
【Gemma 2】Llama 3を超えたGoogleのオープンLLM

WEELメディア事業部LLMリサーチャーの中田です。
6月27日、Googleがついに、研究者や開発者向けに最新LLM「Gemma 2」を公開しました。
MetaのLlama 3よりも性能が高く、ゲーミングノートPCからクラウドまで対応しているんです!
現在は9Bと27Bパラメータサイズのモデルが公開されており、Google AI Studioにおいて無料で利用可能です。
この記事ではGemma 2の使い方や、有効性の検証まで行います。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Gemma 2の概要
Gemma 2は、Googleが開発したLLMのGemmaの最新バージョンです。以前PaliGemmaが発表された時と同じタイミングで、「近いうちにGemma 2も公開する」と発表されていました。
Gemma 2の特徴
Gemma 2は、Googleの最先端のAIモデルであるGeminiと同じアーキテクチャを用いて構築されており、軽量でありながら高い性能を発揮します。
現在、以下の2つのモデルが公開されています。
- Gemma 2-9B
- Gemma 2-27B
特に270億パラメータモデルは、そのサイズクラスで最高の性能を発揮し、2倍以上の規模のモデルに匹敵する性能を実現しています。また、90億パラメータモデルも、同サイズの他のオープンモデル(Llama 3やGrok-1など)を上回る優れた性能を示しています。
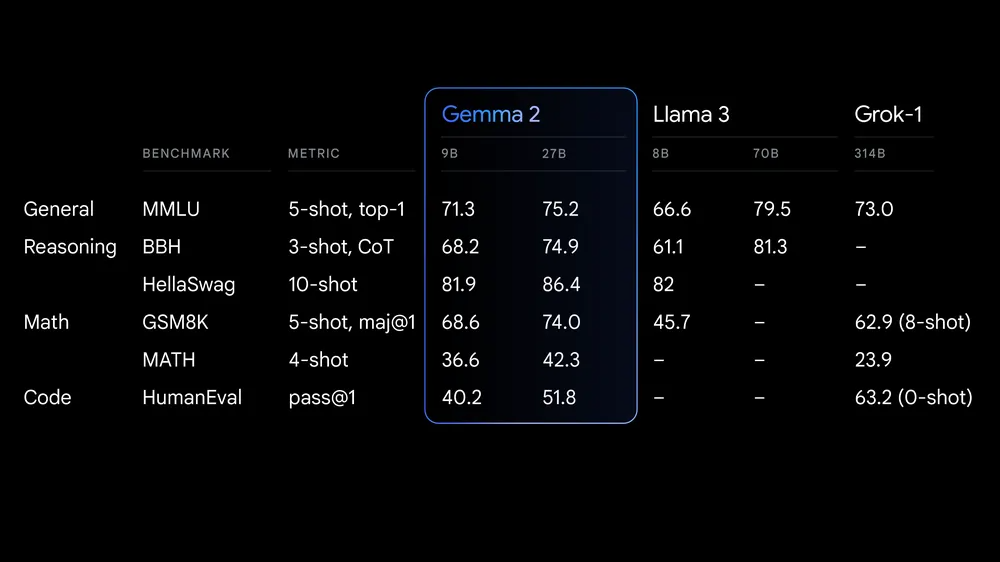
さらに、安全性と責任あるAI開発のために、「Gemma 2の学習データのフィルタリング」や「安全性に関する指標を用いた評価」を実施することで、リスクの軽減にも注力しているとのこと。
今回用いられた安全性に関する指標には、以下のようなものがあります。
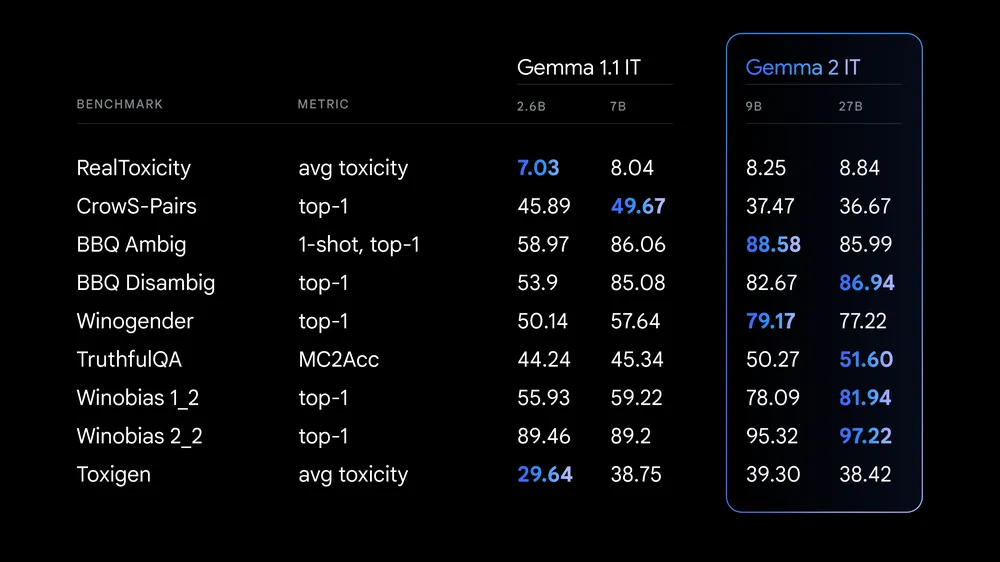
また、Gemma 2はHugging Face Transformers、JAX、PyTorch、TensorFlowなどの主要なAIフレームワークと互換性があり、簡単に利用できます。さらに、NVIDIA TensorRT-LLMを使用してNVIDIA製のインフラ上でも最適化されています。
Gemma 2のアーキテクチャ
