
Apple「Depth Pro」GPUメモリを消費せず1秒で深度推定できるオープンソース!

Appleが2024年10月4日にDepth Proをリリース!
Depth Proはたった1枚の画像から、奥行き情報を高速で高精度で推定するモデルです。従来手法では難しかったカメラの内部パラメータなしで、正確な奥行きの推定や毛皮・髪の毛などの細かい構造の補足が可能となりました。
Depth Proは高解像度の深度マップをたった0.3秒で生成が可能です。
本記事では、Depth Proの詳しい情報やgoogle colaboratoryでの実装方法をお伝えします。本記事を最後まで読むことで正確な奥行きの推定が可能になります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Depth Proの概要
Depth ProはAppleが新たにリリースしたAIモデル。任意の画像に対して、高精細な計量モノキュラー深度推定を行います。
従来手法よりも遥かにシャープで高周波の詳細を含む深度マップを生成し、カメラの内部パラメータなどのメタデータに頼ることなく、絶対スケールで計量深度マップを生成。
さらに、標準的なGPUで2.25メガピクセルの深度マップを0.3秒で生成できるため、高速な処理が可能です。
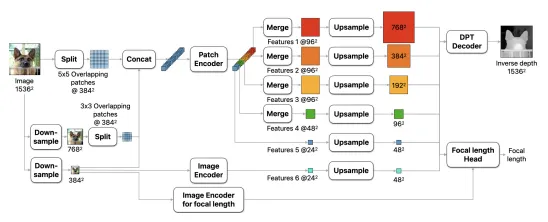
Depth Proは、高精細な深度マップを生成するための、高効率なマルチスケールビジョンTransformerベースのアーキテクチャ、深度マップの境界精度を評価するための専用の評価指標、境界の鋭さを促進する損失関数とトレーニングカリキュラム、単一画像からの最先端の焦点距離推定など、いくつかの技術的の向上によって実現されています。

計量モノキュラー深度推定
計量モノキュラー深度推定(Monocular Depth Estimation)は、単眼深度推定ともいい、1つのカメラ(モノキュラー)から得られる単一の画像を使用して、シーン内の物体の深度(距離)を推定する技術です。
通常、深度推定は2つのカメラ(ステレオカメラ)やレーザー測定(LiDAR)などを用いることで精度を高めることが一般的ですが、モノキュラー深度推定では1枚の画像だけを使うため、ハードウェアのコストを抑えるメリットがあります。
例えば、AIやディープラーニングを用いて訓練されたモデルが、物体の形や背景の情報をもとにして、各ピクセルごとの距離を推定します。これにより、カメラから見たシーン全体の奥行きを推定できるため、ロボットや自動運転車などが周囲の環境をより正確に認識できるようになります。
深度推定には、次のような用途があります
- 自動運転車やドローンでの障害物回避
- AR(拡張現実)やVR(仮想現実)での環境とのインタラクション
- 3Dモデリングやシーン再構築
ただし、モノキュラーでの深度推定は、ステレオやLiDARなどの多視点データに比べて情報が少ないため、特に計量的な正確性を保つのが難しい課題です。そのため、モデルの訓練には大量のデータと高度なアルゴリズムが必要になります。
Depth Proと他の深度推定モデルと比較
Depth Proは、他の深度推定モデルと比較して、次のような特徴があります。
- ゼロショットメトリック深度推定における最先端の精度: これは、カメラの固有パラメータ(焦点距離など)を必要とせずに、任意の画像に対して絶対スケールでメトリック深度マップを生成できることを意味します。 このような特性により、Depth Proは、単一画像からの新規ビュー合成など、正確な形状、サイズ、距離を必要とするダウンストリームアプリケーションに適しています。
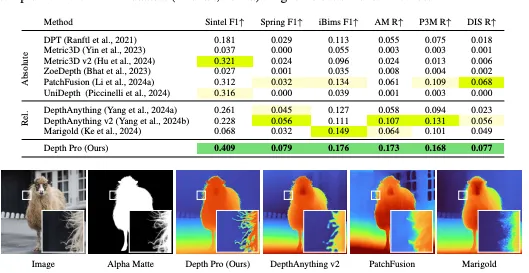
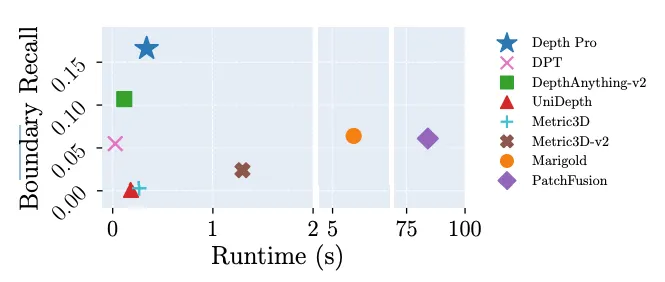
- 境界のトレースに優れる:Depth Proは、毛や毛皮などの細かい構造を含め、オブジェクトの境界を非常に鮮明に描写。 論文によると、Depth Proは、境界の再現率において、従来のすべての研究を大幅に上回っています。
- 高解像度(2.25メガピクセル)で動作:Depth Proは詳細な深度マップを生成。 これは、新規ビュー合成などのアプリケーションで画像品質を低下させる可能性のある「フライングピクセル」の発生を抑制するのに役立ちます。
- 高速:Depth Proは標準GPUで0.3秒以内に2.25メガピクセルの深度マップを生成。 これは、MarigoldやPatchFusionなど、きめ細かい予測に焦点を当てた従来手法よりも非常に高速です。
