
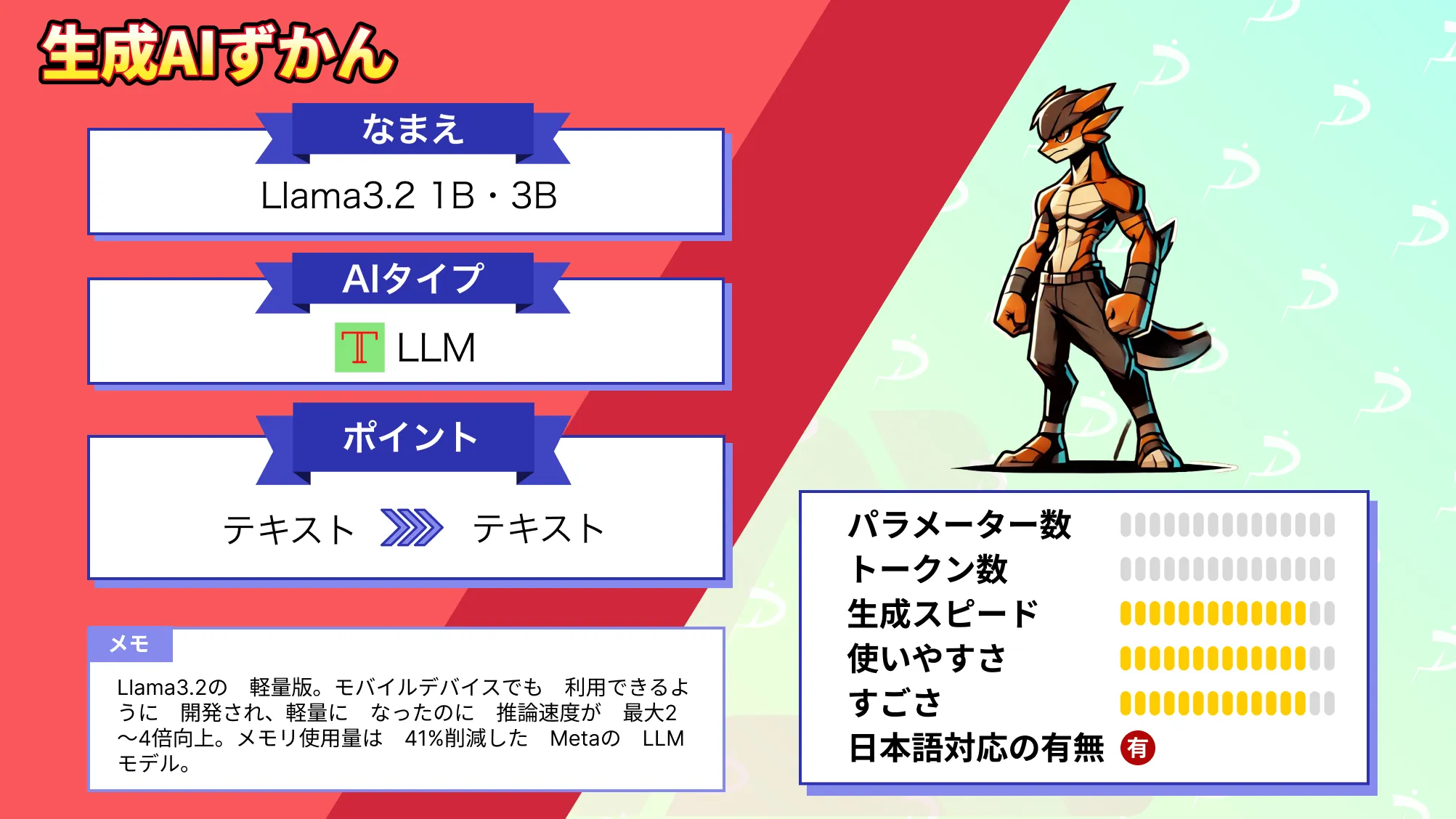
Metaの軽量版Llama 3.2-1Bと3Bが公開!4倍の推論速度をGoogle Colabで体感してみた
2024/10/25、Metaから新たなLLMモデルがリリース!