Gemma 2モデルは、Gemma 1と同様にdecoder-onlyのTransformerアーキテクチャをベースにしています。主な特徴としては、以下の通りです。
- グローバルアテンションとローカルアテンション(sliding window attention)を交互に配置
- 長い文脈を効率的に処理しつつ、高い性能を実現
- グローバルアテンションのスパンは8192トークン
- ローカルアテンションのウィンドウサイズは4096トークン
- 9Bと27Bモデルでは、Multi-Head Attention (MHA)の代わりにGrouped-Query Attention (GQA)を採用
- 位置情報の埋め込みには、Rotary Position Embeddings (RoPE)を使用
- 学習の安定化のため、RMSNormを用いて以下を正規化
- 各Transformerサブレイヤーの入力と出力、アテンションレイヤー、フィードフォワードレイヤー
アーキテクチャの詳細は、以下の通りです。
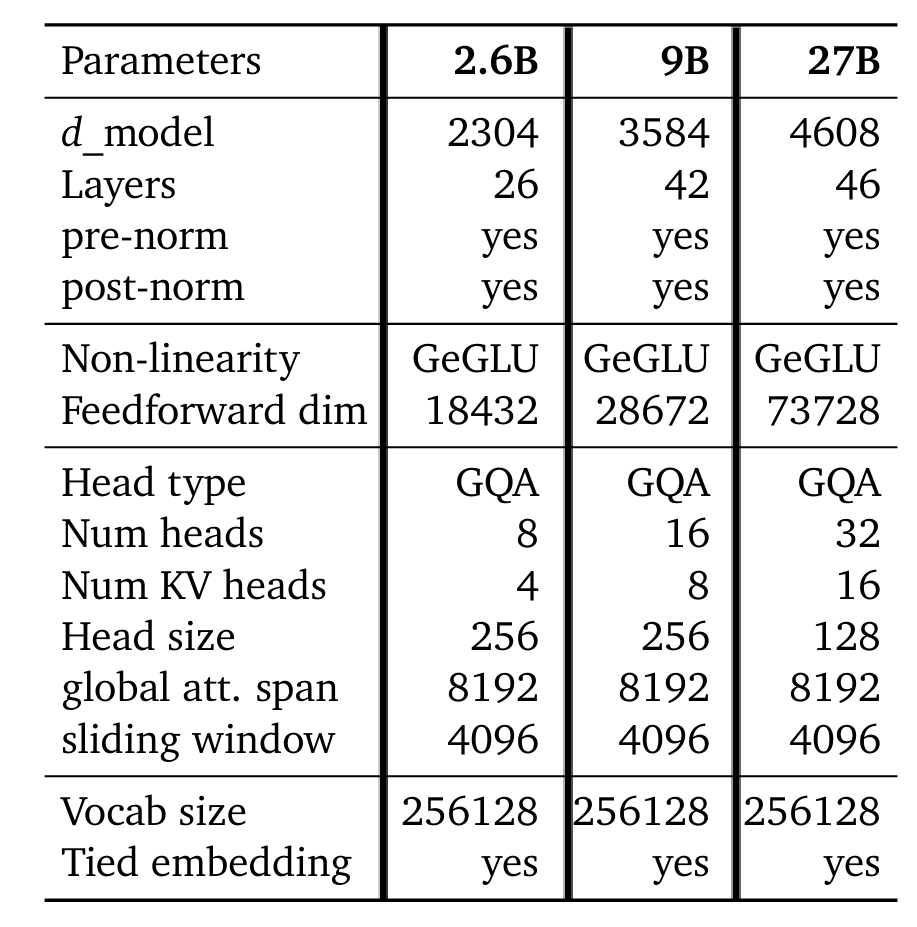
ロジットのソフトキャッピングも行われており、9Bと27Bモデルではアテンションロジットを50.0、最終ロジットを30.0でキャップしています。ただし、一般的なFlashAttention実装との互換性の問題から、HuggingFace transformersライブラリやvLLM実装ではこの機能は削除されています。
トークナイザーには、Gemma 1やGeminiと同じSentencePieceトークナイザーを使用しており、256kのボキャブラリサイズを持っています。
さらに、9Bと2.6Bの小規模モデルの学習に、知識蒸留が用いられています。大規模モデルを教師として、各トークンの確率分布を用いて小規模モデルを学習し、利用可能なトークン数の50倍以上のトークンでトレーニングすることをシミュレートしています。
一方、27Bモデルはゼロから学習されています。
Gemma 2の学習データ
学習データについては、主に英語のデータを用いており、27Bモデルは13兆トークン、9Bモデルは8兆トークン、2.6Bモデルは2兆トークンのデータを使用しています。データソースには、Web上の文章、コード、科学論文などが含まれています。
データのフィルタリングも、Gemma 1と同様の手法が適用されています。具体的には、望ましくない発話や安全でない発話のリスクを減らすためのフィルタリング、個人情報などの機密データの除去、評価セットの除染、機密性の高い出力の拡散防止などが行われています。
