
【やってみた】Japanese Stable LM Alpha、Stability AIの日本語言語モデルを実践解説

画像生成AIツール「Stable Diffusion」で有名なStability AIが、日本語生成に特化したモデル「Japanese Stable LM Alpha」を発表しました。
AI活用を促進したい日本にとっては嬉しいLLMということで、今後多くの注目が集まることでしょう。
そこで今回は、Stability AIのJapanese Stable LM Alphaの概要や導入方法、そして実際に触ってみた感想を紹介します。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Japanese Stable LM Alphaの概要

Japanese Stable LM Alphaは、Stability AI がリリースした大規模言語モデルです。
70億パラメータを持つモデルが2つ公開されています。
(2023/10/10追加)さらに、最新版としてJapanese StableLM Instruct Alpha 7B v2も公開されています。こちらは、商用利用可能なモデルとなっています。
商用利用可能な「Japanese StableLM Instruct Alpha 7B v2」をリリースしました
まず1つは、Japanese StableLM Base Alpha 7Bという汎用言語モデル。
テキストの生成や理解などの一般的なタスクのために使われるものです。
学習データは、7500億トークンという大規模なもので、ウェブ上の日本語と英語のテキストデータで構成されています。
Apache Licencse2.0というライセンスのもとリリースされており、商用利用も可能です!
もう1つは、Japanese StableLM Instruct Alpha 7Bというは指示応答言語モデル。
ユーザーからの具体的な指示や要求に基づき、特定のアクションや応答のために使われるものです。
先程紹介したBaseモデルをファインチューニングしているので、「西郷隆盛はどんな人物ですか?」や「渋谷で楽しく遊ぶには」という質問への回答が可能です。

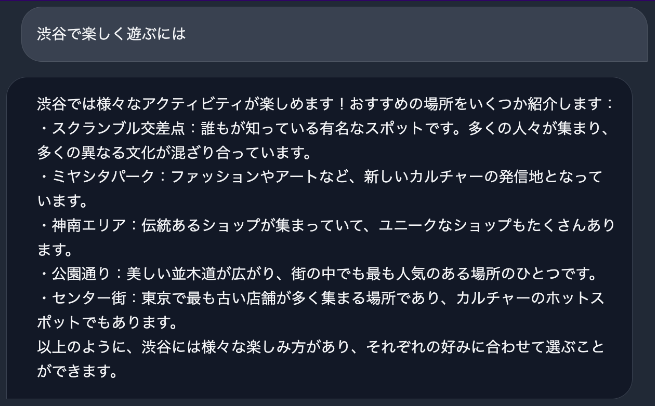
ただし、こちらの指示応答モデルは、研究目的での利用のみが許可されており、商用利用はできなさそうです。
また、この2つのモデルのパフォーマンスについて。
(2023/10/10追加)最新モデルも同等レベルの性能を持ち、商用利用を制限しないデータセットを使用しています。
既存の日本語生成モデルの中でもっともパフォーマンスが高いとのこと。
文の分類や質問応答、文章の要約といったタスクをもとに評価した結果がこちらです。

すごいですね。
ちなみに、どちらも現在、Hugging Faceで利用可能です。
(2023/10/10追加)最新モデルもHugging Faceで利用可能です。
筆者はプログラムを実行してみたので、次は導入方法を確認していきましょう。

Japanese StableLM Alphaの導入方法
Hugging Faceで公開されているステップをもとに導入方法をお伝えします。
筆者は、公開情報だけですんなり実行できなかったので、画像多めに解説していきます!
ぜひ参考にしてください!
まずは、汎用言語モデルであるjapanese-stablelm-base-alpha-7bから見ていきましょう!
japanese-stablelm-base-alpha-7bの場合
以下からGoogle Colabを開きます。

ランタイム→ランタイムのタイプを変更 をクリック。(ファイル名が違うのはご容赦ください)

