
Petalsの始め方!Llama2 70B/Falcon 180Bをローカルで動かせる分散LLM基盤を徹底解説

- 巨大LLM(70B〜180B級)を自宅GPUやColabで実行できる
- P2P型の分散推論により、個人環境でも超大規模モデルを高速に扱える
- 推論だけでなく軽量なファインチューニングまで可能
皆さん、PetalsというLLMプラットフォームをご存知ですか?
なんと、大規模言語モデルが、Google Colabやご自宅のGPUで動かせるようになるんです。
扱えるモデルは、Llama2(70B)やFalcon(180B)などのパラメータ数が特級クラスのものばかり。誰でも、Google Colabさえあればこれらのモデルを動かせます。
ということで、今回の記事ではPetalsというLLMプラットフォームの概要、導入、実際に使ってみた感想についてまとめています。
この記事を最後まで読むと、Petalsを理解できるようになります。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Petalsの概要
Petalsは、家庭用のGPUやGoogle Colabを使用して、大規模な言語モデルを実行するためのプラットフォームです。動かせるモデルは、Llama 2(70B)、Falcon(180B)、BLOOM(176B)など、化け物クラスのパラメータ数を誇るLLMばかりです。
そんなPetalsの特徴は以下の4点です。
| 項目 | 内容 |
|---|---|
| 分散型パイプライン | Petalsは、高速なニューラルネットワークの推論のための分散型パイプラインとして動作します。モデルはいくつかのブロックに分割され、それぞれが異なるサーバー上でホストされます。 |
