
【Japanese Stable CLIP】Stability AI開発の日本語特化型マルチモーダルAIを使ってみた!
WEELメディア事業部テックリサーチャーのゆうやです。
2023年11月15日、Stability AIより最新の日本語画像言語特徴抽出モデル「Japanese Stable CLIP」が公開されました。
このモデルは、ゼロショット画像分類や画像検索能力が大幅に向上し、日本語に特化したマルチモーダルタスクに対応可能です。
例えば以下のように、画像に写っている人物の職業を分類することなどができます。

このモデル自体は生成モデルではありませんが、これをモデルの一部とすることで、様々なマルチモーダルタスクを実現できます!
今回は、Japanese Stable CLIPの概要や使ってみた感想をお伝えします。
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Japanese Stable CLIPの概要
2023年11月15日、Stability AIから商用利用可能な日本語画像言語特徴抽出モデル「Japanese Stable CLIP」が公開されました。
このモデル単体では、ゼロショット画像分類(事前学習なしで画像分類)やテキストから画像を検索する画像検索などに用いることができます。また、他のモデルと組み合わせることで、text-to-imageや image-to-textといったマルチモーダルな生成タスクに拡張することが可能です。
Japanese Stable CLIPは、日本語に特化した画像言語抽出モデルで、学習には最新手法であるSigLIPを用いています。
SigLIPとは、言語と画像の事前学習用に特化したシンプルなシグモイド損失(Sigmoid loss)を使用して、画像-テキストペアの処理を強化する手法で、VLMやCLIPモデルの学習で用いられています。
そんなJapanese Stable CLIPは、オープンソースモデルで、STABILITY AI JAPANESE STABLE CLIP COMMUNITY LICENSEというライセンスで提供されており、商用利用も可能です。
さらに、Stability AIが行った評価では、オープンソース日本語対応CLIPモデルの中で最も高いスコアを獲得しています。
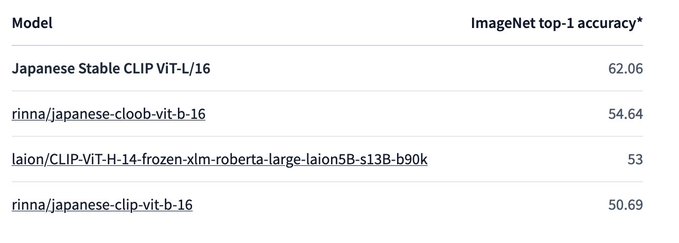
ただ、確かに日本語CLIPとしては最高の性能を有してますが、英語のCLIPモデルではImageNet top-1 accuracyのスコアが80以上のものあり、まだまだこれからだと開発者の方は意気込んでいます。
今後のさらに高性能なモデルを開発してくれることを期待しています!頑張ってください!
Japanese Stable CLIPは、デモ用Colabノートブックが公開されており、誰でも気軽に試すことが可能です。
ここからは実際に使ってみて、性能を検証してみようと思います!
なお、Stability AIの最新の日本語画像言語モデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Japanese Stable VLM】Stability AI、最新の日本語画像言語モデルを忖度抜きで使用レビューしてみた
Japanese Stable CLIPの使い方
Japanese Stable CLIPは、以下のColabノートブックを実行することで使用ができます。
基本的にはこれを実行すればよいだけですが、HuggingFaceのトークンが必要なのであらかじめ取得しておいてください。
また、画像分類に使用するカテゴリは、以下の画像の部分で任意のものに変更できます。
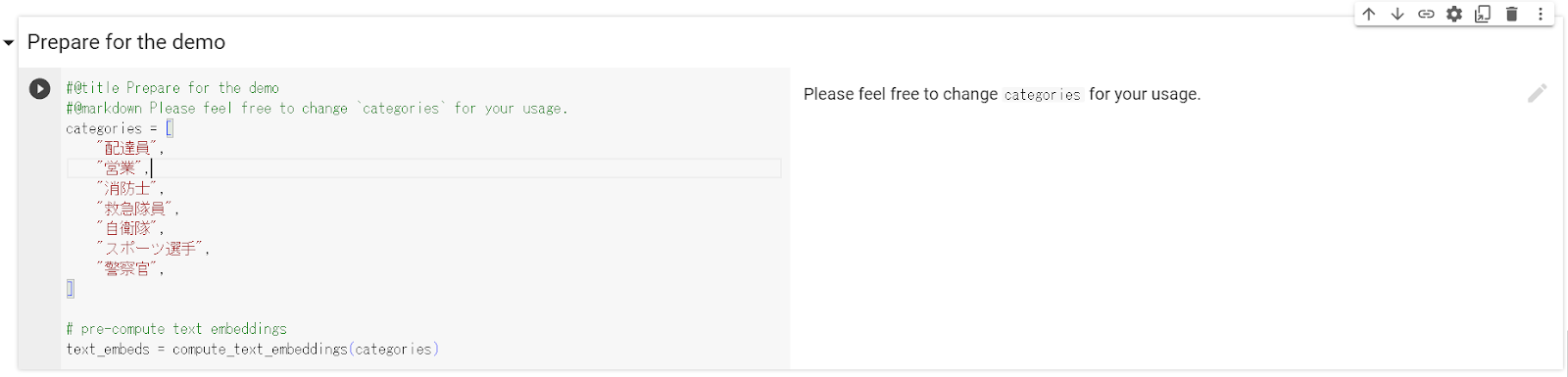
以下にローカルに実装する際のコードを掲載しておきます。
必要なパッケージのインストール
pip install ftfy regex tqdm gradio transformers sentencepiece 'accelerate>=0.12.0' 'bitsandbytes>=0.31.5'実装
#@title Load Japanese Stable CLIP
from typing import Union, List
import ftfy, html, re, io
import requests
from PIL import Image
import torch
from transformers import AutoModel, AutoTokenizer, AutoImageProcessor, BatchFeature
device = "cuda" if torch.cuda.is_available() else "cpu"
model_path = "stabilityai/japanese-stable-clip-vit-l-16"
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).eval().to(device)
tokenizer = AutoTokenizer.from_pretrained(model_path)
processor = AutoImageProcessor.from_pretrained(model_path)
# taken from https://github.com/mlfoundations/open_clip/blob/main/src/open_clip/tokenizer.py#L65C8-L65C8
def basic_clean(text):
