
OpenAIの新音声合成モデル「GPT-4o Mini TTS」とは?使い方・特徴・料金を徹底解説!
- OpenAI製の音声合成モデル
- テキストをより自然な音声に変換
- 話し方の指示が可能
2025年3月21日、OpenAIから新たな音声合成モデルがリリースされました!
今回リリースされたGPT-4o Mini TTSはテキストをより自然な音声に変換するための構成のモデルです。
また、GPT-4o Mini TTSの他に音声認識モデルのWhisper超えのGPT-4o Transcribe、より高速なGPT-4o Mini Transcribeもリリースされました。
本記事では、GPT-4o Mini TTSの概要から使い方、活用方法について解説をします。本記事を最後までお読みいただければ、GPT-4o Mini TTSの理解が深まり、使い方をマスターできます。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
GPT-4o Mini TTSの概要
OpenAIからGPT-4o Mini TTSは、従来の音声合成モデルに比べ、テキストをより自然な音声に変換するための軽量かつ高性能モデルになっています。
GPT-4o Mini TTSはGPT-4oとGPT-4o miniのアーキテクチャに基づき、テキストを高品質かつ自然に聞こえる音声に変換をさせています。
また、GPT-4o Mini TTSでは話し方の指示が可能になっており、例えば「共感してくれるカスタマーサポートのように話をして」などのように話し方を指示できるのが大きな特徴です。
音声出力の対応言語は多言語対応になっており、英語はもちろん、スペイン語や日本語、フランス語、中国語などです。GPT-4o Mini TTSで対応している言語はWhisperで対応している言語に則っています。※1
GPT-4o Mini TTSの特徴
GPT-4o Mini TTSには3つの特徴があります。
- 本物の音声データセットによる事前トレーニング
- 高度な蒸留方法を採用
- 強化学習のアプローチ
まず一つ目に、GPT-4o Mini TTSは本物の音声データセットによる事前トレーニングを行っています。
GPT-4oとGPT-4o miniのアーキテクチャに基づき開発されていますが、モデルのパフォーマンスを最適化する上で重要な役割を果たす、音声中心のデータセットで広範囲にわたる事前トレーニングを実施。
音声中心のデータセットで事前トレーニングを行ったことにより、音声の微妙なニュアンスに対してより高精度な音声出力を実現しています。
また、GPT-4o Mini TTSは高度な蒸留方法を採用。これにより、大規模な音声モデルの知識をより小さくて効率的なモデルに引き継ぐことができるようになっています。
特に、自己対話という手法を使うことにより、実際のユーザーとの会話のように自然でリアルな対話データを作り出し、それを使って学習をしています。このような工夫によって、小型モデルでも高品質かつ素早いレスポンスを実現しています。
最後に強化学習の活用です。GPT-4o Mini TTSでは強化学習を取り入れることにより、認識精度の大幅向上・ハルシネーションの減少、複雑な音声認識の実現をしています。


GPT-4o Mini TTSの性能
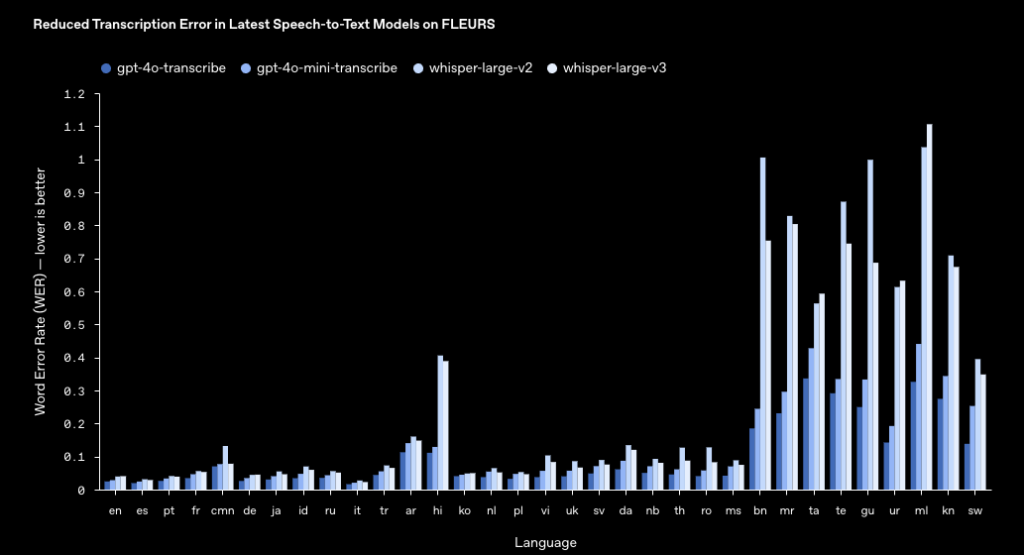