| 透明性 | ブロックの各入力と出力はネットワーク上で送信されるため、モデルのレイヤー間にタスク固有のアダプタを挿入することが可能です。これにより、サーバー上の事前学習済みモデルを変更することなく、軽量な微調整が可能となります。 |
| 実用性 | Petalsのインターフェースは、Transformersライブラリに非常に似ており、複雑なロジックなどは表示されず、分かりやすいUIになっています。 |
| ベンチマーク | Petalsは、同様のプラットフォームであるオフロードとの性能を比較して、レイテンシーが3〜25倍速いことが比較実験で示されています。 |
上記はPetalsの特徴一覧です。最大の特徴は分散型パイプラインとして動作する点。
分散型パイプラインについてもう少し詳しく説明すると、Petalsで大規模なモデルを動かせるのは、BitTorrentのようなP2Pの通信手法をとっているからです。
P2Pを使うと、容量の大きなファイルを大勢のユーザーで分散し共有することができます。BitTorrentの技術は、高速で効率的なデータ転送を可能にするため、Petalsプラットフォームは大規模なモデルもスムーズに動作させることができるということですね。
さらにPetalsは、ファインチューニングやサンプリング方法も使用できるため、多様な用途に対応しています。
ここまでPetalsの概要をご説明してきましたが、ここからは実際に使いながら機能を紹介していきます。
なお、有名大規模言語モデルであるLlama2について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Petals対応モデル
Petalsは、さまざまな巨大言語モデルを分散ネットワーク上で扱える点が大きな特徴です。
公式のGitHubリポジトリでは、Llama 3.1(最大405B)、Mixtral(8×22B)、Falcon(40B+)、BLOOM(176B)といった主要モデルが対応モデルとして記載されています。
