
【Japanese Stable VLM】Stability AI、最新の日本語画像言語モデルを忖度抜きで使用レビューしてみた

Japanese Stable VLMは、2023年11月13日にStability AI Japanから公開された最新の日本語画像言語モデル(Vison-Language Model:VLM)です。
このモデルは、入力画像のキャプションを生成できるだけでなく、入力画像についての質問にも回答できます。
また、画像のようにキャプションに入れてほしい単語をあらかじめ設定することもできます。

Stabilyty AIは、このモデルを画像と日本語を融合した「商用利用可能」な革新的なモデルと謳っており、簡単に画像の説明や画像に関する質疑応答ができます。
現在、このモデルのリリース告知ポストには700以上のいいねがついており、注目を集めています。
今回は、Japanese Stable VLMの概要や使ってみた感想をお伝えします。
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Japanese Stable VLMの概要
Japanese Stable VLMは、2023年11月13日にStability AI Japanから公開された最新の日本語画像言語モデル(Vison-Language Model:VLM)です。
このモデルは、入力画像のキャプションを生成できるだけでなく、キャプションに入れてほしい単語をあらかじめ設定することもできます。
また、画像についてのユーザーの質問に回答する機能も搭載されており、マルチな機能を持つVLMとなっています。
Japanese Stable VLMは、Stability AIが開発したJapanese Stable LM Instruct Gamma 7Bをベースに開発されており、日本語による高精度のキャプション生成および質疑応答を可能にしています。
実はこれ以前に、研究目的で構築されたJapanese InstructBLIP Alphaという画像キャプション生成が可能なモデルが公開されているのですが、今回のJapanese Stable VLMはさらに進化したモデルになっています。
具体的な違う点を紹介します。
- 商用利用可能なライセンスで提供
- 最新手法 LLaVA-1.5 のモデル構造・学習手法を適用
- ベースとする言語モデルを「Japanese StableLM Instruct Alpha 7B」から、最新の「Japanese Stable LM Instruct Gamma 7B」に変更した
- 新規に開発された独自機能の「タグ条件付きキャプショニング」機能を搭載
このモデルはSTABILITY AI JAPANESE STABLE VLM COMMUNITY LICENSEで提供されており、商用利用するには条件を満たす必要があります。条件は、以下のリンクからご確認ください。
STABILITY AI JAPANESE STABLE VLM COMMUNITY LICENSE
性能については詳しい情報は公開されていませんが、Stability AIの社内評価では、Japanese InstructBLIP Alphaと同等レベルの性能を有しているとのことです。
同等の性能できることが増えて、商用利用もできるって感じですね!
また、前述したように、画像についてのユーザーの質問に回答する機能も搭載されているのですが、これは動画のフレームを抜き取ることで、リアルタイムの動画のキャプショニングや質疑応答もできるようです。

Japanese Stable VLMは、モデルが公開されており、誰でもダウンロードして試すことができるので、実際に使ってみようと思います!