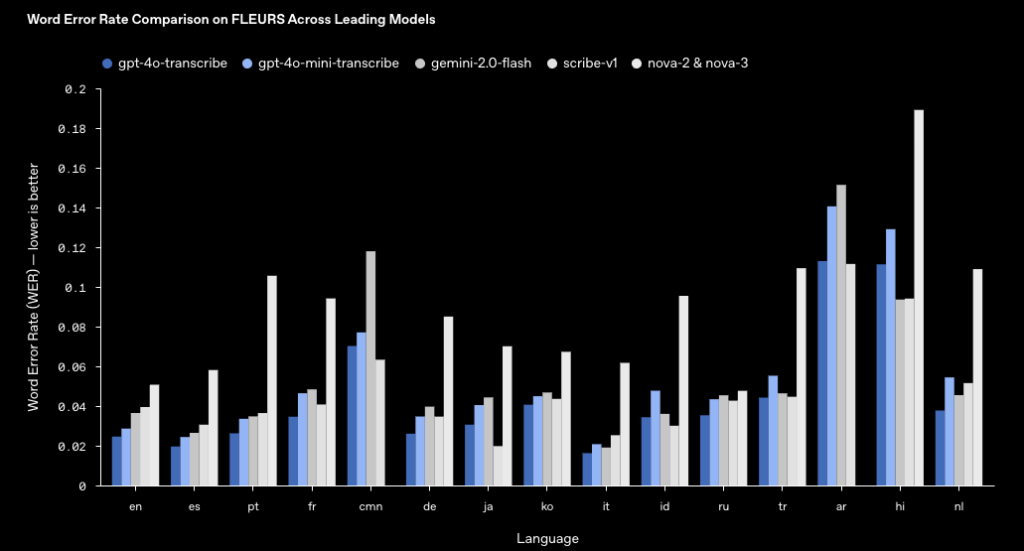
GPT-4o Mini TTSの性能については、公式ページに記載はされていませんでした。
GPT-4o Mini TranscribとGPT-4o Transcribeの性能は記載されていますが、両者ともにWord Error Rateは非常に低く、従来の音声モデルwhisperを上回る性能であることがわかります。
GPT-4o Mini TTSの料金
GPT-4o Mini TTSはAPI経由で使えますが、費用は下記のようになっています。※2
テキストトークン
| Model | Input | Output | Estimated cost |
|---|---|---|---|
| gpt-4o-mini-tts | $0.60 | – | $0.015 minute |
| gpt-4o-transcribe | $2.50 | $10.00 | $0.006 minute |
| gpt-4o-mini-transcribe | $1.25 | $5.00 | $0.003 minute |
オーディオトークン
| Model | Input | Output | Estimated cost |
|---|---|---|---|
| gpt-4o-mini-tts | – | $12.00 | $0.015 minute |
| gpt-4o-transcribe | $6.00 | – | $0.006 minute |
| gpt-4o-mini-transcribe | $3.00 | – | $0.003 minute |
GPT-4o Mini TTSのライセンス
GPT-4o Mini TTSのライセンスは明記されていませんが、OpenaIAの利用規約を見ると商用利用の可否がわかります。
商用利用について、利用規約ではユーザーに対して入力と出力に関して著作権と利用権を明確に譲渡。特に出力に関しては、「OpenAIは、ユーザーに対してその全ての権利、権限、利益を譲渡する」と記載されています。
さらに、私的利用も可能ですが、13歳以上である必要があり、18歳未満の場合には保護者の許可が必要です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ❌ |
| 配布 | ❌ |
| 特許使用 | ❌ |
| 私的使用 | ⭕️ |
なお、文脈を理解する次世代音声生成AIであるCSM-1Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

GPT-4o Mini TTSの使い方
GPT-4o Mini TTSはAPI経由で利用可能です。また、OpenAI.fmでも利用可能。
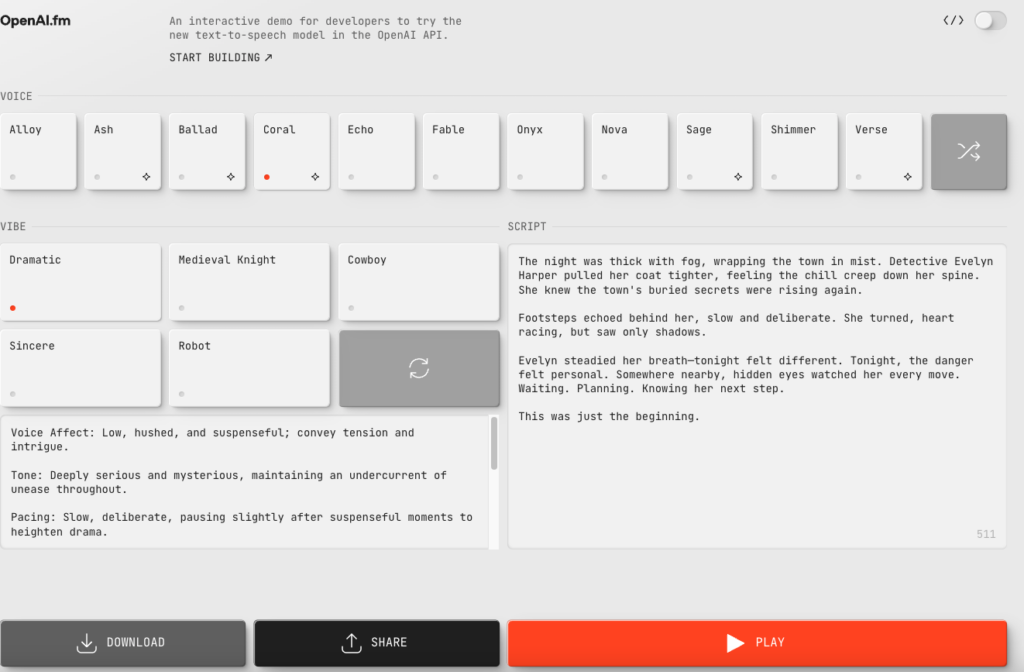
OpenAI.fmで生成した音声はダウンロードすることもできるので、手軽に使ってみたいという場合には、OpenAI.fmを使ってみるのが良いでしょう。実際にOpenAII.fmで生成した音声は以下です。
API経由でGPT-4o Mini TTSを使う
API経由でGPT-4o Mini TTSをgoogle colaboratoryで実装していきます。実行時のgoogle colaboratoryの環境は下記です。ドキュメントはこちら。
Pythonバージョン:3.10
システム RAM
