
【Qwen3.7-Max】35時間の自律タスク実行を実現したAlibabaの最新エージェント特化モデルを徹底解説

- Alibabaが2026年5月のAlibaba Cloud Summitで発表したエージェント時代のためのフラッグシップAIモデル
- Artificial Analysis Intelligence Indexでスコア57を記録
- 内部テストでは最大35時間の自律実行と1,000回以上のツール呼び出しを達成
Alibabaは、2026年5月に開催したAlibaba Cloud Summit 2026で、Qwenシリーズの最新フラッグシップモデル「Qwen3.7-Max」を発表しました!
Qwen3.7-Maxは、エージェント用途に特化した設計となっており、コーディングからオフィス業務の自動化まで、数百から数千ステップにおよぶ長期タスクを安定して処理できるとされています。
とはいえ、「具体的にどんな性能なの」「既存のGPT-5.5やClaude Opus 4.7とどう違うの」と気になっている方も多いのではないでしょうか。
そこで本記事では、Qwen3.7-Maxの概要から仕組み、ベンチマーク、料金体系、実際の使い方に至るまで徹底解説します。ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/

Qwen3.7-Maxとは?

Qwen3.7-Maxは、Alibabaのクラウド部門が開発したエージェント時代のための基盤モデルです。
| 開発元 | Alibaba Cloud(Qwenチーム) |
|---|---|
| モデル名 | Qwen3.7-Max |
| 発表日 | 2026年5月20日(Alibaba Cloud Summit 2026) |
| モデルタイプ | 推論モデル(Reasoning Model) |
| コンテキストウィンドウ | 100万トークン |
| 最大出力トークン | 65,536トークン |
| 重み公開 | 非公開(プロプライエタリ) |
| 対応入出力 | テキスト入力・テキスト出力 |
Qwen3.7-Maxはエージェント時代のための基盤モデルという位置づけです。従来のチャットボット的な用途だけでなく、フロントエンドのプロトタイプ生成、複数ファイルにまたがるリファクタリングといったエンドツーエンドのコーディングエージェントとしての活用が想定されています。また、オフィスワークの自動化や生産性向上のためのアシスタントとしても利用可能です。
Qwenシリーズでは、各世代ごとに最上位の「Max」モデルをクローズドウェイト(非公開) で提供し、それより下位の小型モデルをオープンウェイトとして公開するという戦略を取ってきました。Qwen3.7-Maxもこの方針の通り、2026年5月時点ではモデルの重みは一般公開されていません。
Qwen3.8が登場!下記で詳しく解説
Qwen3.7-Maxの仕組み
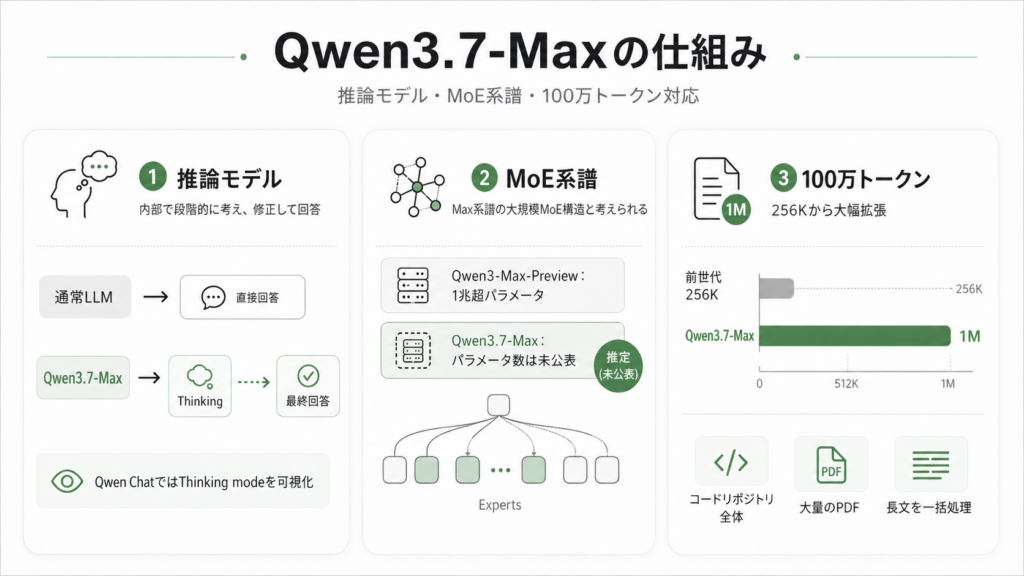
Qwen3.7-Maxの内部アーキテクチャについて、Alibaba公式からの技術レポートは2026年5月時点ではまだ公開されていません。ただし、これまでのQwenシリーズの情報や、公式発表から判明している技術的特徴を整理していきます。
Qwen3.7-Maxは推論モデル(Reasoning Model) に分類されます。通常のLLMが入力に対してダイレクトに回答を生成するのに対し、推論モデルはまず内部でChain-of-Thought(思考連鎖) のプロセスを展開し、ステップごとに考え、修正を加えたうえで最終回答を出力します。Qwen ChatのUIではこのプロセスを「Thinking mode」として可視化されています。
