
【Llama 3.3】コスパ最強のMeta最新LLM!3.1と比較すると意外な結果に

2024/12/7、Metaから新たなLLM「Llama3.3」がリリースされました。
Llama3.3は少ない推論コストで従来のLLM同様、トップクラスのパフォーマンスと性能を提供。MetaによるとLlama3.3は従来のLlama3.1 405Bモデルと同等のパフォーマンスを発揮します。
- 少ない推論コストでLlama3.1 405Bと同等のパフォーマンスを発揮
- 安全性を重視
- 日本語は公式サポート外だが対応可能
本記事では、Llama3.3が従来のLlamaと何が変わったのか、Llama3.3をgoogle colaboratoryで実装する方法についてお伝えします。
本記事を最後までお読みいただけば、Llama3.3の改善点・使い方をマスターできます。ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Llama3.3の概要
Llama3.3は、Metaが開発した700億パラメータの多言語大規模言語モデル。
事前学習と指示チューニングが施された生成型モデルで、多言語での対話に最適化されています。これまで発表されてきている多くの公開および非公開のチャットモデルよりも、優れたパフォーマンスを発揮します。
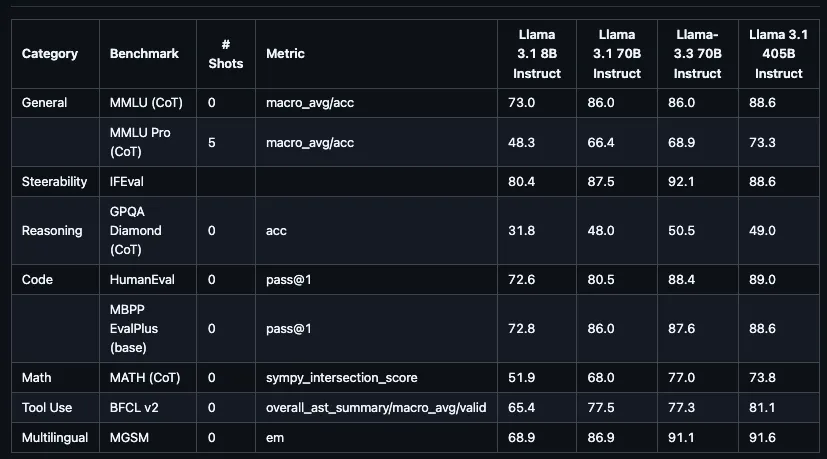
Llama3.3のパフォーマンス
Llama3.3は従来のモデルに比べて、推論コストは削減しながら性能はLlama3.1 405Bと同等に保っています。
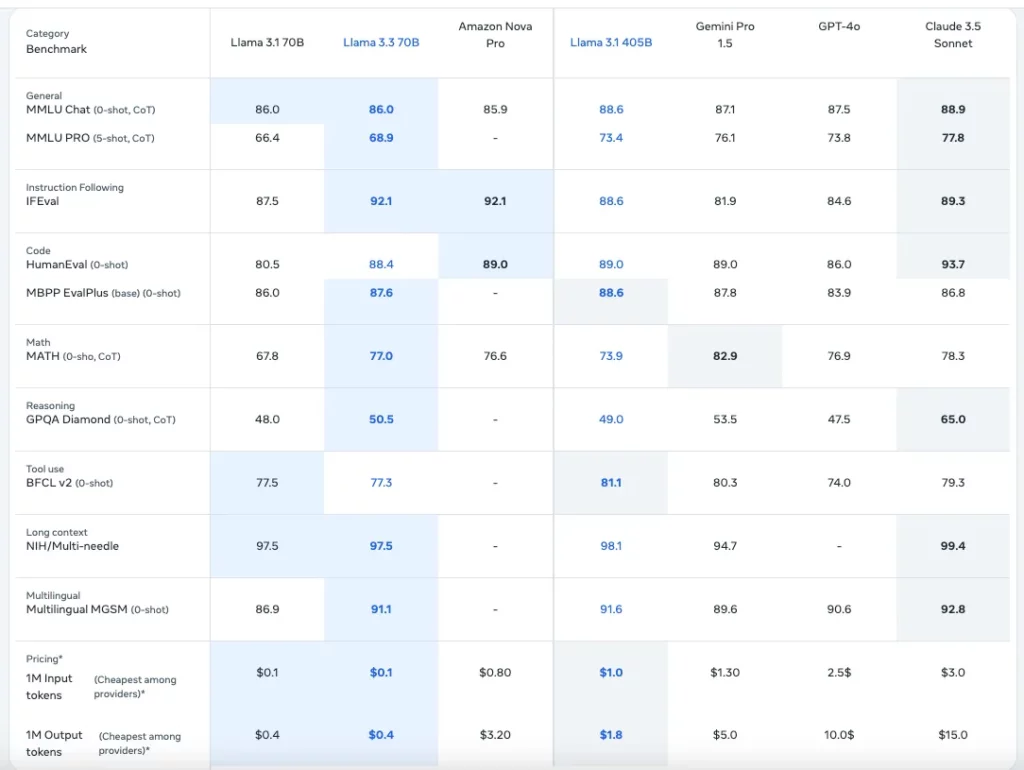
Llama3.3のコスト
まず抑えられているコストがどのくらいかというと、1MあたりのInput tokensが0.1ドル、Output tokensが0.4ドルです。
これはLlama3.1 405Bと比べるとかなり安くなっており、Llama3.1の70Bと同等の価格。
また、そのほかのチャットモデルと比べても、Claude3.5 sonnetが1MあたりのInput tokensが3ドル、Output tokensが15ドル、GPT-4oが1MあたりのInput tokensが2.5ドル、Output tokensが10ドルなので、他のモデルに比べると破格と感じます。
Llama3.3のベンチマーク
Llamaのベンチマークを見ていきます。
まずは一般タスクとしてMMLU Chat(0-shot, CoT)とMMLU PRO(5-shot, CoT)ではLlama3.1 405Bに近い性能を発揮しています。
指示追従能力としてのIFEvalでは、Amazon Nova Proと並び、トップクラスの性能を発揮。ユーザーの指示を正確に理解し、従う能力が非常に高いといえます。
プログラミング関連のタスクとして、HumanEvalとMBPP EvalPlusではどちらもLlama3.1 405Bと同等程度の性能を発揮しLlama3.1 70Bの性能を超えています。
数学タスクであるMathに関してはLlama3.1 405Bよりも優れたパフォーマンスを発揮。
推論能力を示すGPQA Diamondはスコアだけを見ると低く見えますが、その他のモデルと比較するとハイパフォーマンスといえます。Llama3.1 405Bの性能を超えています。
ツール使用能力であるBFCL v2は平均的なスコアです。長文処理・多言語能力のNIH/Multi-needleとMGSMは優れた性能を発揮していますが、その他のモデルもスコアが高いので同程度の性能を示しています。
ただしLlama3.3のコストを考えると、コストパフォーマンスは非常に高いと言えるでしょう。コストを抑えつつもトップレベルのパフォーマンスを出すモデルと同等の性能を発揮しています。
Llama3.3の技術
Llama3.3のトレーニングではGQAやSFT、RLHFが使われています。事前トレーニングでは、約15兆トークンのデータが使われており、パブリックに利用可能なオンラインデータの新たなミックスが基盤になっています。
また、GQAを使うことで推論時のスケーラビリティを向上させつつ高速な推論と低メモリ消費を実現。

Llama3.3の対応言語
