
【Qwen2.5-Turbo】1Mトークン対応のアリババLLM!リポジトリ丸々読ませてみた
2024/11/18、Alibabaから新たなLLMモデルが登場!
Qwen2.5-TurboはこれまでのLLMモデルに比べ、より長いコンテキストの処理が可能になり、従来のコストよりも大幅に抑えられます!
本記事では、Qwen2.5-Turboが従来のLLMと何が違うのか・何ができるのか、どうやって実装するのかについて詳しく解説します!
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Qwen2.5-Turboの概要
Qwen2.5-Turboは、コンテキスト長の大幅な拡張、高速な推論性能、低コストを実現したLLMです。
Qwen2.5-Turboの特徴は次の3つです。
- 100万トークンのコンテキスト対応
- 高速な推論速度
- 低コスト
100万トークンのコンテキスト対応
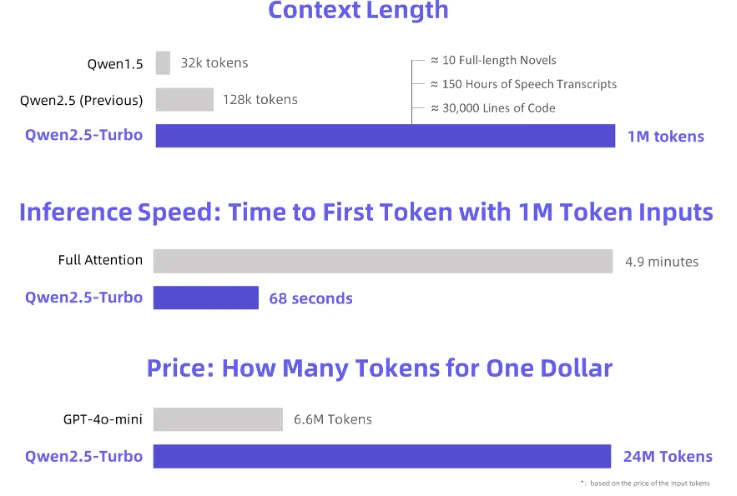
Qwen2.5-Turboは、従来の128kトークンから大幅に拡張し、最大100万トークンのコンテキスト処理を実現しました。
これは、約100万語の英語、150万字の中国語に相当し、10冊の長編小説、150時間分の音声記録、または3万行のコード量に匹敵します。
この長大なコンテキスト処理能力により、長編小説の理解、リポジトリ規模のコード支援、複数の研究論文の読解といった新たな用途が実現します。
高速な推論速度
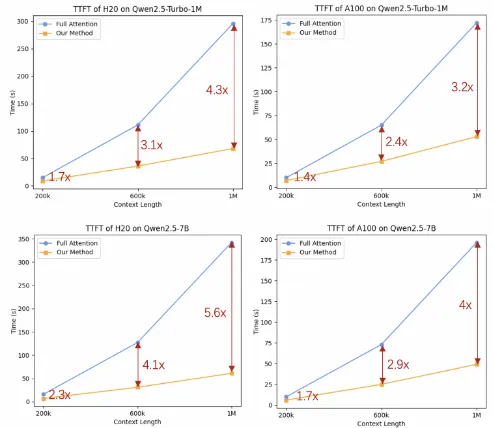
Qwen2.5-Turboはスパースアテンションメカニズムを採用することで、100万トークンのコンテキスト処理における最初のトークン生成時間を4.9分から68秒に短縮。これにより、推論速度は4.3倍の高速化を達成しています。
スパースアテンションメカニズムとは?