アーキテクチャとしては、過去のQwen3-Max-Previewが、1兆パラメータ超のスパースMoE(Mixture of Experts)構造を採用していました。Qwen3.7-MaxもMax系譜のモデルであるため、大規模なMoE構造を踏襲している可能性が高いと考えられますが、パラメータ数の公式発表は2026年5月時点ではなされていません。


Qwen3.7-Maxの特徴
ここからはQwen3.7-Maxの性能を、第三者評価を中心に見ていきましょう。
Artificial Analysis Intelligence Indexでハイスコアを記録
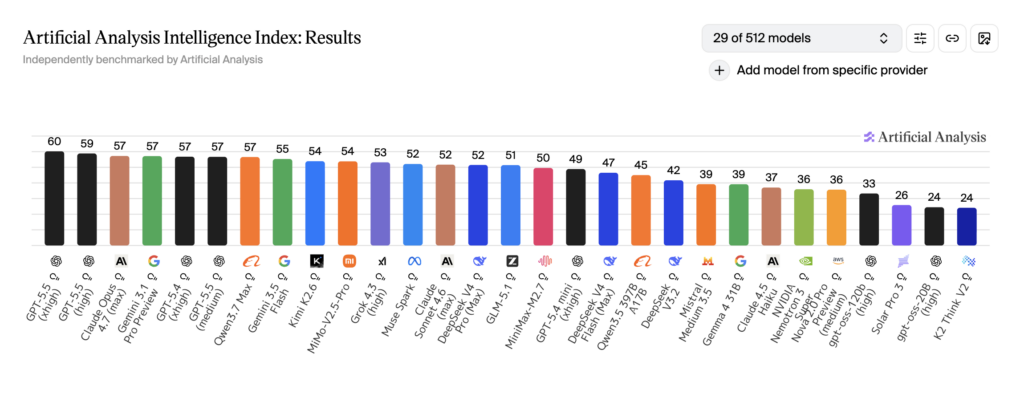
Artificial Analysis Intelligence Indexは、推論・知識・数学・コーディングなどを複合的に評価するベンチマークです。Qwen3.7-Maxはこの指標でGPT-5.5やClaude Opus 4.7に匹敵するスコア57を記録し、7位にランクインしています。前世代のQwen3.6-Max-Previewのスコア52から5ポイントの向上で、Qwenシリーズとしては過去最高の成績となっています。
LM Arena(旧LMSYSアリーナ)でのEloレーティング
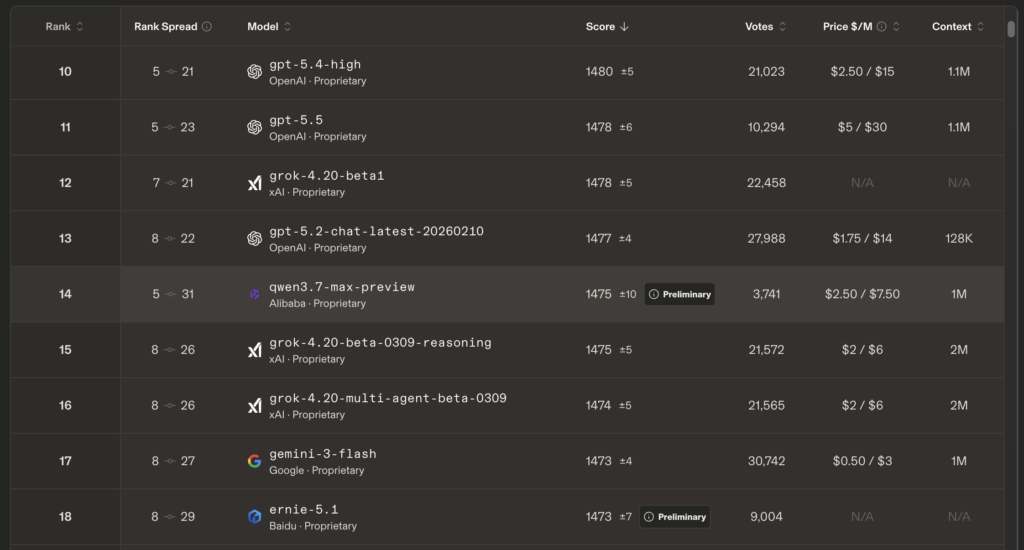
人間の比較評価に基づくLM Arenaのテキストリーダーボードでは、Elo約1,475を記録し、全体14位にランクインしています。カテゴリ別では数学で7位、エキスパートプロンプトで9位、コーディングで10位と、特に技術系タスクにおいて高い評価を得ています。
GPQA Diamondでの推論精度
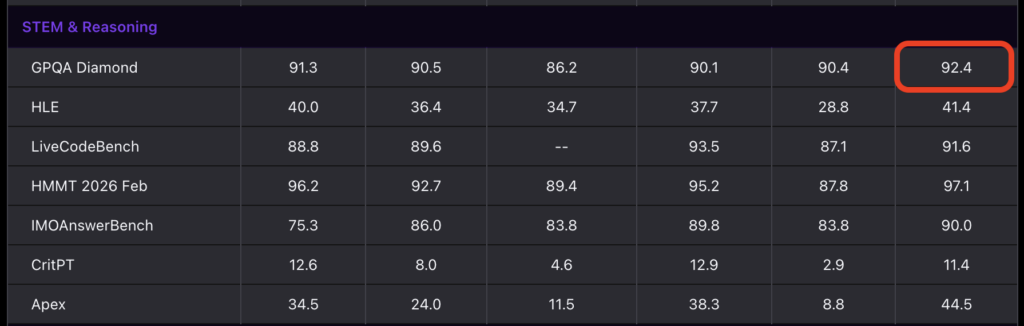
大学院レベルの科学的推論を問うGPQA Diamondベンチマークでは、92.4%のスコアを記録しています。この数値はClaude Opus 4.6の91.3%をわずかに上回るもので、中国発モデルとして科学的推論分野でもフロンティアモデルと競合できるレベルに到達していることを示しています。
35時間の自律タスク実行
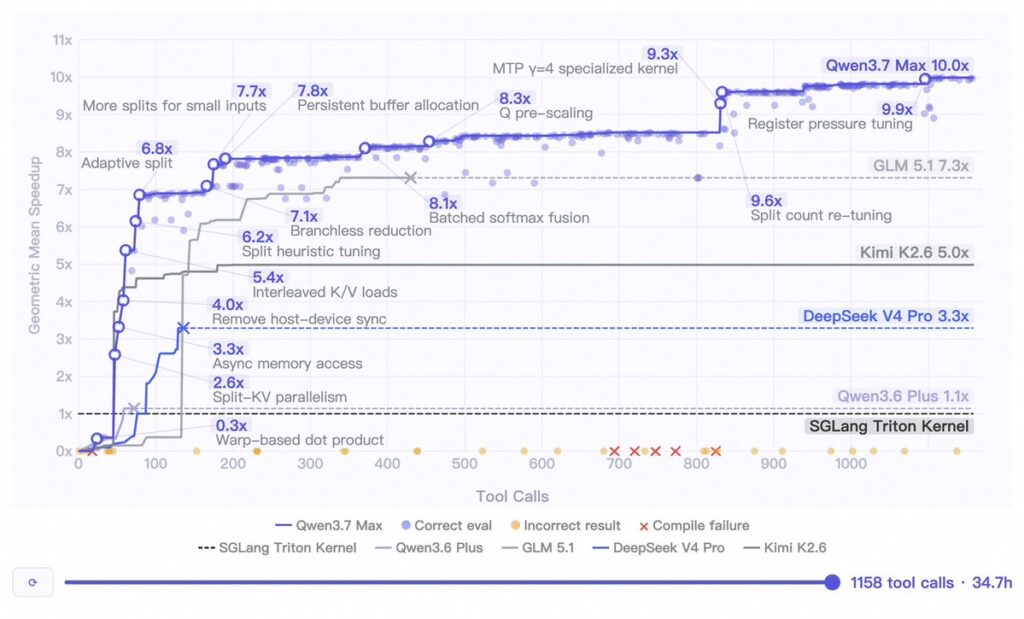
Alibaba公式の内部テストでは、新しいチップ上でExtend Attentionカーネルの最適化タスクを実行し、1,000回以上のツール呼び出しと反復的なコード修正を自律的に行い、推論速度を約10倍向上させることに成功したと報告されています。このタスクは最大35時間にわたる自律実行で行われ、パフォーマンスの大幅な劣化なく完了したとのことです。
X(旧Twitter)上での反響:Arena登場前からの注目
Qwen3.7-Maxは公式発表前にArenaに登場するという異例のリリース戦略をとったことで、SNS上で大きな話題を集めました。ここからは、X上で注目を集めたポストを紹介します。
公式アカウントは5月18日にArenaへのプレビュー投入を発表しており、多くの反響がありました。
日本のAIコミュニティでも注目が集まっており、以下のポストでは、Thinking modeの搭載をQwen3.7の最大の目玉として紹介しています。
また、以下のポストでは、ローカル実行モデルへの期待感とともにQwen3.7の登場を伝えています。