text = ftfy.fix_text(text)
text = html.unescape(html.unescape(text))
return text.strip()
def whitespace_clean(text):
text = re.sub(r"\s+", " ", text)
text = text.strip()
return text
def tokenize(
texts: Union[str, List[str]],
max_seq_len: int = 77,
):
"""
This is a function that have the original clip's code has.
https://github.com/openai/CLIP/blob/main/clip/clip.py#L195
"""
if isinstance(texts, str):
texts = [texts]
texts = [whitespace_clean(basic_clean(text)) for text in texts]
inputs = tokenizer(
texts,
max_length=max_seq_len - 1,
padding="max_length",
truncation=True,
add_special_tokens=False,
)
# add bos token at first place
input_ids = [[tokenizer.bos_token_id] + ids for ids in inputs["input_ids"]]
attention_mask = [[1] + am for am in inputs["attention_mask"]]
position_ids = [list(range(0, len(input_ids[0])))] * len(texts)
return BatchFeature(
{
"input_ids": torch.tensor(input_ids, dtype=torch.long),
"attention_mask": torch.tensor(attention_mask, dtype=torch.long),
"position_ids": torch.tensor(position_ids, dtype=torch.long),
}
)
def compute_text_embeddings(text):
if isinstance(text, str):
text = [text]
text = tokenize(texts=text)
text_features = model.get_text_features(**text.to(device))
text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True)
del text
return text_features.cpu().detach()
def compute_image_embeddings(image):
image = processor(images=image, return_tensors="pt").to(device)
image_features = model.get_image_features(**image)
image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True)
del image
return image_features.cpu().detach()カテゴリ設定
#@title Prepare for the demo
#@markdown Please feel free to change `categories` for your usage.
categories = [
任意のもの
]
# pre-compute text embeddings
text_embeds = compute_text_embeddings(categories)gradioの起動
# @title Launch the demo
import gradio as gr
num_categories = len(categories)
TOP_K = 3
def inference_fn(img):
image_embeds = compute_image_embeddings(img)
similarity = (100.0 * image_embeds @ text_embeds.T).softmax(dim=-1)
similarity = similarity[0].numpy().tolist()
output_dict = {categories[i]: float(similarity[i]) for i in range(num_categories)}
del image_embeds
return output_dict
with gr.Blocks() as demo:
gr.Markdown("# Japanese Stable CLIP Demo")
gr.Markdown(
"""[Japanese Stable CLIP](https://huggingface.co/stabilityai/japanese-stable-clip-vit-l-16) is a [CLIP](https://arxiv.org/abs/2103.00020) model by [Stability AI](https://ja.stability.ai/).