スパースアテンションメカニズムは、自然言語処理や機械学習の分野で使用される手法の一つで、大量のデータを効率的に処理するための工夫です。具体的には、自己注意機構(Self-Attention)を効率化するための技術。
自己注意機構では、すべての入力トークン同士の関係を計算するため、入力トークン数が増加すると計算コストがO(n²)に増大し、長いシーケンスの処理が大きな課題となります。
一方、スパースアテンションでは、すべてのトークン間の関係を計算するのではなく、重要な部分に注意を集中させる仕組みを採用。これにより、各トークンは文脈上関連性の高いトークンや一定距離内のトークンのみを考慮し、非対称的または局所的に注意を集中できます。
また、スパースアテンションでは、事前に定義されたルールに基づいて計算対象を絞ることも可能。
たとえば、固定サイズのウィンドウ内での計算や一定間隔でサンプリングしたトークンを対象にする方法があります。さらに、モデルが学習を通じて重要なトークン間の関係を動的に判断するスパース化手法も活用されます。これにより、計算コストとメモリ使用量を効率的に削減しながら、長いシーケンスの処理が可能です。
低コスト
100万トークンあたりの処理費用は0.3円と非常に低コストで、GPT-4o-miniの3.6倍のトークン数を同コストで処理可能です。
代表的なLLMのAPI料金は以下の通りです。
| モデル名 | コンテキストウィンドウ | 最大出力トークン数 | 入力料金 (100万トークンあたり) | 出力料金 (100万トークンあたり) | コンテキストキャッシュ保存料金 (100万トークンあたり/時間) | チューニング料金 | レート制限 (リクエスト/分) | レート制限 (トークン/分) |
|---|---|---|---|---|---|---|---|---|
| GPT-4o | 128,000 tokens | 16,384 tokens | $0.50 | $1.50 | 利用不可 | 無料 | – | – |
| GPT-4o-mini | 128,000 tokens | 16,384 tokens | $0.05 | $0.10 | 利用不可 | 無料 | – | – |
| GPT-4 Turbo | 128,000 tokens | 4,096 tokens | $0.10 | $0.30 | 利用不可 | 無料 | – | – |
| GPT-3.5 Turbo | 16,385 tokens | 4,096 tokens | $0.01 | $0.02 | 利用不可 | 無料 | – | – |
| Gemini 1.5 Flash | 128,000 tokens | 128,000 tokens | $0.075 | $0.30 | $1.00 | 無料 | 2,000 | 4,000,000 |
| Gemini 1.5 Flash-8B | 128,000 tokens | 128,000 tokens | $0.0375 | $0.15 | $0.25 | 無料 | 4,000 | 4,000,000 |
| Gemini 1.5 Pro | 128,000 tokens | 128,000 tokens | $1.25 | $5.00 | $4.50 | 利用不可 | 1,000 | 4,000,000 |
| Gemini 1.0 Pro | 30,000 tokens | 30,000 tokens | $0.50 | $1.50 | 利用不可 | 利用不可 | 360 | 120,000 |
Qwen2.5-Turboの性能
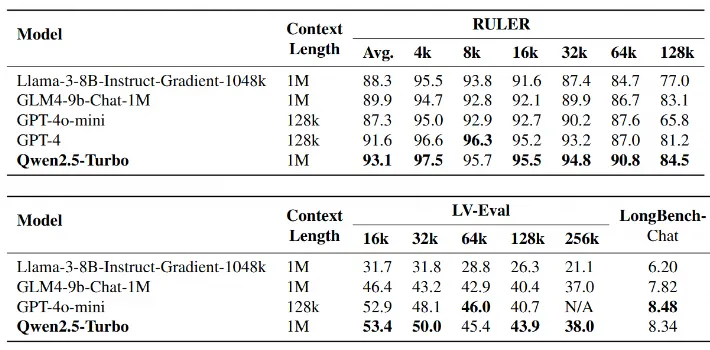
