
【GPT-4o mini】OpenAIの軽量モデル!概要から使い方まで徹底解説
2024年7月19日、OpenAIがGPT-4o miniを発表!発表後1日も経たず85万人以上の人々が興味を示しています。
GPT-4o miniは従来のGPTよりも費用対効果の高い小型モデルとして発表されました。価格は、100万個あたりの入力トークンに対して15セント、出力トークンは100万個あたり60セントと非常に安価であり、従来のGPT-3.5Turboに比べて60%以上安くなります。
この記事では、GPT-4o miniが従来のGPTと比べてどれくらい高速になっているのか、どういった違いがあるのかなどについて、実際に試してみたいと思います。
本記事を最後まで読むことで、従来のGPTとGPT-4o miniの違いについて、深く理解できます。ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
GPT-4o miniとは?
GPT-4o miniは「GPT-4o」の軽量版として設計された革新的なAIモデルでコスト効率の高い小型モデルです。
より手頃な価格で、より幅広いアプリケーションでの利用を促進することを目的としてリリースされました。
このモデルは、テキストおよび画像の両方を入力として処理できるマルチモーダル機能を備えています。OpenAI社の発表によると、将来的にはビデオや音声の入出力にも対応予定とのことです。
また、従来のモデルに比べてセキュリティ面も強化されています。
「instruction hierarchy」と呼ばれる手法で、不正アクセスや悪意のある指示の入力等のサイバー攻撃に対する耐性が向上しているようです。
さらに、ヘイトスピーチや成人向けコンテンツ、個人情報等を事前に除外する処理も施され、安全性も向上しています。
価格、セキュリティの2点が魅力であり、より多くの人にとって使いやすいモデルですね!
GPT-4o miniの特徴
GPT-4o miniの最大の特徴は、従来のGPTに比べて高性能かつ低コストの小型AIモデルである点。特に推論や数学、コーディング、マルチモーダル推論タスクで高い性能を発揮します。
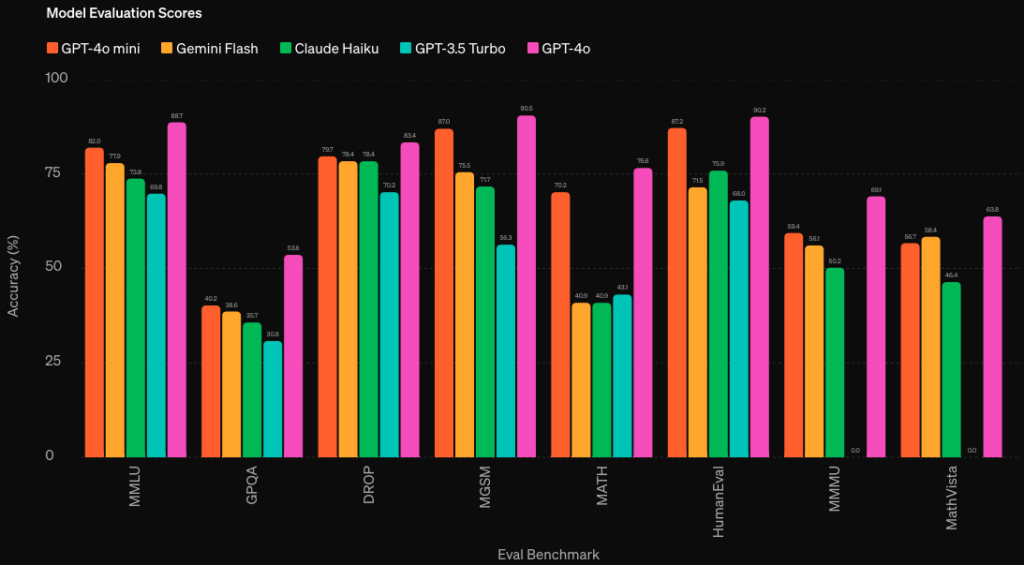
- 推論:MMLU
- 数学:MGSM
- コーディング:HumanEval
- マルチモーダル推論タスク:MMMU
上記画像から、GPT-4o miniが他の小型AIモデルや前世代のGPT-3.5 Turboに比べて、さまざまなタスクで優れた性能を発揮していることがわかります。
一方、公式サイトでは次の注意点も併記されています。
今回のベンチマークの結果はOpenAIのsimple-evalsリポジトリを使用しており、標準化された方法で評価を行っているが、他の組織の評価方法とは異なる可能性がある点、APIアシスタントシステムメッセージプロンプトを使用していることから、特定の設定下での性能を評価していることを注意点として挙げています。
OpenAI
現段階では、GPT-4o miniはテキストと画像のみに対応しており、今後音声および動画へ対応していくとのことですが、具体的な日付に関してはまだ明かされていません。
さらに、これまで発表されている生成AIを比較してみると、GPT-4o miniの費用対効果の高さが明確です。
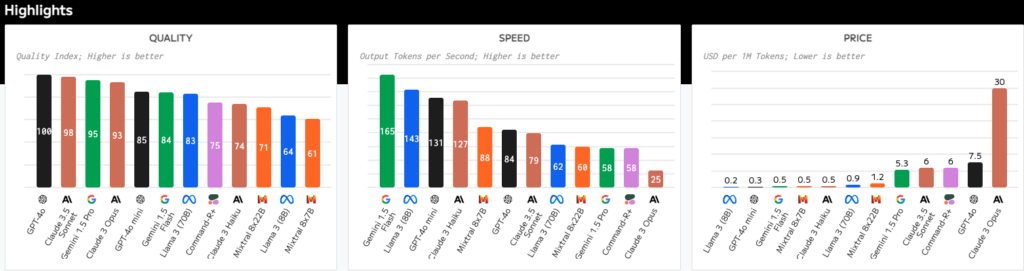
左から
- クオリティ
- 速度
- 価格
