
【Google Lumiere】Soraレベルの動画生成AIの仕組みを徹底解説

2024年1月23日、Google Researchは新たな動画生成AIモデル「Lumiere」を発表しました。
Lumiereは独自の「Space-Time U-Net (STUnet)」というアーキテクチャによって動画全体を一度に処理することで、破綻の少ないリアルな動画を生成することができます。
以下の動画は実際にLumiereで生成された動画のデモムービーです。
今回は、そんな高性能動画生成AIであるLumiereについて、その概要や技術的な特徴を紹介します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Google Lumiereの概要
Google Lumiereは、Googleが開発した最先端の動画生成AIです。
テキストを元に動画を生成(Text-to-Video)できるだけでなく、静止画を動画に変換(Image-to-Video)したり、既存の動画の一部を編集するなど、さまざまな機能があります。
例えば、次の動画はText-to-Videoのサンプルです。
Astronaut on the planet Mars making a detour around his base
和訳:
基地周辺を迂回する火星の宇宙飛行士
宇宙服のしわや足の動きも滑らかで、違和感の少ない動きになっています。
そのクオリティの高さからユーザー評価も高く、論文によると、従来の動画生成AIとして、動画の質・プロンプト再現性の両方でLumiereが優位となったことが報告されています。
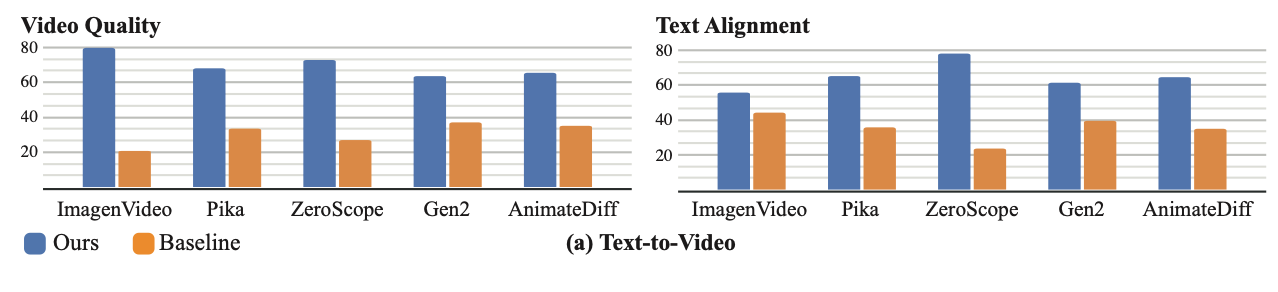
ここからは、そんなLumiereの機能やリアルな動画生成を実現する技術の概要について詳しく紹介していきます。
Lumiereと比較されている動画生成AI「Pika1,0」について、より詳しい内容を知りたい方は、こちらの記事をご覧ください。
→【Pika 1.0】頭の中のアイデアを動画にできる動画生成AI!使い方や料金、商用利用について解説
Google Lumiereにできること
ここからは、Lumiereの機能を詳しく紹介していきます。
Lumiereでは、以下のようなことができると報告されています。
- Text-to-Video