2.0 / 83.5 GB
GPU RAM
0.0 / 40.0 GB
ディスク
37.1 / 235.7 GB
GPU:A100
プラン:有料
まずは必要ライブラリをインストールします。
!pip install –upgrade openai
サンプルコードはこちら
import openai
from IPython.display import Audio
api_key = ""
openai.api_key = api_key
text = "こんにちは。これはGoogle Colabで動くGPT-4o Mini TTSの音声サンプルです。"
response = openai.audio.speech.create(
model="gpt-4o-mini-tts",
input=text,
voice="nova",
response_format="mp3"
)
filename = "gpt4o_mini_tts_output.mp3"
with open(filename, "wb") as f:
f.write(response.content)
display(Audio(filename))出力された音声はこちらです。
非常に流暢な日本語で話をしてくれており、最初聞いた時には驚きました。
パラメータとして「voice」を変更すれば、話者を変更でき、「response_format」は出力拡張子が「mp3 /wav/opus/aac」から選択できます。
話者は全部で11名で、alloy、ash、ballad、coral、echo、fable、onyx、nova、sage、shimmerです。
またパラメータに「instructions」を指定することで話し方を変えることが可能。例えば「instructions=”怒ったように”」と指定すれば怒ったような口調で出力されます。実際に、下記は怒ったように・やさしく話す口調で・驚いた口調でと指示を与えた結果です。
ちょっと違いが分かりにくいかもしれません。もしかしら英語で指示を与えた方がわかりやすく変わるのかもしれませんね。


GPT-4o Mini TTSで会話しているような音声生成ができるかを検証
GPT-4o Mini TTSは音声生成モデルなので、会話をすることはむずかしいです。また、voiceパラメータの呼び出しも1回につき、1種類の声しか指定できません。
そのため、セリフごとに話者を変更したい場合には、話者ごとにAPIを個別に呼び出して音声ファイルを分けて生成、最後に結合する、という方法を取る必要があります。
では実際のコードです。先ほどインストールした他にffmpegもインストールしておきましょう。
!apt-get install ffmpeg -y
サンプルコードはこちら
from IPython.display import Audio
from pydub import AudioSegment
import openai
openai.api_key = "YOUR_API_KEY"
conversation = [
{"speaker": "A", "voice": "nova", "text": "こんにちは、元気だった?"},
{"speaker": "B", "voice": "echo", "text": "うん、最近ちょっと忙しかったけど、元気だよ。"},