の表になっており、黒いバーがOpenAIの生成AIです。GPT-4o miniは高速かつ低コストで生成クオリティが高いことがわかります。
なお、従来のGPT-4について詳しく知りたい方は、下記の記事を合わせてご覧ください。
GPT-4o miniの料金体系と従来コストの比較
GPT-4o miniは従来のGPTに比べ費用対効果が高いことが特徴的です。
入力トークン100万個に対して15セント、出力トークン100万個に対して60セントであり、従来のモデルに比較して1桁以上安価であると発表しています。
また、GPT-3.5 Turboに比べると60%以上安価であり、より高性能なモデルがより低コストで利用可能であり、さらに2022年に導入されたtext-davinci-003モデルと比較すると、GPT-4o miniのトークンあたりのコストは99%削減されており、コスト効率化がされています。
| Model | Price | Price with Batch API |
|---|---|---|
GPT-4o | $5.00/1M input tokens | $2.50/1M input tokens |
| $15.00/1M output tokens | $7.50/1M output tokens | |
GPT-4o-2024-05-13 | $5.00/1M input tokens | $2.50/1M input tokens |
| $15.00/1M output tokens | $7.50/1M output tokens |
| Model | Price | Price with Batch API |
|---|---|---|
GPT-4o-mini | $0.150/1M input tokens | $0.075/1M input tokens |
| $0.600/1M output tokens | $0.300/1M output tokens | |
GPT-4o-mini-2024-07-18 | $0.150/1M input tokens | $0.075/1M input tokens |
| $0.600/1M output tokens | $0.300/1M output tokens |
| Model | Price | Price with Batch API |
|---|---|---|
GPT-3.5-Turbo-0125 | $0.50/1M input tokens | $0.25/1M input tokens |
| $1.50/1M output tokens | $0.75/1M output tokens | |
GPT-3.5-Turbo-instruct | $1.50/1M input tokens | $0.75/1M input tokens |
| $2.00/1M output tokens | $1.00/1M output tokens |


GPT-4o miniの使い方
GPT-4o miniの使い方は簡単です。
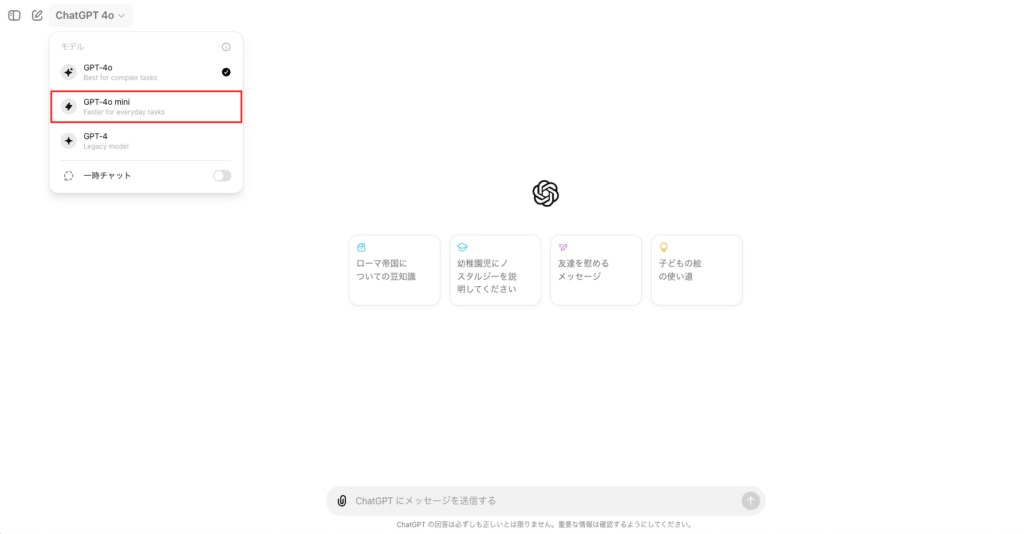
ChatGPTにログインして、モデルを選択するだけで使えます。
これまではGPT-3.5がありましたが、GPT-3.5に代わってGPT-4o miniが用意されています。
モデルをクリック後、これまで通りプロンプトを与えるだけで実行可能です。
GPT-4o miniのAPIの使い方は?