- 画像の焦点距離を推定:Depth Proは、画像から焦点距離を直接推定することで、不正確または欠落している可能性のあるEXIFメタデータに対処。 論文によると、Depth Proは、クロスドメインの焦点距離推定タスクにおいて、従来技術を大幅に上回る性能を発揮します。
これらの特徴をまとめると、Depth Proは、特に単一画像からの新規ビュー合成など、高精度、高解像度、高速処理が求められるアプリケーションに適した汎用性の高い単眼深度推定モデルと言えます。
Depth proの技術
従来の深度推定モデルに比べ性能が向上しているDepth proですが、それを可能にしている技術がいくつかあります。
- 高密度予測のための効率的なマルチスケールViTベースのアーキテクチャ:グローバルな画像コンテキストを捉えながら、高解像度で細かい構造にも対応するように設計された、Depth Proの基盤となるアーキテクチャ。このアーキテクチャは、複数のスケールで抽出されたパッチに単純なViTエンコーダを適用し、これらのパッチ予測を単一の高解像度な高密度予測に融合する、エンドツーエンドで学習可能なモデルです。つまり、このモデルは、画像の異なるスケール(サイズ)で情報を処理し、それらを組み合わせて詳細な深度マップを作成します。
- 推定された深度マップの境界精度を評価するための専用の評価指標:Depth Proの開発者は、深度マップの境界精度を評価するための新しいメトリクスセットを作成。従来の単眼深度予測のベンチマークでは、境界の鮮明さが考慮されていないことが多くありました。これは、高精度なピクセル単位のground truthを持つデータセットの不足が原因で、この問題に対処するために、Depth Proの新しいメトリクスセットは、マッティング、顕著性、またはセグメンテーション用の既存の高品質なアノテーションを深度境界のground truthとして活用。これは、ground truth深度を取得することが不可能な複雑で動的な環境や非常に細かいシーンでも評価を可能にするという点で、大きな技術的改善です。
- 境界の鮮明な深度推定を促進する損失関数とトレーニングカリキュラム:Depth Proのトレーニングプロセスは、鮮明な深度推定を促進するように設計。これは、境界付近の教師データが粗く、不正確なことが多い現実世界のデータセットと、ピクセル単位で正確なground truthを提供するが、リアリズムが限定的な合成データセットの両方で学習しながら行われます。Depth Proは、2段階のトレーニングカリキュラムを採用。第1段階では、現実世界のデータセットと合成データセットの両方を使用して、スケールとシフトに不変の損失関数でトレーニングを実施します。第2段階では、高品質なピクセル単位のground truthを提供する合成データセットのみを使用して、境界をシャープにし、予測された深度マップの細部を明らかにして、境界をより鮮明にするように調整しています。
- 単一画像からの最先端の焦点距離推定:Depth Proは、画像に不正確または欠落している可能性のあるEXIFメタデータに対処するために、焦点距離推定ヘッドを備えています。小さな畳み込みヘッドが、深度推定ネットワークからのフリーズされた特徴と、別のViT画像エンコーダからのタスク固有の特徴を取り込み、水平視野角を予測。焦点距離のトレーニングは、深度ネットワークのトレーニングとは別に、異なるトレーニングセットを使用して行われます。これは、深度推定と焦点距離推定のトレーニング目標のバランスをとる必要性を回避し、深度推定ネットワークのトレーニングで使用される一部の狭いドメインの単一カメラデータセットを除外し、焦点距離の教師データを提供するが深度の教師データは提供しない大規模な画像データセットを追加して、焦点距離ヘッドを異なるデータセットセットでトレーニングすることを可能にします。
Depth proのライセンス
Depth Proは基本的に改変や配布などが可能です。
Appleの商標やロゴを使って宣伝する場合、事前にAppleの書面での許可が必要。明示的な商用利用に関する記述がないため、商用利用が可能かどうかについては慎重に判断する必要がありますが、特別に禁止されているわけではありません。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | 不明 |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | 不明 |
| 私的使用 | ⭕️ |
なお、Appleが公開した画像生成AIのMatryoshkaについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Depth proの使い方
ここからは実際にDepth Proを実装します。サンプルコードはGitHubにも掲載されていますが、google colaboratoryで実行するには一部変更が必要です。
