
フルスタックリサーチエージェントGemini Fullstack LangGraph|概要や性能・使い方まで徹底解説

- Gemini 2.5シリーズとLangChain/LangGraphを融合させたリサーチエージェント
- 検索クエリの自動生成からウェブ調査、ギャップ分析、回答生成までを一気通貫で実装
- Apache 2.0ライセンスで公開、商用利用や改変は基本的に自由
2025年6月3日、GoogleはGemini 2.5シリーズとLangChain/LangGraphを融合させた公式テンプレート「Gemini Fullstack LangGraph」をオープンソースで公開しました!
Geminiモデルの高精度な推論力とLangGraphの柔軟なエージェント制御をワンパッケージで体験できるGemini Fullstack LangGraphは、検索クエリの自動生成からウェブ調査、ギャップ分析、回答生成までを一気通貫で実装しており、「研究開発を加速するデモ」から「実務投入可能な骨格」へと進化している点が大きな特徴です。
公開からわずか数日でGitHub 2,000star超えを記録しており、LLMエンジニアの間で話題を呼んでいます。
本記事では、Gemini Fullstack LangGraphの概要や性能、使い方まで徹底的に解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Gemini Fullstack LangGraphの概要
Gemini Fullstack LangGraphは、React製フロントエンドとLangGraphを利用したPython/FastAPIバックエンドを組み合わせたフルスタックなリサーチエージェントです。
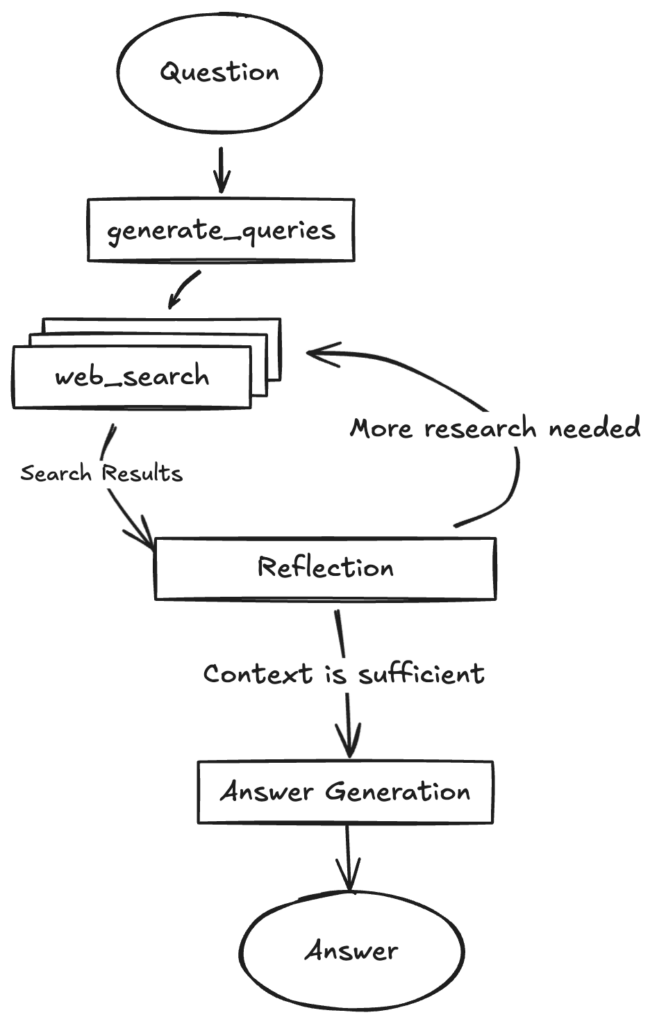
バックエンド側では、LangGraphのStateGraphを用いて「検索クエリ生成→Google Custom Search→結果の反省→不足情報の再検索→最終回答作成」という多段階フローをノードとして定義し、Redisでストリーミングしながら Postgresに永続化します。
フロントエンドは、チャットUIと進捗ストリームが備え付けられており、開発中はホットリロード、プロダクションでは最適化ビルドを同一コンテナで配信するような構成になっています。
Apache 2.0ライセンスのため改変・再配布も自由で、Gemini API KeyとGoogle Search API Keyを用意すればローカル実行をすることも可能です。


Gemini Fullstack LangGraphの特徴
Gemini Fullstack LangGraphの1番の魅力は「深掘り型エージェント」が標準搭載されている点です。
単発のプロンプト対話ではなく、回答に裏付けとなる根拠が不足していれば、自律的に追加検索を繰り返し、信頼度の高い回答と出典リンクを返してくれます。
この設計思想はGoogle社内で研究されている “Deep Research Agent” の縮図と評されており、情報探索系SaaSのベースにも転用しやすい点が何よりの魅力です。
特徴の2つ目として、LangGraphのノード/エッジをコードで定義するだけで、マルチツール呼び出しや条件分岐が実現でき、Vertex AI SDKのLanggraphAgentクラスとも互換性があるため、のちのクラウド移行が容易となっています。
そして3つ目が、フロントとバックを分離せずDocker1つで立ち上がるため、導入が速い点も実務的メリットです。
Redis Pub/Subによりトークン単位でストリーム配信されるため、長文出力でも UI がブロックされません。こうした開発効率とユーザー体験を両立した設計がGemini Fullstack LangGraphの真骨頂です。