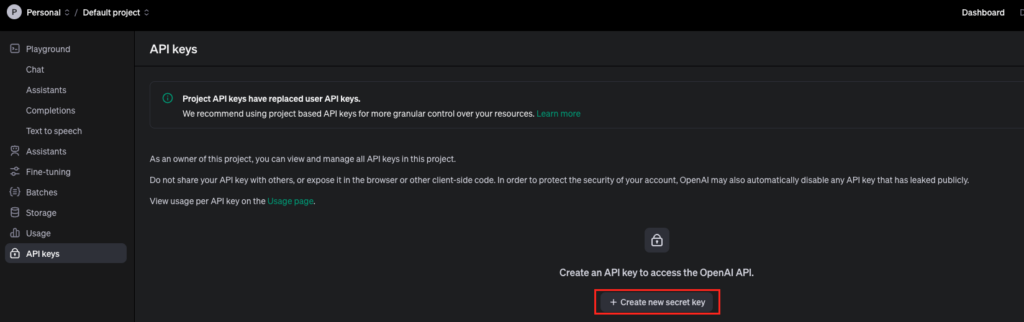
GPT-4o miniはAssistants API、Chat Completions API、Batch APIを通じて開発者向けにすでに提供が始まっています。
OpenAIのAPI keyページからAPIキーを作成し、実装。コーディングの際に「gpt-4o-mini」とモデルを指定するだけで、使うことができます。
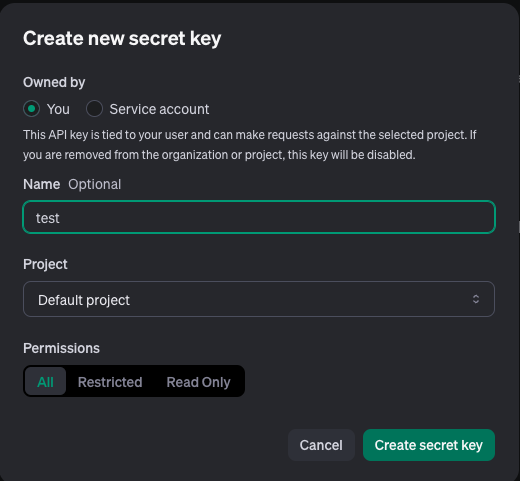
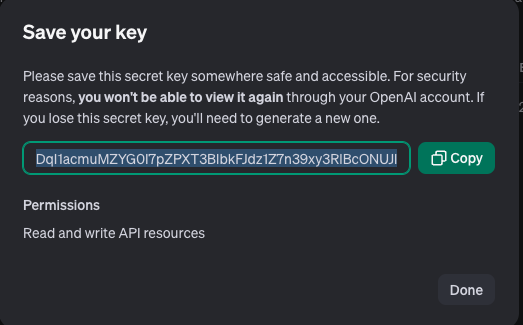
ここで表示されるAPIキーは一度しか表示できないので、必ずどこかにコピペするようにしましょう。
なお、ChatGPTのライバルであるClaude3について詳しく知りたい方は、下記の記事を合わせてご覧ください。

GPT-4o miniのメリット
GPT-4o miniを利用することの利点は大きく2つあります。
- 低価格
- input token100万あたり15セント、outputトークン100万あたり60セントで提供されており、GPT-3.5 Turboと比べると60%以上安い料金で利用できるようになっています。
- ファインチューニング(*)
- GPT-4o miniはファインチューニングが可能であり、高度なカスタマイズが可能となりました。業界特有の専門知識や特殊案件に対応したAIアプリケーションを開発したり、限られたデータセットでも効果的なモデル学習が可能となっています。
GPT-4o miniの活用事例
コスト効率化が図られることで、複数のモデル呼び出しを連鎖または並列化するアプリケーション開発やリアルタイムでの高速チャットボット運用などが実現可能になるでしょう。
実際にGPT-4o mini対応のチャットボットを運用している方がいました。
こちらを見る限り、チャットボットにしては高速で応答してくれている印象を受けます。
また、GPT-4o miniでは改良されたトークナイザーによって非英語テキスト処理の効率化も実現。
非英語テキスト処理の効率化により、より自然で正確な翻訳サービスや多言語対応のチャットボット、多言語ソーシャルメディア管理の自動化などを実装することができ、これまで以上に言語の壁を超えたグローバルコミュニケーションが促進されるでしょう。
実際にGPT-4o miniのAPIを使って改良されたトークナイザーを試しつつ、従来のGPTとも比較をしてみました。
GPTのAPIを使ったサンプルコードはこちら
from openai import OpenAI
import time
import statistics
client = OpenAI(api_key="your_API_key")
def process_text(model, text, runs=5):
times = []
token_speeds = []
input_token_counts = []
output_token_counts = []
for _ in range(runs):
start_time = time.time()
try:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": text}
],
temperature=0.7,
max_tokens=4096,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
end_time = time.time()
processing_time = end_time - start_time
content = response.choices[0].message.content
# APIレスポンスから正確なトークン数を取得
input_tokens = response.usage.prompt_tokens
output_tokens = response.usage.completion_tokens
times.append(processing_time)
token_speeds.append(output_tokens / processing_time)
input_token_counts.append(input_tokens)
output_token_counts.append(output_tokens)
except Exception as e:
print(f"Error processing text with {model}: {str(e)}")
return None
return {
"avg_time": statistics.mean(times),