Qwen2.5-Turboは、超長文のコンテキスト処理において優れた性能を発揮します。
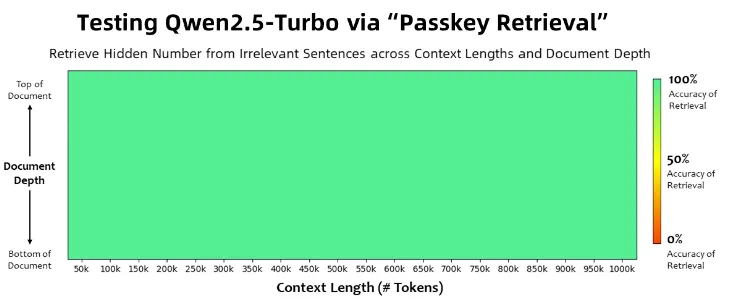
その一例として、Passkey Retrievalタスクでは、100万トークンのテキスト内に隠された数字をすべて正確に捉えることに成功し、超長文の詳細情報を正確に把握する能力が実証されています。
また、長文理解のベンチマークであるRULERにおいて93.1という高スコアを記録し、GPT-4o-miniやGPT-4を上回る結果を達成しています。
さらに、LV-EvalやLongBench-Chatといった他の長文理解タスクにおいても、ほとんどの項目でGPT-4o-miniを上回り、128Kトークンを超えるコンテキスト長を必要とするタスクを処理可能です。
短文タスクにおいても、Qwen2.5-Turboは優れた性能を発揮。
通常、コンテキスト長の延長は短文処理能力に影響を与えることがありますが、このモデルではその影響を最小限に抑える設計がなされており、多くのタスクで他の100万トークン対応モデルを大幅に上回っています。
また、GPT-4o-miniやQwen2.5-14B-Instructモデルと比較して8倍のコンテキスト長をサポートしつつ、短文タスクにおいて同等の性能を発揮する点も特筆すべきです。
Qwen2.5-Turboのライセンス
Qwen2.5-TurboのライセンスはApache 2.0ライセンスです。
Apache 2.0ライセンスは特許ライセンスを含んでいるため、商用利用を含む幅広い使用が可能。再配布や改変時に、元のライセンス条項と表示が求められます。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、プログラミング特化LLMであるQwen2.5-Coderについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Qwen2.5-Turboの使い方
Qwen2.5-TurboはAPIを使って使用する場合とDemoを使って動かす場合とがあります。
まずはどういったものなのかを感じてみたい方はDemoから始めてみるのがおすすめです。
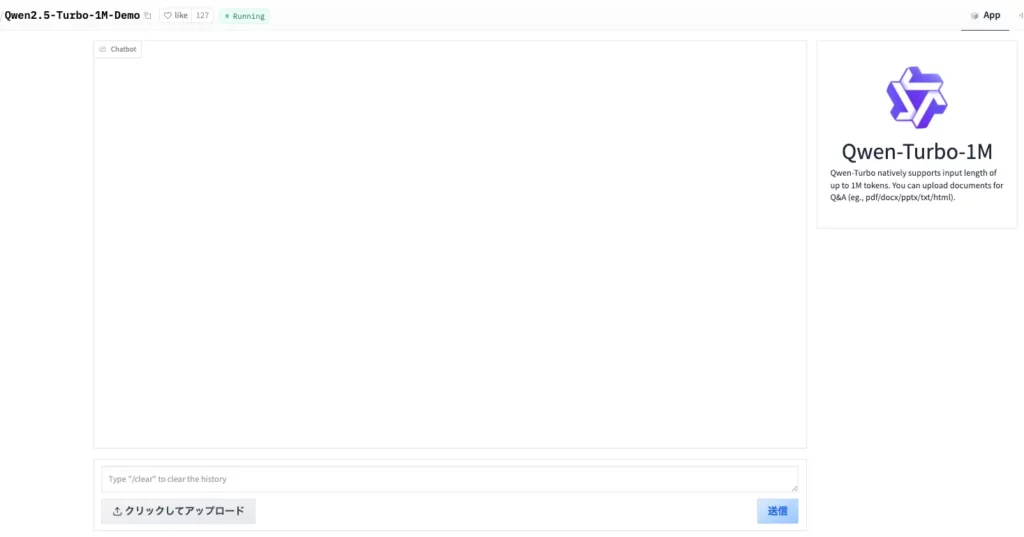
Demoを使う場合は、上記のサイトにアクセスして、プロンプト入力およびテキストファイルをアップロードします。
日本語でプロンプトを入力しても中国語で出力されてしまうので、可能なら英語で指示を与えるようにしましょう。
APIを使ってQwen2.5-Turbo使う方法
Qwen2.5-TurboをAPI経由で使用するには、Alibaba CloudeでAPIを取得する必要があります。
APIを使う場合にはドキュメントも用意されているので、そちらも参考にしつつ実装するのがいいでしょう。
ログイン後、APIを取得したら以下のコードを入力しましょう。
サンプルコードはこちら
import os
from openai import OpenAI
# APIキーを設定
api_key = "API_Key"
os.environ["YOUR_API_KEY"] = api_key
# 指定されたパスからファイルを読み込む
file_path = "/content/example.txt"
# ファイルを読み込む
with open(file_path, "r", encoding="utf-8") as f:
text = f.read()
user_input = text + "\n\nSummarize the above text."