Japanese Stable VLMの使い方
Japanese Stable VLMは、Google Colabでノートブックが公開されているので、そこから使用できます。
基本的には実行ボタンを押していくだけでgradioが起動して使用することができるのですが、いくつか注意点があります。
まず、Japanese Stable VLMを使用するには、以下のHugging Faceのページで、連絡先情報の共有に同意する必要があるので、それを行ってください。
stabilityai/japanese-stable-vlm
次に、Colabでload_inを設定する部分があるのですが、もし無料プランで使用している場合はint8を設定し、有料プランでA100などのGPUを使用できる場合は、fp32かfp16を選択してください。
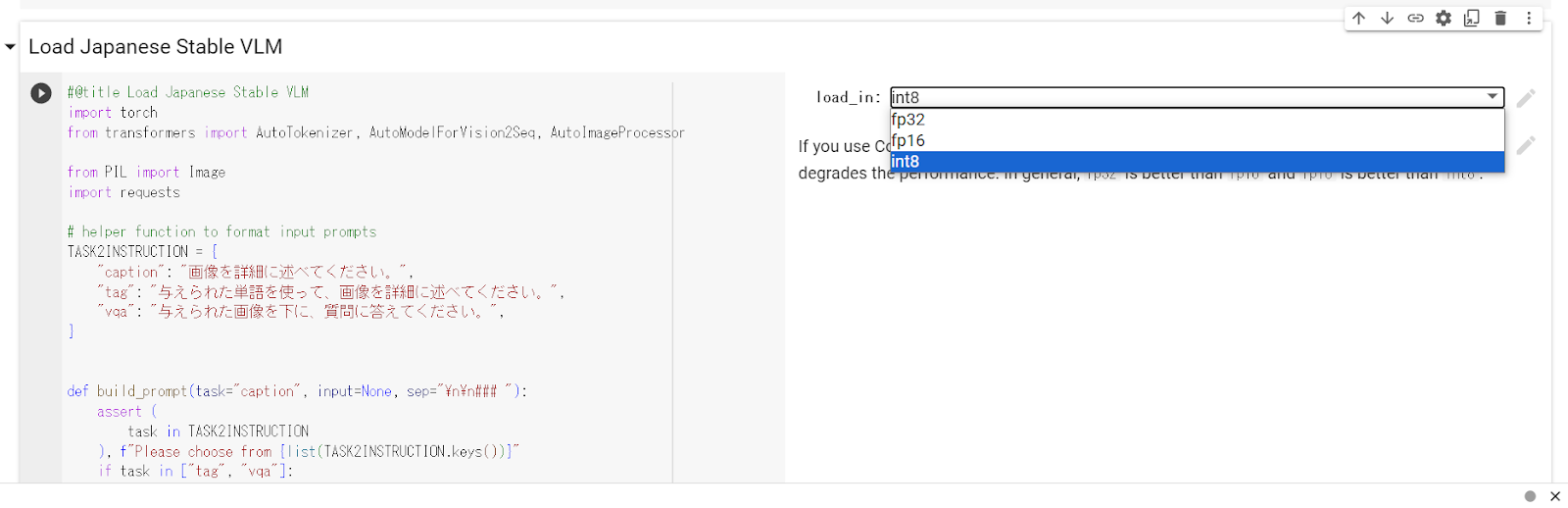
ただし、int8ではパフォーマンスが低下することがあり、fp32はfp16より優れているようなので、有料プランでA100GPUを使用し、fp32を選択するのが最も良いでしょう。
それでは実際に実行してみましょう!
なお、StabilityAIの日本語LLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Japanese Stable LM Gamma 7B】Stability AI史上最強の日本語LLMが誕生!?
Japanese Stable VLMを実際に使ってみた
それでは実際に使っていきましょう!
先ほどのColabのノートブックを、上から実行していけばgradioのurlが出力されて使用できるようになります。
以下のような画面になります。
taskは、「caption」「tag」「vqa」の3つがあるのでそれぞれ試してみようと思います。
なお、パラメータなどはすべてデフォルトのままで行います。
画像はこの画像を入力します。