- Blog: https://ja.stability.ai/blog/japanese-stable-clip
- Twitter: https://twitter.com/StabilityAI_JP
- Discord: https://discord.com/invite/StableJP"""
)
with gr.Row():
with gr.Column():
inp = gr.Image(type="pil")
with gr.Column():
out = gr.Label(num_top_classes=TOP_K)
btn = gr.Button("Run")
btn.click(fn=inference_fn, inputs=inp, outputs=out)
if __name__ == "__main__":
demo.launch(debug=True, share=True)これを実行すると、以下のような画面になり、Japanese Stable CLIPを使用できるようになります。
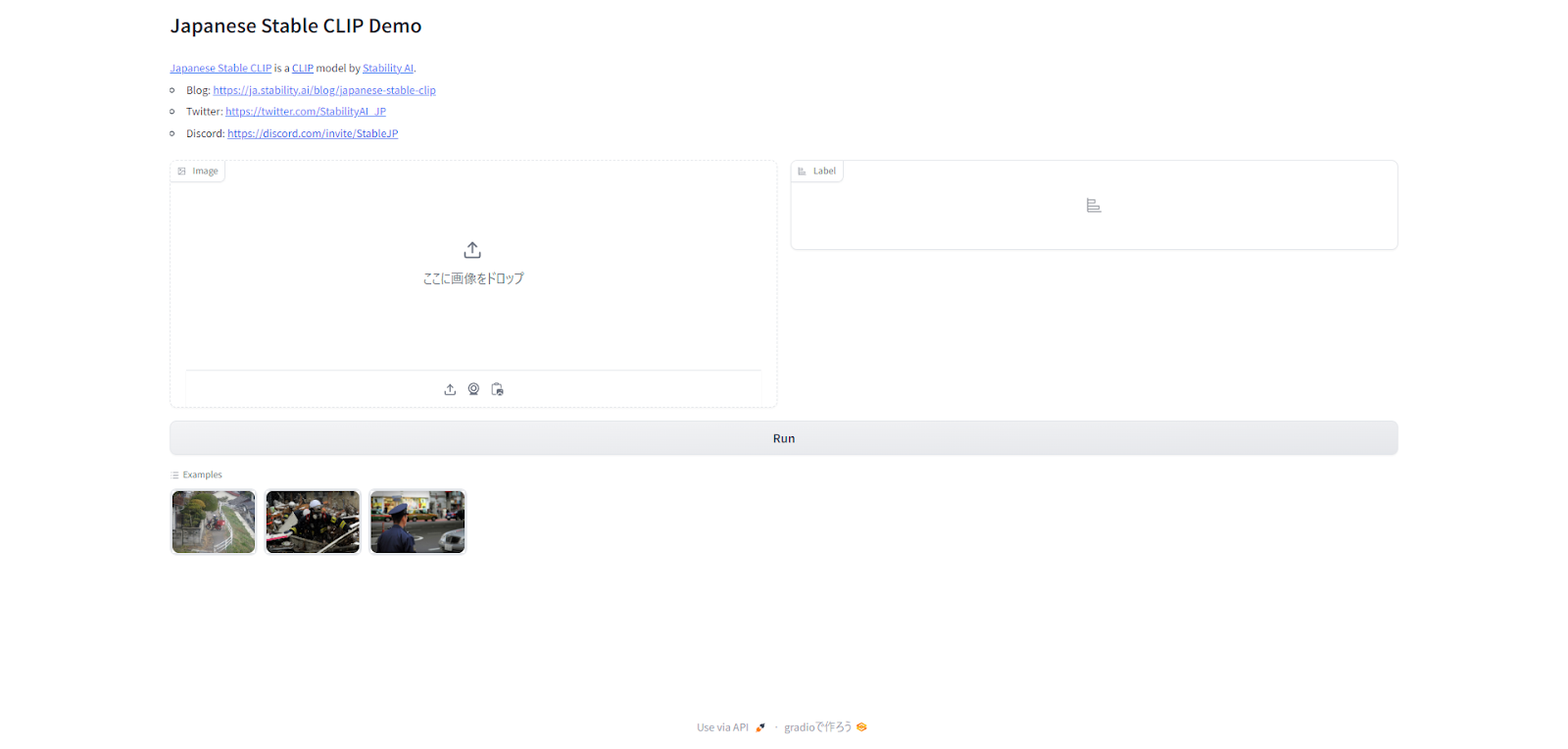
それでは早速使っていきましょう!