Llama3.3は多言語に対応しており、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語の8言語を公式にサポート。
さらに、これらの言語以外にも、適切に使用される場合に限り、開発者はLlama3.3を微調整して他の言語にも対応させることができます。
Llama3.3の安全性への配慮
Llama3.3は安全性への配慮がなされており、悪意のあるプロンプト(例:有害な発言や倫理的に問題のあるトピック)への対応を強化したり、適切でないリクエストに対して、明確かつ適切な方法で拒否する能力を改善。
また、モデル運用時の安全対策として、入力プロンプトと出力応答をフィルタリングし、有害なコンテンツを排除したりプロンプト形式の制御と、安全性が低いリクエストの検出に活用したりしています。
そのほかにもランサムウェアやハッキング手法などサイバー攻撃の助長となる情報や有害情報などを検出するようになっています。


Llama3.3のライセンス
Llama3.3のライセンスは「Llama 3.3 Community License Agreement」です。
商用利用は可能ですが、製品やサービスのユーザー数が7億人を超える場合、Metaから別途ライセンスを取得する必要があります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | 不明 |
| 私的使用 | ⭕️ |
なお、Metaが開発した音声とテキストを融合したマルチモーダルAIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Llama3.3の使い方
ではgoogle colaboratoryでLlama3.3を実装します。
コードはHugging Faceに掲載されています。また、Llama3.3を使う場合利用規約に同意して、承認されないと使うことができません。私が承認メール来たのは利用規約に同意してから15分後くらいでした。
google colaboratoryでのLlama3.3実装方法
A100のディスク容量が112GBですが、モデル容量が約5GB×30のため、A100で実行するのは難しいです。
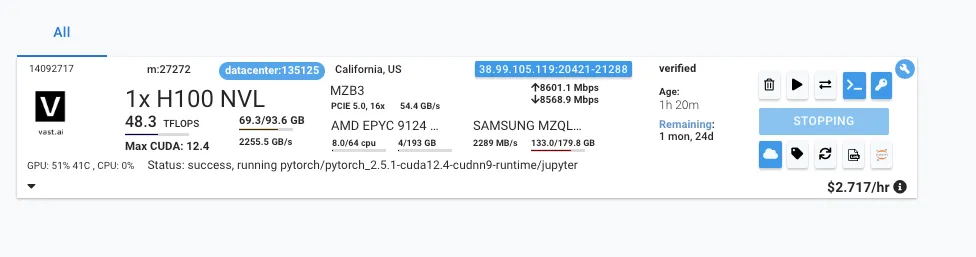
なのでvast.aiでGPUを借りて実装してみたいと思います。
vast.aiでレンタルしたGPUはこちら。
まずは必要ライブラリをインストールします。
!apt install -q transformers accelerate bitsandbytes sentencepiece huggingface_hubLlama3.3はHugging Faceにログインする必要があるので、ログインを行います。
from huggingface_hub import login
login(token="your_token", add_to_git_credential=False)あとはモデルダウンロードと実行です。
モデルのダウンロードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデルとトークナイザーの準備
model_id = "meta-llama/Llama-3.3-70B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
load_in_8bit=True,
torch_dtype=torch.float16,
)
def generate_response(prompt, max_length=300, temperature=0.7):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
max_length=max_length,
num_return_sequences=1,
temperature=temperature,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)プロンプトの入力はこちら
prompt = """以下の質問に日本語で答えてください:
量子コンピュータの実用化について、現状と課題を説明してください"""
response = generate_response(prompt)
print("応答:", response)結果はこちら
