
【MiniCPM-V 2.6】未来予測ができるGPT-4V超えの生成AIで、メッシのスーパープレーをガチ分析してみた

\生成AIを活用して業務プロセスを自動化/
MiniCPM-V 2.6の概要
MiniCPM-V 2.6はOpenBMBがリリースした最新の多機能マルチモーダル大規模言語モデル(MLLM)です。
MiniCPM-V 2.6は単一画像や複数画像、動画の内容理解において、GPT-4Vを上回ります。また、OpenCompass上ではGPT-4oとGemini1.5を超え、iPad上でリアルタイムビデオ分析が可能です。
どれくらいすごいのかはベンチマークを参考に解説します!
MiniCPM-V 2.6の性能
MiniCPM-V 2.6はこれまでのLLMよりも遥かに上回る機能と発表されています。実際にベンチマークを確認してみると、MiniCPM-V 2.6のパフォーマンスの高さがよくわかります。

MiniCPM -V 2.6は8つの一般的なベンチマークを総合的に評価した最新のOpenCompassでは平均スコア65.2を達成。
MiniCPM -V 2.6のパラメーター数は8Bです。比較対象になっているLLMのパラメータ数は以下です。
- Gemini 1.5 Pro:560〜6000億(具体的な数値は公表されていないがデータなどからの推定値)
- GPT-4V-202409:約1.7兆(OpenAIは具体的な数値を公表していないため、これまでの発表データなどからの推定値)
- Cambrian-34B:34億
- InternVL2-8B:81億
MMMUやAI2Dなどの一部はその他のLLMが勝っていますが、MiniCPM-V2.6の機能を考えるとかなり少ないパラメータ数で従来のLLMの機能を凌いでいます。
- MMMU:Massive Multi-discipline Multimodal Understandingの略。大学レベルの教養や専門知識を評価するためのベンチマーク。芸術・デザイン・ビジネス・科学・健康と医学・人文科学と社会科学・技術と工学をカバー
- AI2D:約5000の小学校レベルの科学図と15万以上のリッチアノテーションを含むデータセットで、図の理解と視覚的な質問応答をカバー
複数画像の理解とコンテキスト内学習
MiniCPM -V 2.6は複数の画像に対してもチャットと推論が可能です。Mantis-Eval、BLINK、Mathverse mv、Sciverse mvなどの一般的なマルチ画像ベンチマークで最先端のパフォーマンスを達成し、有望なコンテキスト内学習機能も示しています。