caption
以下のキャプションを生成しました。
0: キッチンで踊る猫
1: キッチンで踊る猫のアニメーション
2: 台所に立っている猫のシェフ簡単ではありますが、画像の特徴を捉えられていると思います。少なくとも間違った出力はしていません。
tag
tagではキャプションに入れてほしい単語をinputに入力できます。
今回は、猫だけでなく画像全体の情報を含んだものを生成してほしいので、このようにタグ付けします。
窓、日差し、トマト、スマホ生成されたキャプションがこちらです。
0: 窓、日差し、スマホを背景にしたキッチンで踊る猫
1: 窓、日差し、スマホを背景にした台所で踊る猫
2: 窓、日差し、スマホを背景にしたキッチンの猫のシェフちょっと想定していたものとは違いますね。
タグ付けした単語をそのまま先頭にくっつけただけのように見えます。
vqa
vqaはinputに画像に関する質問を入力することでその質問の回答を出力してくれます。
結果ですが、上の画像では何を入力してもinputがそのまま返ってくる結果になりました。
ですが、あらかじめ用意されていたサンプル画像では下の画像のように機能したので、そちらで紹介します。
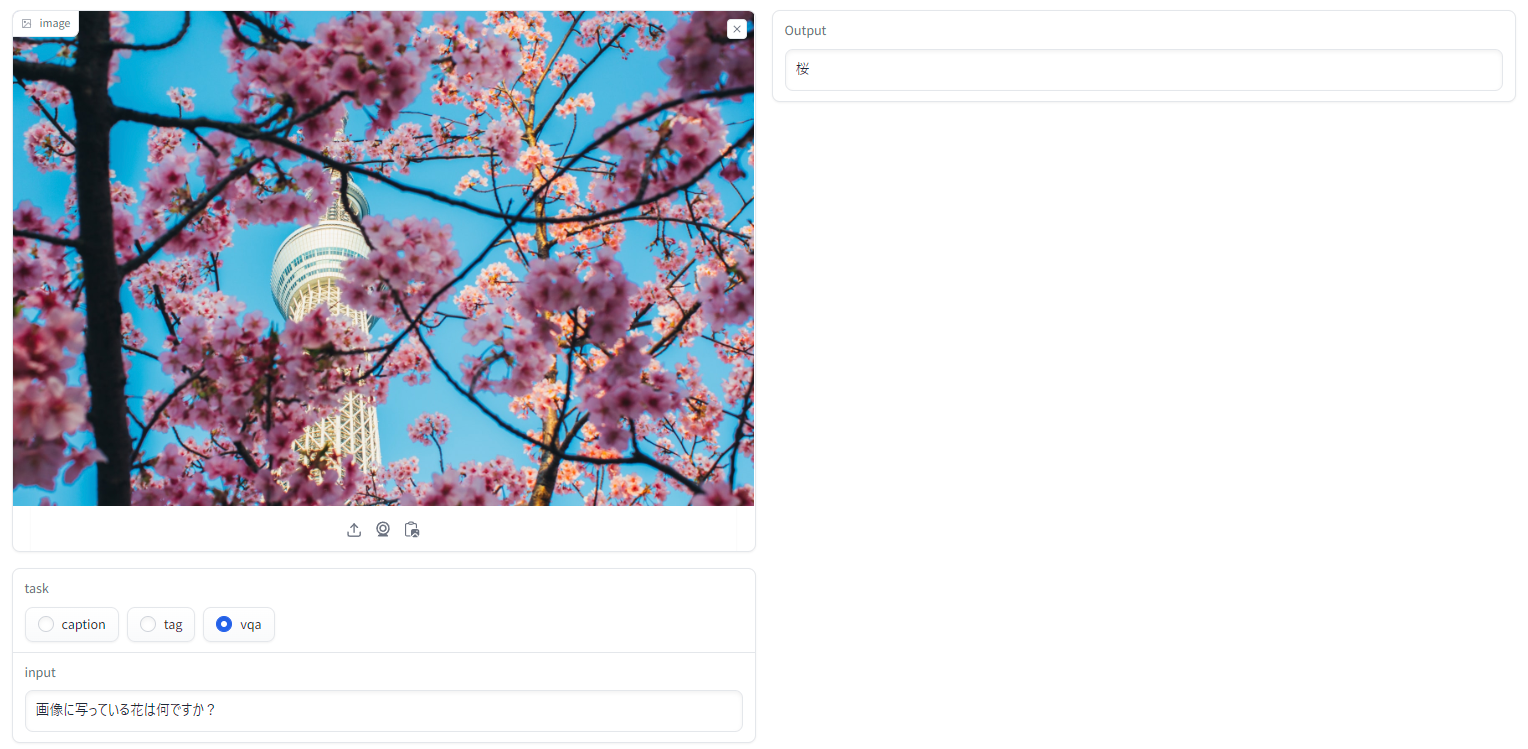
いくつか質問してみた結果です。
画像に写っている花は何ですか? → 桜
桜は何色ですか? → ピンク
後ろに写っている建物は何ですか? → スカイツリー
写真が撮られた時間は何時くらいか分かりますか? → 分かりません。画像にあるものの説明はできるようですが、推測などはできないようです。
推測ができればもっと使い道があるように思います。今後の発展に期待しましょう!
一通り使えることが分かったので、もっと色々なパターンの画像を入力して結果を見てみようと思います!
Japanese Stable VLMに様々なパターンの画像を入力してみた
いくつかのパターンの画像を入力して、出力がどのように変化するか見ていきます。
まず入力するのは、DALL-E3で「複雑な画像を生成して」というプロンプトで生成された画像です。

