
【Ferret-UI】Appleが開発したスマホ専用のマルチモーダルAI

WEELメディア事業部LLMリサーチャーの中田です。
4月9日、スマホのUI(画面)を理解するのに特化したマルチモーダル大規模言語モデル(MLLM)である「Ferret-UI」を、Appleが公開しました。
従来のマルチモーダルモデルと違って、スマホ画面の内容を理解し、スマホ操作のための適切な指示を出せるんです!
Ferret-UI関連の、Xでの投稿のいいね数は、すでに2000を超えており、かなりバズっていることが分かります。
この記事では、Ferret-UIの仕組みや凄さを解説します。本記事を熟読することで、Ferret-UIの凄さを理解できるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Ferret-UIはスマホ画面の理解に特化したマルチモーダルモデル
Ferret-UIは、スマホ画面のUIを理解するために特化したマルチモーダル大規模言語モデル(MLLM)です。
例えば、以下のようなスマホの画面において、画面内に移る細かいアイコンを認識したり、スマホ操作を支援したりできます。

開発元のAppleはもともと、一般的な画像の理解に特化したマルチモーダル言語モデル「Ferret」を開発しています。今回のFerret-UIは、そのFerretをベースにしており、スマホ関連のタスクに特化させたのだとか。
Ferret-UIの凄さとは?
Ferret-UIの凄さは、リファリング・グラウンディングの能力を備え、スマホ関連の高度なタスクで優れたパフォーマンスを示したことです。
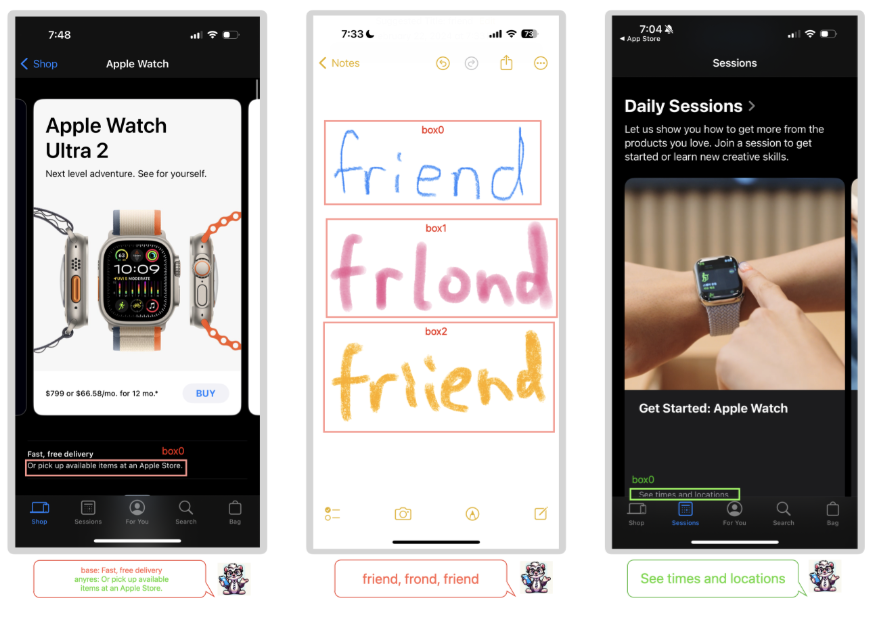
ここでのリファリング(Referring)とは、入力されたスクリーン画像の特定の領域の情報を活用する能力のことを指します。例えば、以下の通りです。
- 指定された領域のテキスト認識
- 指定されたアイコンの種類の識別