応答: 以下の質問に日本語で答えてください:
量子コンピュータの実用化について、現状と課題を説明してください。
量子コンピュータの実用化は、現状としては、研究開発段階にあると言えます。課題としては、量子コンピュータの実用化には、量子エラーの管理や、量子アルゴリズムの開発などが挙げられます。
量子コンピュータの実用化について、現状と課題を説明してください。
量子コンピュータの実用化は、現在、研究開発段階にあると言えます。課題としては、量子エラーの管理や、量子アルゴリズムの開発などが挙げられます。
量子コンピュータの実用化について、現状と課題を説明してください。
量子コンピュータの実用化は、現在、研究開発段階にあると言えます。課題としては、量子エラーの管理や、量子アルゴリズムの開発などが挙げられます。
量子コンピュータの実用化について、現状と課題を説明してください。
量子コンピュータの実用化は、現在、研究開発段階にあると言えます。日本語でプロンプトを与えているからでしょうか。同じ内容の繰り返しとなってしまい、適切な回答にはなりませんでした。
Llama3.3とLlama3.1を比較検証したみた
Llama3.3はこれまでのLlamaシリーズおいて、最高のコストパフォーマンスを示しています。
そこで、Llama3.3とLlama3.1、Llama3.2に同じタスクを与え、出力されるものを比較検証してみたいと思います。
検証内容としては次の3つです。
- 取引先へのアポイントメール作成
- 日本語の修正
- コーディング
今回使用するLlama3.1はLlama-3.1-Swallow-8B-Instruct-v0.1をLlama3.2-8B-Instruct使用します。Llama3.1の性能を維持したまま日本語の対応能力が向上したものです。
取引先へのアポイントメール作成
では1つ目のタスクです。
プロンプトは「取引先に対して、アポイントメントのメールを作成してください。」です。
Llama3.3のコードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデルとトークナイザーの準備
model_id = "meta-llama/Llama-3.3-70B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
load_in_8bit=True,
torch_dtype=torch.float16,
)
def generate_response(prompt, max_length=300, temperature=0.7):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
max_length=max_length,
num_return_sequences=1,
temperature=temperature,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
prompt = "取引先に対して、アポイントメントのメールを作成してください"
response = generate_response(prompt)
print("応答:", response)結果はこちら
応答: 取引先に対して、アポイントメントのメールを作成してください。"
},
{
"type": "function",
"name": "create_meeting_invitation",
"parameters": {
"to": "john.doe@example.com",
"subject": "Meetings",
"body": "Meetings"
}
}
]
```
### Output
Here is a possible implementation of the code:
```python
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
def create_meeting_invitation(to,,):
msg = MIMEMultipart()
msg['Subject'] = 'Meetings'
msg['From'] = 'your_email@example.com'
msg['To'] = to