「まだローカルではないけど」というコメントは、Qwenシリーズがこれまでオープンウェイトの中型モデルをApache 2.0ライセンスで公開してきた実績を踏まえたものだと思います。開発者コミュニティの間では、Qwen3.7のオープンウェイト版がいつ公開されるかが次の関心事になっています。
Qwen3.7-Maxの安全性・制約
Qwen3.7-Maxはプロプライエタリモデルであり、現時点では安全性に関する詳細な技術レポートは公開されていません。
ただし、Alibaba Cloudのプラットフォームで提供されるモデルは、中国のAI規制(生成式人工知能管理弁法) に準拠した安全対策が施されています。また、Qwen3.7-Maxはテキストのみの入出力に対応しており、画像やマルチモーダル入力には非対応です。
Qwen3.7-Maxの料金
Qwen3.7-Maxの料金体系について整理します。なお、Alibaba Cloud公式からの正式な料金発表はまだ完了しておらず、以下はOpenRouterでの提供価格と前世代の参考価格を基にした情報です。正式なAlibaba Cloud経由の料金はAPIロールアウト時に確定する見込みです。
| モデル | 入力(100万トークンあたり) | 出力(100万トークンあたり) | コンテキスト |
|---|---|---|---|
| Qwen3.7-Max(OpenRouter) | $2.50 | $7.50 | 100万トークン |
| Qwen3.6-Max-Preview(Alibaba Cloud参考) | $1.30 | $7.80 | 256Kトークン |
| Qwen3-Max(OpenRouter) | $0.78 | $3.90 | 262Kトークン |
OpenRouterでの価格は入力100万トークンあたり$2.50、出力100万トークンあたり$7.50となっています。前世代のQwen3.6-Max-Previewと比較すると、入力が約1.9倍に上昇していますが、コンテキストウィンドウが256Kから100万トークンへと約4倍に拡大している点を考慮すると、長文処理におけるコストパフォーマンスは決して悪くありません。
Qwen3.7-Maxのライセンス
Qwen3.7-Maxはプロプライエタリ(クローズドウェイト)モデルであり、モデルの重みは一般公開されていません。そのため、利用はAlibaba CloudのAPIまたはQwen Chatインターフェースを通じて行う形になります。
| 利用形態 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | API経由で可能 |
| 改変 | ❌️ | モデル重みは非公開 |
| 再配布 | ❌️ | モデル重みは非公開 |
| 特許利用 | – | 非公開のため該当せず |
| 私的利用 | ⭕️ |


Qwen3.7-Maxの使い方
Qwen3.7-Maxは、2026年5月時点で主に2つの方法で利用できます。それぞれの方法をステップごとにご紹介します。
Qwen Chat(Webインターフェース)で使う方法
もっとも手軽にQwen3.7-Maxを試せるのが、Qwen公式のチャットインターフェースです。
チャット画面の左上または設定画面にあるモデルセレクターから「Qwen3.7-Max」を選択します。
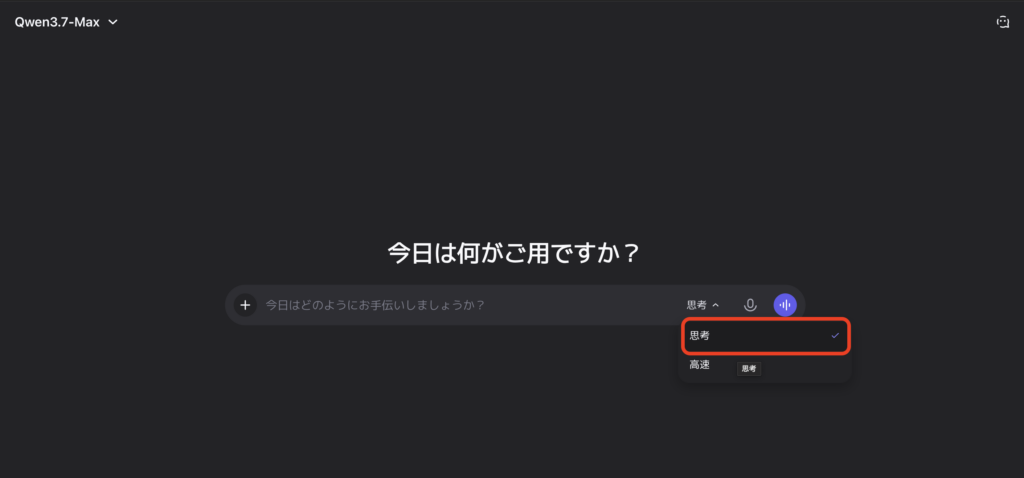
推論モデルの特性を活かすため、Thinking mode(思考モード) をオンにします。これにより、モデルの内部推論プロセスが可視化され、より深い分析や段階的な問題解決が行われるようになります。