V100 GPU を選んで、ハイメモリにして保存

以下を実行する。
!pip install sentencepiece einops transformers
モデルをダウンロードするために、以下を実行する
import torch
from transformers import LlamaTokenizer, AutoModelForCausalLM
tokenizer = LlamaTokenizer.from_pretrained("novelai/nerdstash-tokenizer-v1", additional_special_tokens=['▁▁'])
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/japanese-stablelm-base-alpha-7b",
trust_remote_code=True,
)モデルのダウンロードが終わったら、以下を実行。
prompt で、入力している文章である「AI で科学研究を加速するには、」の続きが生成されるはずです。
model.half()
model.eval()
if torch.cuda.is_available():
model = model.to("cuda")
prompt = """
AI で科学研究を加速するには、
""".strip()
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
# this is for reproducibility.
# feel free to change to get different result
seed = 23
torch.manual_seed(seed)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=128,
temperature=1,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)このような出力結果になりました。

テキストも貼り付けておきますー。
AI で科学研究を加速するには、データ駆動型文化が必要であることも明らかになってきています。
研究のあらゆる側面で、データがより重要になっているのです。
20 世紀の科学は、研究者が直接研究を行うことで、研究データを活用してきました。
その後、多くの科学分野ではデータは手動で分析されるようになったものの、これらの方法には多大なコストと労力がかかることが分かりました。
そこで、多くの研究者や研究者グループは、より効率的な手法を開発し、研究の規模を拡大してきました。
21 世紀になると、研究者が手動で実施する必要のある研究は、その大部分を研究者が自動化できるようになりました。
しっかり続きの文章が生成されてますね!
次は、指示応答モデルを確認していきましょう!
japanese-stablelm-instruct-alpha-7bの場合
以下は実際に動かしたプログラムです。まずはこちらからGoogle Colabを開きます。
ランタイム→ランタイムのタイプを変更 をクリック。(ファイル名が違うのはご容赦ください)
V100 GPUを選んで、ハイメモリにして保存
以下を実行する
!pip install sentencepiece einops transformers
次にHugging Faceのアクセストークンを取得します。
こちらのリンクにアクセス。必要に応じてアカウントの作成やログインをしてください。

以下のページにアクセスしたら、New tokenをクリック

以下のようにして、Generate a tokenをクリック。
Name:何でもOK
Role:read
アクセストークンをコピー。

以下プログラムの
access_token = “your-access-token”
をコピーしたものと置き換え実行しましょう。
モデルをダウンロードするための処理です。
import torch
from transformers import LlamaTokenizer, AutoModelForCausalLM
access_token = “your-access-token”
tokenizer = LlamaTokenizer.from_pretrained("novelai/nerdstash-tokenizer-v1", additional_special_tokens=['▁▁'],use_auth_token=access_token)
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/japanese-stablelm-instruct-alpha-7b",
trust_remote_code=True,
use_auth_token=access_token
)
model.half()
model.eval()
if torch.cuda.is_available():
model = model.to("cuda")モデルの設定が終わったら、以下のコードを実行しましょう!
user_queryで指定している「VR とはどのようなものですか?」に対しての応答が出力されるはずです。
# import torch
# from transformers import LlamaTokenizer, AutoModelForCausalLM
def build_prompt(user_query, inputs="", sep="\n\n### "):
sys_msg = "以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。"
p = sys_msg
roles = ["指示", "応答"]
msgs = [": \n" + user_query, ": "]
if inputs:
roles.insert(1, "入力")
msgs.insert(1, ": \n" + inputs)
for role, msg in zip(roles, msgs):
p += sep + role + msg
return p
# this is for reproducibility.
# feel free to change to get different result
seed = 42
torch.manual_seed(seed)
# Infer with prompt without any additional input
user_inputs = {
"user_query": "VR とはどのようなものですか?",
"inputs": ""
}
prompt = build_prompt(**user_inputs)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=256,
temperature=1,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0][input_ids.shape[1]:], skip_special_tokens=True).strip()
print(out)実行するとこのような出力が。