例えばこちらの画像の内容をMiniCPM -V 2.6が推論すると次のようになります。

Round1:自転車のサドルを下げる手伝いをしてください。
Round1 MiniCPM-V2.6:1.サドルポストクランプを見つける: サドルの下側に、サドルポストを固定しているクランプが見えるはずです。
2.クランプを解除する: 通常、クイックリリースレバーまたはボルトがあります。レバーの場合は引いてサドルポストを解除します。ボルトの場合は少し緩めます。
3.サドルを下げる: サドルが希望の高さに達するまでゆっくりと下げます。下げすぎないように注意してください。ライディングのポジションと快適さに影響を与える可能性があります。
4.サドルを固定する: 希望の高さに達したら、クランプを再度締めます。レバーの場合は、レバーを元の位置に戻してサドルを固定します。ボルトの場合は、しっかりと締めます。
5.サドルの確認: サドルがしっかり固定されていることを確認するために、軽く押してみます。しっかり固定されていて揺れないことを確認してください。ライディングのスタイルに応じてサドルの高さを調整してください。
たった一枚の画像から非常に詳しくかつ注意点も踏まえて説明を行ってくれています。これだけ詳しい説明と注意点を答えてくれるなら、もしかしたら将来的には製品の取扱説明書もなくなってしまうかもしれませんね。
次に複数の画像からの推論です。
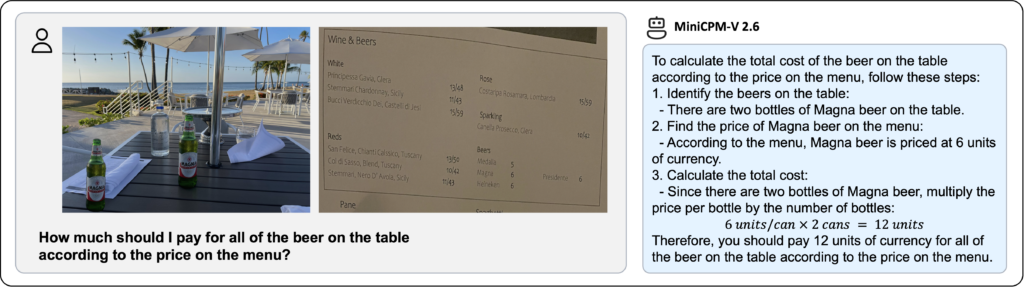
こちらはメニュー表からビールの値段を画像にして、テーブルの上に置かれているビールの合計金額について尋ねています。
MiniCPM-V2.6はMagna Beerは1本6ユニットでテーブルの上には2本のMagna Beerがあるから合計で12unitです。と回答しています。
単位がユニットになっていますが、メニュー表に単位が書いていないのでユニットになっているのでしょう。たったこれだけで合計金額を出してくれるのは、かなりハイレベルと言えるでしょう。
他にもコーディング内容の画像を提示することで、バグの原因と修正方法を推論してくれたりもします。
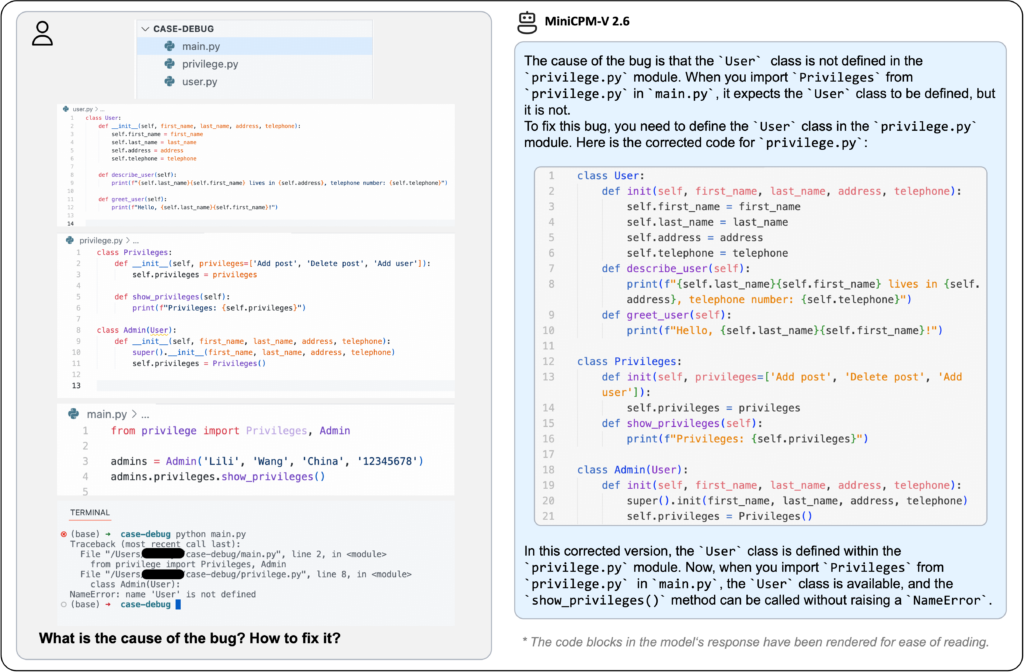
画像だけでコーディングのバグ原因と修正方法提案してくれるって、控えめに言ってすごいですね…!
