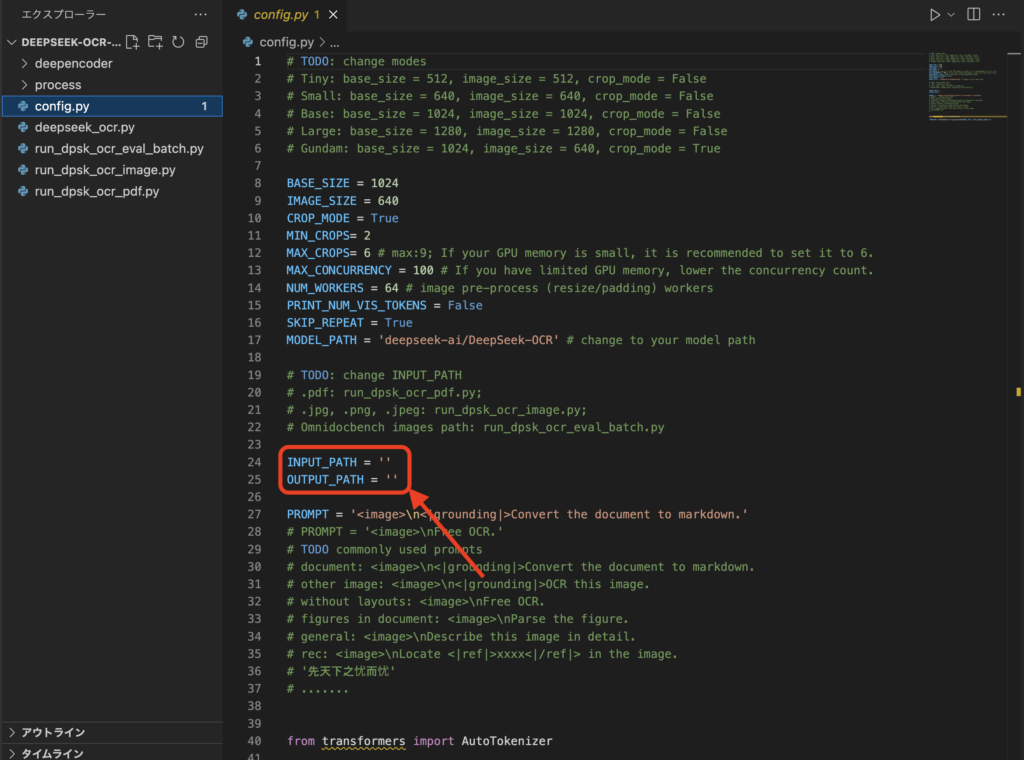
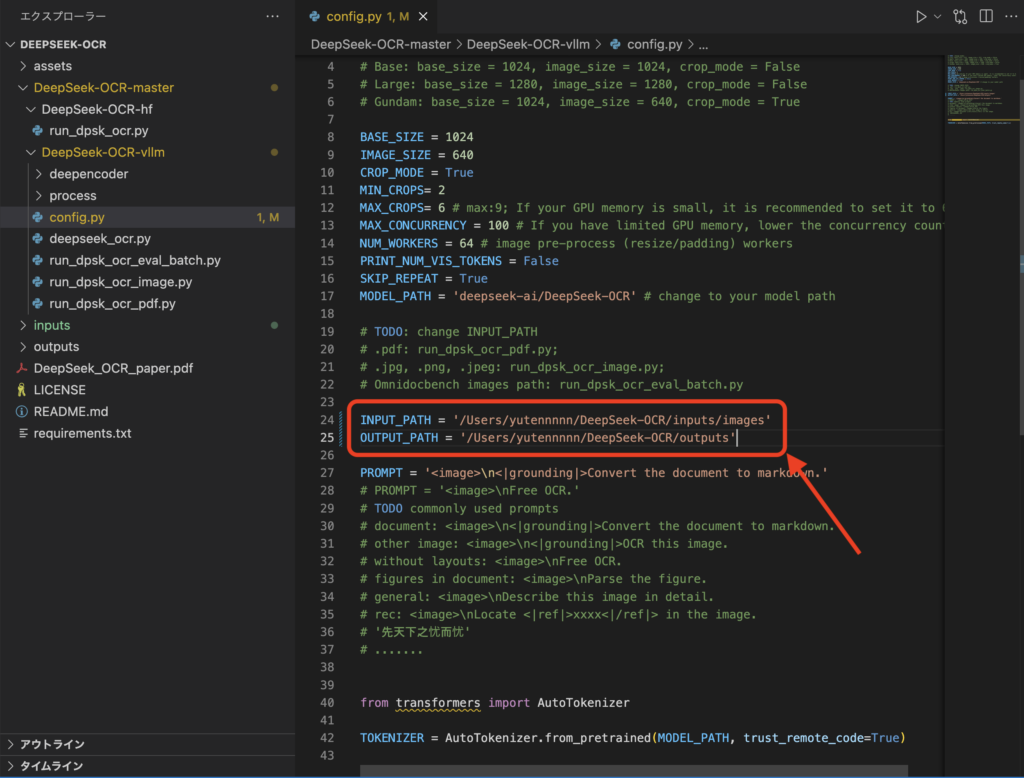
DeepSeek-OCRリポジトリ内の DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py に、入力フォルダと出力フォルダなどの基本設定がまとまっています。
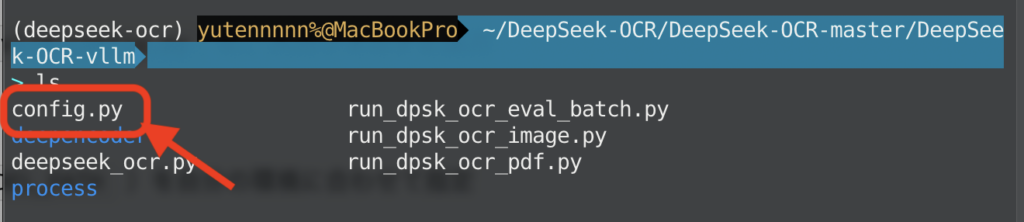
まずはここでINPUT_PATH と OUTPUT_PATH(場合によっては MODEL_PATH)を自分の環境に合わせて指定します。その際、以下のコマンドでinputsディレクトリとoutputsディレクトリを作っておきましょう。
mkdir -p ~/data/deepseek_ocr/inputs/images
mkdir -p ~/data/deepseek_ocr/inputs/pdfs
mkdir -p ~/data/deepseek_ocr/outputs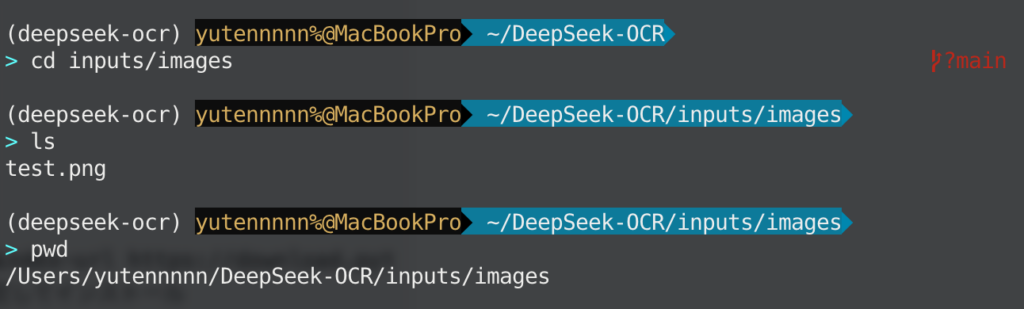
また、インプット用画像として、以下のようなテキストが多く書かれた画像を用意します。
準備ができたら、vLLM向けディレクトリに移動して実行します。画像のストリーミング出力実行コマンド例は下記の通りです。
cd DeepSeek-OCR-master/DeepSeek-OCR-vllm
python run_dpsk_ocr_image.pyWindowsの方はこれで実行ができるものと思われます。
以上、Transformers経由とvLLM経由の使い方の紹介でした。


まとめ
DeepSeek-OCRは、長文テキストを効率よく処理するための新たなアプローチが特徴のモデルです。
ただ文字を読むOCRに留まらず、ページ全体を理解してMarkdownや構造化データに落とし込むその出力は、ドキュメントデータの利活用を大きく前進させてくれる可能性があります。
今後、このアプローチがさらに洗練され他のモデルにも波及していくことで、より効率的で人間らしい記憶システムを備えたAIが登場するかもしれません。
DeepSeek-OCRが切り開いた光学的圧縮の道筋は、まさに次世代のAIドキュメント理解の可能性を感じさせるものです。
気になる方はぜひ一度試してみてください。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


