
【Matryoshka】Appleがついに画像生成AIを公開!Sable Diffusion3と性能比較してみた

Matryoshka Diffusion ModelsはAppleが発表した画像・動画生成技術。従来の画像生成技術とは異なる点も多いので、本記事で解説をします。
- 新しい技術を取り入れたことにより、より高品質で詳細な画像生成が可能
- 計算効率向上により生成時間が短縮
- 複数解像度をひとまとめで、低解像度から高解像度まで同時に学習・生成を行う
最後まで読むことで、このについての理解が深まり、google colaboratoryで実装できるようになります。
ぜひ最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
Matryoshka Diffusion Modelsの概要
Appleが発表したMatryoshka Diffusion Modelsは高解像度の画像や動画を生成するための新しいディープラーニングモデルです。
Matryoshka Diffusion Modelsの仕組み
このモデルは、拡散モデルという、ノイズの多いデータから画像を生成する技術に基づいています。また、ネストされたUNetアーキテクチャと呼ばれる新しいアーキテクチャを採用しており、複数の解像度を同時にノイズ除去することで画像を生成します。
UNetアーキテクチャによるアプローチにより、従来の拡散モデルよりも効率的に高解像度の画像を生成することが可能。

Matryoshka Diffusion Modelsの特徴
特徴は、複数の解像度における拡散プロセスを同時に実行する点や複数の解像度でのノイズ除去を同時に最適化する損失関数の採用、計算効率の向上などです。
他にもUNetアーキテクチャの使用やプログレッシブトレーニング、潜在拡散モデルの採用などもあります。
これらの特徴を踏まえて、従来手法との違いやそれぞれの特徴を紹介します。
Matryoshka Diffusion Modelsと従来手法の違い
従来の画像生成モデルでは、カスケード拡散モデルと潜在拡散モデルを使用しており、それぞれ別個のモデルに依存するか事前学習されたオードエンコーダの低解像度の潜在空間で拡散を実行することで、高解像度の画像生成を行っていました。
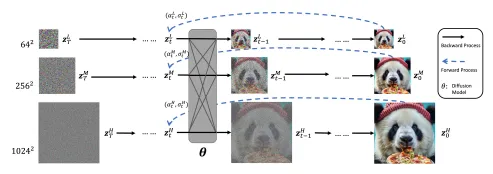
一方で、Matryoshka Diffusion Modelsは、データの持つ階層的な構造を活かしながら、一つの統合されたプロセスで高解像度のデータ生成を学習する仕組みです。
また、UNetアーキテクチャを使用しており、複数解像度の潜在表現間で重みと計算を共有することが可能。この技術により、高解像度生成の学習を容易にして、トレーニングと推論をより効率的に再割り当てできます。
従来のカスケード拡散モデルは、低解像度のデータを生成するために最初の拡散モデルを使用し、次に最初のステージの生成を条件として、超解像度バージョンを生成するために2番目の拡散モデルを使用します。そのためカスケードモデルは、各ステップで前のステップの出力に依存していました。
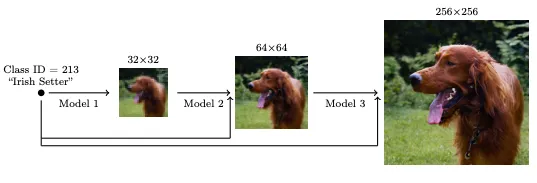
カスケード拡散モデルが低解像度画像から高解像度の画像を生成するために、段階的に解像度を上げていくのに対して、Matryoshka Diffusion ModelsのUNetアーキテクチャでは、複数の解像度で同時にノイズ除去を行うため高解像度画像生成が高速です。
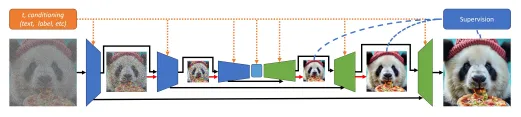
Matryoshka Diffusion Modelsで使われているプログレッシブトレーニング
プログレッシブトレーニングは、トレーニングを低解像度から徐々に高解像度へと進める方法。これにより、最初から高解像度のトレーニングに多くの計算リソースを使う必要がなくなり、効率よくモデルの精度を高めることができます。その結果、トレーニング全体のスピードが上がり、高解像度での性能も向上します。
さらに、異なる最終解像度のサンプルを1つのバッチ内で同時にトレーニングする混合解像度トレーニングを取り入れることも可能。
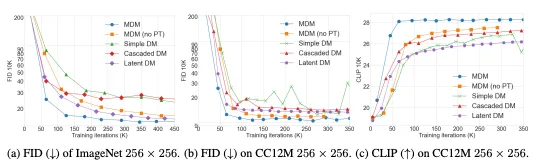
Matryoshka Diffusion Modelsでは、拡張空間における拡散モデル・UNetアーキテクチャ・プログレッシブトレーニング技術を活用することで、たった1200万枚の画像しか含まれていないCC12Mデータセットを使用し、最大1024×1024ピクセルの解像度で単一のピクセル空間モデルをトレーニングできます。
潜在拡散モデルを使った画像生成
潜在拡散モデルは、画像生成において高解像度かつ効率的な生成を可能にする技術で、Stable Diffusionにも用いられています。潜在拡散モデルは高次元データをより低次元の潜在空間に圧縮してから、拡散プロセスを適用します。
そのため、計算効率が向上し、高解像度の画像生成が短時間で行えます。