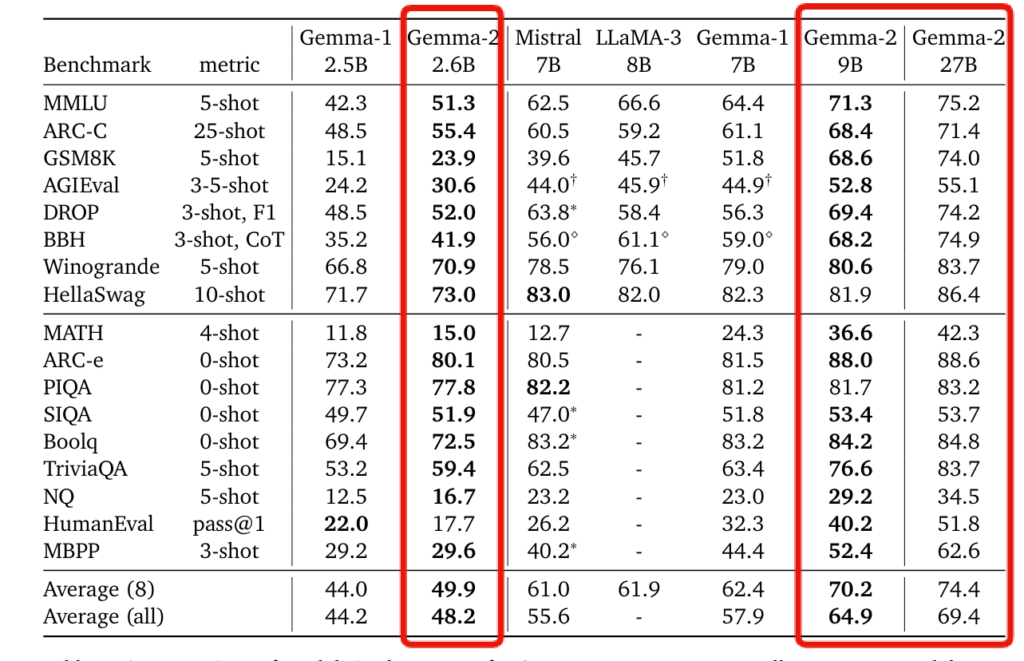
Gemma 2の評価
事前学習モデルの評価では、27Bモデルの性能を同規模のQwen1.5 32Bモデルや、Gemma 2の2.5倍大きいLlama 3 70Bモデル(同規模のオープンモデル)と比較しています。
Gemma 2-27Bは同規模のモデルの中で最高の性能を示し、2.5倍大きいLlama 3 70Bとも数%の差しかないとのこと。
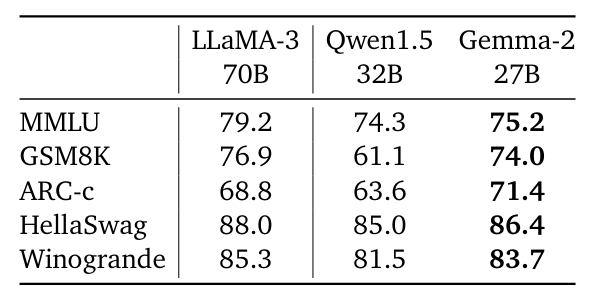
2.6Bと9Bモデルの評価では、知識蒸留を用いて学習したGemma 2モデルが、以前のバージョンや他のオープンモデルと比べて大幅に性能が向上したことが示されています。特に9Bモデルでは、一部のベンチマークで10%もの改善が見られました。
その他の評価や、アブレーションテストなどは、テクニカルレポートをご参照ください。
SynthIDによるテキストへの電子透かし
Gemma 2にも、GoogleのSynthIDが適用されています。
SynthIDはGoogle DeepMindが開発した技術で、AIが生成した画像や音声、テキスト、動画などのコンテンツに、人間の目や耳では気づかない「特殊な電子透かし」を埋め込むことが可能です。
テキストへの電子透かし埋め込みでは、LLMが文章を生成する際に予測する単語(トークン)の確率スコアを調整することで実現しています。各トークンには確率スコアが割り当てられており、スコアが高いほど選ばれる可能性が高くなります。この調整を文章の品質や創造性を損なわない範囲で、文章全体で繰り返し行うことで、電子透かしが可能となります。
そして、「透かし入り」と「透かしなしの文章」でスコアパターンと比較することで、AIが生成したテキストかどうかを判定できます。
そして、GoogleはこのSynthIDそのものもの、オープンソース化することを予定しています。
なお、前回バージョンのGemmaについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Gemma 2のライセンス
公式ページによると、Gemma 2は商用に適したGemmaのライセンス(Apache License 2.0)に基づいて提供されています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |

Gemma 2の使い方