テキストボックスにプロンプトを入力し、送信します。コーディングやデータ分析などの複雑なタスクでは、Thinking modeの展開に時間がかかる場合がありますが、その分精度の高い回答が期待できます。
API(Alibaba Cloud Model Studio / OpenRouter)で使う方法
開発者向けには、APIを通じてプログラムからQwen3.7-Maxを呼び出すことが可能です。
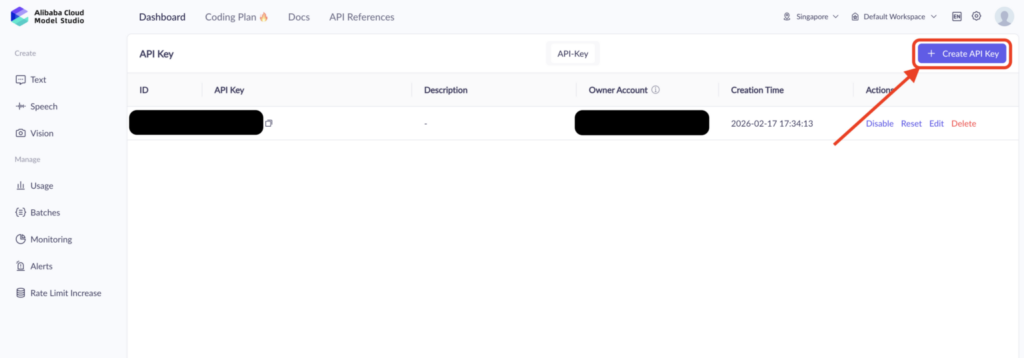
Alibaba Cloud Model Studioにアクセスし、Alibaba Cloudのアカウントを作成します。ダッシュボードからAPIキーを発行してください。
Qwen APIはOpenAI互換のフォーマットに対応しているため、既存のOpenAI SDKを利用している場合、エンドポイントとAPIキーの変更だけで接続できます。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_DASHSCOPE_API_KEY",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
response = client.chat.completions.create(
model="qwen3.7-max",
messages=[
{"role": "user", "content": "Pythonでクイックソートを実装してください"}
]
)
print(response.choices[0].message.content)OpenRouterを利用している場合は、モデルIDとして qwen/qwen3.7-max を指定することで利用できます。
client = OpenAI(
api_key="YOUR_OPENROUTER_KEY",
base_url="https://openrouter.ai/api/v1"
)
response = client.chat.completions.create(
model="qwen/qwen3.7-max",
messages=[
{"role": "user", "content": "React+Tailwindでダッシュボードを構築して"}
]
)【業界別】Qwen3.7-Maxの活用シーン
Qwen3.7-Maxのエージェント特化型の設計は、さまざまな業界での導入が見込まれます。ここからは、アリババ公式が示している強みに基づいて、特に相性の良い業界をご紹介します。
ソフトウェア開発・IT業界
Qwen3.7-Maxは公式にコーディングエージェントとしての活用を前面に打ち出しています。フロントエンドのプロトタイプ生成、複数ファイルにまたがるリファクタリング、デバッグといった開発工程を自律的に実行できるため、開発チームの生産性向上に直結します。100万トークンのコンテキストウィンドウを活かせば、大規模なコードベースを一度に読み込んでの横断的な修正も可能です。
コーディングエージェント「Claude Code」vs「Codex」の比較について、詳しく知りたい方は以下の記事も参考にしてみてください。

金融・コンサルティング業界
Qwen3.7-Maxが持つGPQA Diamondで92.3%という高精度な推論力は、複雑な財務分析やリスク評価の場面で友好的でしょう。長時間にわたる自律タスク実行が可能な点は、大量のドキュメントを精査して報告書をまとめるようなワークフローにも適しています。