Japanese Stable CLIPを実際に使ってみた
Exampleであらかじめ用意されていた3種類の画像を入力してみます。
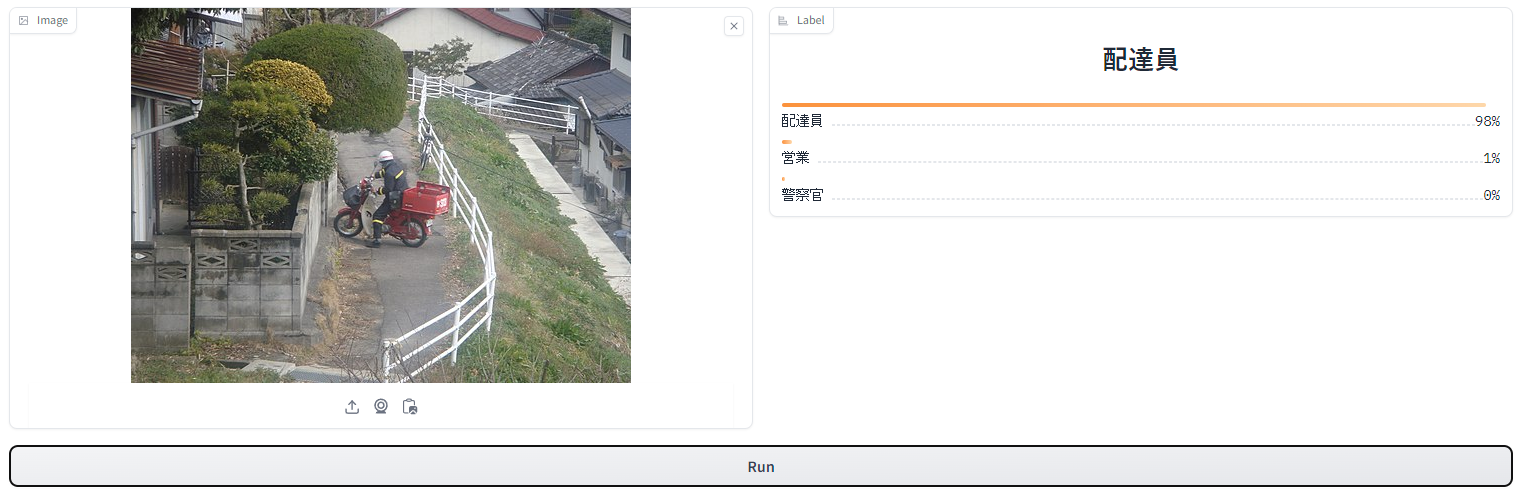
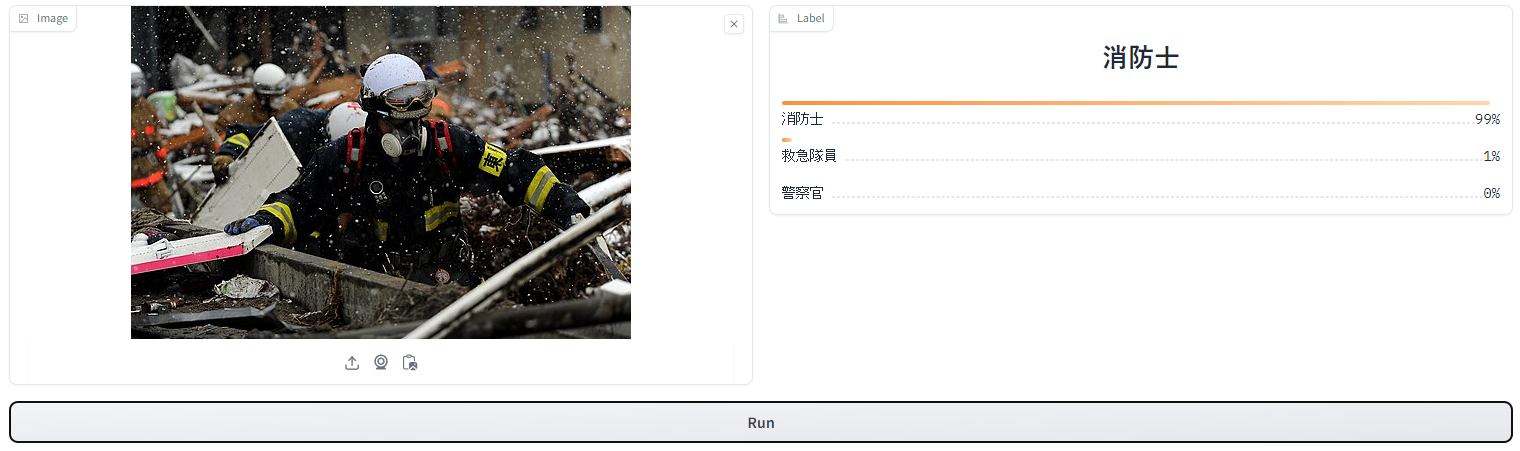
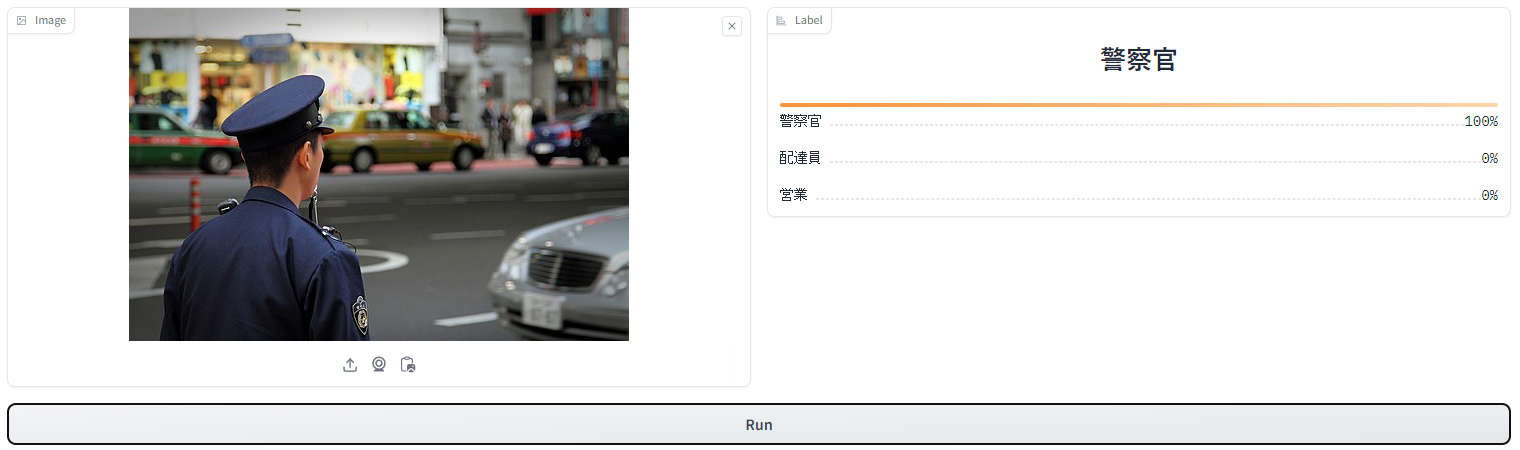
結果は、どの画像も正確に画像に写っている人物の職業を当てています。
3枚目に関しては100%警察官だと言い切っているので、かなり自信があるのでしょうね。
これは日本語CLIPモデルで最高の性能を持っているというのも本当のようです。
ここからは、風景や人物以外の対象物を分類させてみて結果がどうなるか検証してみようと思います。
Japanese Stable CLIPで色々なパターンの画像を分類させてみた