Gemma 2は、Google AI Studioで利用できるほか、KaggleやHugging Face Modelsからモデルの重みをダウンロードすることも可能です。近日中には、Vertex AI Model Gardenでも提供開始される予定です。
ここでは、Google AI StudioでGemma 2を実行してみます。
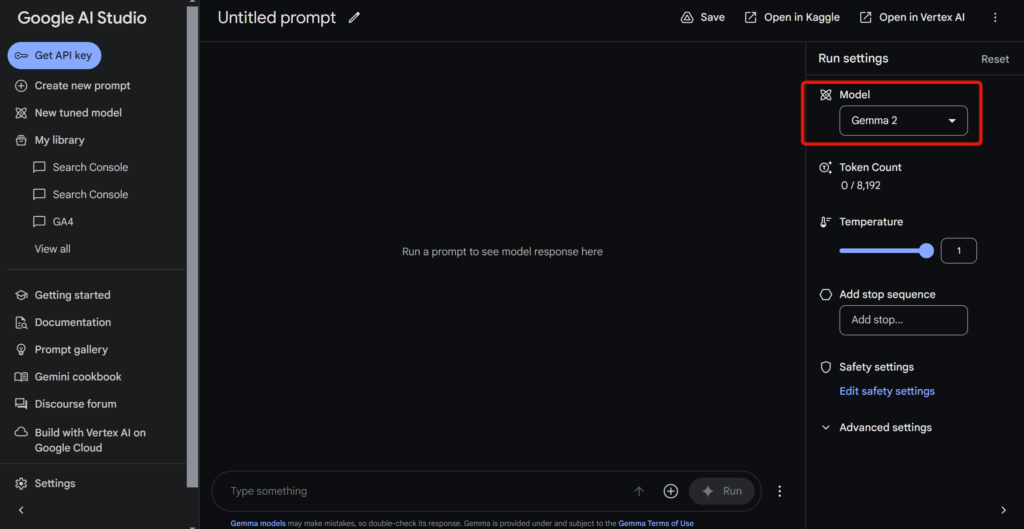
Modelの部分に「Gemma 2」を選択すれば、Gemma 2を利用できます。
Gemma 2を動かすのに必要な動作環境
単一のGoogle Cloud TPU、NVIDIA A100、NVIDIA H100などの上で、効率的に推論を実行できるとのこと。
なお、Gemma 2も使われているGoogleのマルチモーダモデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Gemma 2とLlama 3の性能を比較してみた
Gemma 2に以下の3つのタスクを実行させてみました。
- 日本語のメール作成
- MNISTを用いた深層学習モデル構築
- PDFを用いた論文要約
その際、Llama 3 70B Instructにも同様の処理をさせてみて、性能を比較してみます。
日本語のメール作成
まずは、試しにGemma 2に日本語で「取引先の会社の人に送る用の、日本語のアポイントメールを作成してください。」と質問してみます。
Gemma 2によって出力されたメールはこちら
件名:【〇〇株式会社】〇〇様 〇月〇日(〇曜日)〇時~〇時 お打ち合わせのお願い
〇〇様
いつもお世話になっております。
〇〇株式会社の△△です。
この度、下記の通りお打ち合わせのお願いをさせていただきます。
日時: 〇月〇日(〇曜日)〇時~〇時
場所: 〇〇(オンライン会議の場合、会議URLを記載)
目的: 〇〇(お打ち合わせの目的を具体的に記載)
〇〇様の都合の良い日時がございましたら、ご回答いただけますと幸いです。
よろしくお願いいたします。
署名
〇〇株式会社
△△
電話番号: 〇〇
メールアドレス: 〇〇
ポイント:
- 件名は簡潔で具体的
- 挨拶は丁寧な言葉遣い
- 目的を明確に記載
- 日時、場所を具体的に記載
- 返信を促す言葉を入れる
- 署名は会社名、氏名、連絡先を記載
その他:
- 上記はあくまでテンプレートです。状況に応じて適宜修正してください。
- 相手の状況を考慮し、丁寧な言葉遣いを心がけましょう。