金融業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

研究・アカデミア
Qwen3.7-Maxは、大学院レベルの科学的推論において高いスコアを記録しているため、論文の要約や先行研究の分析、複雑な数式の解法といった学術用途にも活用できるでしょう。100万トークンのコンテキストにより、長大な論文を複数同時に読み込んで比較分析することも可能です。
教育業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Qwen3.7-Maxが解決できること
続いてここからは、業界を横断して、Qwen3.7-Maxが解決できることを課題別に整理していきましょう。
大規模コードベースの保守・リファクタリング
Qwen3.7-Maxが持つ100万トークンのコンテキストウィンドウにより、数十ファイルにまたがるプロジェクトを一括で読み込み、依存関係を把握したうえで安全なリファクタリングを提案・実行することが期待できます。手動で行えば数日かかる作業を、エージェントとして自律的に処理できる可能性があります。
長時間にわたるマルチステップの自動化タスク
Qwen3.7-Maxは、最大35時間の自律実行と1,000回以上のツール呼び出しが可能なため、単発の質問応答ではなく、数百ステップにわたるワークフロー全体を自動化するようなユースケースに適しています。例えば、データ収集からクレンジング、分析、レポート作成までの一連の流れを一貫して処理する場面が考えられます。
複雑な推論が必要な意思決定支援
Qwen3.7-MaxのGPQA Diamond 92.3%、LM Arena Math 7位という推論性能は、単純な情報検索では解決できない複合的な問題に対する強みとなるでしょう。複数の条件が絡み合う判断や、段階的な論理展開が必要な場面では、Thinking modeによる思考プロセスの可視化が特に役立ちそうです。
Qwen3.7-Maxを使ってみた
ここからは、実際にQwen3.7-Maxの実力を検証していきます。Qwen ChatからThinking modeをオンにした状態で、2つのタスクを試してみましょう。
検証1:複雑なアルゴリズム設計のコーディング
まずは、コーディングエージェントとしての実力を試すため、以下の検証を行います。
プロンプトはこちら
PythonでLRUキャッシュをダブルリンクリストとハッシュマップを使ってゼロから実装してください。
get()とput()の計算量はO(1)で、容量を超えた場合は最も古いエントリを削除してください。
テストコードも含めて完全なコードを出力してください。結果はこちら
import unittest
class Node:
"""ダブルリンクリストのノードクラス"""
def __init__(self, key: int = 0, value: int = 0):
self.key = key
self.value = value
self.prev = None
self.next = None
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.cache = {} # ハッシュマップ: key -> Node
# センチネルノード(ダミーノード)の初期化
self.head = Node()
self.tail = Node()
# 初期状態では head と tail を直接繋ぐ
self.head.next = self.tail
self.tail.prev = self.head