MiniCPM-V2.6の強力なOCR機能と効率性
MiniCPM-V2.6は任意のアスペクト比で最大180万ピクセルの画像処理が可能。さらにOCRベンチでは最先端のパフォーマンスを発揮しており、GPT-4oやGPT-4V、Gemini 1.5 Proなどの性能よりも上回っています。
これは最新のRLAIF-VとVisCPM技術に基づいており、Object HalBenchでGPT-4oやGPT-4Vよりもハルシネーションが大幅に少ないためで、英語や中国語、ドイツ語、フランス語など多くの言語をサポート。
RLAIF-V:AIフィードバックを用いた強化学習の一種で、特に大規模多言語モデル(MLLMs)の信頼性を向上させるために開発された新しいフレームワーク
VisCPM:清華大学のNLP研究所やOpenBMB、Zhihuなどの共同研究によって開発された大規模なマルチモーダルモデル。主に中国語を対象としており、画像とテキストのデータを組み合わせて学習可能
また、MiniCPM-V2.6は従来に比べトークン密度が高く、1.8Mピクセルの画像を処理するときのトークン数はこれまでのモデルより75%も少なくて済みます。必要とされるトークン数が減ったことにより、推論速度やメモリ消費量、消費電力などが改善され、iPadなどのタブレットでリアルタイムビデオ推論を可能にしています。
MiniCPM-V2.6のライセンス
MiniCPM-V2.6のライセンスはApache2.0です。Apache2.0のため、商用利用や改変なども可能です。
もしMiniCPM-Vモデルの重みの使用をする場合には、MiniCPM Model License.mdに従う必要があります。MiniCPM Modelは学術研究目的は無料で利用でき、商用利用する場合にはアンケートに回答することで無料で利用できます。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、GPT-4oを上回るスコアを獲得しているMiniCPM-Llama3-V 2.5について詳しく知りたい方は、下記の記事を合わせてご確認ください。

MiniCPM -V2.6の使い方
では実際にMiniCPM-V2.6をgoogle colaboratoryで実装していきましょう。
MiniCPM-V2.6をgoogle colaboratoryで実装する場合には、ランタイムをGPUにする必要があるので、実行する前にGPUに変更しておきましょう。また、無料版のGPUだと実行時にGPU RAMをオーバーしてしまう可能性があります。
もし利用できなかった場合には、オンラインデモが用意されているので、そちらを利用してみてください。そのほかMiniCPM-Llama3-V 2.5なども用意されています。
MiniCPM -V2.6動かすのに必要な動作環境
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
53.3GB
■システムRAMの使用量
4.2GB
■GPU RAMの使用量
18.3GB
MiniCPM-V2.6をgoogle colaboratoryで実装
まずはHagging Faceに掲載されているサンプルコードを実行してみましょう。