"avg_token_speed": statistics.mean(token_speeds),
"avg_input_tokens": statistics.mean(input_token_counts),
"avg_output_tokens": statistics.mean(output_token_counts),
"content": content # 最後の実行結果を保存
}
def compare_models(models, texts):
for text in texts:
print(f"\nInput: {text}\n")
for model in models:
result = process_text(model, text)
if result:
print(f"Model: {model}")
print(f"Average processing time: {result['avg_time']:.2f} seconds")
print(f"Average token generation speed: {result['avg_token_speed']:.2f} tokens/second")
print(f"Average input tokens: {result['avg_input_tokens']:.2f}")
print(f"Average output tokens: {result['avg_output_tokens']:.2f}")
print(f"Sample output: {result['content'][:100]}...") # 最初の100文字だけ表示
print()
# テストするモデルとテキスト
models = ["gpt-3.5-turbo-0125", "gpt-4o-2024-05-13", "gpt-4o-mini-2024-07-18"]
texts = [
"Explain the concept of artificial intelligence in simple terms.",
"人工知能の概念を簡単な言葉で説明してください。",
"Write a short story about a robot learning to feel emotions.",
"気候変動の主な原因と、その影響を5つずつ挙げて説明してください。",
"以下の文章を要約してください:日本の伝統文化である茶道は、単なる茶を飲む行為以上の意味を持っています。茶道は、「和敬清寂」という四つの精神を基本としており、これは「和」(調和)、「敬」(尊敬)、「清」(清浄)、「寂」(静寂)を意味します。茶室での所作や道具の扱い方、客人へのもてなしなど、すべてにおいてこの精神が反映されています。茶道を通じて、人々は日常生活から離れ、静かな時間の中で自己を見つめ直す機会を得ることができます。また、季節の移ろいを感じ取り、自然との調和を学ぶこともできます。このように、茶道は日本文化の奥深さと美意識を体現する重要な芸術形態の一つと言えるでしょう。",
]
compare_models(models, texts)結果はこちら
Input: Explain the concept of artificial intelligence in simple terms.
Model: gpt-3.5-turbo-0125
Average processing time: 1.49 seconds
Average token generation speed: 50.43 tokens/second
Average input tokens: 28.00
Average output tokens: 74.60
Sample output: Sure! Artificial intelligence, often referred to as AI, is the simulation of human intelligence proc...
Model: gpt-4o-2024-05-13
Average processing time: 2.70 seconds
Average token generation speed: 55.26 tokens/second
Average input tokens: 27.00
Average output tokens: 134.40
Sample output: Sure! Artificial Intelligence, or AI, is the way we create machines and software that can perform ta...