Gemini Fullstack LangGraphの性能
Gemini Fullstack LangGraphそのものはテンプレートであり、基本的な性能は、呼び出すGemini 2.5 Pro/Flashに依存します。
最新のLegalBench 2025-05-30では、Gemini 2.5 Pro Expが83.6%の正答率で首位を獲得し、推論レイテンシは平均3.5 秒、コストは入力1M tokenあたり1.25 USDと報告されています。
Gemini Fullstack LangGraphは、このモデルを複数ステップで繰り返し呼び出すため、総レイテンシは「検索回数 × モデル応答時間 + ネットワーク遅延」で概算できます。
デフォルト設定(最大ループ3回)で平均9〜12秒、ストリーム開始は1秒以内という実測報告がコミュニティに上がっており、実用上の待ち時間は十分許容範囲となっています。
開発ビルド時のメモリフットプリントはフロント+バック併せて800 MB程度、CPU使用率はアイドル状態で3%前後、負荷時は単発60%程度と軽量です。
また、LangGraph Cloudを併用すると10k traceまでは無料、以降は0.50 USD/1k traceで水平的にスケールできるため、小規模PoCから商用移行まで段階的に拡張することができます。
Gemini Fullstack LangGraphのライセンス
Gemini Fullstack LangGraphは、Apache 2.0 ライセンスで公開されており、商用利用や改変は基本的に自由です。
ただし、実行時に使用するGemini APIはGoogle AI for Developers規約に従う必要があり、生成物の安全性チェックにも留意しなければなりません。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 私的利用 | ⭕️ | |
| 特許利用 | ⭕️ | ※1 |
※1…Apache 2.0は特許使用許諾を含みますが、Gemini APIの出力物についてはGoogle側が特許を保証するわけではありません。自社特許と絡めた派生開発を行う場合、生成物の帰属とライセンス相互作用を必ず法務部と確認するようにしましょう。
Gemini Fullstack LangGraphの料金プラン
Gemini Fullstack LangGraphの導入自体にはライセンス料はかかりませんが、運用コストは「① Gemini API トークン」「② LangGraph Cloud のトレース」「③ Google Programmable Search のクエリ」という3つの従量課金が主軸になります。
無料枠だけでも、プロトタイプ検証を数100回分までは十分に賄えますが、多段検索エージェントを本番投入するとトークン消費は急増する点に注意しましょう。
| 項目 | 無料枠 | 従量課金 | 備考 |
|---|---|---|---|
| Gemini 2.5 Pro API | 入力6万/出力6万 トークン/月 | 入力1.25USD/100万トークン 出力5USD/100万トークン | 128kトークンを超えるプロンプトは2倍料金 |
| LangGraph Cloud(Base Trace) | 1万トレース/月 | 0.50USD/1千トレース | 保持期間14日。Extended Traceは 5USD/1千トレース |
| Google Programmable Search | 100クエリ/日 | 5USD/1千クエリ | JSON API版も同額。日次上限は 10kクエリ |
Geminiの入出力トークン課金がコストの大半を占めており、LangGraph Cloudはトレースをフル保存しない限りは影響は小さいことが分かります。