今回は風景の画像と人間以外が中心に写っている画像を入力してみます。
入力する画像と私が判断した画像の分類です。
田園風景

富士山

阿蘇山

シュナウザーが走っている

まずはカテゴリ設定をする必要があるので、決めていきます。
カテゴリ設定は、システムを惑わせるように似たようなものを複数設定します。
田舎の風景
盆地
都会の風景
田園風景
晴れた田舎
曇った田舎
富士山
阿蘇山
剣岳
高尾山
犬が走っている
犬が歩いている
猫が走っている
猫が歩いている
柴犬が走っている
シュナウザーが走っている
犬が寝ている
犬が座っている
犬が飛んでいるまずは最初の画像から実行してみます。
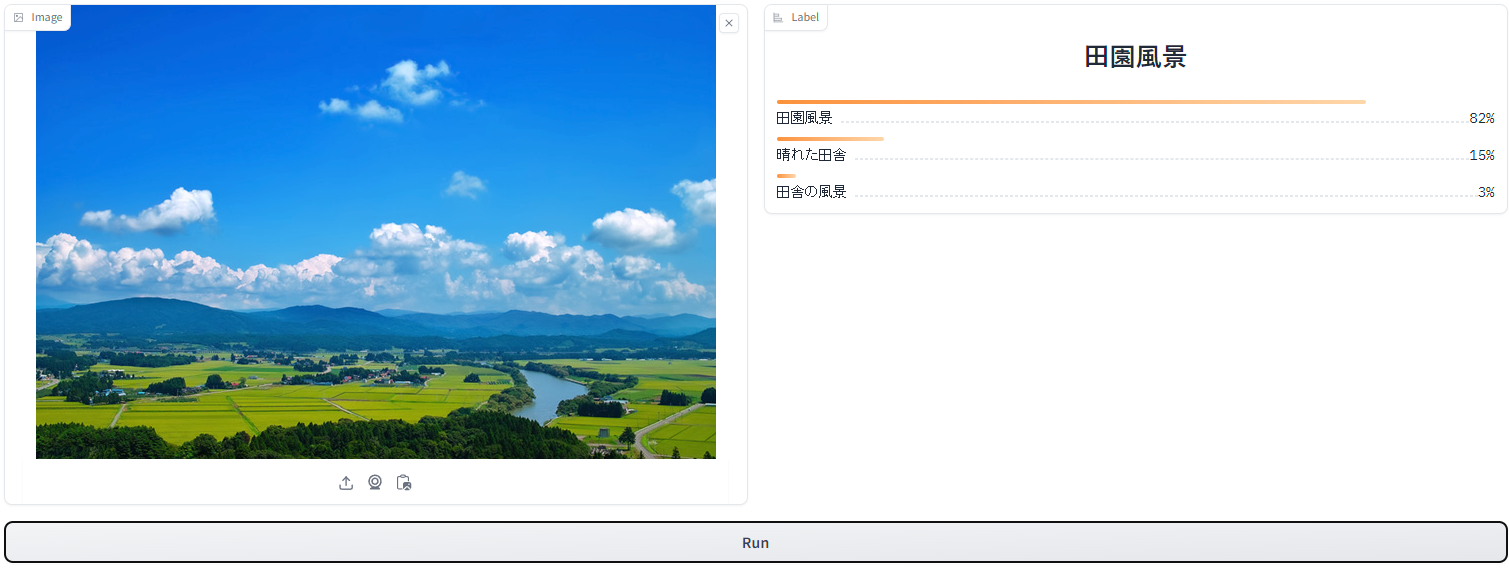
こちらは、画像の内容に合致するもののみがピックアップされて分類されました。
田園風景が82%と判断されており、人間と近い判断基準を持っているようですね。