google colaboratoryでDepth Proの実装
■Pythonのバージョン
Python 3.10以上
■使用ディスク量
38.4GB
■GPU RAMの使用量
0.0GB
■システムRAMの使用量
6.4GB
必要パッケージのインストールはこちら
# 必要なパッケージのインストール
!pip install torch torchvisionリポジトリのクローンはこちら
!git clone https://github.com/apple/ml-depth-pro.gitモデルのダウンロードはこちら
%cd ml-depth-pro
!bash get_pretrained_models.sh追加でパッケージのインストールはこちら
%cd /content/ml-depth-pro
!pip install -e .PYTHONPATHにディレクトリを追加はこちら
import sys
sys.path.append('/content/ml-depth-pro/src')サンプルコードはこちら
from PIL import Image
import torch
import depth_pro
# モデルと前処理の読み込み
model, transform = depth_pro.create_model_and_transforms()
model.eval()
# 画像のロードと前処理
image_path = './data/example.jpg'
image, _, f_px = depth_pro.load_rgb(image_path)
image = transform(image)
# 推論の実行
with torch.no_grad():
prediction = model.infer(image, f_px=f_px)
depth = prediction["depth"]
focallength_px = prediction["focallength_px"]
# 結果の表示
import matplotlib.pyplot as plt
plt.imshow(depth.squeeze(), cmap='viridis')
plt.colorbar(label='Depth (m)')
plt.show()これでDepth Proを使うことができます。GPUメモリを消費しないのでgoogle colaboratoryの無料版でも実装可能かもしれません。
また、標準的なGPUで2.25メガピクセルの深度マップを0.3秒で生成できると論文には記載されていますが、サンプル画像をgoogle colaboratoryで深度推定した時は実行終了するまでに40秒ほどかかりました。もしかしたら生成はできるけど、それ以外の処理が長いもしくは環境の影響があるのかもしれません。
Depth proと従来の深度推定モデルを比較
深度推定モデルはこれまでいくつかリリースされているので、従来の深度推定モデルとDepth Proを比較してみたいと思います。また、動画の深度推定が可能なので、ここでは動画の深度推定を行なっていきます。
今回比較する従来の深度推定モデルは次の2つです。
Depth Proで動画の深度推定をするには、一度フレームごとに静止画にして深度推定後にフレームを重ね合わせて動画にする必要があります。
ライブラリのインポートなどは画像の時と一緒なので、フレームごとに深度推定をするコードからです
動画のフレーム分けはこちら
import cv2
import os
# 動画をアップロード
video_path = '.mp4' # 動画ファイルのパス
output_dir = '/content/frames/' # フレームを保存するディレクトリ
# ディレクトリ作成
os.makedirs(output_dir, exist_ok=True)
# 動画を読み込み
cap = cv2.VideoCapture(video_path)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
frame_interval = 10 # 10フレームごとに保存
success, frame = cap.read()
count = 0
saved_count = 0
while success:
if count % frame_interval == 0: # frame_intervalごとにフレームを保存
cv2.imwrite(os.path.join(output_dir, f"frame_{saved_count:05d}.jpg"), frame)
saved_count += 1