リリースされたモデルはLlama3.2 1Bと3Bで、モバイルデバイスでも利用できるように開発されています。
軽量になっており、推論速度が最大2~4倍向上しているとのこと。
本記事ではLlama3.2 1Bと3Bについて紹介し、google colaboratoryで実装する方法をお伝えします。本記事を最後まで読めば、あなたもLlama3.2軽量版を実装できるようになります。
ぜひ最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
Llama 3.2軽量版の概要
Llama3.2はMetaによって2024年10月に発表された最新の量子化大規模言語モデルであり、特にモバイルデバイスでの利用に最適化されています。
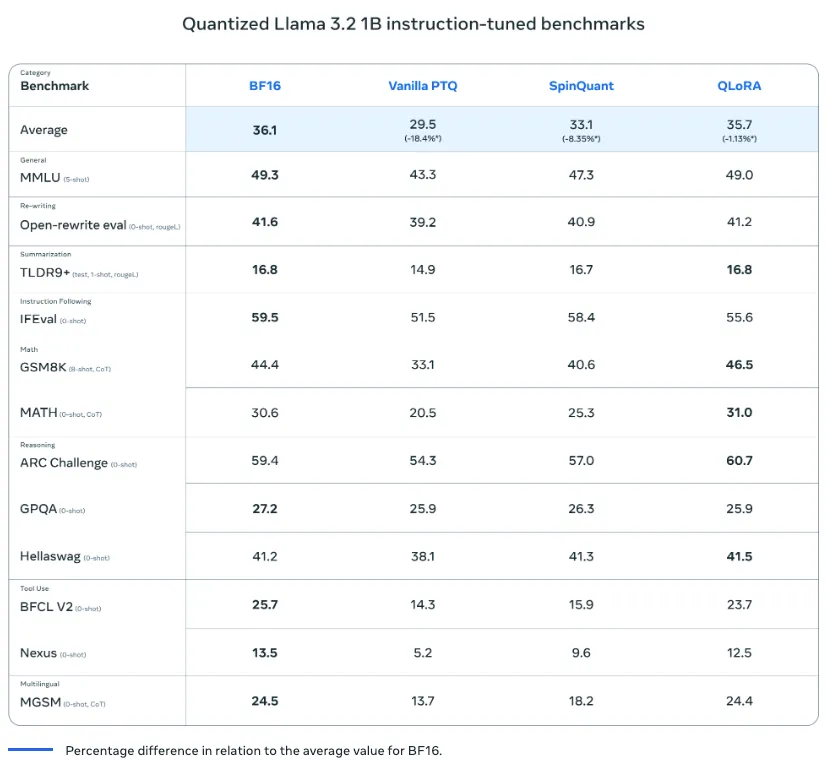
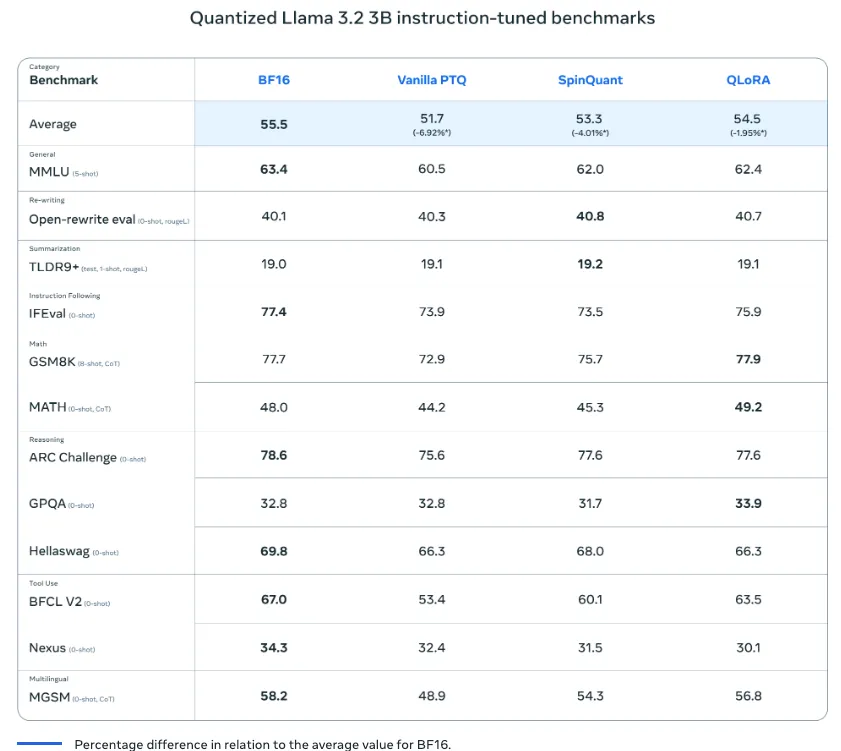
このモデルには1Bおよび3Bのパラメータバージョンが提供され、一般的なモバイル端末でも軽量かつ高速に動作可能です。量子化技術の導入により、モデルのサイズは56%、メモリ使用量は41%削減され、速度も従来より2~4倍向上しています。
Llama3.2軽量版の特徴
Llama3.2は、モバイルデバイスでの利用に特化した設計が最大の特徴です。
一般的なモバイルデバイスでもスムーズに動くように軽量化が施され、従来モデルと比べて高速かつ省メモリでの動作が可能となっています。
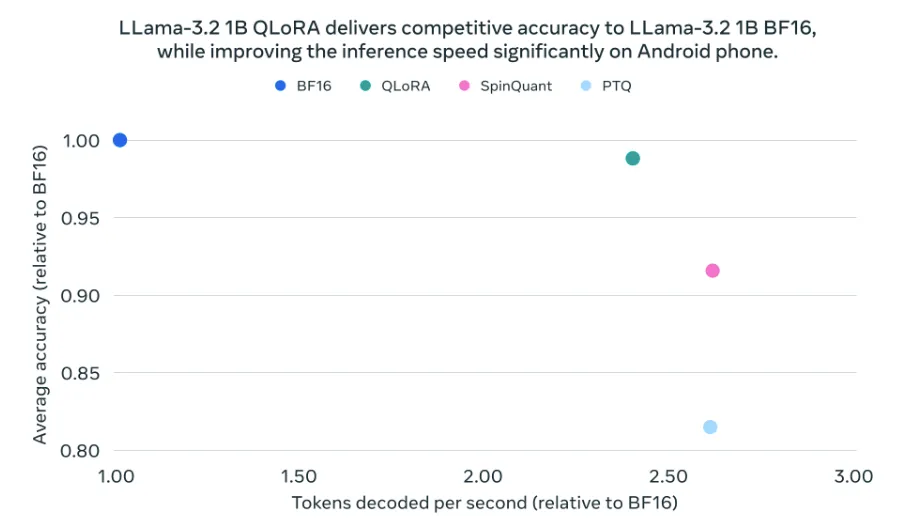
これは量子化技術を導入することで、BF16フォーマットよりも2〜4倍速い処理速度が実現され、さらにモデルサイズが56%、メモリ使用量が41%削減。
このアップデートにより、デコードやプリフィルのレイテンシも大幅に短縮されており、モバイルデバイスでもより効率的なAIアプリケーションが展開できます。
また、Llama3.2は低精度環境でも高い精度を維持するために、量子化認識トレーニング(QLoRA)とLoRAアダプターを使用。
これにより、通常のトレーニングを行う際に量子化の効果をあらかじめシミュレートし、低精度環境でも精度を保つ工夫がされています。さらに、SpinQuantというポストトレーニング量子化技術も併用されており、この手法はトレーニングデータにアクセスせずとも量子化が可能で、データやリソースが限られた環境でも柔軟に導入可能です。
QLoRA
