
【Phi 3.5 MoE】業務改善を実現するMicrosoftのモデルを徹底解説!

- 数学や論理、コーディングなどの推論を必要とするタスクで優れた性能を発揮
- 20カ国以上の言語に対応
- 長文タスク対応
Phi 3.5 MoEはMicrosoftがリリースしているシリーズの一つです。 Mixture-of-Experts (MoE) アーキテクチャを採用し、効率的な計算処理を可能としています。
ベンチマークも優れており、軽量モデルながら大規模言語モデルと同等の性能を持っています。
本記事ではPhi 3.5 MoEの概要からgoogle colaboratoryでの実装方法について解説をしていきます。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Phi 3.5 MoEの概要
Phi 3.5 MoEは、最大32,064トークンの語彙サイズをサポートするオープンモデルであり、アクティブパラメータ数は6.6Bと比較的小さいにもかかわらず、高いパフォーマンスを発揮します。
トレーニングデータは合計4.9兆トークンで、そのうち10%が多言語です。
また、トレーニング後には安全対策が施されており、不適切な出力を拒否する能力も向上。ただし、完全に拒否することはできず、ユーザーが追加の調整やリスク評価を行うことが推奨されています。
Phi 3.5 MoEの性能
Phi 3.5 MoEは、公開されているドキュメントから、モデルの推論能力を高める可能性のある質の高いデータに焦点を当てています。
特定の日の株価データや市場動向など、フロンティアモデルのトレーニングデータとしては適していますが、小規模モデルの推論能力を高めるために削除する必要がある情報を含むようにフィルタリングされているということです。
ReasoningやMath、長いコンテキストでのコード理解で優れた性能を発揮します。
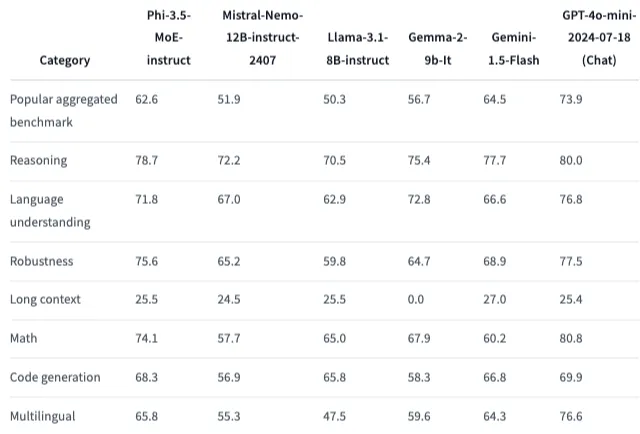
多言語対応もしており、対応言語は20カ国以上です。
対応言語例
アラビア語、中国語、チェコ語、デンマーク語、オランダ語、英語、フィンランド語、フランス語、
ドイツ語、ヘブライ語、ハンガリー語、イタリア語、日本語、韓国語、ノルウェー語、ポーランド語、
ポルトガル語、ロシア語、スペイン語、スウェーデン語、タイ語、トルコ、ウクライナ語
ただし、Hugging Faceのページにも記載されていますが、英語以外の言語では性能が低下する可能性があり、言語間で性能差が生じる可能性があることに注意が必要です。
なお、Phi 3.5について詳しく知りたい方は、以下の記事をご覧ください。