Model: gpt-4o-mini-2024-07-18
Average processing time: 3.69 seconds
Average token generation speed: 46.14 tokens/second
Average input tokens: 27.00
Average output tokens: 159.40
Sample output: Artificial intelligence (AI) is a branch of computer science that focuses on creating machines and s...
Input: 人工知能の概念を簡単な言葉で説明してください。
Model: gpt-3.5-turbo-0125
Average processing time: 1.74 seconds
Average token generation speed: 73.48 tokens/second
Average input tokens: 44.00
Average output tokens: 128.20
Sample output: 人工知能とは、人間の知能をコンピューターや機械に模倣させる技術や研究のことです。つまり、人間が思考や学習、問題解決などを行う能力をコンピューターや機械に与えることで、様々なタスクを自動化したり、新しい...
Model: gpt-4o-2024-05-13
Average processing time: 1.86 seconds
Average token generation speed: 57.55 tokens/second
Average input tokens: 33.00
Average output tokens: 106.20
Sample output: 人工知能(AI)は、コンピュータやロボットが人間のように考えたり、学んだり、問題を解決したりする能力のことを指します。これには、例えば、会話を理解して返答する、画像や音声を認識する、ゲームをプレイする...
Model: gpt-4o-mini-2024-07-18
Average processing time: 2.58 seconds
Average token generation speed: 46.98 tokens/second
Average input tokens: 33.00
Average output tokens: 116.40
Sample output: 人工知能(じんこうちのう)、またはAI(エーアイ)とは、人間のように考えたり学んだりする能力を持つコンピュータープログラムやシステムのことです。つまり、機械がデータを使って判断をしたり、問題を解決した...
Input: Write a short story about a robot learning to feel emotions.
Model: gpt-3.5-turbo-0125
Average processing time: 4.34 seconds
Average token generation speed: 83.88 tokens/second
Average input tokens: 29.00
Average output tokens: 364.20
Sample output: In a bustling city of the future, there was a robotic assistant named Aria. Aria was designed to be ...
Model: gpt-4o-2024-05-13
Average processing time: 8.48 seconds
Average token generation speed: 86.55 tokens/second
Average input tokens: 29.00
Average output tokens: 727.40
Sample output: In a small, bustling city, there was a robot named Axiom who stood out from the rest. Built by a rec...
Model: gpt-4o-mini-2024-07-18
Average processing time: 18.64 seconds
Average token generation speed: 53.14 tokens/second
Average input tokens: 29.00
Average output tokens: 951.40
Sample output: In a bustling city filled with towering skyscrapers and shimmering lights, there lived a robot named...
Input: 気候変動の主な原因と、その影響を5つずつ挙げて説明してください。
Model: gpt-3.5-turbo-0125
Average processing time: 7.52 seconds
Average token generation speed: 100.77 tokens/second
Average input tokens: 52.00
Average output tokens: 743.00
Sample output: 気候変動の主な原因とその影響をそれぞれ5つずつ挙げます。
主な原因:
1. 化石燃料の燃焼:化石燃料の燃焼により二酸化炭素などの温室効果ガスが大気中に放出され、地球の気温が上昇する。
2. 森林伐採...
Model: gpt-4o-2024-05-13
Average processing time: 11.18 seconds
Average token generation speed: 74.48 tokens/second
Average input tokens: 41.00
Average output tokens: 814.00
Sample output: 気候変動の主な原因とその影響について説明します。
### 主な原因
1. **化石燃料の燃焼**
- **説明**: 石炭、石油、天然ガスなどの化石燃料を燃焼することで、大量の二酸化炭素(C...
Model: gpt-4o-mini-2024-07-18
Average processing time: 15.46 seconds
Average token generation speed: 54.90 tokens/second
Average input tokens: 41.00
Average output tokens: 802.60
Sample output: 気候変動の主な原因とその影響について、以下にそれぞれ5つずつ挙げて説明します。
### 主な原因
1. **温室効果ガスの排出**
- 二酸化炭素(CO2)、メタン(CH4)、一酸化二窒素(...