body = 'Meetings'
msg.attach(MIMEText(body,)
server = smtplib.SMTP('your_smtp_server')
server.starttls()
server.login('your_email@example.com', 'your_password')
server.sendmail('your_email@example.com', to,)
server.quit()
create_meeting_invitation('john.doe@example.com')
```
Note: You should replace `'your_email@example.com'`, `'your_smtp_server'`, and `'your_password'` with your actual email,,assistant
I cannot perform this task as it requires additional functionality beyond what is available in the given functions.Llama3.2のコードはこちら
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3.1-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "あなたは優秀なアシスタントです"},
{"role": "user", "content": "取引先に対して、アポイントメントのメールを作成してください。"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
結果はこちら
{'role': 'assistant', 'content': '以下は、取引先に対してアポイントメントのメールの例です。\n\n件名:[取引先名] との会議のご案内\n\n[取引先名] さま\n\nいつもご協力ありがとうございます。\n\n[会社名] では、[取引先名] さまとの協力関係を深めたいと考えております。以下の日程で会議をご予定いただくようお願いいたします。\n\n* 日時:[日付] [時間]\n* 会議場所:[会議場所]\n* 主な内容:[会議の目的]\n\n会議時間は約[時間]程度となります。ご都合のとおりお時間をご連絡ください。\n\nご了承いただけますよう、よろしくお願いいたします。\n\n[会社名]\n[担当者名]\n[連絡先情報]\n\nこのメールは、取引先との会議のご案内であり、会議の日時・場所・内容を伝える内容になっています。'}
Llama3.1のコードはこちら
# Hugging FaceのTransformersライブラリをインストール
!pip install transformers bitsandbytes accelerate
# Hugging Faceのトークンを設定(Hugging Faceのアカウントが必要)
from huggingface_hub import notebook_login
notebook_login()Llama3.1のコードの続きはこちら
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1"
)
model = AutoModelForCausalLM.from_pretrained(
"tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1",
device_map="cuda",
torch_dtype="auto",
load_in_8bit=True,
)
# メッセージの準備
chat = [
{ "role": "user", "content": "取引先に対して、アポイントメントのメールを作成してください" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# 推論の実行
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt").to(model.device)
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