検索費用も1kクエリ当たり5USD と小さめですが、深掘りエージェントが1リクエスト内で数十回検索する設計にすると雪だるま式に増えます。
推論コストを抑えるには「① Flash モデルで粗い下書きを生成 → ② 必要部分だけ Pro で高精度仕上げ」や「再検索ループがゼロなら即終了」といったロジックを入れるのが有効かと思います。


Gemini Fullstack LangGraphの使い方
ここからはGemini Fullstack LangGraphの代表的な使い方を2つご紹介します。
Dockerで最速起動
ステップ1:まずターミナルを開き、以下コマンドで対象リポジトリを取得します。
git clone https://github.com/google-gemini/gemini-fullstack-langgraph-quickstart.gitステップ2:クローンしたフォルダーに移動(チェンジディレクトリ)し、.envファイルを新規作成して GOOGLE_AI_API_KEY と GOOGLE_SEARCH_API_KEY を貼り付けます。
API キーは Google AI Studio と Programmable Search の管理画面で無料枠で発行することができます。
ステップ3:Docker Desktopが起動していることを確認し、make dev(または docker compose up –build)を実行します。これだけでフロントエンド(Vite+React)とバックエンド(FastAPI+LangGraph)が同時にビルドされ、Postgres と Redisも内部ネットワークで立ち上がります。
ステップ4:数分後、ターミナルに localhost:5173 と表示されたらブラウザで開き、チャット欄に例えば「ロサンゼルスの観光名所を3つ教えて」と入力して動作確認します。入力直後にストリーム配信が始まれば成功です。
ステップ5:終了するときは Ctrl + C でプロセスを止め、不要になったイメージは以下コマンドで削除します。
docker compose down --volumes公式手順
ステップ1:以下コマンドでリポジトリを取得します。
git clone https://github.com/google-gemini/gemini-fullstack-langgraph-quickstart.git
cd gemini-fullstack-langgraph-quickstartステップ2:Gemini API キーを用意し .env に書きます。Google AI Studio で GEMINI_API_KEY を発行し、backend/ へ移動してサンプルをコピーします。
cd backend
cp .env.example .envコピーした .env をエディタで開き以下の形で保存します。
GEMINI_API_KEY="あなたのキー"
ステップ3:以下コマンドで依存ライブラリを入れます。
cd backend
pip install .cd ../frontend
npm install # yarn か pnpm でも可ステップ4:以下コマンドで開発サーバーを起動できればOKです。
make dev以上です。
他にもLangGraph Cloud(Waitlist登録必須)を利用する方法などもありますので興味のある方は覗いてみてください。
Gemini Fullstack LangGraphを使ってみた
ここからは実際にGemini Fullstack LangGraphを試していきましょう。
今回は使い方パートでご説明した公式手順の方法で進めていきます。
以下コマンドを実行して、画像の通りクローン完了できればOKです。