これらのモデルはいずれも個人のGPUでは扱いづらい規模ですが、Petalsの仕組みを通じて、ローカル環境からAPIのように利用できるようになります。
対応モデルは、Petalsが公開しているヘルスチェックページに一覧化されており、そこから任意のモデルを選択してネットワークに接続可能。
ユーザーは、選択したモデルの重みをローカルへダウンロードする必要はなく、分散ネットワーク内の他のピアが保持しているレイヤーに処理を委ねながら推論を進めます。
この設計により、巨大モデルであっても軽快に動作し、チャットや対話アプリケーションを中心に実用的な速度で利用可能です。
また、Petalsは既存のモデルを単に推論するだけではなく、ファインチューニングにも対応。
MixtralやLlama 3.1といった最新モデルを対象とした軽量チューニングにより、ユーザー固有のタスクへ適応させることも可能です。通常であれば大規模なリソースを必要とするモデルの学習も、分散協調によって現実的な負荷に抑えられます。
Petalsの安全性
Petalsは、分散環境でBLOOMを推論できる仕組みを持ちながら、安全性・プライバシー・AIリスクへの配慮が徹底されています。
利用時に重要となるポイントは「他のピアが任意のコードを実行できない設計」と「入力データが漏洩する可能性」です。
Petalsでは参加者同士が交換するのはテンソルのみであり、コードは送信されません。他のピアが実行できるのは、あらかじめ定義されたBLOOMのレイヤー処理に限られます。この構造により、外部から任意コードを実行されるリスクはありません。
一方で、入力データとモデル出力の復元や改ざんが理論上は可能である点は注意が必要。とくに機密データを扱う場合は、パブリックなスワームを使わず、信頼できるメンバーのみで構成されたプライベートスワームを構築する運用が推奨されています。