- Image-to-Video
- Cinemagraphs(静止画の一部のみ動かす)
- Video-to-Video
- Inpainting(動画修正)
それぞれについて、詳しく見ていきましょう。
Text-To-Video
まずは先ほど紹介した、「Text-To-Video」機能です。これはLumiereの目玉である、書かれたテキストを基にビデオを生成する機能です。
複数のサンプル動画が紹介されていますが、どれも細部までリアリティのある動画が生成されています。
花が揺れているシーンや魚の群れなど、複数の物体が重なる動画でも精度の高さが伺えます。
Image-to-Video、Cinemagraphs
静止画をもとに動画を生成する機能です。全体を動画化するだけでなく、Lumiereは画像の一部のみを指定して動かすことも可能です。
まずはImage-to-Videoを見てみましょう。
A girl winking and smiling
和訳:
ウインクして微笑む少女
A timelapse oil painting of a starry night with clouds moving
和訳:
星降る夜の絵画の雲が動くタイムラプス
よく知られた名画が、リアルな映画やアニメのような質感で動画化されています。
また、画像の一部のみを動かすCinemagraphs機能では、写真の中を範囲指定し、その部分のみを動画に変換することも可能です。
煙や炎のゆらぎなどは、普通に撮影した動画と比べても遜色がないように見えます。
これらの機能は、静止画に動きを加えてより鮮やかに表現したいシーンなどに便利ですね。
Video-to-Video、Inpainting
既存の動画素材を元に、スタイル変更や内容の修正・編集を行うこともできます。
以下の例では、元の動画から被写体のテクスチャをさまざまなものに変更しています。
Made of stacked wooden blocks
和訳:
積み木
Origami folded paper art
和訳:
折り紙
Made of colorful toy bricks, Sculpture made of flowers
和訳:
カラフルなおもちゃのブロック
Sculpture made of flowers
和訳:
花でできた彫刻
また、Inpainting機能では動画の中の不要な要素を消去したり、欠けている部分を補完することができます。