実際のプログラムは以下です。
バーチャルリアリティは、現実の世界のように見える仮想世界の 3D 仮想現実のシミュレーションです。
これは、ヘッドセットを介して、ユーザーが見たり、聞いたり、体験できるものです。「VR とはどのようなものですか?」に対する回答が出てますね!
japanese-stablelm-instruct-alpha-7b-v2の場合
以下は実際に動かしたプログラムです。まずはこちらからGoogle Colabを開きます。
ランタイム→ランタイムのタイプを変更 をクリック。(ファイル名が違うのはご容赦ください)

V100 GPUを選んで、ハイメモリにして保存

以下を実行します。
!pip install sentencepiece einops transformers以下プログラムを実行し、モデルをダウンロードします。
import torch
from transformers import LlamaTokenizer, AutoModelForCausalLM
tokenizer = LlamaTokenizer.from_pretrained(
"novelai/nerdstash-tokenizer-v1", additional_special_tokens=["▁▁"]
)
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/japanese-stablelm-instruct-alpha-7b-v2",
trust_remote_code=True,
torch_dtype=torch.float16,
variant="fp16",
)
model.eval()
if torch.cuda.is_available():
model = model.to("cuda")モデルの設定が終わったら、以下のコードを実行しましょう!
user_queryと、inputsから「情けは人のためならず」についてどのようなことわざか出力されるはずです。
def build_prompt(user_query, inputs="", sep="\n\n### "):
sys_msg = "以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。"
p = sys_msg
roles = ["指示", "応答"]
msgs = [": \n" + user_query, ": \n"]
if inputs:
roles.insert(1, "入力")
msgs.insert(1, ": \n" + inputs)
for role, msg in zip(roles, msgs):
p += sep + role + msg
return p
# Infer with prompt without any additional input
user_inputs = {
"user_query": "与えられたことわざの意味を小学生でも分かるように教えてください。",
"inputs": "情けは人のためならず"
}
prompt = build_prompt(**user_inputs)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=256,
temperature=1,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0][input_ids.shape[1]:], skip_special_tokens=True).strip()
print(out)
"""
「情けは人のためならず」は、「情けをかけるとその人のためにならない」という意味ではありません。
このことわざは、もともと「誰かのために行動するとその行動が回り回って自分に返ってくる」ということを説いたことわざです。
"""実行するとこのような出力が。

実際の出力は以下です。
「情けは人のためならず」は、「情けをかけるとその人のためにならない」という意味ではありません。
このことわざは、もともと「誰かのために行動するとその行動が回り回って自分に返ってくる」ということを説いたことわざです。「情けは人のためならず」に対する回答が出てますね!
以上で導入方法は終わりです。
なお、その他の高性能な日本語LLMについて知りたい方はこちらをご覧ください。
→【ELYZA-japanese-Llama-2-13b】東大スタートアップがGPT3.5を超えるLLMを開発!使い方〜実践まで
Japanese Stable LM Alphaを実際に触ってみた感想
Japanese Stable LM Alpha は、日本語に特化したモデルです。
パフォーマンスも類似モデルの中でもっとも高いということで、
日本語のニュアンスや文化を非常によく捉えられるのではないでしょうか?
有用なAIチャットはすでに多くありますが、この日本語モデルを活用したAIチャットなどさまざまなサービスが生まれてくることに期待です。
まとめ
Japanese Stable LM Alphaは、StabilityAIが開発した日本語に特化したLLM。
1つは、汎用言語モデルのJapanese Stable LM Base Alpha 7B 。
テキストの生成や理解などの一般的なタスクのために使われるもの。
商用利用可能です。
もう一つは、指示応答言語モデルのJapanese StableLM Instruct Alpha 7B。
ユーザーからの具体的な指示や要求に基づき、特定のアクションや応答のために使われるもの。
研究目的のみ利用可能で、商用利用はできません。
どちらも70億パラメータを持つモデルで、かつ、7500億トークンという大規模な学習データをもとに開発されました。
そのおかげか、既存の日本語LLMのなかで最もパフォーマンスが高い。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