実際かなり複雑な画像ですね。
この画像で3つのタスクでどのような出力がされるのか試します。
caption
0: ストックホルダーによるイラスト
1: ストックホルダー、イラストレーター
2: ストックホルダーのイラスト全くダメでした。
もしかしたらAIで生成された画像ではエラーが起きるのかもしれません。
tag
以下のようにタグを設定しました。
飛行船、時計、夕日生成されたキャプションです。
0: 飛行船、時計、夕日
1: 飛行船、時計
2: 飛行船、夕日こちらもcaptionと同様に全く期待していない出力でした。
これは生成された画像ではエラーになる説が有力です。
vqa
何個か質問してみようと思いましたが、最初の質問から下の画像のようにバグってしまっているためやめました。
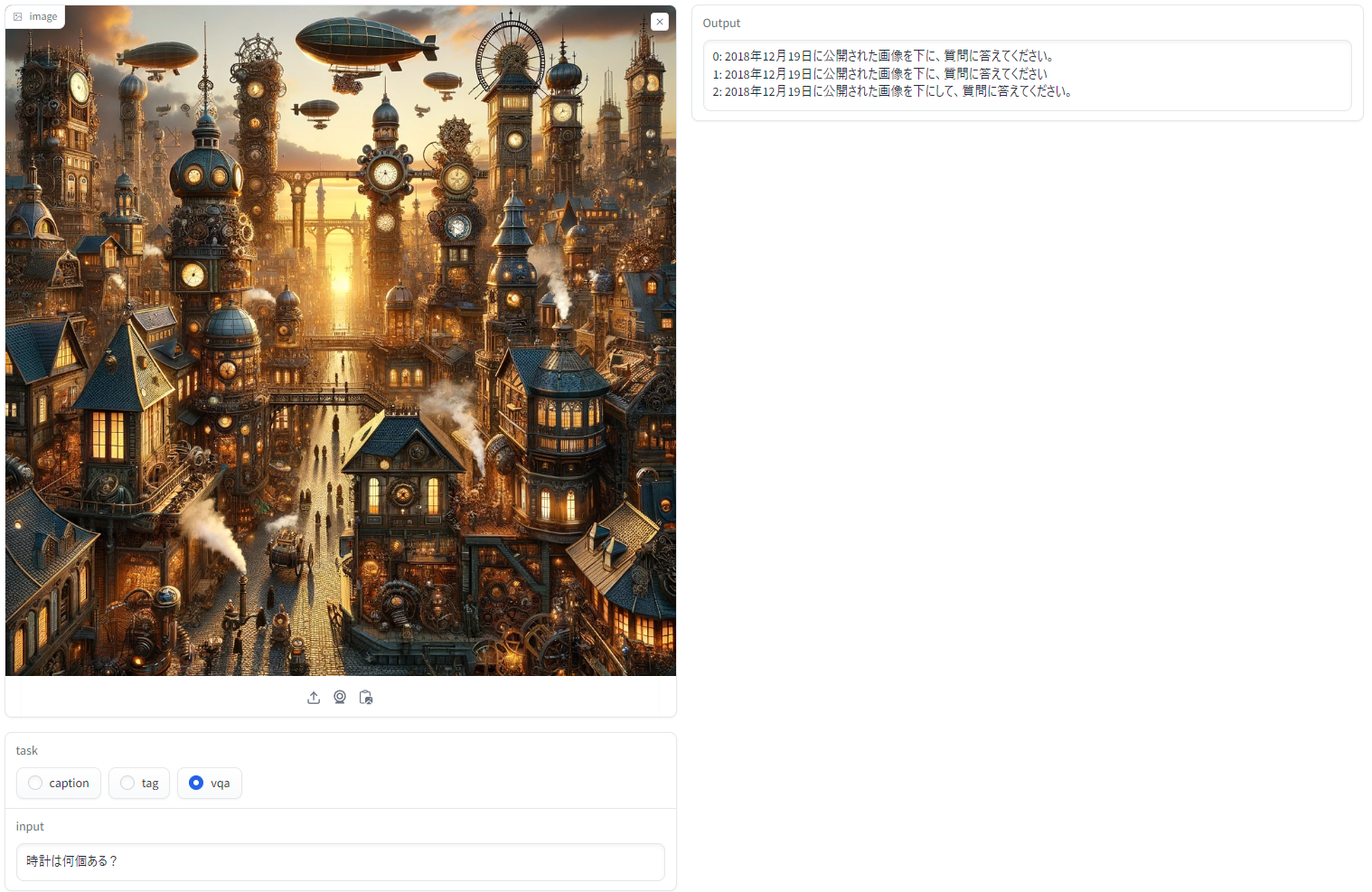
おそらく生成された画像ではエラーになってしまうので、次は撮影された下の写真でやってみようと思います。