サーバーを公開する場合は、必要なポートのみ開放し、不要なポートを開いたままにすると他アプリケーションへ意図せぬアクセスを許してしまう可能性が高いです。
ネットワーク面では、PetalsはTCPとQUICをlibp2p経由で利用しており、IPFSや暗号資産の基盤でも用いられる技術が採用されています。
攻撃者が通信を妨害したり、一時的に無駄な処理を強いることはできても、任意コードの実行までは至りません。この点は分散システムに慣れていないユーザーにとって安心材料となるはずです。
Petalsの料金体系
Petalsはオープンソースプロジェクトであり、GitHubから無料でダウンロードして使用することができます。
ただし、Google Colab Pro / Pro + を使う場合、月額1,179円 / 5,767円がかかります。
それでは、気になるPetalsの導入方法を見ていきましょう。

Petalsの導入方法
以下のGoogle Colabファイルにアクセスします。
画面上部のメニューバーからランタイム→ランタイムのタイプを変更 をクリックします。
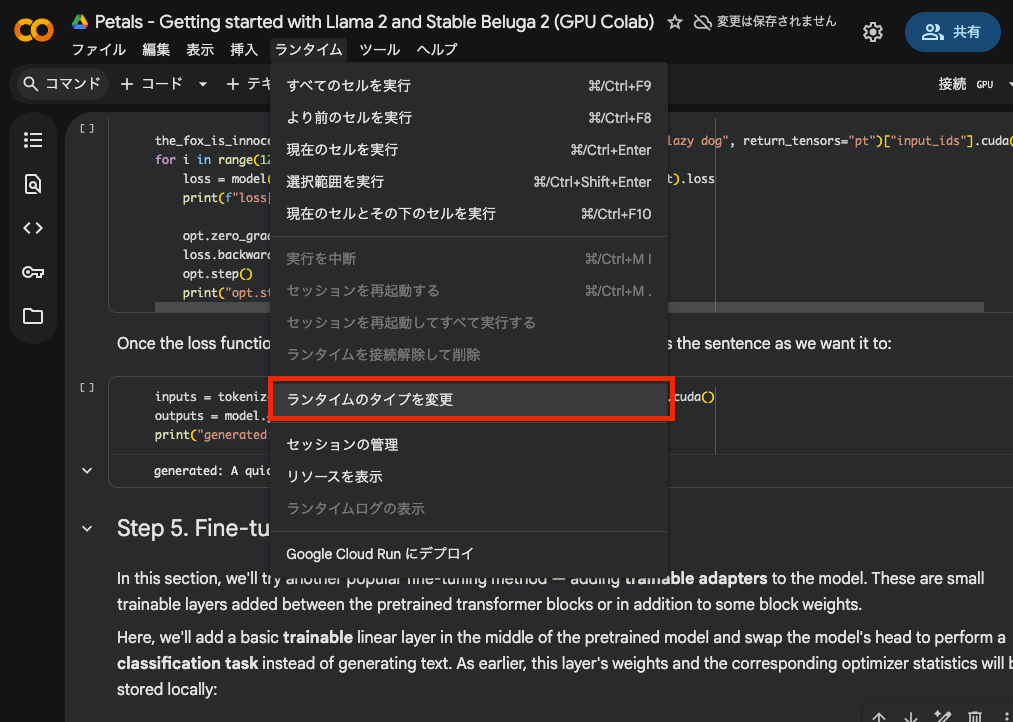
GPUを選択します。今回は、共有したColabファイルの初期設定のまま、T4 GPUを使いました。
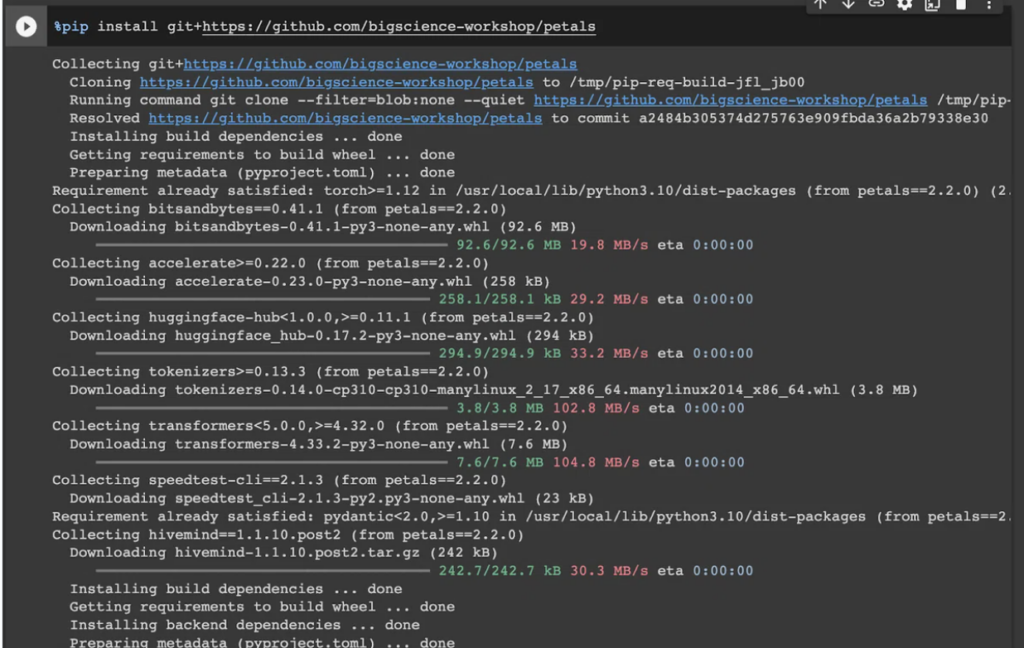
以下を実行しPetalsのパッケージをインストールします。
%pip install git+https://github.com/bigscience-workshop/petals実行すると以下のような画面になります。
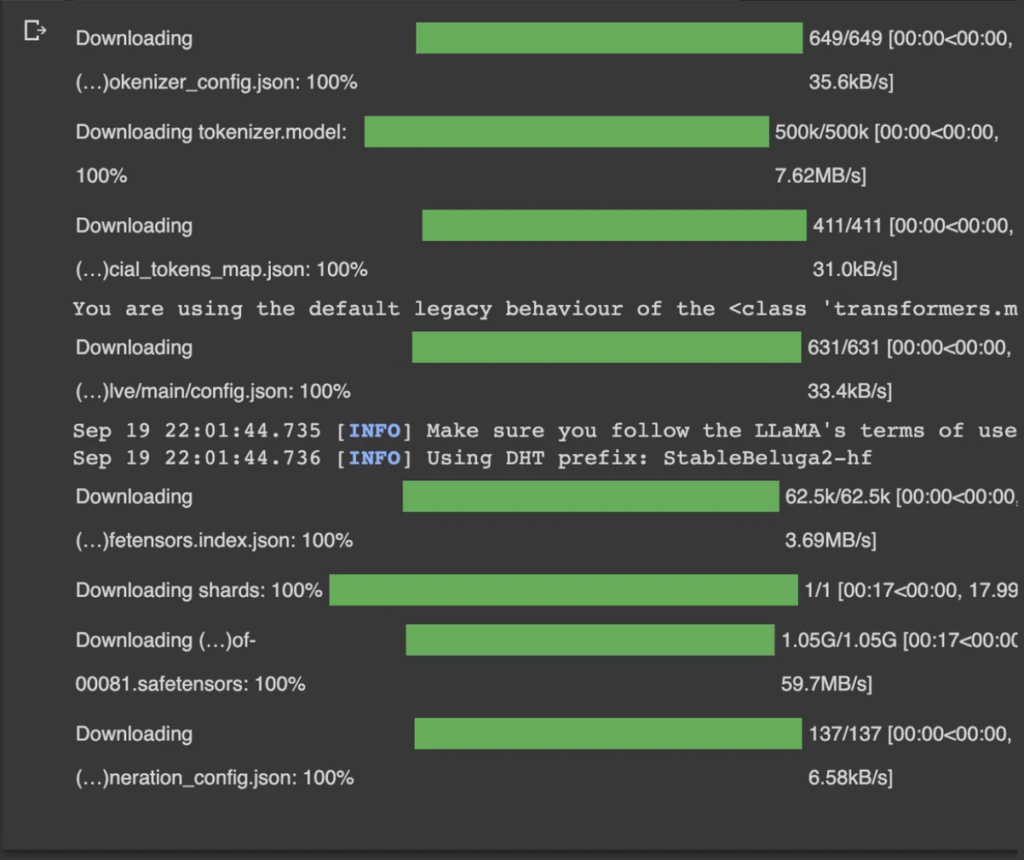
次に、以下を実行し、StableBeluga2というモデルをロードします。
import torch