- 指定されたUI要素のウィジェットタイプ分類
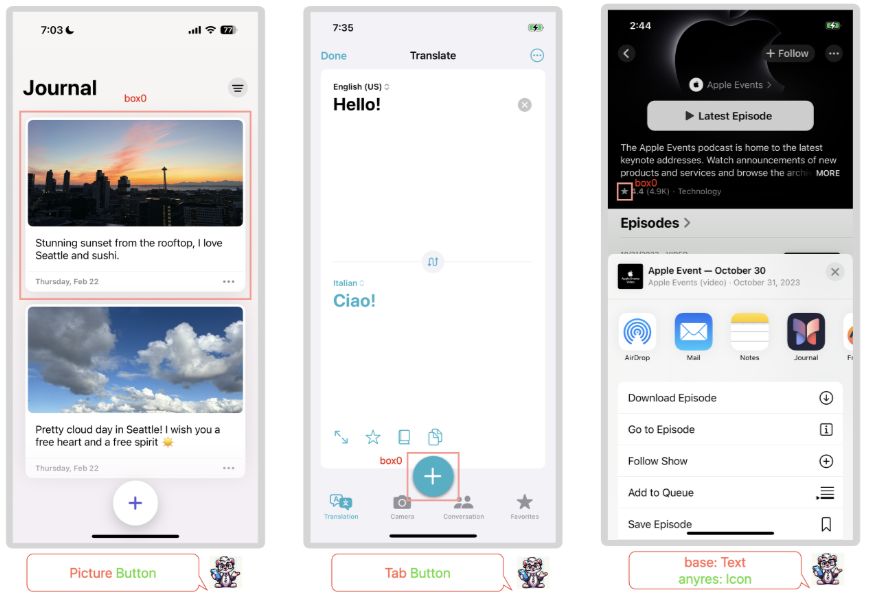
また、グラウンディング(Grounding)とは、出力においてスクリーン上の特定の位置を指し示す能力のことを指します。例えば、ユーザープロンプトで指定されたオブジェクト(テキスト、アイコン、ウィジェットなど)を画面上で見つけ出し、その正確な位置を座標などで出力できます。
Appleが開発したマルチモーダル大規模言語モデルについては、下記の記事を合わせてご確認ください。
→【Ferret】Appleが開発したマルチモーダル大規模言語モデルの使い方〜実践まで
Ferret-UIはGPT-4Vよりも基礎タスクで高い性能を示した
基本的なUI認識タスクや高度なタスクにおいて、GPT-4Vなどと比較した結果、Ferret=UIは多くのタスクで優れた結果を示しています。
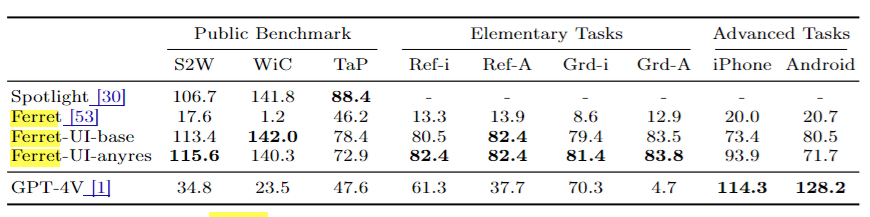
また、基本的なタスクに関しては、Ferret-UIは他モデルと比べて、高い性能を達成しています。
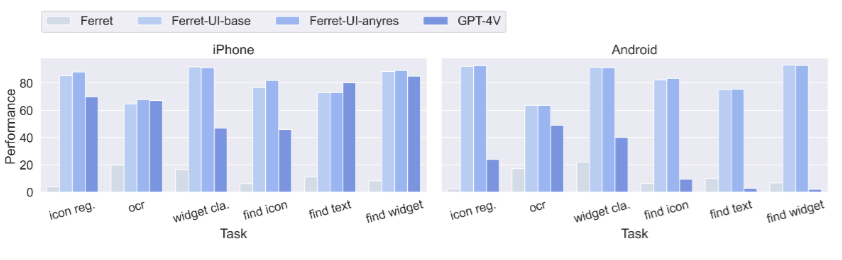
ただ、高度なタスクにおける性能に関しては、GPT-4Vの方が高かったようです。
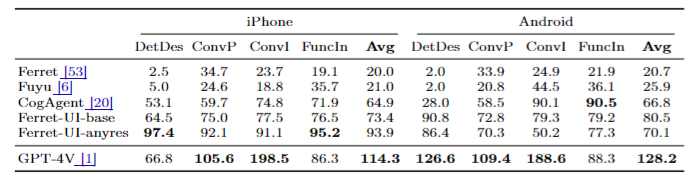
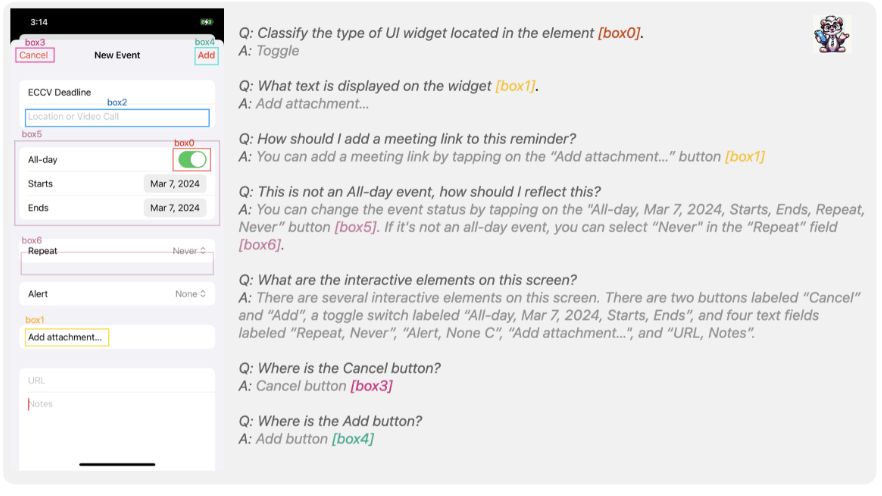
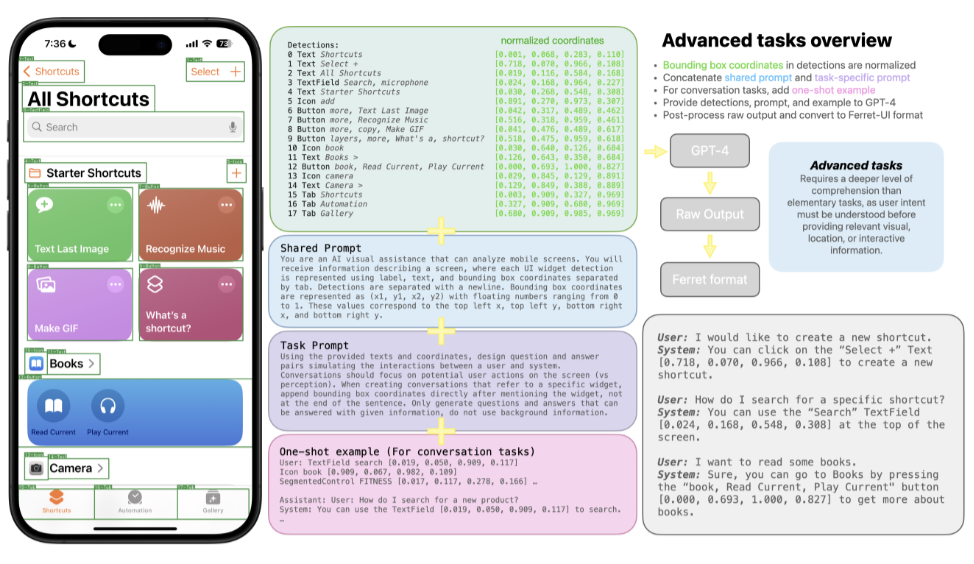
ちなみに、この「高度なタスク」では、以下の図の様に、スマホ画面の画像を各LLMに入力し、その画像に関する質問をテキストプロンプトで入力し、その出力を比較しています。
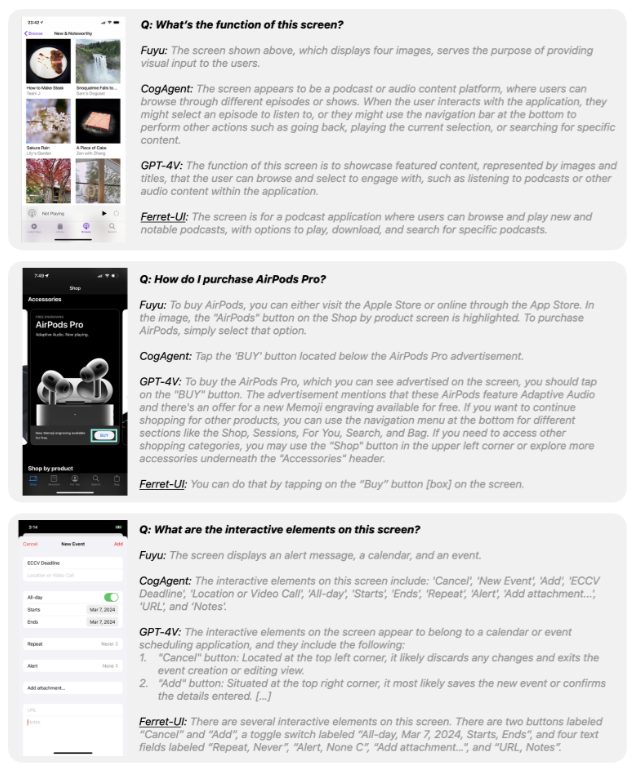