必要ライブラリのインストールはこちら
!git clone https://github.com/OpenBMB/MiniCPM-V.git
%cd MiniCPM-V
!pip install -r requirements.txtエラーが発生した場合の解決はこちら
!pip install flash_attnMiniCPM-V2.6の実行はこちら
# test.py
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
image = Image.open('your_image').convert('RGB') # 画像は自前で用意
question = 'What is in the image?'
msgs = [{'role': 'user', 'content': [image, question]}]
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(res)
## if you want to use streaming, please make sure sampling=True and stream=True
## the model.chat will return a generator
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
stream=True
)
generated_text = ""
for new_text in res:
generated_text += new_text
print(new_text, flush=True, end='')上記のコードで画像の推論を行うことができます。
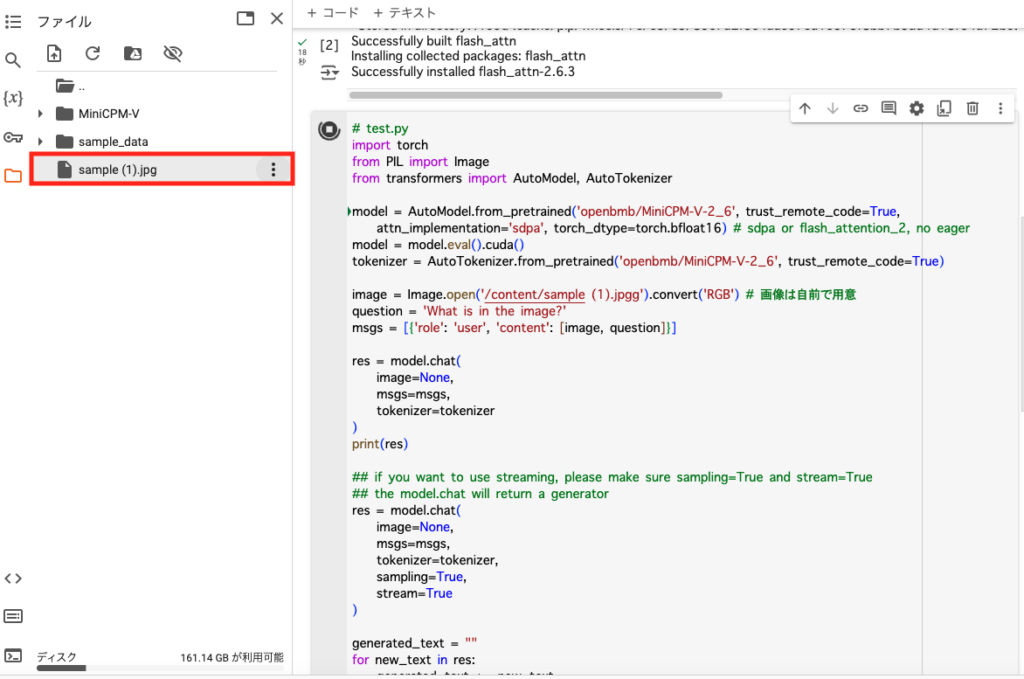
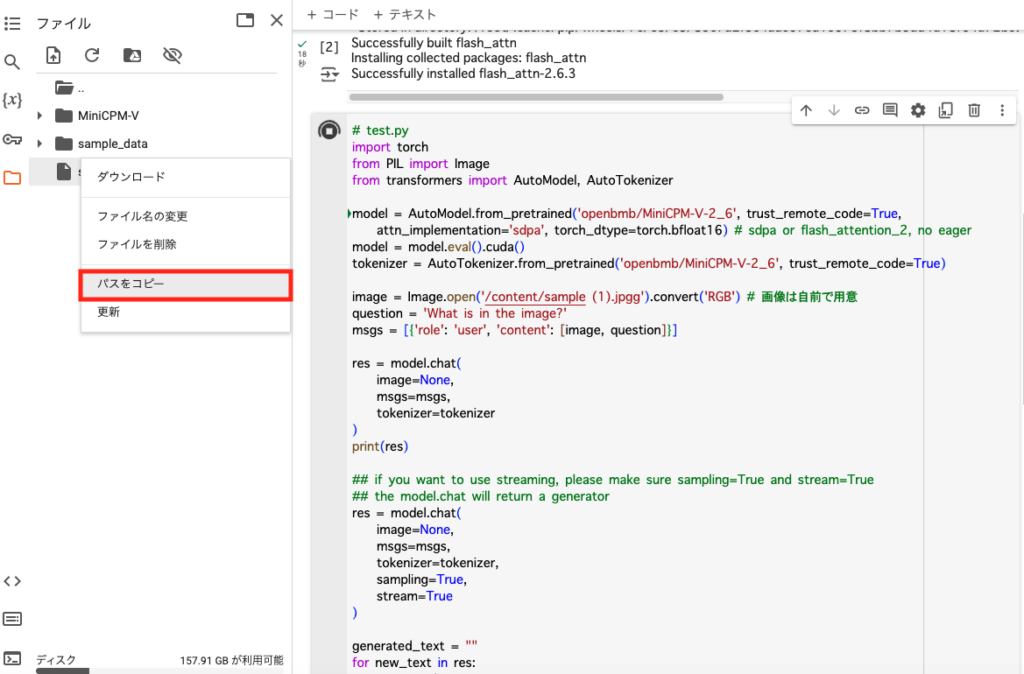
「your_image」の部分は自身が用意した画像のパスを入力すればOKです。
画像はgoogle colaboratoryにアップロードして、ファイル名にカーソルを合わせると3つの縦点が出てくるので、そちらをクリック。「パス名をコピー」をクリックすれば画像のパス名がコピーできます。
MiniCPM-V2.6の検証
MiniVPM-V2.6の検証では、画像1枚と動画2種類の検証をしたいと思います。画像はFLUX.1で生成した画像を使います。
画像を使って検証を行う際のコードは上記のサンプルコードをそのまま使います。変更するのは画像パス名のみです。
実際に画像の推論を行っている様子はこちらです。
推論の結果はこちら
The image depicts a person aiming a handgun. The individual is wearing headphones and has white hair. They are in an outdoor setting, possibly during a sports event or competition, as suggested by the background crowd and banners.