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
model_name = "petals-team/StableBeluga2"
# You could also use "meta-llama/Llama-2-70b-chat-hf" or any other supported model from 🤗 Model Hub
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, add_bos_token=False)
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
model = model.cuda()このようになったら準備完了です。
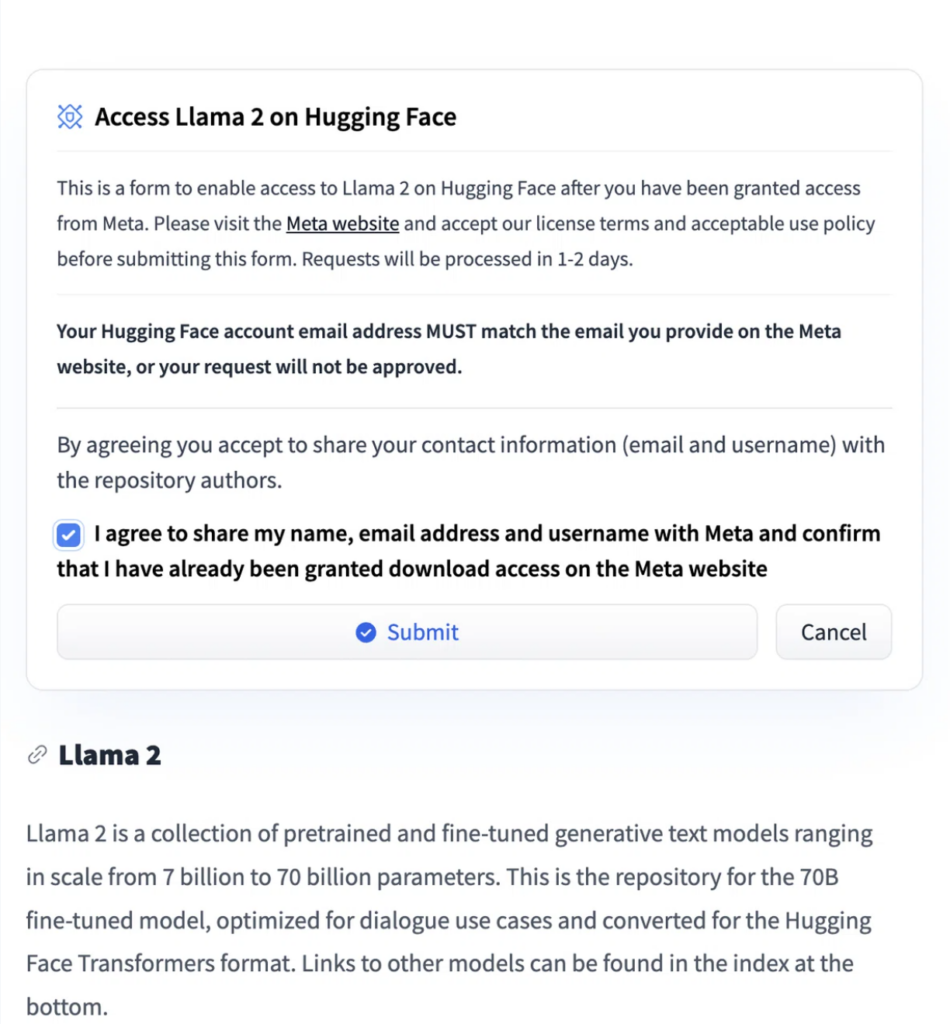
ちなみに、”meta-llama/Llama-2-70b-chat-hf”モデルを使う場合は、Metaにアクセストークンをリクエストする必要がありますので、以下の手順でリクエストを送信してください。
まずは、こちらのURLにアクセスします。
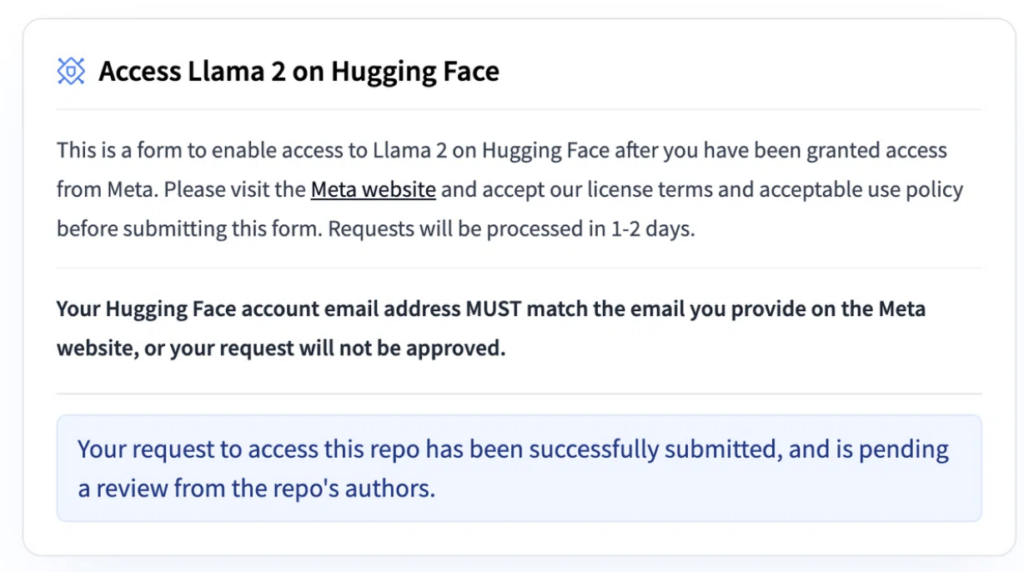
下にスクロールするとこんな画面があるので、「I agree…」にチェックを入れて、Submitを押しましょう
以下のように、リクエストに成功と出たらOKです。
次にHugging Faceのアクセストークンを取得します。
Hugging Faceにログインした状態で、以下のページにアクセスします。
New tokenをクリックして生成します。

終わったら、Google Colabで、以下のコマンドを実行。
!huggingface-cli login --token your-access-tokenLogin successfulと出たらOKです!