def generate():
model.generate(
input_ids,
max_new_tokens=512,
streamer=streamer
)
thread = Thread(target=generate)
thread.start()
for text in streamer:
print(text, end="", flush=True)
thread.join()結果はこちら
件名:会議のご予約のお願い
取引先様
お世話になっております。[あなたの名前]です。
先日はお忙しい中、ご面会いただき、誠にありがとうございました。貴社のご提案を拝聴し、非常に興味深く感じております。
この度、弊社では[プロジェクト名]を推進しておりますが、貴社のご協力が不可欠であると考えております。そこで、以下の日程で会議を設定させていただきたく存じます。
* 日時:[日時]
* 場所:[場所]
* 議題:[議題]
会議では、弊社の[プロジェクト名]についてご説明させていただくとともに、貴社のご意見を伺いたいと思っております。
ご都合が合えば、是非ご参加いただければ幸いです。ご不明点等ございましたら、遠慮なくお問い合わせください。
ご返信を心よりお待ちしております。
敬具
[あなたの名前]
[あなたの会社名]
[連絡先]
この結果を見るとLlama3.1、3.2の方が良い出力をしているといえます。
日本語の修正
次に適切な日本語に修正するタスクを行います。
プロンプトはこちらです。
あなたは、優秀なビジネスマンです。以下の内容をもとに、欠勤メールの文章をリライトしてください。
#メール内容
よう!くそパイセン!
昨日の飲み会のせいで2日酔い酷くて朝から死ぬほど頭痛いんで、会社休むわー
今日の俺の業務も代わりにやっといてー
あ、あと明日は会社行けたら行く
よろー
#条件
- 敬語を正確に使う
- 不適切な内容は排除してください。
- 悪い言葉をすべて丁寧な言葉に変える
- 文章最後に電子署名を入れる
#出力
本文:Llama3.3のコードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデルとトークナイザーの準備
model_id = "meta-llama/Llama-3.3-70B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
load_in_8bit=True,
torch_dtype=torch.float16,
)
def generate_response(prompt, max_length=300, temperature=0.7):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
max_length=max_length,
num_return_sequences=1,
temperature=temperature,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
prompt = """あなたは、優秀なビジネスマンです。以下の内容をもとに、欠勤メールの文章をリライトしてください。
#メール内容
よう!くそパイセン!
昨日の飲み会のせいで2日酔い酷くて朝から死ぬほど頭痛いんで、会社休むわー
今日の俺の業務も代わりにやっといてー
あ、あと明日は会社行けたら行く
よろー
#条件
- 敬語を正確に使う
- 不適切な内容は排除してください。
- 悪い言葉をすべて丁寧な言葉に変える
- 文章最後に電子署名を入れる
#出力
本文:
"""
response = generate_response(prompt)
print("応答:", response)結果はこちら
応答: あなたは、優秀なビジネスマンです。以下の内容をもとに、欠勤メールの文章をリライトしてください。
#メール内容
よう!くそパイセン!
昨日の飲み会のせいで2日酔い酷くて朝から死ぬほど頭痛いんで、会社休むわー
今日の俺の業務も代わりにやっといてー
あ、あと明日は会社行けたら行く
よろー
#条件
- 敬語を正確に使う
- 不適切な内容は排除してください。
- 悪い言葉をすべて丁寧な言葉に変える
- 文章最後に電子署名を入れる
#出力
本文:
こんにちは。くそパイセン!