Phi 3.5 MoEの技術的な特徴
Phi 3.5 MoEは、Mixture-of-Experts (MoE) アーキテクチャを採用しており、全体のパラメータ数は16×3.8Bですが、実際にアクティブになるのは6.6Bパラメータに制限されています。このアーキテクチャにより、効率的かつ高精度な推論が可能です。
また、128Kトークンという非常に長いコンテキスト長をサポートしており、長文の要約や質疑応答、複雑なドキュメントの解析など、長い文脈を必要とするタスクに対応しています。
Mixture-of-Expertsアーキテクチャ
Mixture-of-Expertsアーキテクチャは大規模言語モデルの効率性と性能を向上させるための技術です。
モデルを複数の「エキスパート」サブネットワークに分割し、各エキスパートは特定のタイプの入力や特定のドメインに特化しています。典型的なMoEモデルでは、TransformerのFeed Forward層が複数のエキスパートに分割されます。
MoEを導入することで、トークンあたりのアクティブエキスパート数を一定に保ちつつ、モデルの総パラメータ数を増やすことが可能。また、計算コストを増加させることなく、モデルサイズの拡張ができます。
一方で、複数のエキスパートネットワークの管理には注意が必要であり、特定のエキスパートが過度に使用され他のエキスパートが十分に活用されない可能性もあるため、MoEを活用するには技術的な課題もともなっています。
Phi 3.5 MoEの最適化
Phi 3.5 MoEの最適化にはSupervised Fine-TuningとProximal Policy Optimization、Direct Preference Optimizationの3つの技術が使われています。
Supervised Fine-Tuningはモデルをあらかじめ準備された教師データでさらに訓練する技術であり、Proximal Policy Optimizationは強化学習で用いられる最適化手法の一種で、モデルが環境から得たフィードバックに基づいてパラメータを更新、Direct Preference Optimizationはモデルの出力に対して直接的な「好ましさ」を基準に最適化する方法です。
また、モデルのトレーニングデータは、高品質な公開文書や教育用データ、そしてプログラミングコードで構成。
さらに、数学やコーディング、常識的推論、一般的な知識を効率的に教えることを目的として、新たに作成された合成データも利用されています。また、公開文書に関しては、モデルの推論能力を最大限に引き出すため、知識の適切なレベルを保つようにフィルタリングが行われています。
例えば、特定の日のスポーツの結果のような短期間で価値が失われる情報は削除されています。
さらに、トレーニングデータには、高品質なチャット形式の教師データが含まれており、これによりユーザーの指示に忠実に従い、ハルシネーションを回避し、ユーザーの求めている応答を生成する能力が強化されています。
Phi 3.5 MoEのコスト効率化
Phi 3.5 MoEは上記のMixture-of-Expertsアーキテクチャや3つの最適化技術を取り入れることで、コスト効率化を実現しています。
限られたリソースの中で安全性や有用性を最大化するよう設計されており、その上で最大128Kトークンの文脈をサポートしているので、長文処理や複雑なタスクにも対応が可能になっています。
Phi 3.5 MoEのライセンス
Phi 3.5 MoEのライセンスは、MITライセンスです。基本的には商用利用や改変、私的利用など全て可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、カーソルの動きで動画を編集できる最先端動画生成AI【DragNUWA】について知りたい方はこちらの記事をご覧ください。

Phi 3.5 MoEの使い方
Phi 3.5 MoE instructの実装ですが、こちらはモデル容量が大きすぎてA100のGPUでもリソースが足りなくなってしまいます。
ライブラリのバージョンはHuggingFaceで指定されているので、それに則ります。
ライブラリのインポートはこちら
!pip install flash_attn==2.5.8 torch==2.3.1 accelerate==0.31.0 transformers==4.43.0デモコードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3.5-MoE-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3.5-MoE-instruct")
messages = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 100,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])Phi 3.5 mini instructやPhi 3.5 Vision instructはSpacesでデモ版が使えますが、Phi 3.5 MoEはSpacesの用意がありませんでした。そのため、コーディングをせずにPhi 3.5 MoEを使う場合には、Azure AI Studioで使うことになります。