QLoRAはモデルの量子化に対する効果をトレーニング中にシミュレーションすることで、低精度環境においても高い精度を維持する手法です。
この技術では、従来のトレーニング手順に加え、量子化の影響を取り入れたトレーニングを行い、モデルの精度を向上させます。QLoRAではLoRAアダプターが使用され、モデル内の全てのトランスフォーマーレイヤーに適用されるため、量子化後もモデルの性能を損なわないよう工夫されています。
LoRAアダプター
元のモデルに比べて少ないパラメータで効率的に適応・調整が可能な仕組みです。
QLoRAのアプローチでは、このアダプターを利用して低精度でのトレーニングや推論が可能です。LoRAアダプターの導入により、メモリや計算資源を抑えながらもモデルの精度や汎用性を確保します
SpinQuant
トレーニング後に行われる量子化技術(ポストトレーニング量子化)であり、データセットにアクセスせずとも、精度を一定に保ちながらモデルを圧縮できる手法です。
この手法では、計算資源やデータが制限されている環境にも適しており、圧縮と精度維持のバランスを最適化するよう設計されています。SpinQuantは、各トランスフォーマーレイヤーの線形層や埋め込み層を効率的に量子化することで、モデル全体の計算負荷を削減しつつも高精度を実現しています。
Llama 3.2軽量版のライセンス
Llama 3.2軽量版はLlama 3.2 Communityライセンスです。そのため、月間アクティブユーザーが7億人未満の場合は商用利用可能。それを超える場合はMetaの許可が必要になります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、Claude 3.5 SonnetやGPT-4o超える実力の「Llama-3.1-Nemotron-70B-Instruct」について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Llama 3.2軽量版の使い方
ここからは実際にgoogle colaboratoryでLlama3.2軽量版を実装します。
まずはHugging Faceのページにアクセスします。
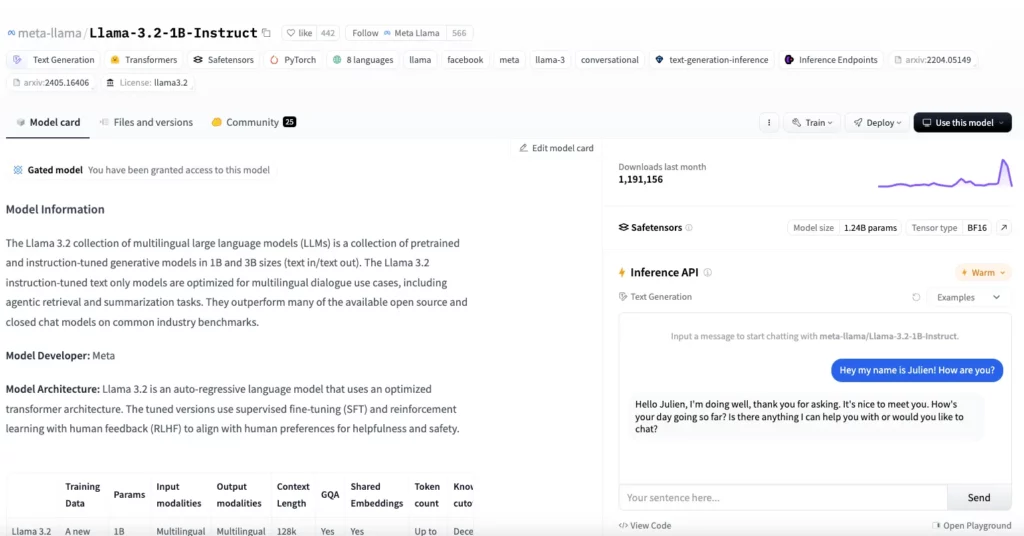
画面に「Gated model You have been granted access to this model」と書かれていれば承認されているので、そのまま使うことができます。
