
【Rnj-1】GPT-4oに匹敵するオープンソースLLM!?Essential AI発の80億パラメータのモデルを徹底解説

- 80億パラメータのオープンソースの言語モデルで、最大32,000トークンもの長大な文脈を扱えるよう設計
- 一部指標で、GPT-4oモデルに匹敵する性能を誇る
- コード生成と数理・科学分野(STEM)でよりよい性能を発揮するよう最適化されている
2025年12月6日、アメリカの新興AI企業Essential AIが「Rnj-1(レンジワン)」という大規模言語モデルを発表しました!
Essential AIは、高度なAI技術の開発と普及が、一部の企業に独占される現状に危機感を抱き、オープンソースでAIのブレイクスルーを推進することを目標に掲げています。
CEOのアシシュ・ヴァスワニ氏は、GoogleでTransformerを開発したチームの一員で、『Attention Is All You Need』論文の共著者としても知られる人物です。
そんな背景から生まれたRnj-1は、80億パラメータを持つオープンソースの言語モデルで、最大32,000トークンもの長大な文脈を扱えるよう設計されています。
驚くべきことに、Rnj-1はコード生成や科学技術分野の推論タスクで同等規模の他モデルを上回る性能を示し、一部の指標ではGPT-4クラスのモデルに匹敵する成果を収めています。
本記事では、このRnj-1の特徴や性能、使い方について詳しく解説していきます。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Rnj-1の概要

Rnj-1は、Essential AIが初めて公開したオープンウェイトの大規模言語モデルで、その名称はインドの天才数学者シュリニヴァーサ・ラマヌジャン(Ramanujan)に由来しているそうです。モデル名の「Rnj」はRamanujanの略称で、読み方は「レンジワン」です。
Rnj-1は、「Baseモデル(基礎モデル)」と、指示に従うよう追加訓練された「Instructモデル」のペアで提供されていて、われわれユーザーは、用途に応じて使い分けることができます。
このモデルのアーキテクチャは、Googleが公開している大規模言語モデル「Gemma-3」の構造をベースにした密結合Transformerです。
特徴的なのは、長文対応技術「YaRN」を導入することで、最大32,000トークンという非常に長いコンテキスト長を実現している点です。
これによって、長大なドキュメントの読解や長時間の対話、多段階の推論が求められるタスクもこなしてくれます。
また、Rnj-1は、コード生成と数理・科学分野(STEM)でよりよい性能を発揮するよう最適化されています。
ソフトウェア開発での用途を強く意識していて、PythonやJavaなど、様々なプログラミング言語でのコード生成・補完、デバッグ提案などに強みがあります。
加えて、高度な数学問題や科学的推論も得意としており、大学レベルの数学問題や物理・化学の難問に対しても同規模の他モデルに匹敵する回答能力を持っています。