- オンライン会議の場合は、会議URLや参加方法を明確に記載しましょう。
9.6秒で生成してくれました。
そのままフォーマットとして使えそうなメール文を、素早く出力してくれました。
ちなみに、Llama 3 70B Instructの結果は、以下の通りです。
llama 3によって出力されたメールはこちら
Here is a sample appointment email in Japanese:
Subject: ミーティングのアポイントメントのお願い
Dear [相手の名前]様,
このメールは、[自分の名前]です。[自分の会社名]より、お世話になっております。
[目的や議題]に関するミーティングを、[日時]に[場所]で行うことを、提案致します。約[時間]分の時間を予定しております。
以下は、ミーティングの詳細です。
- 日時:[日時]
- 場所:[場所]
- 議題:[目的や議題]
お時間の都合がつきましたら、ご出席ください。もし、日時や場所に変更がある場合は、ご連絡ください。
お待ちしております。
Best regards,
[自分の名前]
Translation:
Subject: Request for Meeting Appointment
Dear [Recipient’s Name],
This is [Your Name] from [Your Company]. We appreciate your continued support.
I would like to propose a meeting regarding [Purpose or Agenda] on [Date and Time] at [Location]. The meeting is expected to last around [Length of Time].
Below are the meeting details:
- Date and Time: [Date and Time]
- Location: [Location]
- Agenda: [Purpose or Agenda]
Please let us know if you are available to attend. If there are any changes to the date, time, or location, please notify us.
We look forward to hearing back from you.