次の例ではテキストプロンプトによる指示のみで元の緑色の肩出しドレスから、さまざまなデザインのドレスに服装を変化させています。
A woman wearing a purple strapless dress
和訳:
紫のストラップレスドレスを着た女性
A woman wearing a stripe strapless dress
和訳:
ストライプのストラップレスドレスを着た女性

元の動画では隠れていた肘の部分も破綻がなく、綺麗に保管して生成されているのには驚きます。
従来の動画生成AIの事例について詳しく知りたい方は、次の記事も参考にしてみてください!
→【DragNUWA】カーソルの動きで動画を編集できる最先端動画生成AIの使い方〜実践まで
Google Lumiereの仕組み・技術
ここからは、今までに紹介したようなLumiereの機能がどのような技術によって成り立っているのかを紹介します。
従来の動画生成AIと違う技術とは、どのようなものなのでしょうか。
Space-Time U-Net (STUnet)アーキテクチャ
Lumiereが独自に採用した「STUnetアーキテクチャ」は、動画の空間(画像の縦横)と時間(ビデオの長さやフレーム)の両方の情報を同時に処理できる、進化したニューラルネットワークの設計です。
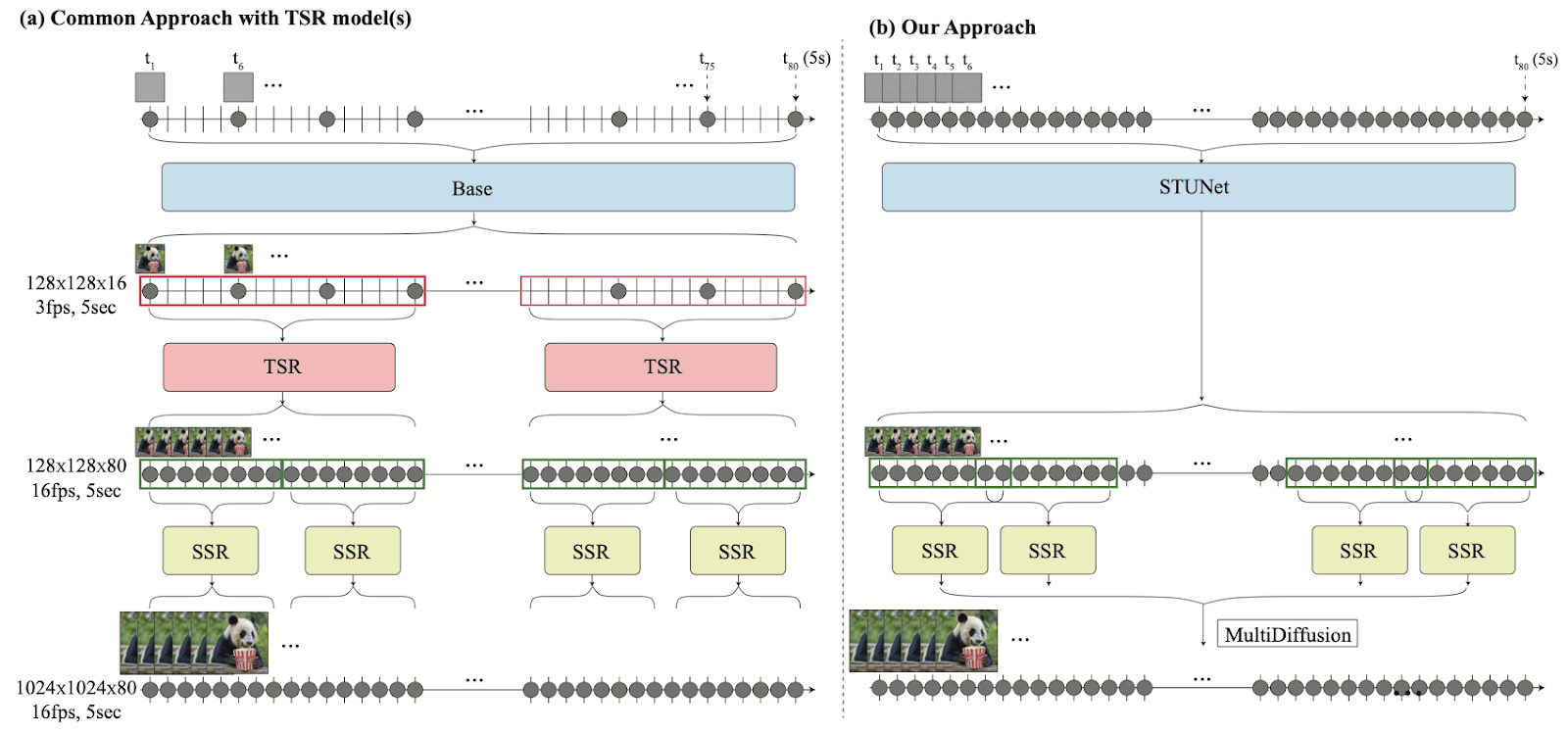
従来のアプローチでは、まず離れたキーフレームを生成し、TSRモデルによる時間的な処理によってキーフレームの間が補完されます。その次に、SSRモデルによる空間的な処理が適用されることで高解像度の動画を生成していました。
これに対し、STUnetは一度にすべてのフレームを処理できるため、TSRモデルのカスケードを使用しません。そのため、全体的に一貫した動きを実現し、処理時間も大幅に短縮されています。
STUnetについて、さらに詳しく見ていきましょう。
STUnetアーキテクチャでは、動画データを取り扱う際に空間的・時間的なダウンサンプリングが行われます。
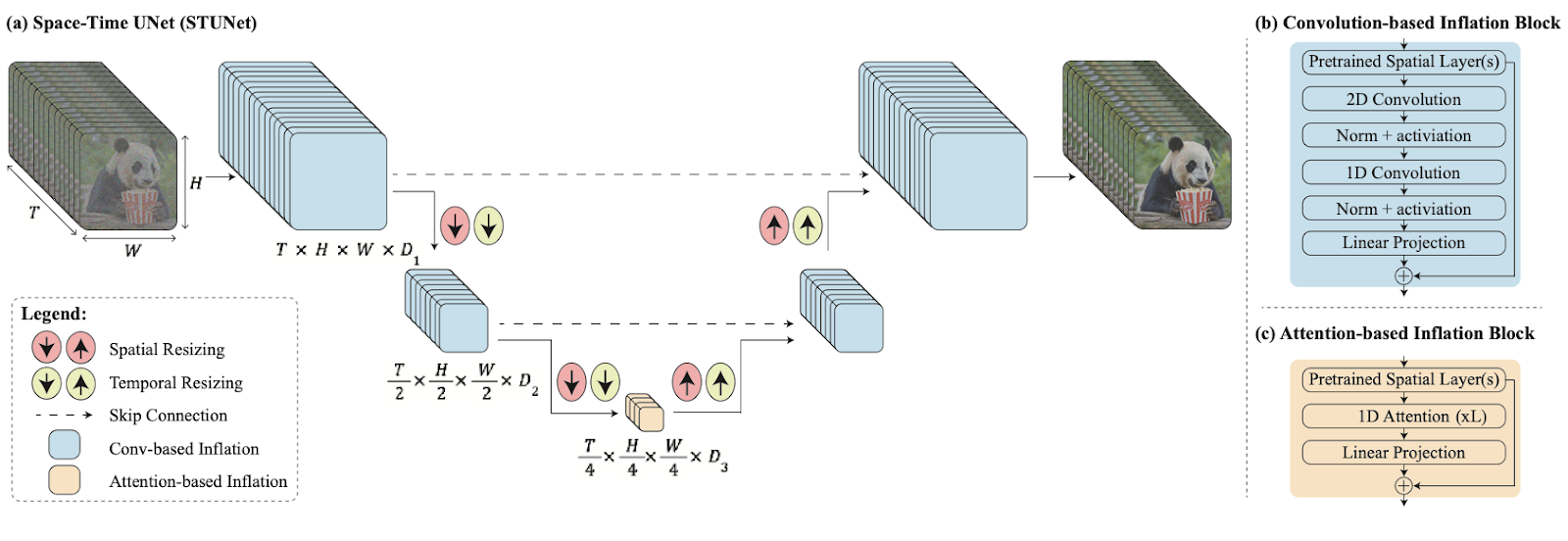
画像サイズ(空間)とフレーム数(時間)の両方を「小さく切り詰める」ことによって全体を一度に処理できるため、より滑らかな動画生成が可能になっているんですね。