git clone https://github.com/google-gemini/gemini-fullstack-langgraph-quickstart.git
ここで、使い方パートに記載の通り仮想環境を作成しつつクローンしたディレクトリへ移動してください。ディレクトリ構成は以下画像の通り。

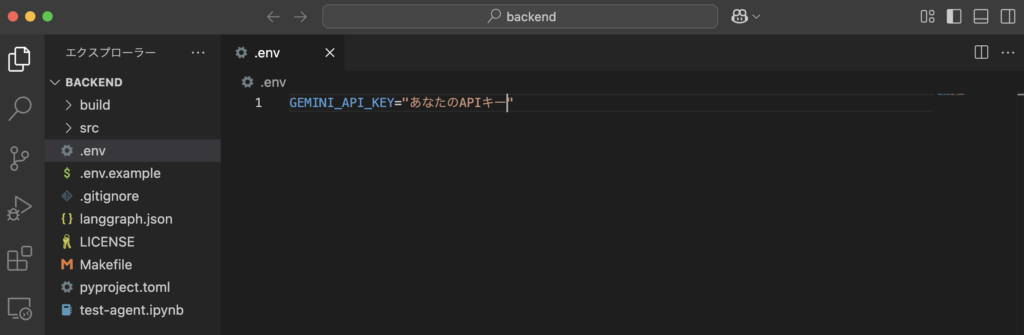
.envファイルにGemini APIキーを入力して保存します。
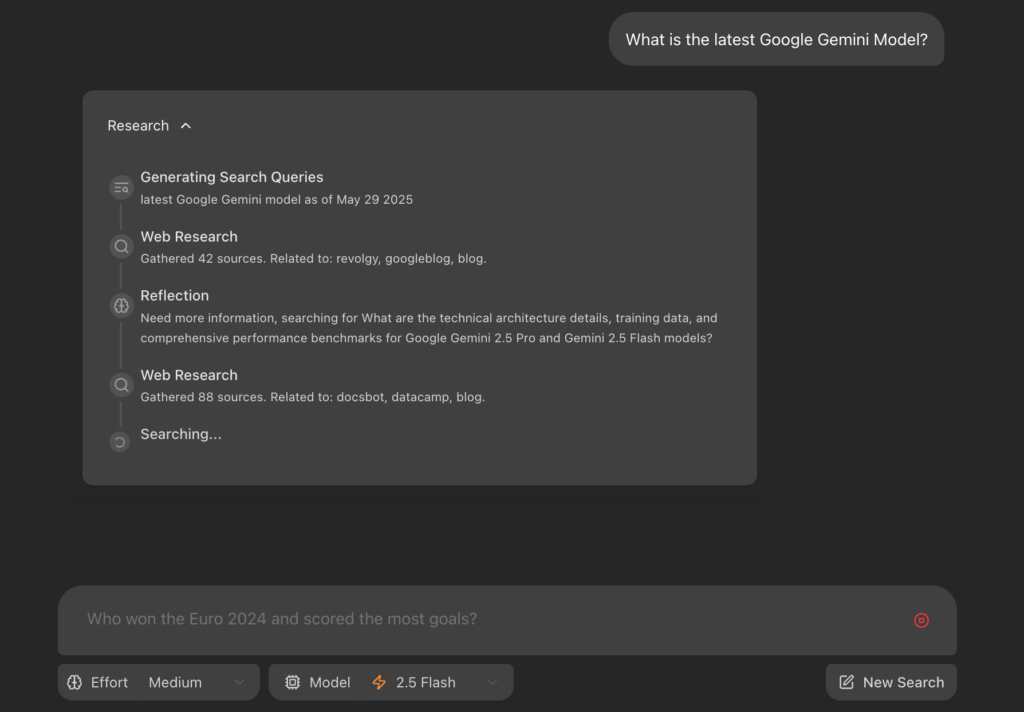
依存ライブラリをインストールし、make devコマンドを実行すると、以下画像のような実行結果が表示されます。
http://localhost:5173/app/ へブラウザからアクセスすれば以下画像の通りGemini Fullstack LangGraphの起動が完了です。
ひとまずプロンプトは何でもいいので挙動を確認してみましょう。
モデルはGemini 2.5 Flashです。
プロンプトはこちら
2025年版生成AI Passport試験に最短合格する方法を2,000文字でまとめ、参考文献をAPA形式で5本添えて実行直後に、ChatGPTやGeminiのDeep Research系統によくみられる「思考プロセス」が確認できました。Webリサーチ → 2,000文字出力でおよそ1分強ほどの所要時間でした。
完成テキストには脚注リンクもしっかり挿入されており、カーソルを当てると出典URLがツールチップ表示される点も秀逸で、ローカル環境で1分程度でこのレベルのアウトプットを出せるのはなかなか良いですね。
もう1つ、Geminiの強みであるコーディングタスクを試してみます。こちらもGemini 2.5 Flashモデルを使用します。
プロンプトはこちら
データ行を含む1行のCSV文字列を JSON文字列に変換する関数 to_json(csv_str: str) をPythonで書いて。標準ライブラリのみで、エラーハンドリング付き、docstringと簡単な使用例も添えて。最小構成で読みやすく、失敗してもエラー落ちしないような構成になっていますね。コピーしてそのまま業務スクリプトやJupyter Notebookなどに貼り付けても、ほぼ手直し不要で使えそうです。Geminiのコーディングの強さが出ていると感じます。
いかがでしょうか?ローカル環境でもWebリサーチしながらここまで精度高くアウトプットを一気通貫で出せるのは、Gemini Fullstack LangGraphの強みが出ていることを実感いただけたかと思います。
ぜひご自身の環境でも試してみてください。
まとめ
Gemini Fullstack LangGraphは、「検索特化エージェントを最速で試したい」というニーズに応える公式テンプレートです。
ReactとLangGraphの標準構成が用意されているため、クローン直後から本格的な研究ボットを動かすことができます。
また、Apache 2.0により商用利用もハードルが低く、LangGraph CloudとGemini APIの従量課金モデルを組み合わせればスモールスタートからスケールアウトまで段階的に拡張可能です。
ぜひ本記事を参考に最初は無料枠で試しつつ、プロンプトとノード構成を自社ユースケースに最適化していただければと思います!
最後に
いかがだったでしょうか?
生成AIは、単なる業務の自動化だけでなく、クリエイティブな業務支援や開発の効率化、社内DXの推進など、企業の多くの領域で活用できます。
貴社の事業にどう活かせるか、具体的な導入事例や最適な活用方法をご提案できますので、ぜひご相談ください。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