{"speaker": "A", "voice": "nova", "text": "それはよかった。週末は何か予定ある?"},
{"speaker": "B", "voice": "echo", "text": "まだ決めてないけど、映画でも観に行こうかな。"}
]
segments = []
for i, part in enumerate(conversation):
response = openai.audio.speech.create(
model="gpt-4o-mini-tts",
input=part["text"],
voice=part["voice"],
response_format="mp3"
)
filename = f"part_{i}.mp3"
with open(filename, "wb") as f:
f.write(response.content)
segments.append(AudioSegment.from_file(filename, format="mp3"))
combined = segments[0]
for seg in segments[1:]:
combined += AudioSegment.silent(duration=300)
combined += seg
output_filename = "conversation_A_B.mp3"
combined.export(output_filename, format="mp3")
Audio(output_filename)生成・結合した音声がこちらです。
ちょっと無理やり結合している感があるので、ノイズっぽいのが入ってしまっているのと、機械的な喋り方に感じます。
CSM-1Bと同じ内容を出力して比較
同じ時期にリリースされたSesame AIのCSM-1BとGPT-4o Mini TTSの出力も比較してみたいと思います。
出力音声はCSM-1Bで出力した「Hello from Sesame AI. This is a test of the CSM-1B model.」です。
まずはCSM-1Bの結果がこちら
こちらがGPT-4o Mini TTSで出力した結果です。
正直、人の耳で違いが感じられないような精度ですが、強いて言えばGPT-4o Mini TTSの方がクリアな感じはしますね。実際に皆さんも色々生成してみて比較してみてください。
なお、音声とテキストを融合したマルチモーダルAIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事ではGPT-4o Mini TTSの概要から使い方、活用方法についてお伝えをしました。同じ時期にSesame AIからリリースされたCSM-1Bも文脈を考慮して音声を生成できましたが、日本語に非対応でした。
そのため、国内サービスに導入する際にはGPT-4o Mini TTSが第一候補になりそうです。ぜひ皆さんも本記事を参考にGPT-4o Mini TTSを使ってみてください!
最後に
いかがだったでしょうか
GPT-4o Mini TTSなら、感情や文脈を汲んだ自然な音声生成が可能に。カスタマーサポートやナレーション、対話型UIなどの音声体験を次のレベルへ引き上げる活用法をご紹介します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。
※1:Text to speech
※2:Pricing