こちらもなかなか情報量が多い画像ですが出力はどうなるでしょうか。
caption
0: 横断歩道を渡る人々
1: 横断歩道を渡る人々のグループ
2: 横断歩道を渡る人々の群衆こちらは簡単ではありますが正しいキャプションが生成されました。
もう少し詳しいキャプションが生成されてもいい気はしますが、これがこのモデルの性能なのかもしれません。
tag
以下のようにタグを設定しました。
クロックス、派手な髪以下のようなキャプションが生成されました。
0: 横断歩道を渡る白い靴と派手な髪の人々
1: 横断歩道を渡る人々、派手な髪と白い靴
2: 横断歩道を渡る派手な髪と白い靴の人々白い靴と派手な髪をタグ付けすると、中心に写っている人物にフォーカスされるかと思いましたが、そうではなく全員が白い靴で派手な髪ということになってしまいました。
ここまでみると正直性能が高いとは言えませんね。
vqa
質問と回答の一覧です。
一番手前の人が履いている靴の色は何色ですか? → 0: 青色 1: 白色 2: 黄色
中心に写っている人の髪は何色ですか? → 0: 茶色 1: 黒色 2: 金髪
左の人が履いているズボンの色は何ですか? → 0: 黒です。 1: 青 2: 青です。
写真が撮影された時間帯は分かりますか? → 0: 分かりません。 1: 朝から昼にかけての時間帯だと思います。 2: 朝から昼にかけての時間帯です。結果は、なぜか回答が3つずつ出力されるようになってしまい、質問に対する答えとしては不適切なものだと思います。
内容については、大体3つの中に正解はあるのですが、私が意図していたような回答ではなかったので残念です。
全体的な結果としては、先ほどの生成された画像よりはよくなったものの、決して性能が高いとは言えない結果となりました。
サンプルで入力されていた画像とそんなに違いはないはずなのになぜこのような結果になってしまったのでしょうか。
もっと単純な画像ならうまくいくでしょうか?
以下の画像で再チャレンジしてみましょう。

captions
首輪をつけた小さな犬がベランダに座っているtag
設定したタグ
首輪、タグ生成キャプション
首輪にタグが付いた小さな犬vqa
首輪の色は何? → オレンジ
犬の気分を教えて → 不機嫌
この犬の犬種は何? → 柴犬
犬についているタグの素材は? → 金属結果はすべてのタスクで画像の内容をばっちり把握してキャプションを生成してくれています。
特にvqaでは、写っている犬の特徴を完璧に捉えて回答を出力してくれています。
やはり、これまで入力していた画像は複雑すぎて対応しきれていなかったようです。
今回の検証では、単純な画像であれば正確なキャプションの生成と質疑応答ができるが、複雑な画像ではエラーが発生して、キャプションのや応答の精度が極端に悪くなることが分かりました。
今後のアップデートで、今回検証したような複雑な画像にも対応した画像言語モデルが開発されることに期待しましょう!
なお、東工大が開発した日本語LLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Swallow】東工大の日本語特化の大規模言語モデル!使い方〜日本語性能比較まで
まとめ
Japanese Stable VLMは、入力画像のキャプションを生成できる日本語画像言語モデル(Vison-Language Model:VLM)で、さらにキャプションに入れてほしい単語をあらかじめ設定したり、入力画像についてのユーザーからの質問にも回答できます。
Japanese Stable LM Instruct Gamma 7Bをベースにして、LLaVA-1.5 のモデル構造・学習手法が適用されており、条件を満たせば商用利用も可能です。
実際に使ってみた感想は、単純な画像に対してはそれなりのキャプションや応答を出力してくれますが、もう少し詳細な出力がされると期待していたので、そこは残念でした。
また、情報量の多い複雑な画像を入力すると、出力の精度が極端に悪くなってしまう欠点を発見したので、今後のモデルでは改善されることに期待します。
Stability AIでは、今後も商用利用可能なモデルを積極的に開発して公開するそうなので、こういったモデルがどんどん世の中で活用されていってさらに便利になることでしょう!

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