Phi 3.5 MoE検証
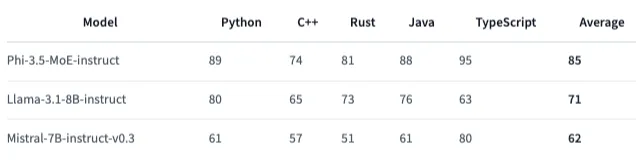
Phi 3.5 MoEはPythonのコードをトレーニングデータとして使っているため、特にPythonのコーディングを得意としています。
そこで、Pythonのコーディングタスクを2種類提示して、どのような結果になるかをGPT-4o-miniと比較してみたいと思います。
与えるタスクは次の2つです。
- クイックソートアルゴリズムを実装
- バグを含むコードの修正
今回の検証はgoogle colaboratoryでは実装できないため、Azure AI StudioでPhi 3.5 MoEをデプロイしてプレイグラウンドで実行します。
クイックソートアルゴリズムを実装
まずはクイックソートアルゴリズムを実装してもらいます。
プロンプトはこちらです。
クイックソートアルゴリズムを実装するPython関数を記述してください。
この関数は整数のリストを入力として受け取り、ソートされたリストを返す必要があります。結果はこちら
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
# 使用例:
arr = [3,6,8,10,1,2,1]
print("ソート前:", arr)
print("ソート後:", quicksort(arr)) ちなみに出力された結果を実行すると以下の結果が得られるので、ちゃんとコードを生成できていることがわかります。
ソート前: [3, 6, 8, 10, 1, 2, 1]
ソート後: [1, 1, 2, 3, 6, 8, 10]GPT-4o-miniの結果はこちら
def quick_sort(arr):
# ベースケース: リストが空または1つの要素しかない場合
if len(arr) <= 1:
return arr
# ピボットをリストの最初の要素に設定
pivot = arr[0]
# ピボットより小さい要素を左側、ピボットより大きい要素を右側に分ける
left = [x for x in arr[1:] if x <= pivot]
right = [x for x in arr[1:] if x > pivot]
# 再帰的に左と右をソートして、ピボットを中央に挿入する
return quick_sort(left) + [pivot] + quick_sort(right)
# 使用例
arr = [3, 6, 8, 10, 1, 2, 1]
sorted_arr = quick_sort(arr)
print(sorted_arr)こちらも問題なくコード生成されました。
バグを含むコードの修正
次にバグを含むコードを修正してもらいます。
与える情報はこちら
def calculate_average(numbers):
total = sum(numbers)
average = total / len(numbers)
return average
result = calculate_average([])
print(result)こちらのコードにバグを修正してください、と指示を加えて修正してもらいます。
結果はこちら
def calculate_average(numbers):
if len(numbers) == 0:
return None # または、提示する適切なエラーメッセージを返す
total = sum(numbers)
average = total / len(numbers)
return average
result = calculate_average([])
if result is not None:
print(result)
else:
print("リストが空です。平均を計算できません。") こちらはエラーハンドリングが追加され、不適切な場合にはエラーメッセージが返される仕様となりましたね。
GPT-4o-miniの結果はこちら
def calculate_average(numbers):
if len(numbers) == 0:
return 0 # 空のリストの場合、平均値を0または他の適切な値で返す
total = sum(numbers)
average = total / len(numbers)
return average
result = calculate_average([])
print(result) # 結果は0こちらはエラーメッセージを返すというよりも0を返すようになっていますね。しかし、平均値0っていうのは適切ではなく、Noneやエラーメッセージを返す方が仕様としてはいいように思います。
なお、視覚推論ができるQVQ-72B-Previewについて知りたい方はこちらの記事をご覧ください。

まとめ
本記事ではPhi 3.5 MoEの概要から実装方法についてお伝えをしました。
google colaboratoryでの実装方法もお伝えはしましたが、A100を使ってもリソースが不足するため、手軽に使いたい場合にはAzure AI Studioを使うのがおすすめです。
Phi 3.5 MoEは、数学や推論、コーディングなど高度な知識を要するタスクにおいて、効率的かつ高いパフォーマンスを発揮します。また、多言語対応や長文タスクへの適性を備え、さまざまなユースケースでの活用が期待されています。
特に、モデルの最適化にはSupervised Fine-TuningやDirect Preference Optimizationといった先進的な技術が導入されており、軽量ながらも大規模モデルに匹敵する性能を実現しています。
弊社では、Phi 3.5を活用したローカル環境でのデータ分析システムを開発しました。事例について詳しく知りたい方は以下の記事をご覧ください。

最後に
いかがだったでしょうか。
ローカル環境でのLLM活用は、セキュリティ強化やコスト効率の面で注目されています。自社データを最大限に活用し、競争力を高めるための具体的な導入方法をご提案いたします。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