# OpenAIクライアントの設定
client = OpenAI(
api_key=os.getenv("YOUR_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# APIリクエストの実行
completion = client.chat.completions.create(
model="qwen-turbo-latest",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': user_input},
],
)
print(completion.choices[0].message)このコードでは、google colaboratory上に保存したテキストファイルを読み込み、要約することができます。
Qwen2.5-TurboにGitHubリポジトリを読み込ませてコードを改変する
Qwen2.5-Turboは超長文のコンテキスト処理において優れた性能を発揮するため、GitHubのリポジトリを読み込ませて、コードが改変できるのかを検証してみたいと思います。
GitHubのリポジトリは以下のようにURLを変更するとテキスト化することができます。
"http://github.com"の"g"を"u"→"https://uithub.com"今回はPyGWalkerのVisualizationをWebアプリともして使いたいのですが、どこをどのように変更すれば良いかテキストで教えてくださいとプロンプトを入れています。
ただし、英語でないとレスポンスが悪いので英語で以下のように入力しました。
I want to be able to use the Visualization of the code in the pdf as a web service, so please tell me in text what to change and how!
Qwen2.5-Turboの活用方法
Qwen2.5-Turboは、超長文の理解と処理に優れているため、特定の用途や業界における活用をさらに深めることができます。
超長文の分析や要約には、最大1Mトークンのコンテキスト処理能力を活用することで、書籍、契約書、法務文書、研究論文などの超長文データを効率的に分析し、要約ができるでしょう。
たとえば、法律事務所では契約書や規制文書の重要部分を自動的にハイライトし、リスクや矛盾箇所の特定。また、研究者は複数の論文を比較分析し、主要な結論やデータ傾向を一目で把握すが可能です。この機能は、企業の意思決定や効率的な情報収集に役立つだけでなく、時間やコストの削減にも貢献します。
また、大規模なコードベースや複数のリポジトリを一度に解析し、リファクタリングの効率化も可能です。
コード全体の構造を理解し、関数間の依存関係や未使用コードの特定を行い、バグの検出や修正の提案、コードの整理案を提供し、保守性を向上させます。
さらに、自動的にドキュメントを生成することで、開発者がコードの背景や意図を容易に理解できるようにすることもできるでしょう。
これにより、チーム間の連携が円滑になり、プロジェクトの生産性を大幅に向上させることが期待されます。
なお、GPT-4oやLlama 3.1 405Bと競合する驚異の72B言語モデルのAthene-V2について詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事では、Qwen2.5-Turboについて解説をしました。超長文テキストを読み込めるようになったため、これまで時間がかかっていたコードの改変が非常に手軽にできるようになりました。
オープンソースのコードを手軽に改変できるようになると、自身の開発したいものを短期間で開発できるようにもなりますね。
ぜひ本記事を参考に、Qwen2.5-Turboを使ってみてください!
最後に
いかがだったでしょうか?
長文タスクの性能がビジネスの効率化や開発の加速にどのように活用できるか、個々の課題に合わせた具体的な事例をご提案します!
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