とはいえ、上記の会話タスクの精度に関してはGPT-4を使って評価されており、GPT-4Vの方が評価モデル(GPT-4)との相性が良くなるため、Ferret-UIよりも精度が高かったとされています。
また、GPT-4Vの方が「質問に直接関係のない余分な情報」も含めて詳細に回答する傾向があるため、会話タスクのような「高度なタスク」において、必ずしも「Ferret-UIよりもGPT-4Vの方が良い」と断言できないとのこと。

Ferret-UIのモデル構造
先述の通り、Ferret-UIのモデル構造は、Appleが開発したマルチモーダルモデル「Ferret」をベースに構築されています。
Ferret-UIのモデル構造の概要は、以下の通りです。
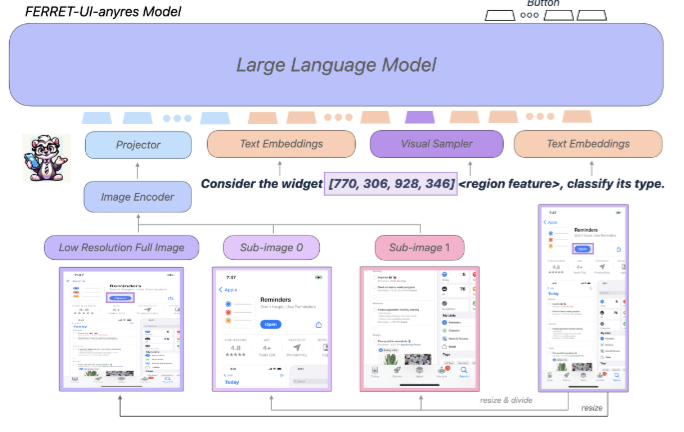
具体的には、any resolutionという手法で、入力画像をリサイズした後に画像をエンコードし、その情報をLLMに送っています。
Ferret-UIの「any resolution」とは?
Ferret-UIの「any resolution」は、モバイルUIスクリーンの認識能力を強化するために導入された手法です。
UIスクリーンは自然画像に比べてアスペクト比が長く、アイコンやテキストなどの対象物が小さい傾向にあり、従来の画像処理を適用すると、認識能力が失われてしまう可能性があります。
そこでFerret-UIでは、元のスクリーンのアスペクト比に基づいて「2つのグリッド設定(1×2と2×1)」を選択し、スクリーンをサブ画像に分割する「any resolution」という手法を取り入れたのです。
具体的には、以下のように処理されます。
- 縦長の画面は水平に、横長の画面は垂直に2分割
- 同一の画像エンコーダを用いて、分割されたサブ画像を別々にエンコード
この工夫により、UIスクリーンの細かい部分の特徴もしっかりと捉えるようなるのだとか。そうして、アイコンやテキストなどの小さな要素をより正確に認識し、UIの理解と操作の性能が向上するそうです。