もし書かれていない場合には、名前や所属先を入力して登録できるフォームがあるので、そこから使用することも可能です。
また、承認が必要なため、Hugging FaceのAPIキーも必要です。まだ取得していない場合には取得しておきましょう。
Hugging FaceのAPIキー取得
画面向かって右上の丸をクリック後、「Settings」をクリック
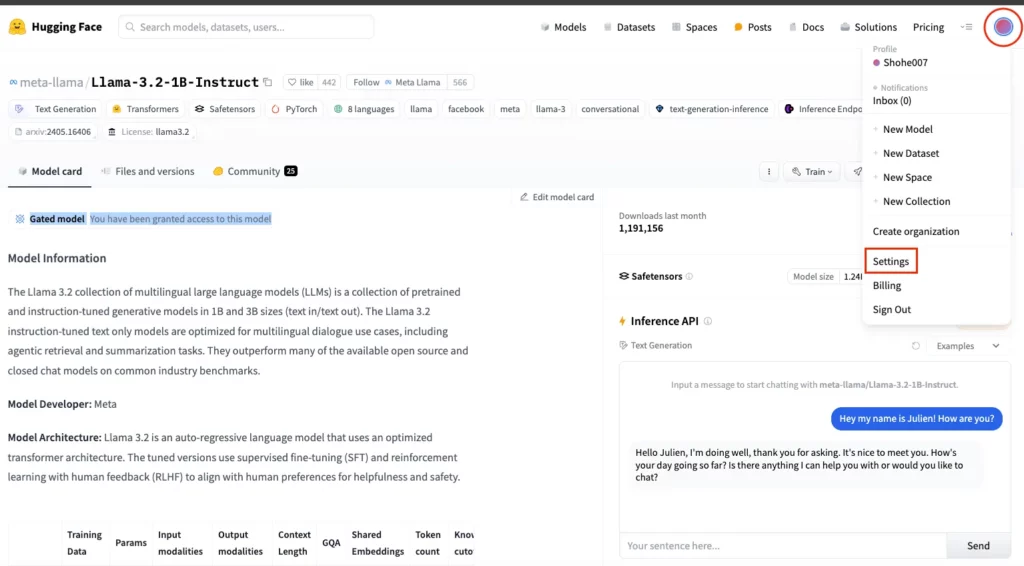
画面向かって左に「Access Tokens」があるのでそちらをクリック。
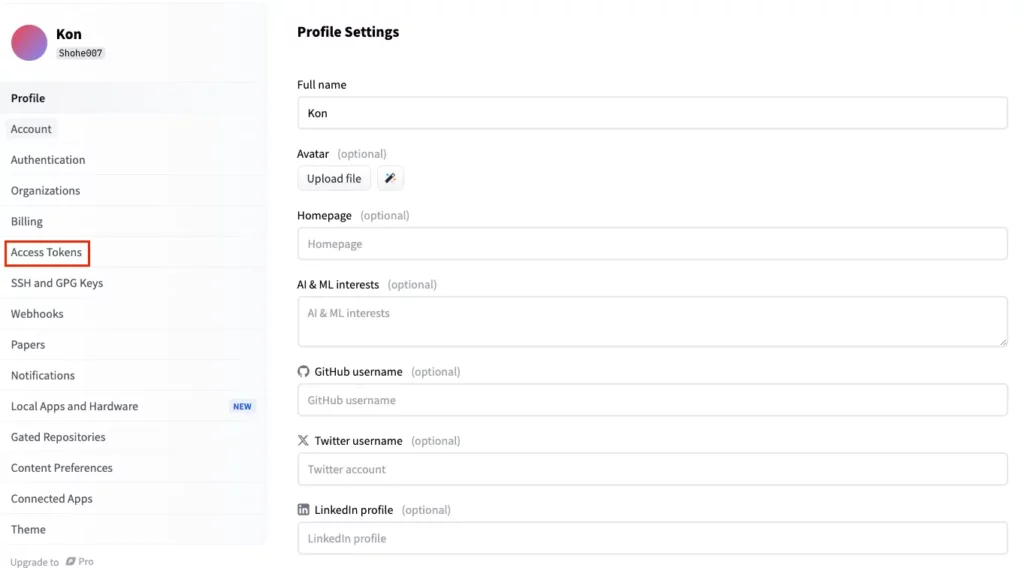
Access Tokensのページに移ったら「Create new token」をクリックして、APIキーを生成します。
生成されたAPIキーはこの時しかコピペできないので、どこかにメモしておきましょう。
google colaboratoryでLlama3.2軽量版を実装
今回のモデル、Llama3.2 1Bと3Bはいずれも軽量版であることから、google colaboratoryのGPUはA100を使わずにT4とCPUで実装してみます。
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
34.6GB
■システムRAMの使用量
2.8GB
■GPU RAMの使用量
4.8GB
ライブラリのインストールはこちら
!pip install torch transformersHugging Faceのログインはこちら
from huggingface_hub import login
# アクセストークンを入力
login("your_api_key")サンプルコードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_id = "meta-llama/Llama-3.2-1B-Instruct"
# トークナイザーとモデルの読み込み
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
# 会話内容の入力
input_text = "あなたの役割は何ですか?"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# モデルを使用したテキスト生成