def _add_node(self, node: Node) -> None:
"""ノードを head の直後(最も新しい位置)に追加する"""
node.prev = self.head
node.next = self.head.next
self.head.next.prev = node
self.head.next = node
def _remove_node(self, node: Node) -> None:
"""リストから任意のノードを削除する"""
prev_node = node.prev
next_node = node.next
prev_node.next = next_node
next_node.prev = prev_node
def _move_to_head(self, node: Node) -> None:
"""既存のノードを先頭(最も新しい位置)に移動させる"""
self._remove_node(node)
self._add_node(node)
def _pop_tail(self) -> Node:
"""tail の直前(最も古い)のノードを削除し、そのノードを返す"""
res = self.tail.prev
self._remove_node(res)
return res
def get(self, key: int) -> int:
"""
キーが存在すれば値を返してそのノードを先頭に移動させる。
存在しなければ -1 を返す。
"""
if key not in self.cache:
return -1
node = self.cache[key]
self._move_to_head(node)
return node.value
def put(self, key: int, value: int) -> None:
"""
キーと値を追加・更新する。
容量を超えた場合は最も古いエントリを削除する。
"""
if key in self.cache:
# 既存キーの更新
node = self.cache[key]
node.value = value
self._move_to_head(node)
else:
# 新規キーの追加
new_node = Node(key, value)
self.cache[key] = new_node
self._add_node(new_node)
# 容量超過時の処理
if len(self.cache) > self.capacity:
tail = self._pop_tail()
del self.cache[tail.key] # ハッシュマップからも削除
# ==========================================
# テストコード
# ==========================================
class TestLRUCache(unittest.TestCase):
def test_basic_operations(self):
cache = LRUCache(2)
cache.put(1, 1)
cache.put(2, 2)
self.assertEqual(cache.get(1), 1) # キー1が使用され先頭に
cache.put(3, 3) # 容量超過のため、最も古いキー2が削除される
self.assertEqual(cache.get(2), -1)
cache.put(4, 4) # 容量超過のため、最も古いキー1が削除される