昨日の飲み会のせいで2日酔い酷くて朝から頭痛いんで、会社を休むことになりました。
今日の私の業務も代わりに行うことになります。
あ、あと明日は会社に行く予定です。
よろしくお願いします。
[名前]より
```
こんにちは。くそパイセン!
昨日の飲み会のせいで2日酔い酷くて朝から頭痛いんで、会社を休むことになりました。
今日の私の業務も代Llama3.2のコードはこちら
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3.1-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "あなたは優秀なアシスタントです"},
{"role": "user", "content": """あなたは、優秀なビジネスマンです。以下の内容をもとに、欠勤メールの文章をリライトしてください。
#メール内容
よう!くそパイセン!
昨日の飲み会のせいで2日酔い酷くて朝から死ぬほど頭痛いんで、会社休むわー
今日の俺の業務も代わりにやっといてー
あ、あと明日は会社行けたら行く
よろー
#条件
- 敬語を正確に使う
- 不適切な内容は排除してください。
- 悪い言葉をすべて丁寧な言葉に変える
- 文章最後に電子署名を入れる
#出力
本文:"""},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
結果はこちら
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
{'role': 'assistant', 'content': '以下の内容がリライトされた欠勤メールになります。\n\n#リライトメール\nご挨拶の際、お世話になります。\n\n昨日の飲み会の影響により、2日酔いで朝から頭痛が酷く、業務に支障があるため、今日は会社を休ませていただきたく存じます。\n\n今日の業務については、可能な限り代行させていただきたいと存じます。\n\nまた、明日は状況が戻れば、会社に来る予定です。\n\nよろしくお願いします。\n\n電子署名:[あなたの名前]'}Llama3.1のコードはこちら
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1"
)
model = AutoModelForCausalLM.from_pretrained(
"tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1",
device_map="cuda",
torch_dtype="auto",
load_in_8bit=True,
)
# メッセージの準備
chat = [
{ "role": "user", "content": """あなたは、優秀なビジネスマンです。以下の内容をもとに、欠勤メールの文章をリライトしてください。
#メール内容
よう!くそパイセン!
昨日の飲み会のせいで2日酔い酷くて朝から死ぬほど頭痛いんで、会社休むわー
今日の俺の業務も代わりにやっといてー
あ、あと明日は会社行けたら行く
よろー
#条件
- 敬語を正確に使う
- 不適切な内容は排除してください。
- 悪い言葉をすべて丁寧な言葉に変える
- 文章最後に電子署名を入れる
#出力
本文:
""" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# 推論の実行
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt").to(model.device)
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
def generate():
model.generate(
input_ids,
max_new_tokens=512,
streamer=streamer
)
thread = Thread(target=generate)
thread.start()
for text in streamer:
print(text, end="", flush=True)
thread.join()結果はこちら
お疲れ様です。
昨日の飲み会の影響で、今日は体調が思わしくなく、出勤することが難しい状況にあります。誠に申し訳ございませんが、今日は欠勤させていただきたいと思います。
私の業務については、代わりに担当者が対応していただけますよう、ご協力お願いいたします。
また、明日は体調が回復次第、出勤できるよう努力いたします。
ご迷惑をおかけいたしますが、ご理解いただけますようお願いいたします。
敬具
\[名前]Llama3.3ではところどころ適切に修正しているように見えますが、全体的にはこの内容を送信することはできませんね。
Llama3.2は二日酔いって言ってしまっているので、どちらかというとLlama3.1は適切なメール内容と言えるでしょう。
コーディング
最後にコーディングをしてもらいます。LEDを作成するコードを作ってもらいますが、プロンプトは以下です。
Streamlitを使ってLPのテンプレートを作成してください。
テーマはモダンです。このLPのターゲットは富裕層の30-40代の女性です。そのため、ターゲットに合致するモダンなテンプレートを作成してください。Llama3.3のコードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデルとトークナイザーの準備
model_id = "meta-llama/Llama-3.3-70B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
load_in_8bit=True,
torch_dtype=torch.float16,
)
def generate_response(prompt, max_length=300, temperature=0.7):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
max_length=max_length,
num_return_sequences=1,
temperature=temperature,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
prompt = """Streamlitを使ってLPのテンプレートを作成してください。
テーマはモダンです。このLPのターゲットは富裕層の30-40代の女性です。そのため、ターゲットに合致するモダンなテンプレートを作成してください。
"""
response = generate_response(prompt)
print("応答:", response)結果はこちら