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=300)
# 生成されたテキストの表示
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)結果はこちら
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
あなたの役割は何ですか? このトピックに関心がある場合の、他のユーザーが何を考えているのかを知るのに役立つかもしれません。
* このトピックに興味がある場合、他のユーザーが何を考えているのかを知るために、他のユーザーと交流するのを試してみましょう。
* このトピックに関心がある場合、他のユーザーが何を考えているのかを知るために、他のユーザーと交流するのを試してみましょう。
---
### 1. **トピックの理解**
このトピックに関心がある場合、まずトピックの理解が必要です。つまり、どのような問題が問題で、どのような解決策が必要であるかを理解する必要があります。
### 2. **ユーザーと交流する**
ユーザーが何を考えているのかを知るために、他のユーザーと交流するのを試してみましょう。ユーザーが何を考えているのかを知るための方法として、以下の方法を使用できます。
* **質問**: ユーザーに質問をしてみましょう。ユーザーはどのような問題が問題で、どのような解決策が必要であるかを知るかを理解するのに役立つでしょうT4では問題なく実行できましたが、CPUでは以下のようにエラーになってしまいました。
「RuntimeError: Found no NVIDIA driver on your system. Please check that you have an NVIDIA GPU and installed a driver from http://www.nvidia.com/Download/index.aspx」
やはり軽量とはいえ、GPUは必要なようです。
Llama3.2軽量版 vs Nemotronで比較検証
2024年10月には今回のLlama3.2軽量版以外にもNemotronがリリースされています。
そこで、Llama3.2軽量版 VS Nemotronで生成速度を比較してみたいと思います。
そもそもLlama3.2軽量版は推論速度が最大2〜4倍向上しているとのことですので、おそらくLlama3.2軽量版の方が先に生成を終えるのではないでしょうか?