The image shows an individual aiming a pistol. The person is wearing headphones, sunglasses, and has a bag slung over their shoulder. In the background, there appears to be a sports stadium with spectators and banners displaying "PARISO" and Olympic rings.
和訳:画像には拳銃を狙う人物が描かれている。その人物はヘッドホンをしており、白い髪をしている。背景の群衆や横断幕が示唆するように、彼らは屋外におり、おそらくスポーツイベントか競技の最中であろう。
ピストルを構える人物。その人物はヘッドホンをし、サングラスをかけ、バッグを肩にかけている。背景には、観客と「PARISO」とオリンピック・リングを表示した横断幕があるスポーツ・スタジアムがあるように見える。次に以下2つの動画で推論を行っていきます。
動画を推論する場合には、コードが画像推論とは異なりますので、以下のサンプルコードをコピペしてパス名だけ変更してください。
詳しい内容についてはMiniCPM-V2.6のGitHubに掲載されているので、そちらもご覧ください
指示は「Anticipate what happens next.」です。動画がこの後どうなるのかについて回答するようにしています。
動画を推論するコードはこちら
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
MAX_NUM_FRAMES=64 # if cuda OOM set a smaller number
def encode_video(video_path):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1) # FPS
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
print('num frames:', len(frames))
return frames
video_path="your_video"
frames = encode_video(video_path)
question = "Anticipate what happens next."
msgs = [
{'role': 'user', 'content': frames + [question]},
]
# Set decode params for video
params = {}
params["use_image_id"] = False
params["max_slice_nums"] = 2 # use 1 if cuda OOM and video resolution > 448*448
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
**params
)
print(answer)to be continue動画の結果はこちら
The video is likely concluding with the "To Be Continued" graphic, indicating that there will be a sequel or continuation of this content. The blurred yellow object suggests it may have been a significant part of the scene before being intentionally out of focus to draw attention to the ending message.
和訳:動画は「To Be Continued」のグラフィックで締めくくられ、このコンテンツの続編や続きがあることを示しているのだろう。ぼやけた黄色の物体は、エンディングのメッセージに注意を引くために意図的にピントを外す前は、シーンの重要な部分であった可能性を示唆している。to be continue動画では、この後どうなるのかの推論というよりも、画面上に書かれている「To Be Continued」の説明になってしまいました。ただ、To Be Continuedだけでこれだけの推論を行えるとは驚きです。
次はサッカーのシーンを一部切り取った動画で推論を行っていきます。
指示は先ほどと同じ「Anticipate what happens next.」です。
サッカー動画の結果はこちら
Based on the current actions and positioning of the players, the next likely event is that the player in white with the ball will attempt to either pass it to a teammate or take a shot at the goal. The goalkeeper's posture indicates readiness for action, suggesting he may dive to intercept if a shot is taken. Other players are positioned to support their teammates' movements or to defend against an opposing team's counterattack.
和訳:現在のプレーヤーの行動とポジショニングから、次に起こりそうなのは、ボールを持った白のプレーヤーが味方にパスを出すか、ゴールを狙ってシュートを打つことである。ゴールキーパーの姿勢は準備態勢を示しており、シュートが決まれば飛び込んでインターセプトする可能性を示唆している。他の選手は、味方の動きをサポートしたり、相手チームの反撃から守備をしたりする。最初の動画とは異なり、かなりそれっぽい推論を返してくれています。もしかしたらminiCPM-V2.6で推論する動画としては、人物などが動いているものがいいのかもしれません。ここら辺は今後の検証課題ですね。
なお、FLUX.1について詳しく知りたい方は、下記の記事を合わせてご確認ください。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