特にStable Diffusion XLでは、潜在拡散モデルを使ってノイズ除去を行なって画像生成をしています。計算の効率化やより少ない次元で複雑な画像構造を表現できるようになっているため、高解像度の画像生成が可能になっています。
ここまでのまとめ
Matryoshka Diffusion Models:UNetアーキテクチャを使用して複数解像度で処理するため、高解像度画像生成が高速
従来の手法:カスケード拡散モデル・潜在拡散モデルを使用するため、高解像度画像生成は低速
Matryoshka Diffusion Modelsのライセンス
Matryoshka Diffusion Modelsのライセンスは以下のようになっています。もしAppleの商標や名称を使用する場合には、許可が必要であり、ソフトウェアは現状のまま提供されていて保証はありません。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ❌ |
| 私的使用 | ⭕️ |
なお、Stable Diffusionの開発者がリリースしたFLUX.1について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Matryoshka Diffusion Modelsの使い方
google colaboratoryで実装してみます!google colaboratoryで実装する際には、ランタイムをGPUに変更する必要があります。
また、Matryoshka Diffusion ModelsのGitHubに掲載されている通りに実装しても動かない可能性が高く、google colaboratoryで動くように修正しているので、ぜひこちらを参考にgoogle colaboratoryでMatryoshka Diffusion Modelsを実装してみてください。
Matryoshka Diffusion Modelsを動かすのに必要な動作環境
Matryoshka Diffusion Modelsを実行した時の環境は以下です。結構GPUを使います。
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
52.7GB
■システムRAMの使用量
5.8GB
■GPU RAMの使用量
17.0GB
■GPUタイプ:A100
■プラン:有料
google colaboratoryでのMatryoshka Diffusion Modelsの実装方法
まずはGitHubリポジトリをクローンします。次に必要ライブラリのインストール、モデルのダウンロード、Pre-commit、Matryoshka Diffusion Modelsの実行という流れですが、実行でめちゃくちゃつまづきました・・・。
GitHubリポジトリのクローンはこちら
!git clone https://github.com/apple/ml-mdm.git
%cd ml-mdm必要ライブラリのインストールはこちら
!pip install .学習済みモデルのダウンロードはこちら
!curl https://docs-assets.developer.apple.com/ml-research/models/mdm/flickr64/vis_model.pth --output vis_model_64x64.pth
!curl https://docs-assets.developer.apple.com/ml-research/models/mdm/flickr256/vis_model.pth --output vis_model_256x256.pth
!curl https://docs-assets.developer.apple.com/ml-research/models/mdm/flickr1024/vis_model.pth --output vis_model_1024x1024.pthパスの追加はこちら
import sys
sys.path.append('/content/ml-mdm')アンインストールと再インストールのコードはこちら
!pip uninstall -y ml_mdm
!pip install -e .Pre-commitのインストールおよびconfigファイルの作成はこちら
!pip install pre-commit
pre_commit_config = """
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v3.2.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-added-large-files
"""
with open('.pre-commit-config.yaml', 'w') as f:
f.write(pre_commit_config)Pre-commitはこちら
!pre-commit install
!pre-commit run --all-filesMatryoshka Diffusion Modelsの実行はこちら
!torchrun --standalone --nproc_per_node=1 ml_mdm/clis/generate_sample.pyここからが重要です!