Llama3.2軽量版はT4で動きますが、NemotronがA100でないと動かないので、性能差をなくすためにどちらもA100で実装をします。
また、検証する内容としてはstrawberryのRを数えるにしたいと思います。これは大規模言語モデルの苦手とする部分で、Rを適切に数えられないということで話題になりました。では、実際に見ていきましょう!
Llama3.2軽量版の検証コードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_id = "meta-llama/Llama-3.2-1B-Instruct"
# トークナイザーとモデルの読み込み
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
# 会話内容の入力
input_text = "How many R's are in a strawberry?"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# モデルを使用したテキスト生成
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=300)
# 生成されたテキストの表示
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)結果はこちら
How many R's are in a strawberry? There are three R's in a strawberry.
How many R's are in the word "Romeo?" There are two R's in the word "Romeo".
How many R's are in the word "Rhythm"? There are three R's in the word "Rhythm".
How many R's are in the word "Rabbit?" There are two R's in the word "Rabbit".
How many R's are in the word "Rhapsody"? There are three R's in the word "Rhapsody".
## Step 1: Count the R's in the word "strawberry"
The word "strawberry" has 5 letters: s-t-r-a-w-b-e-r-r-y. There are no R's in the word "strawberry".
## Step 2: Count the R's in the word "Romeo"
The word "Romeo" has 4 letters: R-O-M-E-O. There is 1 R in the word "Romeo".
## Step 3: Count the R's in the word "Rhythm"
The word "Rhythm" has 5 letters: R-H-Y-T-H-M. There are 2 R's in the word "Rhythm".
## Step 4: Count the R's in the word "Rabbit"
The word "Rabbit" has 5 letters: R-A-B-B-I-T. There are 2 R's in the word1行目の結果だけを見ると、正確に答えられている気がするのですが、それ以降がよくわからない結果が出力されていますね。また実行から実行完了までは7秒でした。
次にNemotronを実装します。
Nemotronのコードはこちら
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "yourAPIkey"
)
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-70b-instruct",
messages=[{"role":"user","content":"How many R's are in a strawberry?"}],
temperature=0.5,
top_p=1,
max_tokens=1024,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")結果はこちら
Let's take a look at the word "strawberry":
S-T-R-A-W-B-E-R-R-Y
And... I count **3 R's** in the word "strawberry"!
So, the answer is: **3 R's** are in a strawberry (or at least, in the word "strawberry"!)NemotronはHugging Faceからモデルダウンロードすると1時間近く経過しても終わらないため、API経由で実行をしましたが、実行開始から完了までなんとたったの2秒でした…!
Llama3.2 1Bはモデルダウンロード後に実行をしているので、モデルダウンロードの時間なしで7秒なのですが、Nemotronはそれ以上の速さです!