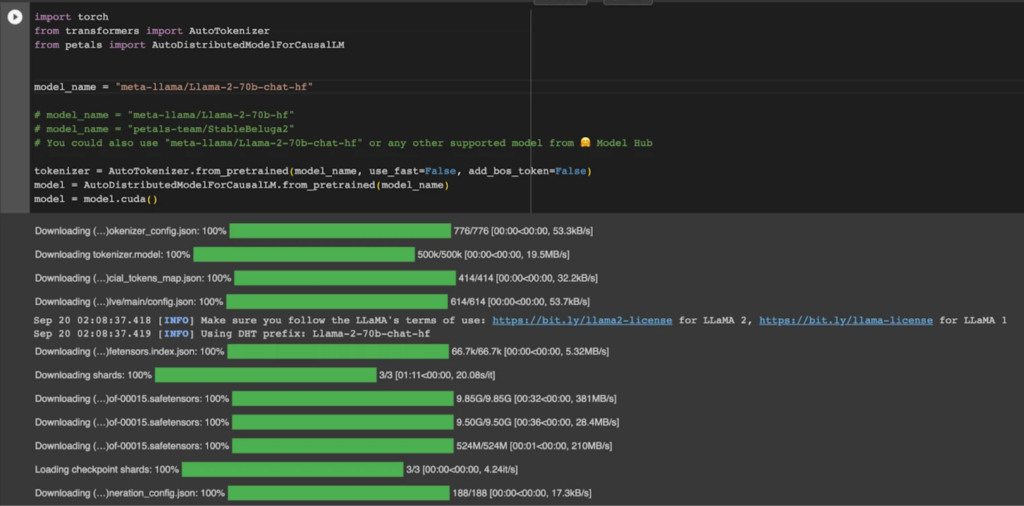
Llama-2-70b-chat-hf モデルを選択して実行する。
import torch
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
model_name = "meta-llama/Llama-2-70b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, add_bos_token=False)
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
model = model.cuda()以下のようになっていたらOKです!
Petalsを実際に使ってみた
ここからは、Petalsで出来ることを実際に試していきます。
テキスト生成
まずは、テキスト生成から。
以下を実行すると、文章の続きを生成してくれます。
今回の場合、「A cat in French is」に続く文章が生成されます。
inputs = tokenizer('A cat in French is "', return_tensors="pt")["input_ids"].cuda()
outputs = model.generate(inputs, max_new_tokens=3)
print(tokenizer.decode(outputs[0]))実行結果はこちらです。

「A cat はフランス語でun chat だ」と出力されています。
リアルタイムでのトークン生成
次は、リアルタイムでのトークン生成について。
以下を実行すると、出力が1トークンずつ生成されるところを確認できます。
fake_token = tokenizer("^")["input_ids"][0] # Workaround to make tokenizer.decode() keep leading spaces
text = "What is a good chatbot? Answer:"
prefix = tokenizer(text, return_tensors="pt")["input_ids"].cuda()
with model.inference_session(max_length=30) as sess:
for i in range(20):
# Prefix is passed only for the 1st token of the outputs
inputs = prefix if i == 0 else None
# Let's use sampling with temperature = 0.9 and top_p = 0.6 to get more diverse results
outputs = model.generate(inputs, max_new_tokens=1, session=sess,
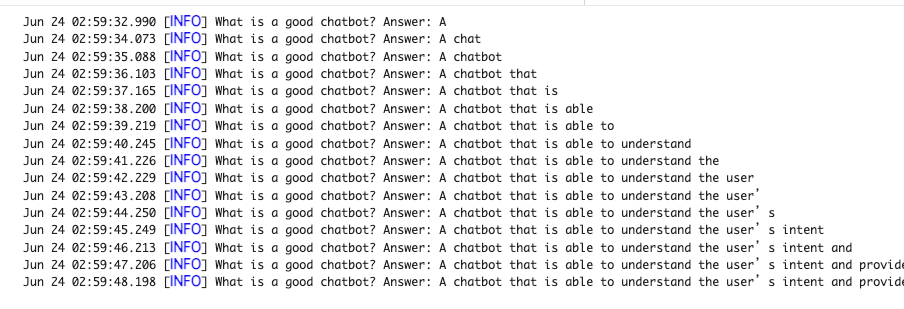
do_sample=True, temperature=0.9, top_p=0.6)今回のプロンプトは「What is a good chatbot? Answer:」です。
これに対する回答がトークンごとに出力されていきます。
段階を追って出力される様子は以下のとおりです。
チャットボットの作成
次はチャットボットについて。
以下を実行すると、会話ができるチャットボットを作れます。
with model.inference_session(max_length=512) as sess:
while True:
prompt = input('Human: ')
if prompt == "":
break
prefix = f"Human: {prompt}\nFriendly AI:"
prefix = tokenizer(prefix, return_tensors="pt")["input_ids"].cuda()
print("Friendly AI:", end="", flush=True)
while True:
outputs = model.generate(prefix, max_new_tokens=1, session=sess,
do_sample=True, temperature=0.9, top_p=0.6)
outputs = tokenizer.decode([fake_token, outputs[0, -1].item()])[1:]
# Now, let's print one new token at a time
print(outputs, end="", flush=True)
if "\n" in outputs or "</s>" in outputs:
break
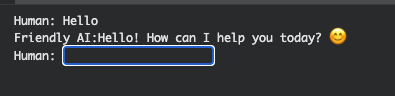
prefix = None # Prefix is passed only for the 1st token of the bot's responseこのように入力欄ができます。

「Hello」と書いてみると、あいさつが返ってきました!