おそらく「!pre-commit run –all-files」でエラーが出るので、「configs/models/cc12m_64×64.yaml」を開き、4,5,7,8行目をコメントアウト。これで「!pre-commit run –all-files」のエラーは回避できます。
他に1024×1024、256×256のyamlファイルもありますが、これはひとまず削除しておいてOKです。というのも、1024×1024での生成はA100のGPUでもメモリオーバーになりますし、256×256での生成はコードの修正がかなり必要になります。
次に、local URLにアクセスできない問題解決方法です。
今回はGradioのlaunch()関数に修正を加えて、ポートフォワーディング機能を使っていきます。
「/content/ml-mdm/ml_mdm/clis/generate_sample.py」を開きます。
541行目あたりにある「demo.queue(default_concurrency_limit=1).launch(**launch_args)」を「demo.queue(default_concurrency_limit=1).launch(share=True, **launch_args)」に変更してください。
また、「if __name__ == “__main__”:」の最後の部分に以下のコードを追加します。
追加コードはこちら
from google.colab import output
output.serve_kernel_port_as_iframe(args.port)これでWeb DemoのURLにアクセスできるようになります。
画像一番下に書いてある「Running on public URL」にアクセスします。「Running on local URL」はgoogle colaboratoryからではアクセスできません。

ポートフォワーディング以外にもngrokを使って公開URLを作成してアクセスする方法などもありますが、ポートフォワーディング機能使うのが簡単で手っ取り早く実装できると思います。
pre-commitについて
pre-commitは、Gitのフック機能を利用して、コミットが実行される前に特定のスクリプトやツールを自動的に実行するためのツール。これにより、コードの品質を向上させるためのチェックやフォーマットをコミット前に行うことができます。
Matryoshka Diffusion Modelsの開発者は、pre-commit installでpre-commitもセットアップする必要がある。と述べています。
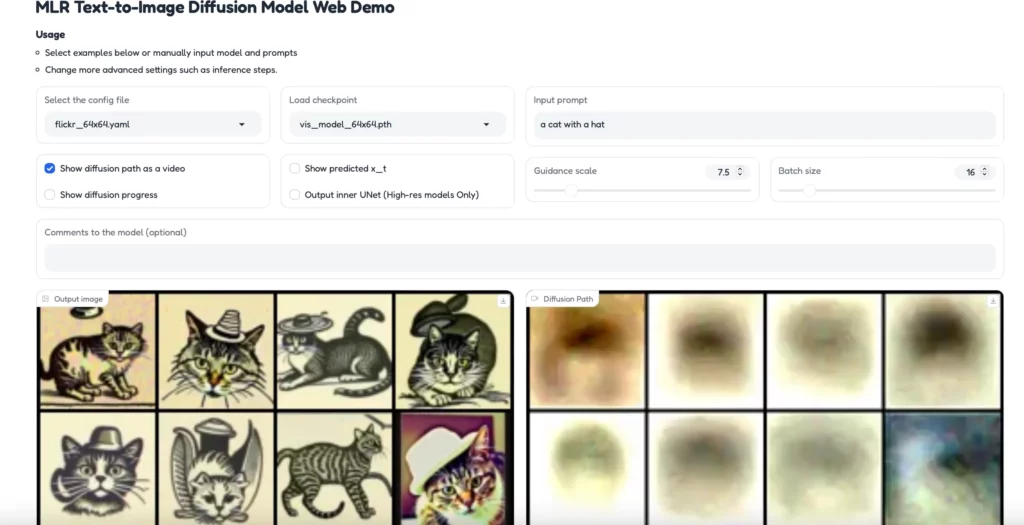
Matryoshka Diffusion Modelsで画像生成を試してみた
今回はMatryoshka Diffusion Modelsの64×64で画像を生成します。バッチサイズを変更すると生成する枚数が変わります。Matryoshka Diffusion Modelsの良いところは高画質な画像が生成できる点ですが、google colaboratoryではGPUが足りません。
Matryoshka Diffusion Modelsで生成する画像は無課金おじさんです。
プロンプトはこちら
「A realistic digital illustration of an athlete during a precision shooting event. The athlete has white hair, is wearing glasses and a white t-shirt with the word ‘TURKIYE’ on it, and is aiming a pistol straight ahead. The athlete’s left hand is in their pants pocket. The background shows a sports venue with a crowd of photographers and a blue banner that says ‘PARIS 2024.’ The overall mood is focused and intense, capturing the moment of concentration in a competitive sports setting.」
和訳:精密射撃競技中のアスリートのリアルなデジタルイラスト。選手は白髪で、眼鏡をかけ、「TURKIYE」と書かれた白いTシャツを着て、ピストルをまっすぐ前に向けている。選手の左手はズボンのポケットに入っている。背景には、大勢のカメラマンと『PARIS 2024』と書かれた青い横断幕が掲げられたスポーツ会場が映っている。全体的に集中した激しいムードで、競技スポーツの場での集中の瞬間をとらえている。