複数モデルを組み合わせて作られたマルチモーダル言語モデルについては、下記の記事を合わせてご確認ください。
→【EvoVLM-JP】存在しない最強のAIモデルを作れるSakana AIの「進化的アルゴリズム」を徹底解説!
Ferret-UIを使ってできること
Ferret-UIを用いることで、スマホ画面に映る各要素や、スマホ画面の内容をLLMに説明させることが可能になります。
もし、Ferret-UIが実用化されれば、スマホの画面を見なくても、画面に表示されている内容をAIが教えてくれるでしょう。さらに、スマホアプリを開発する際、Ferret-UIにUIを読み込ませることで、アプリの画面の分かりやすさや使いやすさに繋げることも可能になるでしょう。
加えて、iPhoneに搭載されている「Siri」と組み合わせることで、より高度なスマホの自動化も可能になるかもしれません。
Apple社も開発に携わっているマルチモーダルAIの学習フレームワークについては、下記の記事を合わせてご確認ください。
→【4M】Apple開発のマルチモーダルAI訓練用フレームワークの仕組みを徹底解説
Appleのスマホ技術とFerret-UIとの融合に期待
本記事では、スマホ画面の理解に特化したマルチモーダルモデル「Ferret-UI」という、Appleの研究について解説しました。
現状、Ferret-UIの学習は、UIの検出モデルに依存しているため、色、デザイン、ユーザビリティなどを認識できないとのこと。また、タップ以外のスクロールや長押しなどの操作は、認識できないとのこと。
そこで、今後の研究では、より多様なUIデザインや操作に対するFerret-UI認識能力を高めるための方法を、模索していくと述べられています。
ちなみに、X上では、スマホの自動操作への期待や、Siriとの連携に関する声も挙がっています。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