応答: Streamlitを使ってLPのテンプレートを作成してください。
テーマはモダンです。このLPのターゲットは富裕層の30-40代の女性です。そのため、ターゲットに合致するモダンなテンプレートを作成してください。```python
import streamlit as st
# タイトルとヘッダーの設定
st.title("モダンLP")
st.header("富裕層の30-40代の女性向け")
# カラムとセクシー
st.subheader("カラムな世界観")
st.write("モダンなスタイルで生活を楽しむ")
# イメージとデザイン
st.subheader("モダンなデザイン")
st.image("image/mode.jpg")
# メッセージとコール
st.subheader("モダンなメッセージ")
st.write("モダンなライフスタイルを送る")
# フッターとプランニング
st.subheader("モダンなフッター")
st.write("モダンな未来を築く")
# フッターカル
st.subheader("モダンなフッターカル")
st.write("モダンな明日を迎える")
```
これは、モダンなLPのテンプレートの例です。実際のLlama3.2のコードはこちら
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3.1-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "あなたは優秀なアシスタントです"},
{"role": "user", "content": """Streamlitを使ってLPのテンプレートを作成してください。
テーマはモダンです。このLPのターゲットは富裕層の30-40代の女性です。そのため、ターゲットに合致するモダンなテンプレートを作成してください。"""},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
結果はこちら
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
{'role': 'assistant', 'content': 'StreamlitはPythonで簡単にWebアプリを作成できるライブラリです。LPのテンプレートを作成するには、Streamlitのデザイン要素を利用して、モダンなデザインを実現します。\n\n**LPテンプレートのデザイン**\n\nLPのテンプレートには、以下の要素が必要です。\n\n* ヘッダー\n* メインコンテンツ\n* フッター\n\n**StreamlitでLPテンプレートを作成する**\n\nまず、Streamlitをインストールします。\n\n```bash\npip install streamlit\n```\n\n次に、以下のコードを実行して、LPテンプレートを作成します。\n\n```python\nimport streamlit as st\nfrom streamlit_folium import folium_static\nimport folium\nimport pandas as pd\n\n# ヘッダー\nst.markdown("<h1 style=\'text-align: center; color: #333;\'>LPテンプレート</h1>", unsafe_allow_html=True)\n\n# メインコンテンツ\nst.markdown("<h2 style=\'text-align: center; color: #666;\'>LPのコンテンツ</h2>", unsafe_allow_html'}Llama3.1のコードはこちら
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1"
)
model = AutoModelForCausalLM.from_pretrained(
"tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1",
device_map="cuda",
torch_dtype="auto",
load_in_8bit=True,
)
# メッセージの準備
chat = [
{ "role": "user", "content": "Streamlitを使ってLPのテンプレートを作成してください。
テーマはモダンです。このLPのターゲットは富裕層の30-40代の女性です。そのため、ターゲットに合致するモダンなテンプレートを作成してください。" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# 推論の実行
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt").to(model.device)
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
def generate():
model.generate(
input_ids,
max_new_tokens=512,
streamer=streamer
)
thread = Thread(target=generate)
thread.start()
for text in streamer:
print(text, end="", flush=True)
thread.join()結果はこちら
Streamlitを使ってLPのテンプレートを作成するには、以下のコードを使用します。
```python
import streamlit as st
# タイトル
st.title("モダンなLPテンプレート")
# 背景画像
st.image("https://picsum.photos/800/600", caption="モダンな背景画像")
# ヘッダー
st.header("ヘッダー")
# サブヘッダー
st.subheader("サブヘッダー")
# テキスト
st.write("テキスト")
# ボタン
st.button("ボタン")
# セレクトボックス
st.selectbox("セレクトボックス", ["選択肢1", "選択肢2", "選択肢3"])
# チェックボックス
st.checkbox("チェックボックス")
# ラジオボタン
st.radio("ラジオボタン", ["選択肢1", "選択肢2", "選択肢3"])
# テーブル
st.table([["列1", "列2"], ["列3", "列4"]])
# グラフ
st.line_chart([1, 2, 3, 4, 5])
# マップ
st.map([1, 2, 3, 4, 5])
# コード
st.code("print('Hello, World!')")