Petalsの推しポイントである大規模言語モデルのロードは本当にできるのか?
それでは、推しポイントを確認していきます。
以下が推されていたので、実際に比較していきましょう。
- Llama 2(70B)モデルなどの大規模モデルをGoogle Colabや家庭用GPUで動かせる。
比較する環境は、Google Colab のA100 GPUです。
というわけで、Petalsを使った場合と使わなかった場合で本当に変化があるのか検証していきます。
Petalsを使わない場合
まずは、以下を実行し、Llama-2-70b-chat-hfをロードしました。
from transformers import AutoTokenizer
import transformers
import torch
# モデルID
model = "meta-llama/Llama-2-70b-chat-hf"
# トークナイザーとパイプラインの準備
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)モデルをロードする段階でディスクがパンパンに。
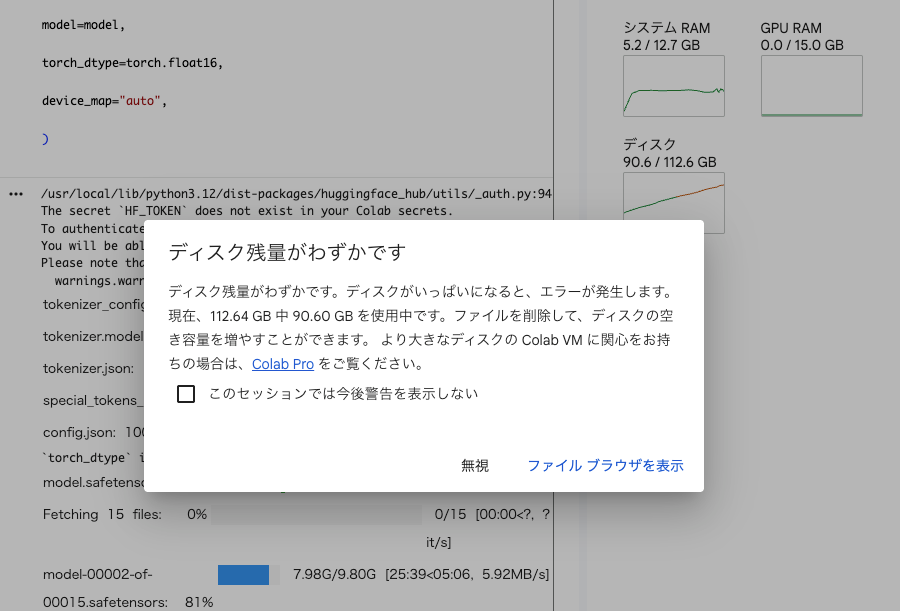
ですから、そのあともプロンプトを入力していますが動きません。ずっとセルの実行ボタンがクルクルしてます。
Petalsを使った場合
以下を実行し、同様にLlama-2-70b-chat-hfモデルをロードしました。
import torch
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
model_name = "meta-llama/Llama-2-70b-chat-hf"
# model_name = "meta-llama/Llama-2-70b-hf"
# model_name = "petals-team/StableBeluga2"
# You could also use "meta-llama/Llama-2-70b-chat-hf" or any other supported model from 🤗 Model Hub
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, add_bos_token=False)
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
model = model.cuda()問題なくロードできました。
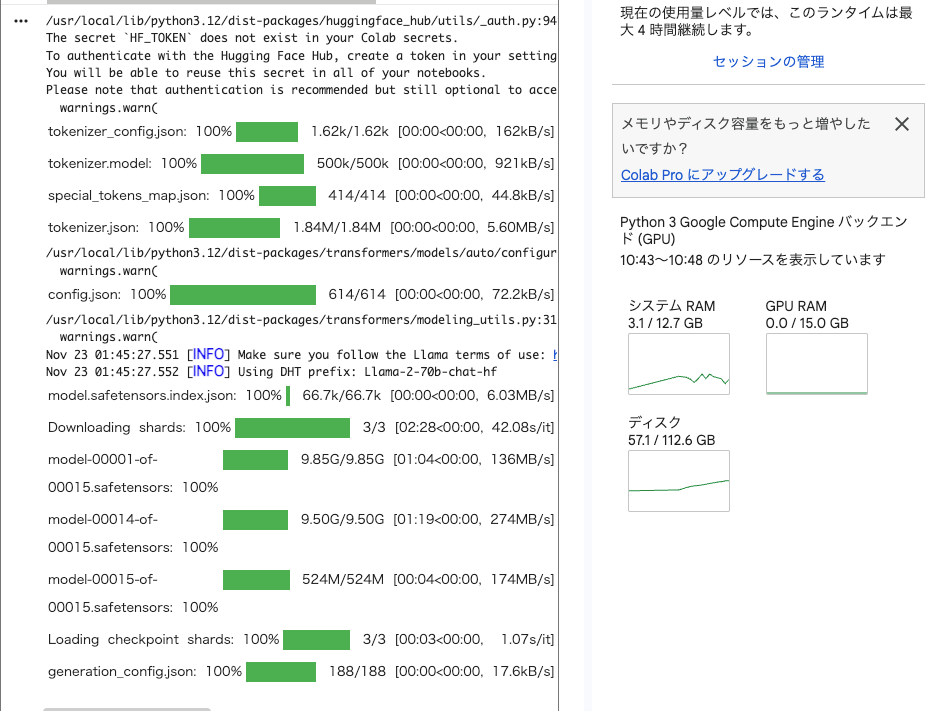
ディスク容量の圧迫具合も全然違います。
ちなみに、過去に記事を書きたかったのですが、実行できずに断念したFalcon-180Bモデルも実行してみました。