実際にMatryoshka Diffusion Modelsで生成された画像はこちらです。バッチサイズ16で生成しているので16枚の画像が1枚に収まっています。

Matryoshka Diffusion Modelsは高画質の画像を生成できるのが特徴ですが、1024×1024サイズで画像生成できず画質を検証することはできませんでした。
また、同じようにStable Diffusion 3でも生成をしたので、見比べてみます。画像サイズが小さいので画質についてはわかりにくいかもしれません。一枚目がMatryoshka Diffusion Modelsで生成、二枚目がStable Diffusion 3で生成した画像です。
しかし、Matryoshka Diffusion Modelsで生成した方は、プロンプトに忠実に従っており全身が写っていますね。


Stable Diffusion 3のコードはこちら
!pip install --upgrade diffusers accelerate
#次のセル
from huggingface_hub import login
login()#Hugging FaceのAccess Tokenを入力
#次のセル
# 必要なモジュールをインポート
import torch
from diffusers import StableDiffusion3Pipeline
# Stable Diffusion 3のパイプラインを読み込み
pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
# パイプラインをGPUに移動
pipe = pipe.to("cuda")
# 画像を生成
image = pipe(
"A realistic digital illustration of an athlete during a precision shooting event. The athlete has white hair, is wearing glasses and a white t-shirt with the word ‘TURKIYE’ on it, and is aiming a pistol straight ahead. The athlete’s left hand is in their pants pocket. The background shows a sports venue with a crowd of photographers and a blue banner that says ‘PARIS 2024.’ The overall mood is focused and intense, capturing the moment of concentration in a competitive sports setting.", # プロンプト
negative_prompt="", # ネガティブプロンプト(空欄でOK)
num_inference_steps=28, # 推論ステップ数
guidance_scale=7.0, # ガイダンススケール
height=64,
width=64,
).images[0]
# 生成された画像を表示
imageなお、Stable Diffusion 3について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Matryoshka Diffusion Modelsの応用例
Matryoshka Diffusion Modelsは従来の画像生成モデルに比べ、高画質の画像を短時間で生成することが可能です。このような特徴を活かすことで、次のような応用ができるでしょう。
- デジタルアート:Matryoshka Diffusion Modelsを使うことで高画質な画像生成が可能。生成した画像をアート作品にもできます。
- 広告やチラシ:これまでフリー素材を使っていた場合には、Matryoshka Diffusion Modelsを使って素材を生成することで、広告やチラシに応用可能。
- ゲーム開発・映像作品:Matryoshka Diffusion Modelsでは画像だけではなく、動画の生成も可能。高画質に作られた動画を組み合わせてゲームのワンシーンやショート動画制作に応用ができます。
まとめ
本記事ではMatryoshka Diffusion Modelsの概要から使い方を紹介しました。従来モデルとは異なるアプローチ方法を取ることで、より高画質により詳細により高速に画像を生成することができるようになりました。
ぜひ本記事を参考にMatryoshka Diffusion Modelsを使ってみてください!
最後に
いかがだったでしょうか?
Matryoshka Diffusion Modelsを活用すれば、効率的に高品質な画像や動画を生成できます。この技術を事業に取り入れる可能性について、相談してみませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。