Multidiffusion for Spatial-Super Resolution
「Multidiffusion for Spatial-Super Resolution」は、動画の解像度を向上させるために用いられる技術です。
動画内の低解像度フレームを取り除き、ビデオの時間的な流れ(フレームの間の動きや変化)も考慮に入れて、自然な高解像度化を行います。

Google Lumiereの問題点
これまで、Lumiereの数々の魅力的な機能を紹介してきましたが、Lumiereも当然完璧ではありません。
Google ReserchはLumiereの持つ問題点について、次のように報告しています。
フレームワークの限界
Lumiereの手法は、1つの動画内で複数のショットや画角を切り替えたり、異なるシーン間を滑らかに遷移させたビデオを作ることには向いていません。
映画のようにシーンが変わるような複雑なビデオを自動で作成するのは難しいということです。確かに、紹介されている動画はいずれも単一のショットのものですね。
生成できる動画時間が短い
Lumiereは動画全体を一度に処理する都合上、生成できる動画は5秒間に限定されています。
OpenAI社が公開したsoraは最長1分間もの動画を生成できることと比較すると、少し見劣りしてしまうかもしれませんですが、今後の改善によって大きな進歩を遂げる可能性を秘めています。
これからの進歩が楽しみですね!
LumiereのOpenAI版であるSoraについて知りたい方は、こちらの記事をご覧ください。
→【OpenAI Soraの動画事例】一晩で世界を変えた動画生成AIのヤバい使い方10選
Google Lumiereは高クオリティな動画生成AIモデル!
Google Lumiereは、2024年1月23日にGoogleが発表した、スムーズで破綻の少ない動画を生成してくれるAIモデルです。
最後にGoogle Lumiereの特徴をまとめると、
- 動画の空間・時間の両方を同時に処理できるアーキテクチャ
- テキストから動画の生成
- 静止画を動画に変換
- 動画へのフィルター適用
- 動画の部分的な修正・編集
今後、Lumiereがどのように進化していくか、対抗馬となるSoraと比較してどのようなポテンシャルを持っているのか、続報が期待されますね。
一般公開される日が楽しみです!