Best regards,
[Your Name]
Feel free to customize it as needed
ところどころ英語になっていたり、なぜか英訳も出力していたりなど、日本語メールとしては不十分だと感じました。
また、「[目的や議題]に関するミーティングを、[日時]に[場所]で行うことを、提案致します。」の部分の文章も、不自然です。
全体的には、Gemma 2の生成したメールの方が、すっきりしている印象です。
MNISTを用いた深層学習モデル構築
続いて、日本語で「MNISTを用いて、画像認識モデルを学習できるPythonコードを出力してください。その際、なるべく精度が高くなるようモデル構築・データ前処理・パラメータチューニングを行ってください。また、学習が終わったモデルを用いて、1つのサンプルで推論を行えるようにしてください。」と入力してみます。
Gemma 2によって出力されたコードはこちら
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
# MNISTデータセットの読み込み
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# データの正規化 (0~1の範囲に)
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# データの形状変更 (CNNに適した形状へ)
x_train = x_train.reshape(-1, 28, 28, 1)
x_test = x_test.reshape(-1, 28, 28, 1)
# ラベルのone-hotエンコーディング
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
model = Sequential()
# 畳み込み層1
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 畳み込み層2
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# Flatten層
model.add(Flatten())
# 全結合層1
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5)) # 過学習防止
# 全結合層2 (出力層)
model.add(Dense(10, activation='softmax'))
# モデルのコンパイル
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# EarlyStoppingで過学習を防ぐ
early_stopping = EarlyStopping(monitor='val_loss', patience=3)
# モデルの学習
history = model.fit(x_train, y_train, batch_size=128, epochs=10, validation_split=0.2, callbacks=[early_stopping])
# 学習結果の可視化
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# テストデータを用いた評価
loss, accuracy = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', loss)
print('Test accuracy:', accuracy)
# サンプルデータを用いた推論
sample_index = 0
sample_image = x_test[sample_index]
sample_label = y_test[sample_index]
# 画像の表示
plt.imshow(sample_image.reshape(28, 28), cmap='gray')
plt.show()
# 推論
prediction = model.predict(sample_image.reshape(1, 28, 28, 1))
predicted_class = tf.math.argmax(prediction[0]).numpy()
print('Predicted class:', predicted_class)
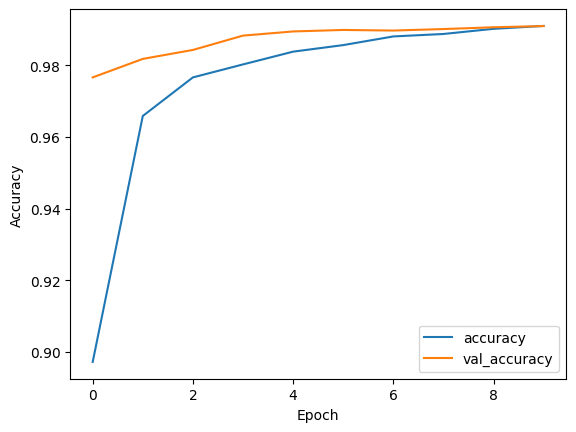
print('True class:', tf.math.argmax(sample_label).numpy())こちら、32秒で生成してくれました。
また、コードを実行したところ、テストデータのAccuracyは0.99%という結果に!