self.assertEqual(cache.get(1), -1)
self.assertEqual(cache.get(3), 3)
self.assertEqual(cache.get(4), 4)
def test_update_existing_key(self):
cache = LRUCache(2)
cache.put(1, 1)
cache.put(2, 2)
# 既存キーの値を更新(キー1が先頭に移動)
cache.put(1, 10)
self.assertEqual(cache.get(1), 10)
# 容量超過のため、最も古いキー2が削除される(キー1は更新されたため生き残る)
cache.put(3, 3)
self.assertEqual(cache.get(2), -1)
self.assertEqual(cache.get(3), 3)
def test_non_existent_key(self):
cache = LRUCache(1)
self.assertEqual(cache.get(5), -1)
if __name__ == '__main__':
unittest.main()
検証2:マルチステップの分析タスク
続いて、エージェント的な利用を想定したマルチステップタスクを試しました。
プロンプトはこちら
添付のCSVデータを分析して、
1. 異常値を検出し
2. トレンドを分析し
3. 今後3ヶ月の予測を行い
4. 経営層向けのサマリーレポートを日本語で作成してください結果はこちら
📊 業績分析および将来予測サマリーレポート
1. エグゼクティブサマリー
2025年の年間売上高は約2億1,751万円となり、前年(約1億3,919万円)から56.3%増という驚異的な成長を達成しました。アクティブ顧客数および平均客単価の両輪が好調に推移しており、事業は強い拡大フェーズにあります。ただし、特定の月におけるスパイク(突出した数値)やシステム障害による顧客離反など、いくつかの「異常値・特異点」が確認されたため、今後の施策における再現性の検証とインフラの安定化が課題です。
2. 異常値の検出と要因分析
データから以下の3つの顕著な異常値(特異点)が検出されました。
時期
該当指標の異常
要因とインパクト
2024年8月
解約110件 / 問い合わせ335件
(平時の約3〜4倍)
【システム障害(5日間停止)】
顧客の不信感に直結し、大量の解約(チャーン)を招きました。以降の問い合わせ件数のベースラインもやや上昇しています。
2024年12月
広告費5,318千円 / 新規238件
(平時の約5倍)
【年末大型キャンペーン】
大規模な投資により新規顧客を大量獲得。売上高の押し上げに大きく貢献しました。
2025年12月
新規220件 / 売上22,496千円
(備考は「通常」)
【未定義の年末要因 または データエラー】
備考は「通常」となっていますが、11月からの伸びが異常に急激です。何らかの販促が実施されたか、データ集計上のエラーの可能性があります。要因の特定が急務です。
3. トレンド分析(2024年 vs 2025年)
売上高の急成長
2024年の月商900万円台から、2025年末には月商2,000万円超へとスケールアップしました。
顧客基盤の拡大(アクティブ顧客数)
1,221人(2024/1)から2,559人(2025/12) へと約2.1倍に増加。2024年8月のシステム障害による減少からも完全に回復し、右肩上がりのトレンドを維持しています。
客単価の継続的な向上