import torch
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
# model_name = "petals-team/StableBeluga2"
model_name = "tiiuae/falcon-180B"
# You could also use "meta-llama/Llama-2-70b-chat-hf" or any other supported model from 🤗 Model Hub
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, add_bos_token=False)
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
model = model.cuda()1800億のモデルが無事にロードできました!

Falcon-180Bは、本来ならA100GPUが8機必要らしいので、それが1機で難なくロードできているとなると、1/8以下のリソースで使用できることになるので、本当に便利ですね!
このプラットフォームを活用することで、今まで使えなかった強力なモデルをローカルで利用して、様々なタスクをこなすことが出来そうです。
なお、BLOOMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

よくある質問
ここではPetalsを使う際によくある質問に回答していきます。
まとめ
Petals は、家庭用のGPUやGoogle Colabを使用して、Llama 2(70B)、Falcon(180B)、BLOOM(176B)などの大規模な言語モデルの実行を可能にするためのプラットフォームです。
これは、BitTorrentのようなP2Pの通信手法をとって、モデルをいくつかに分割して、異なるサーバ上でロードすることで実現しています。
実際に使ってみた感想は、通常ではクラッシュしてしまうような規模のモデルのロードも難なく行うことができ、そのモデルを使って、推論の実行やチャットボットの作成もできました。
このプラットフォームを使えば、これまで使えなかったモデルが使えるようになり、LLMの活用の幅が広がると思うので、もしこの記事を読んで気になった方は、是非使ってみてください!

最後に
いかがだったでしょうか?
自社GPUやColabで70B超LLMを動かす現実性を、用途選定・性能/コスト試算・機密対策(プライベートスワーム設計)まで含めてPoCに落とし込めます。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