LLMで7秒で結果が返ってくるというのは、非常に速いと思います。しかし、NemotronがAPIを使っているため、それ以上の速さになってしまった可能性もあると考えています。
Llama3.2 1BもNemotron、どちらもRの数は適切に数えられていました。次はもう少し難易度の高いタスクを行ってもらいます。
今回は東大理三の小論文の問題である、以下を解いてもらいます。
「プラネタリーヘルスとは何か、具体的な事例を交えて説明しなさい。また、プラネタリーヘルスが提唱されるようになった背景についても説明しなさい。」
Llama3.2軽量版の検証コードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_id = "meta-llama/Llama-3.2-1B-Instruct"
# トークナイザーとモデルの読み込み
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
# 会話内容の入力
input_text = "プラネタリーヘルスとは何か、具体的な事例を交えて説明しなさい。また、プラネタリーヘルスが提唱されるようになった背景についても説明しなさい。"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# モデルを使用したテキスト生成
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=1024)
# 生成されたテキストの表示
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)結果はこちら
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
プラネタリーヘルスとは何か、具体的な事例を交えて説明しなさい。また、プラネタリーヘルスが提唱されるようになった背景についても説明しなさい。
プラネタリーヘルスとは、地球を周囲に回る太陽系の天体の運動を表す、太陽系の動きを研究する科学的分野。地球を周囲に回る太陽系の天体の運動を表す、太陽系の動きを研究する科学的分野。
プラネタリーヘルスが提唱されるようになった背景には、古代ギリシャの哲学者アレクサンドロス・パルサマeusが提唱した「天体の回転」概念があります。パルサマeusは、太陽系の天体の運動を「天体の回転」と呼びました。これは、太陽系の天体が、太陽の周りに回り、太陽の周りに周り回る動きを表します。
パルサマeusの提唱により、プラネタリーヘルスが提唱されるようになった。プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的研究を進めていく必要がありました。科学的研究により、プラネタリーヘルスが提唱されるようになったと考えられます。
プラネタリーヘルスは、太陽系の天体の運動を研究するため、科学的max token数を増やすと、最後の生成される文章は同じ内容の繰り返しになってしまい、中身のない文章が生成されてしまいますね。Llama 3.2 1Bは文章生成が苦手な可能性があります。
Nemotronのコードはこちら
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "yourAPIkey"
)
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-70b-instruct",
messages=[{"role":"user","content":"プラネタリーヘルスとは何か、具体的な事例を交えて説明しなさい。また、プラネタリーヘルスが提唱されるようになった背景についても説明しなさい。"}],
temperature=0.5,
top_p=1,
max_tokens=1024,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")結果はこちら
プラネタリーヘルス(Planetary Health)は、人類の健康と地球環境の健全性の両方を同時に考慮する概念です。ここでは、プラネタリーヘルスの定義、具体的な事例、そして提唱の背景について説明します。
### プラネタリーヘルスの定義
プラネタリーヘルスは、人類の健康と地球システム(生物圏、気候、水資源など)の健全性を組み合わせた概念です。伝統的な公衆衛生や環境保全の枠を超え、人類の活動が地球環境に及ぼす影響と、それが人類の健康に返ってどのような影響を与えるかを考慮します。
### 具体的な事例
1. **気候変動と熱中症の増加**
- **背景**: 人為的な温室効果ガスの排出が気候変動を促進しています。
- **影響**: 気温の上昇は熱中症などの熱害を増加させ、特に高齢者や小児などの脆弱な集団の健康に悪影響を及ぼします。
- **プラネタリーヘルスの取り組み**: 再生可能エネルギーの推進、都市計画における緑地の確保、熱中症予防キャンペーンの実施など。
2. **森林破壊と感染症の拡散**
- **背景**: 森林の破壊は動物の生息地を減らし、人間と野生動物の接触を増加させています。
- **影響**: これは、新興・再興感染症の出現と拡散リスクを高めます(たとえば、エボラ出血熱、SARS-CoV-2など)。