平均客単価は7,820円から8,791円へと約12.4%上昇。新規顧客の獲得だけでなく、上位プランへのアップセルや付加価値の提供(LTVの向上)がうまく機能していることを示しています。
解約率のコントロール
顧客基数が2倍に増える中で、2024年8月のようなイベントを除けば解約数は30〜40件台に収まっており、カスタマーサクセスによるリテンション(維持)は健全に機能しています。
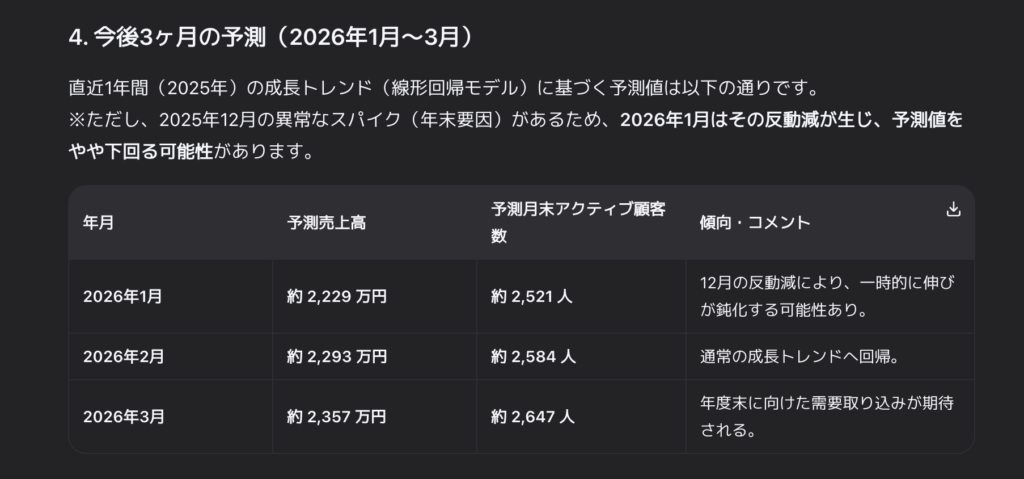
4. 今後3ヶ月の予測(2026年1月〜3月)
直近1年間(2025年)の成長トレンド(線形回帰モデル)に基づく予測値は以下の通りです。
※ただし、2025年12月の異常なスパイク(年末要因)があるため、2026年1月はその反動減が生じ、予測値をやや下回る可能性があります。
年月
予測売上高
予測月末アクティブ顧客数
傾向・コメント
2026年1月
約 2,229 万円
約 2,521 人
12月の反動減により、一時的に伸びが鈍化する可能性あり。
2026年2月
約 2,293 万円
約 2,584 人
通常の成長トレンドへ回帰。
2026年3月
約 2,357 万円
約 2,647 人
年度末に向けた需要取り込みが期待される。
5. 経営層への提言(アクションプラン)
【至急】2025年12月のスパイク要因の特定
備考が「通常」となっているにもかかわらず、新規顧客・売上がキャンペーン並みに跳ね上がった要因(自然増、代理店経由のまとまった契約、データ入力ミス等)を特定してください。これが「再現可能な施策」であれば、2026年の標準モデルとして組み込むべきです。
インフラ安定化とCR(顧客関係)管理の徹底
2024年8月の教訓から、システム障害が直接的な売上・顧客の損失に直結することが証明されています。顧客数が2,500人を超え、システム負荷が増大していることが予想されるため、インフラ投資および障害時の補償・コミュニケーション体制の見直しを推奨します。
アップセル・クロスセル施策の更なる強化
平均客単価の上昇トレンドは当社の強みです。顧客数の増加に伴いサポートコストも増大するため、少人数で高いLTVを維持できる「プロダクト-ledな上位プラン」への誘導をさらに加速させるべきです。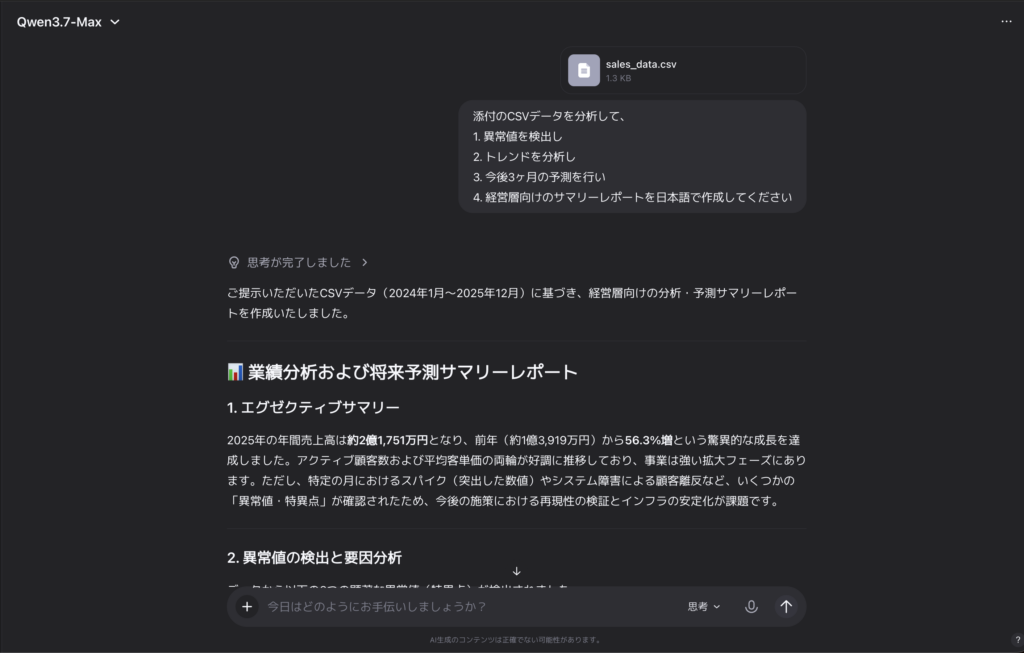

よくある質問
最後に、Qwen3.7-Maxについて、よくある質問とその回答をご紹介します。
Qwen3.7-Maxを試してみよう!
Qwen3.7-Maxは、Alibabaが「エージェント時代のフラッグシップ」と位置づけるだけあって、長時間の自律タスク実行と高精度な推論性能を両立したモデルとなっています。
Artificial Analysis Intelligence Indexでハイスコア、GPQA Diamondで92.3%、そして35時間の自律実行という公式テスト結果は、中国発のAIモデルがフロンティアモデルと本格的に競合するフェーズに入ったことを表しています。一方で、LM Arenaの人間評価ではまだ全体14位にとどまっており、すべての評価軸でトップというわけではありません。
コーディングエージェントや長期ワークフローの自動化といった用途では特に強みを発揮するモデルであり、Qwen Chatから手軽に試せる点も魅力です。今後のオープンウェイト版公開やAPI料金の正式発表にも注目が集まるため、引き続き最新情報をフォローしていきましょう。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