続いて2枚目の画像です。
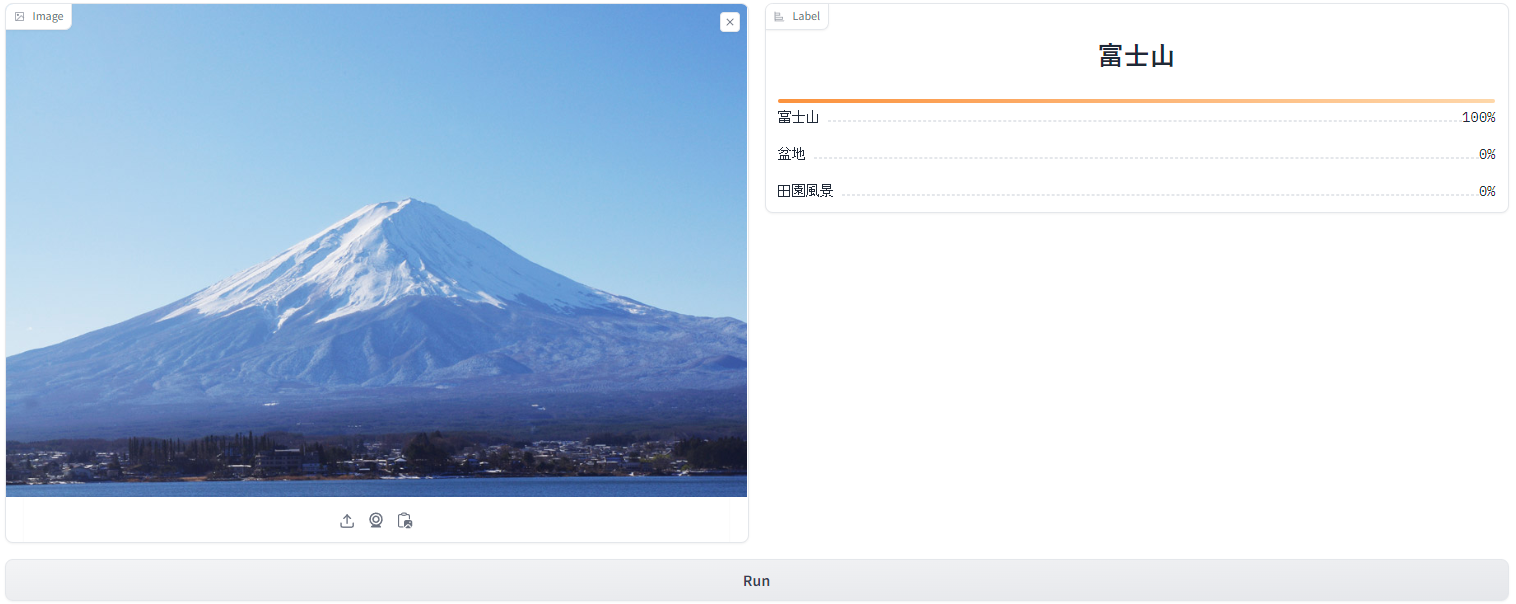
こちらは100%富士山だと判断しており、やはり特徴的なものは判断に自信があるようですね。
次は少しマイナーな阿蘇山の画像ですが、こちらはどのように判断するのでしょうか。
結果は以下のようになりました。
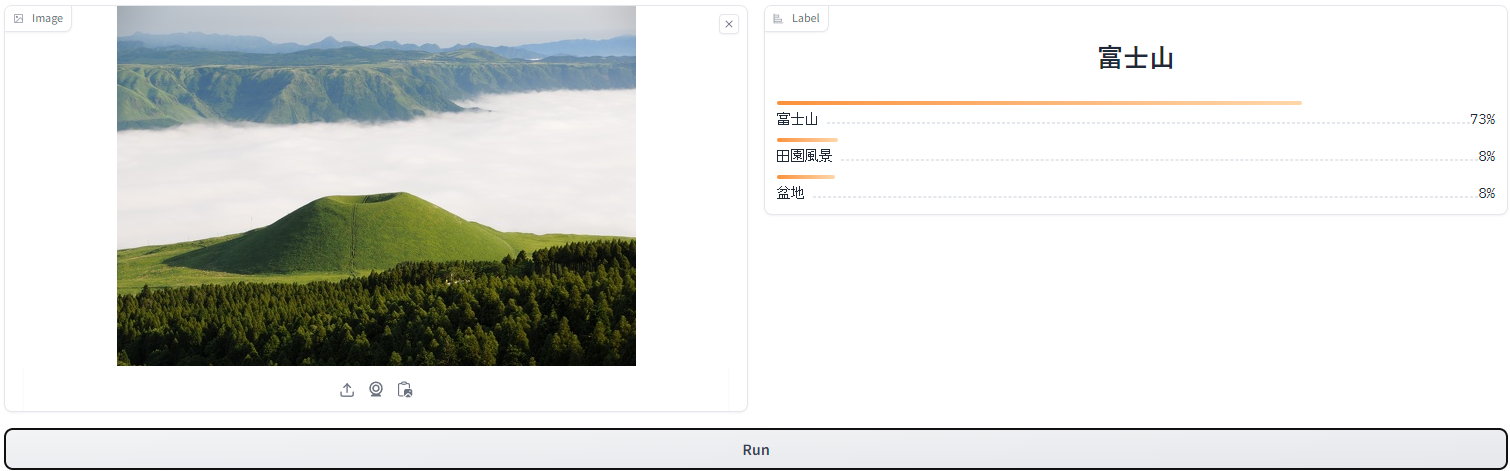
こちらは富士山と判断してしまっており、誤った分類をしてしまいました。
やはりマイナーなものは判断しきれないのでしょうか。
それでは最後のシュナウザーが走っている画像です。
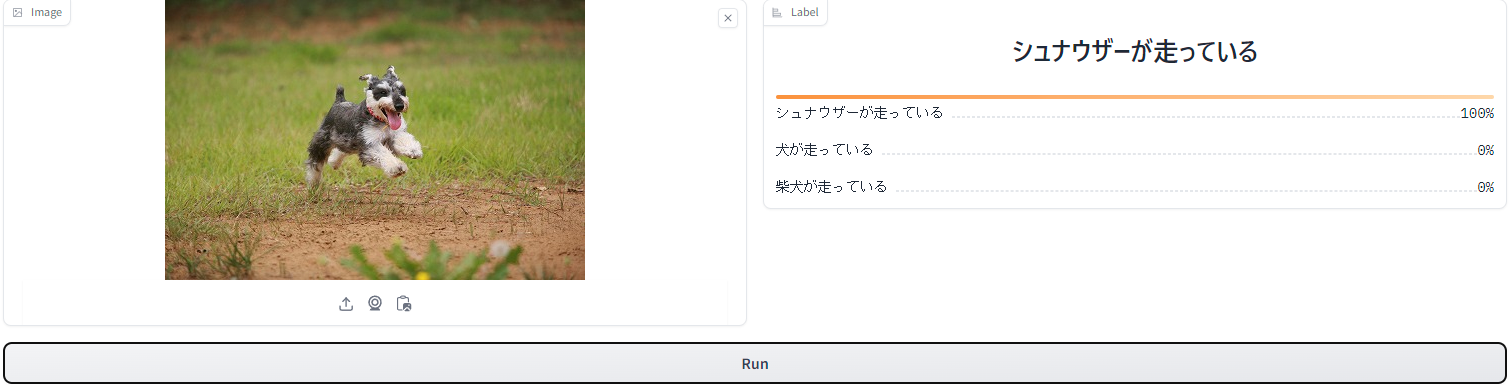
こちらは100%シュナウザーが走っている画像だと判断しています。
正直シュナウザーまでは識別できずに犬が走っていると判断するだろうと思っていたので驚きました。