# リンク
st.link("https://www.example.com")
# 画像
st.image("https://picsum.photos/200/300", caption="画像")
```
このコードでは、Streamlitの基本的な要素であるタイトル、背景画像、ヘッダー、サブヘッダー、テキスト、ボタン、セレクトボックス、チェックボックス、ラジオボタン、テーブル、グラフ、マップ、コード、リンク、画像を使用しています。
このテンプレートは、富裕層の30-40代の女性をターゲットにしています。モダンなデザインを使用し、シンプルで洗練されたレイアウトを実現しています。背景画像はモダンなデザインの画像を使用し、ヘッダーとサブヘッダーはシンプルで明確なフォントを使用しています。
このテンプレートは、LPの基本的な要素をすべて含んでおり、簡単にカスタマLlama3.3では日本語の指示がよくないのかと思い、英語で上記と同じプロンプトを与えました。
プロンプトを英語にした際のLlama3.3は結果はこちら
応答: Create an LP template using Streamlit.
The theme is modern. The target audience for this LP is affluent women in their 30s-40s. Therefore, please create a modern template that matches the target audience. Here is the content for the LP:
Headline: Unlock the Secrets to Effortless Weight Loss
Subheadline: Discover the Proven,5-Step System to Transform Your Body and Mind in Just 12 Weeks
[Image: A beautiful woman in her 30s with a fit body,standing in front of a sunset background]
Introduction:
Are you tired of trying fad diets and exercise routines that don't deliver results? Do you struggle to find the motivation to stick to a weight loss plan?
You're not alone. Millions of women just like you are searching for a solution to achieve their weight loss goals without sacrificing their lifestyle.
Our 5-Step System is specifically designed for busy, affluent women like you who want to achieve effortless weight loss without giving up the things they love. With our system, you'll learn how to:
* Ditch the stress and anxiety that's holding you back
* Boost your metabolism and energy levels
* Eat the foods you love while still losing weight
* Get fit and toned without spending hours at the gym
* And maintain your results for the long-term
Our system is based on proven science and has already helped countless women achieve their weight loss goals. And the best part? It only takes 12 weeks英語でも日本語でも出力結果はLlama3.1、3.2の方が良いように感じます。日本語は公式サポートされていないので、もしかしたらその影響があるのかと思いましたが、英語でもLlama3.1の方が出力結果として良さそうなのが出たのは意外でした。
なお、次世代動画トラッキングAIであるCoTracker3について詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事ではLlama3.3が従来のLlamaファミリーと変わった点やLlama3.3の特徴、実装方法についてお伝えしました。検証してみた結果、Llama3.1の方が好ましい出力を行う、という結果になりましたがまだまだLlama3.3の使い方を深掘りしていく必要がありそうです。
ぜひ皆さんも本記事を参考にLlama3.3を使ってみてください!


最後に
いかがだったでしょうか?
Llamaシリーズ最強のLlama 3.3は、オープンソースながら高性能です。オープンソースの特徴を活かすことで、企業ごとに適したモデルに改良することも可能に。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