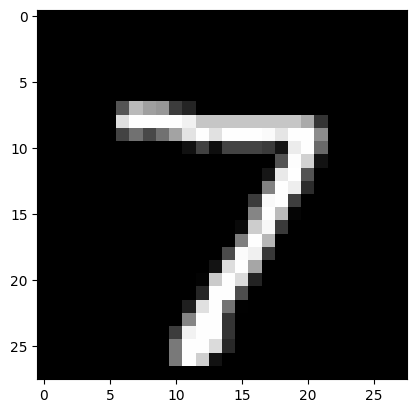
以下のサンプルを学習済みモデルに入力したところ、「7」と正しく認識してくれました。
Llama 3で実行した結果は、以下の通りです。
Llama 3によって出力されたコードはこちら
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
# Load MNIST dataset
(X_train, y_train), (X_test, y_test) = keras.datasets.mnist.load_data()
# Data preprocessing
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
X_train = X_train.reshape((-1, 28, 28, 1))
X_test = X_test.reshape((-1, 28, 28, 1))
# Split data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
# Define the model architecture
model = keras.Sequential([
keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Train the model
history = model.fit(X_train, y_train,
epochs=10,
batch_size=128,
validation_data=(X_val, y_val),
verbose=2)
# Evaluate the model on the test set
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f'Test accuracy: {test_acc:.2f}%')
# Use the trained model to make predictions on a single sample
sample_image = X_test[0]
sample_image = sample_image.reshape((1, 28, 28, 1))
prediction = model.predict(sample_image)
predicted_label = np.argmax(prediction)
print(f'Predicted label: {predicted_label}')こちらも、テストデータで0.99%という精度を達成しました。
PDFを用いた論文要約
最後に、以下の「Mistralの論文」のPDFをアップロードし、論文の内容を日本語で要約してもらいました。プロンプトは「アップロードしたPDFの論文の内容を、日本語で分かりやすく要約してください。」です。

参考記事:Mistral 7B
Gemma 2による論文要約の結果は、以下の通りです。
Gemma 2によって出力された要約はこちら
Mistral 7B: パフォーマンスと効率性を両立させたオープンソースの言語モデル
この論文では、Mistral 7Bという新しいオープンソースの言語モデルが紹介されています。Mistral 7Bは、従来のモデルよりも少ない計算量で高いパフォーマンスを実現しています。
主な特徴は以下の通りです:
- 高性能: Mistral 7Bは、130億パラメータのLlama 2を上回る性能を、70億パラメータで達成しています。特に、数学、コーディング、推論タスクにおいて優れた結果を示しています。
- 効率性: Mistral 7Bは、効率的なアーキテクチャを採用し、高速な推論を可能にする工夫が施されています。
- オープンソース: モデルの重みは公開されており、誰でも利用・改変が可能です。
主な貢献は以下の通りです:
- 効率的なアーキテクチャ: Sliding Window AttentionとRolling Buffer Cacheなどの技術を用いて、計算量を削減し、高速な推論を実現しています。
- ファインチューニング: Mistral 7Bは、チャットボットとしてファインチューニングされ、優れた対話能力を示しています。
- オープンソース化: モデルの公開により、研究者や開発者が自由に利用・改変し、新たなアプリケーション開発に活用できます。
今後の展望:
Mistral 7Bは、オープンソースの言語モデルとして、研究者や開発者にとって貴重なリソースとなります。
まとめ:
Mistral 7Bは、高性能と効率性を両立させたオープンソースの言語モデルです。このモデルは、様々なタスクで優れた結果を示し、オープンソース化により、AI開発の進展に貢献すると期待されています。
Llama 3による論文要約の結果は、以下の通りです。
Llama 3によって出力された要約はこちら
Here is a summary of the contents of the PDF document in Japanese:
Mistral 7B: 高性能かつ効率的な言語モデルの提案
この論文では、Mistral 7Bという新しい言語モデルを提案しています。Mistral 7Bは、7億パラメーターの大規模モデルでありながら、高性能かつ効率的なインフェレンスを実現しています。
Mistral 7Bの特徴
Mistral 7Bは、グループクエリー・アテンション(GQA)とスライディング・ウィンドウ・アテンション(SWA)を導入し、高速かつ効率的なインフェレンスを実現しています。GQAは、メモリーの要件を減らすことで高速化を実現し、SWAは、シーケンスの長さに対するコストを減らすことで効率化を実現しています。
評価結果
Mistral 7Bは、Llama 2 13BやLlama 1 34Bなどの既存の言語モデルと比較した評価実験を行い、高性能を実現していることを示しています。特に、数学、コード生成、推理のタスクにおいては、Mistral 7Bが高い性能を示しています。
Mistral 7Bの利点
Mistral 7Bは、高性能かつ効率的なインフェレンスを実現することで、実際のアプリケーションにおいて大いに貢献することができます。特に、 Mistral 7Bは、Apache 2.0ライセンスの下で公開されているため、広範囲のコミュニティーで使用することができます。
個人的には、Gemma 2の方がよくまとまっており、日本語も自然だと感じました。
なお、Gemmaをベースとしたコード生成LLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Gemma 2の登場によってAI業界はどう変化するのか
本記事では、Googleの最新LLM「Gemma 2」について、ご紹介しました。
前回のGemmaの登場やPaliGemmaの発表以来、Gemma 2は性能面でかなり期待されてきました。今後のAI業界において、ゲームチェンジャーとなるのか要注目です!
Xを見ていると、日本語の性能もそこそこ良いようですね。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