今回の検証結果から、誤った判断をすることもりますが、おおよそ人間と同じように分類できるほどの性能を有していることが分かりました。
ただ、欠点としては分類するカテゴリーはあらかじめ自分で設定する必要があり、その中にあるものでしか分類してくれないので、使い勝手があまりよくない点です。
今後、このモデルを活用して高性能で使い勝手のいいマルチモーダルモデルがリリースされることに期待しましょう!
なお、StabilityAIの画像言語モデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Japanese Stable VLM】Stability AI、最新の日本語画像言語モデルを忖度抜きで使用レビューしてみた
まとめ
Japanese Stable CLIPは、Stability AIから公開された商用利用可能な日本語画像言語特徴抽出モデルで、ゼロショット画像分類(事前学習なしで画像分類)やテキストから画像を検索する画像検索などに用いることができます。
その性能は、オープンソースの日本語CLIPモデルの中では最高性能であり、今後もさらに開発を継続して英語のCLIPモデルに近い性能を目指すそうです。
また、他のモデルと組み合わせることで、text-to-imageや image-to-textといったマルチモーダルな生成タスクに拡張することが可能であり、更なる可能性を秘めています。
使ってみた感想は、使い勝手が悪い部分はあるものの、人間とほぼ同じレベルで画像を分類することができる性能を有していると感じました。
将来、この技術が発展して、「スター・ウォーズ」のように物体を識別できるドロイドが作られるようになるかもしれませんね!

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