Input: 以下の文章を要約してください:日本の伝統文化である茶道は、単なる茶を飲む行為以上の意味を持っています。茶道は、「和敬清寂」という四つの精神を基本としており、これは「和」(調和)、「敬」(尊敬)、「清」(清浄)、「寂」(静寂)を意味します。茶室での所作や道具の扱い方、客人へのもてなしなど、すべてにおいてこの精神が反映されています。茶道を通じて、人々は日常生活から離れ、静かな時間の中で自己を見つめ直す機会を得ることができます。また、季節の移ろいを感じ取り、自然との調和を学ぶこともできます。このように、茶道は日本文化の奥深さと美意識を体現する重要な芸術形態の一つと言えるでしょう。
Model: gpt-3.5-turbo-0125
Average processing time: 2.11 seconds
Average token generation speed: 76.36 tokens/second
Average input tokens: 330.00
Average output tokens: 162.60
Sample output: 茶道は、単なる茶を飲む行為以上の意味を持ち、「和敬清寂」の精神を基本としています。この精神は「和」、「敬」、「清」、「寂」を表し、茶室での所作や道具の扱い方、おもてなしに反映されています。茶道を通じて...
Model: gpt-4o-2024-05-13
Average processing time: 2.21 seconds
Average token generation speed: 58.40 tokens/second
Average input tokens: 231.00
Average output tokens: 127.00
Sample output: 茶道は単なる茶を飲む行為ではなく、「和敬清寂」(調和、尊敬、清浄、静寂)という四つの精神が基本となっています。茶室での所作や道具の扱い、客人へのもてなしにもこれが反映され、茶道を通じて静かな時間の中で...
Model: gpt-4o-mini-2024-07-18
Average processing time: 3.15 seconds
Average token generation speed: 44.54 tokens/second
Average input tokens: 231.00
Average output tokens: 138.80
Sample output: 茶道は日本の伝統文化であり、単なる茶を飲む行為に留まらず、「和敬清寂」という四つの精神(調和、尊敬、清浄、静寂)を基にしています。茶室での所作や道具の扱い、客人へのもてなしにこの精神が反映されており、...結果を簡単にまとめると、処理時間はgpt-3.5-turbo-0125が最も速く、次いでgpt-4o-2024-05-13、gpt-4o-mini-2024-07-18の順です。クオリティと回答の詳細を比べると、gpt-4o-2024-05-13とgpt-4o-mini-2024-07-18で、より詳細で高品質な回答を生成する傾向があり、複雑なタスクや深い理解が必要な場合に最適と言えるでしょう。
処理時間とクオリティを比較してみましたが、それに加えAPIのコスト面を含めて考えないといけないため今回の結果だけで答えを出すのは難しいかもしれません。
GPT-4oとGPT-4o miniの使い分け
GPT-4o miniは軽量化と高速性を追求する一方、出力精度においてはGPT-4oに劣るといった違いがあります。
以下のようなユースケースでは、GPT-4oを使うと良いかもしれません。
- 複雑な推論
- 専門的な知識を要する高度なタスク
- 長文生成や詳細分析
- ブラウジング
- 画像生成
ただ、以下のような小規模システム、リソースが限られた環境や簡易なテキスト処理のみであれば、GPT-4o miniを使用することで、コストを抑えながらAI活用ができます。
- スマートフォンやスマートウォッチなどのエッジデバイスでのリアルタイム処理
- ローカル環境でのデータ解析
- チャットボット
GPT-4o miniとClaude3.5 sonetのスピード比較してみた
GPT-4o miniが高速なのかをGPT4oとClaude3.5 sonetでも比較をしてみました。
まずは動画をご覧ください。
開始のタイミングに違いがあるかもしれませんが、それを踏まえても処理が完了したのは、以下の順番でした。
- GPT-4o mini
- Claude3.5 sonet
- GPT4o
今回の質問は一般的な知識としてモデル間でも差が出にくいであろうかつ、ある程度の複雑さがあるような質問にしています。
そのため、モデルの性能を比較するには妥当な質問かと思いますが、実際にご自分でも試してみると面白いかもしれません。
なお、Googleが発表している最強のLLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではGPT-4o miniについて詳しく解説を行いました。公式サイトやSNSでの批評をみていると、GPT-4o miniはエンドユーザー向けというよりも開発者向けとの印象を受けました。
特に大規模アプリケーションや複雑なアプリケーションを低コストで開発したい場合にGPT-4o miniは活躍するでしょう。
今度、GPT-4o miniを活用したアプリケーションがリリースされるのが楽しみですね!GPT-4o miniのAPIを使うことができる方は、ぜひ試してみてください!
最後に
いかがだったでしょうか?
ChatGPTなどを活用したAI導入でコスト効率と業務効率を最大化!貴社の課題に最適なソリューションを提供する方法を専門家がサポートします。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