success, frame = cap.read()
count += 1
cap.release()
print(f"Extracted and saved {saved_count} frames from {count} total frames.")
推論の実行はこちら
import torch
import depth_pro
from PIL import Image
import glob
import os
import matplotlib.pyplot as plt # 追加
# モデルと前処理の読み込み
model, transform = depth_pro.create_model_and_transforms()
model.eval()
# フレームごとに深度推定を実行
frame_paths = sorted(glob.glob(output_dir + '*.jpg'))
depth_output_dir = '/content/depth_frames/' # 深度フレームを保存するディレクトリ
os.makedirs(depth_output_dir, exist_ok=True)
for frame_path in frame_paths:
# 画像をロードして前処理
image, _, f_px = depth_pro.load_rgb(frame_path)
image = transform(image)
# 推論実行
with torch.no_grad():
prediction = model.infer(image, f_px=f_px)
depth = prediction["depth"]
# 深度を画像として保存
depth_image_path = os.path.join(depth_output_dir, os.path.basename(frame_path))
plt.imsave(depth_image_path, depth.squeeze().numpy(), cmap='viridis')
print(f"Depth estimation completed for {len(frame_paths)} frames.")
動画として保存するコードはこちら
import cv2
import glob
# フレームのパスを取得
depth_frame_paths = sorted(glob.glob(depth_output_dir + '*.jpg'))
# 動画として保存
output_video_path = '/content/depth_video.mp4'
frame = cv2.imread(depth_frame_paths[0])
height, width, layers = frame.shape
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video = cv2.VideoWriter(output_video_path, fourcc, 30.0, (width, height))
for frame_path in depth_frame_paths:
video.write(cv2.imread(frame_path))
video.release()
print(f"Depth video saved to {output_video_path}")動画のダウンロードはこちら
from google.colab import files
files.download(output_video_path) # ダウンロードリンクを表示動画を若干無理やり深度推定しているので、チラつく感じはありますが、Depth Proでも動画の深度推定が可能でした。ただ、GitHubやHuggingFaceには動画のコードは掲載されていないので、あくまでもDepth Proは画像の深度推定に使うのがいいかもしれません。
深度推定のクオリティも画像の方が高い印象を受けます。
なお、画像内の距離感を正確に理解できるAI Depth Anythingについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではAppleがリリースしたDepth Proについて、google colaboratoryでの使い方も踏まえて詳しく紹介しました。正確かつ高速に深度推定ができるDepth Proは今後、さまざまな分野での活用が期待されます。
ぜひ本記事を参考にDepth Proを使ってみてくださいね!

最後に
いかがだったでしょうか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。