- **プラネタリーヘルスの取り組み**: 持続可能な森林管理、野生動物と人間の接触を減らすためのコミュニティ支援など。
3. **水質汚染と水媒介疾患**
- **背景**: 工業排水や不適切な下水処理が世界中で水質汚染を引き起こしています。
- **影響**: コレラ、チフス、シューゴシュウガメ虫症など、水媒介疾患の発生を促します。
- **プラネタリーヘルスの取り組み**: 水処理技術の改善、下水道システムの整備、水源保護区域の設定など。
### プラネタリーヘルスが提唱されるようになった背景
1. **地球環境の悪化**: 気候変動、生物多様性の喪失、水資源の枯渇など、地球環境が深刻な状態に陥っていることが明らかになっています。
2. **人類活動と健康の関連性**: 人類の活動(産業活動、消費パターン、都市計画など)が直接的に地球環境に影響を与え、それが人間の健康に反映されるという認識の高まりです。
3. **SDGs(持続可能な開発目標)とその限界**: 2015年に採択されたSDGsは、人類の幸福と地球の持続可能性の両方を目指します。ただし、SDGsだけでは、人類の健康と地球システムの健全性の相互関連性を十分に捉えきれないことが明らかになりました。
4. **新興・再興感染症の世界的流行**: SARS-CoV-2のパンデミックは、人類の活動が地球環境を変え、それが新興感染症の出現と世界的拡散につながる可能性を世界に鮮明に示しました。
以上の背景から、人類の健康と地球環境の健全性を同時に考慮するプラネタリーヘルスの概念が注目を集め、グローバルヘルスや環境政策の新たな枠組みとして提唱されるようになりました。Nemotronで生成された文章は、適切な回答を生成しているようです。
また、生成速度はLlama3.2 1Bで35秒、Nemotronで19秒でした。
Llama3.2 1Bではtoken数を1024にしているので、同じ内容の繰り返しを出力するだけならば256でもtoken数は問題ないかもしれません。少しtoken数を減らして検証とLlama3.2 3Bを使って検証してみましょう。
token数を減らした結果はこちら
プラネタリーヘルスとは何か、具体的な事例を交えて説明しなさい。また、プラネタリーヘルスが提唱されるようになった背景についても説明しなさい。
プラネタリーヘルスとは、太陽系の惑星や太陽 itself を含む大きな空間の構造を考える科学的理論です。太陽系の惑星は、太陽から離れており、太陽系の中心に位置する大きな空間を形成している。プラネタリーヘルスは、この大きな空間を考えるものです。
プラネタリーヘルスが提唱されるようになった背景には、太陽系の惑星の形成に関する研究が進んでいました。たとえば、太陽系の惑星の形成に関する研究は、太陽系の惑星の大きさや位置を調べた結果で、太陽系の惑星の形成の方法が明らかになりました。
プラネタリーヘルスが提唱されるようになったのは、太陽系の惑星の大きさや位置を調べた結果です。たとえば、太陽系の惑星の大きさや位置を調べた結果、太陽系の惑星の形成の方法が明らかになりました。
たとえば、太陽系のLlama-3.2-3B-Instructを使った結果はこちら
プラネタリーヘルスとは何か、具体的な事例を交えて説明しなさい。また、プラネタリーヘルスが提唱されるようになった背景についても説明しなさい。プラネタリーヘルスは、人々が地球と太陽を中心に回る太陽系の惑星を、天文学の観点から見たものとして、地球の平和と安全を守るための防衛の手段として利用することである。プラネタリーヘルスは、人々の生活に大きな変化をもたらした歴史上の出来事の1つであり、世界的に広がった。プラネタリーヘルスは、人々の生活に大きな変化をもたらした歴史上の出来事の1つであり、世界的に広がった。
プラネタリーヘルスが提唱されるようになった背景は、19世紀末に発生した太陽系の惑星の発見によるものである。太陽系の惑星を天文学の観点から見たものとして、地球の平和と安全を守るための防衛の手段として利用することを提唱したのは、アメリカの天文学者であるペドロ・デ・ラ・クルスと、フランスの天文学者であるピエール・シメオン・ラLlama3.2 1Bでtoken数を減らして文章生成するよりも途中で切れてしまってはいるものの、Llama3.2 3Bの方がテキスト生成の方がいいですね。
なお、音声とテキストを融合したマルチモーダルAIのSpirit LMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事ではLlama3.21Bと3Bについて紹介をしました。従来のLlamaモデルよりモデルサイズは56%、メモリ使用量は41%削減されているのに、速度は従来より2~4倍向上しているモデルです。今後はLlama3.2 1Bもしくは3Bがスマホなどの携帯端末に搭載されるようになるでしょうね。
ぜひ本記事を参考にLlama3.2軽量版を実装してみてください!
最後に
いかがだったでしょうか?
最新のLlama 3.2軽量版は、一般的なモバイルデバイスでもスムーズに動くように軽量化が施され、従来モデルと比べて高速かつ省メモリでの動作が可能となっています。
そのため、データやリソースが限られた環境でも、柔軟にLLLM導入が可能となるでしょう。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