Rnj-1の性能
Rnj-1の性能は、公開直後からAIコミュニティで大きな注目を集めています。
その理由は、80億という比較的小型のモデルでありながら、各種ベンチマークでこれまでの同規模モデルを大きく上回るスコアを叩き出したためです。
以下、主要な評価項目ごとにRnj-1の性能を見ていきましょう。
コード生成性能
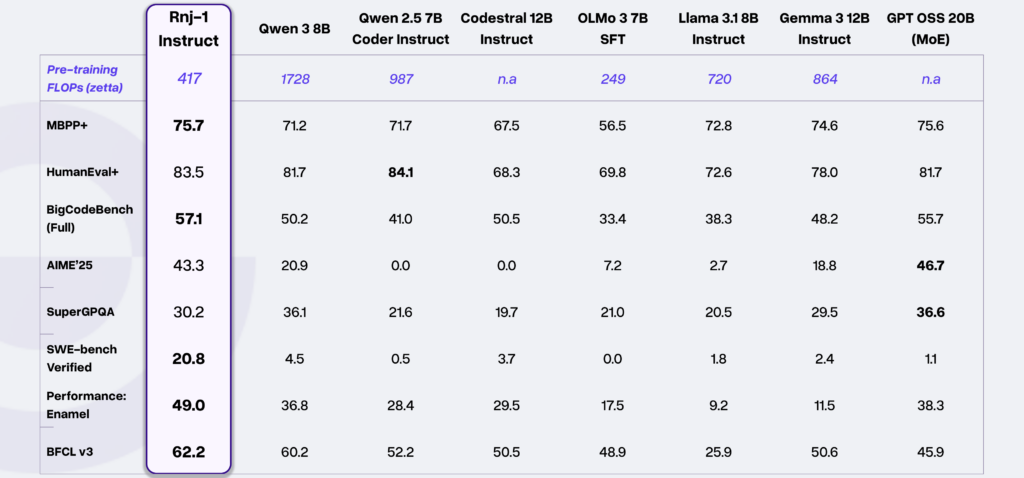
アルゴリズムコード生成(HumanEval+やMBPP+)、汎用的なコーディングタスク(BigCodeBenchなど)において、Rnj-1のBaseモデル・Instructモデルは、いずれも同規模トップクラスのオープンモデルに匹敵し、場合によっては20B規模のより大型なモデルを上回る性能を出しています。
特に、Essential AIが重視するエージェントコーディング(AIが自律的にコードを書き問題解決する能力)の分野では群を抜く結果を残しています。
ソフトウェアエンジニアリングタスクの指標となるSWE-benchでは、Rnj-1 Instructが20.8%というスコアを記録しており、この値は、他の80億級オープンモデルと比べて桁違いに高く、GoogleのGemini 2.0 Flashや、OpenAIのGPT-4oに匹敵する水準だと報告されています。
科学・数学分野の性能
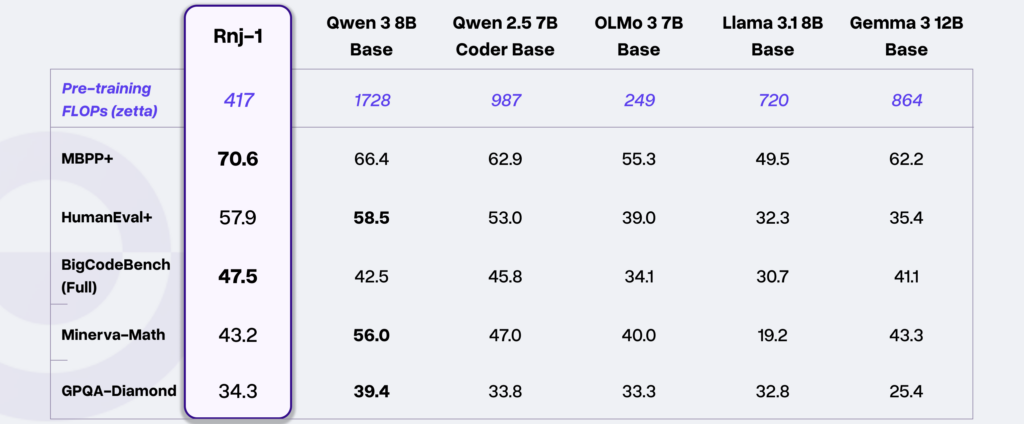
Rnj-1はコーディングだけでなく、数学や科学領域の高度な問題解決にも秀でています。
例えば、学部〜大学院レベルの数学的推論力を測るMinerva-MATHベンチマークでは、同規模のオープンウェイトモデルとほぼ同等のスコアを記録しました。
さらに、生物・物理・化学分野の博士課程レベルの難問集であるGPQA-Diamondにおいても、80億クラスのモデル中トップクラスに近い結果を残しています。
これは、小さなモデルであっても、適切なデータと訓練戦略によって、高度な専門知識を要する問題に対応できることが証明されており、Rnj-1のデータセットと訓練プロセスの質の高さを物語っています。
エージェント的な問題解決とツール使用
Rnj-1 Instructは、外部ツールや、関数を使いこなす能力でも優れた成績を収めています。
Berkeley Function Calling Leaderboard (BFCL)というツール使用能力の指標では、同等モデルを上回るトップクラスのスコアを達成しました。
また、モデル自身が、プログラミング環境内でコードを実行・プロファイルし、性能改善のためにコードを反復的に最適化する能力(Essential AIが開発中のmini-SWE-agentフレームワーク内での動作)も確認されています。
なお、GoogleのGeminiシリーズ最新モデル「Gemini 3.0 Pro」について、詳しく知りたい方は、以下の記事も参考にしてみてください。

Rnj-1のライセンス
Rnj-1は、Apache License 2.0の下で公開されています。
オープンソースライセンスであり、個人・企業問わず、自由にモデルを利用・改変・再配布することが許可されています。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |


Rnj-1の料金
Rnj-1そのものはオープンソースモデルのため、ライセンス料や利用料は一切かかりません。
Hugging Face上でモデルデータをダウンロードできますし、オンラインデモも提供されていて、基本的に無料で試すことができます。
| 利用方法 | 料金 |
|---|---|
| ローカルでモデルを実行(Hugging Faceからダウンロード) | 無料 |
| デモページを利用(Hugging Face Spaces) | 無料 |
| クラウドAPI経由(OpenRouterなどのサードパーティ) | 従量課金制 |
Rnj-1の使い方
Rnj-1の使い方としては、大きく分けてオンラインで手軽に試す方法と、モデルをダウンロードしてローカル環境で動かす方法の2通りがあります。それぞれ順に説明していきます。
オンライン(デモページ)
まず、1番お手軽なのは、Hugging Faceのデモページ(Spaces)を利用する方法です。
Essential AIは、Hugging Face上にRnj-1 Instructのデモ環境を公開しており、Webブラウザから誰でもアクセスできます。
このデモでは、入力ボックスにテキストを入れて送信するだけでモデルからの応答を得ることができます。
注意点として、このデモ環境はCPU上で動作しているため応答までに時間がかかる場合があります(数秒~十数秒程度)。しかしインストール不要で動かせるので、まずRnj-1の挙動を見てみたいという方にはおすすめです。
ローカル実行
本格的にRnj-1を活用したい場合は、モデルをダウンロードしてローカル環境で実行する方法があります。
Hugging Faceのモデルページ(EssentialAI/rnj-1, rnj-1-instruct)からモデルのチェックポイント(約16GB)を取得し、自身のマシンで読み込んで推論していく流れです。
環境準備
Pythonとtransformersライブラリ、GPU用のtorchをインストールします。モデルが大きいので、できればGPUメモリが16GB以上あるマシンが望ましいです。
モデル・トークナイザの読み込み
プログラム内でHugging FaceのモデルリポジトリからRnj-1をロードします。例えば以下の通りです。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "EssentialAI/rnj-1-instruct"
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)テキストを与えて推論実行
モデルに対して入力文を与え、テキスト生成を行います。Instructモデルはチャット形式を想定しているので、本来はシステムメッセージやユーザーメッセージの形式を整えるのが望ましいですが、簡易的にはシンプルなテキストでも動作します。例えば以下の通りです。
prompt = "こんにちは。自己紹介してください。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(answer)実行結果はanswer変数に文字列として格納されます。
Rnj-1を使ってみた
それでは実際に、Rnj-1の実力を確かめるために簡単な検証を行ってみましょう。上述したHugging Faceのデモページで実行していきます。
ここではRnj-1の得意分野である「コード生成」と「数学的な知識・推論」について、それぞれ試してみます。
コード生成
ニュートン法を用いて与えられた数値の平方根を近似計算するPython関数を書いてくださいニュートン法は、数学的知識とコーディング両方が求められる課題ですが、Rnj-1はどのようなコードを返すでしょうか。
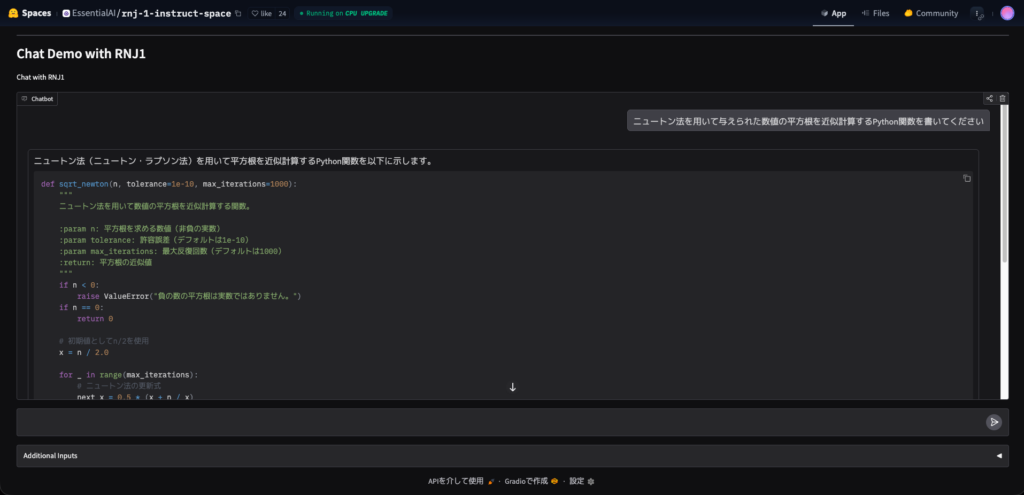
ニュートン法(ニュートン・ラプソン法)を用いて平方根を近似計算するPython関数を以下に示します。
def sqrt_newton(n, tolerance=1e-10, max_iterations=1000):
"""
ニュートン法を用いて数値の平方根を近似計算する関数。
:param n: 平方根を求める数値(非負の実数)
:param tolerance: 許容誤差(デフォルトは1e-10)
:param max_iterations: 最大反復回数(デフォルトは1000)
:return: 平方根の近似値
"""
if n < 0:
raise ValueError("負の数の平方根は実数ではありません。")
if n == 0:
return 0
# 初期値としてn/2を使用
x = n / 2.0
for _ in range(max_iterations):
# ニュートン法の更新式
next_x = 0.5 * (x + n / x)
# 収束判定
if abs(next_x - x) < tolerance:
return next_x
x = next_x
# 最大反復回数に達した場合
raise RuntimeError("最大反復回数に達しました。収束しませんでした。")
# 使用例
if __name__ == "__main__":
number = 25
result = sqrt_newton(number)
print(f"{number}の平方根は約{result}です。")
この関数は、与えられた数値nの平方根をニュートン法を用いて近似計算します。
初期値としてn/2を使用し、反復回数がmax_iterationsに達するか、許容誤差tolerance以下の収束が確認されるまで反復します。
収束しない場合、RuntimeErrorを発生させます。負の数の平方根を求めることはできませんが、0の平方根は0を返します。デモ環境はCPU上で動作しているので、実行に時間がかかるかと思いましたが、わずか3秒ほどで出力が返ってきました。
中身をみてみると、ニュートン法の公式に従って、反復計算を行う関数がきちんと出力されました。ゼロや負の数の入力へのチェックも含まれており、コメントも適切につけられていて非常に読みやすいコードになっていますね。
数学的知識・推論の検証
続いて、Rnj-1の数学に関する知識をテストしてみます。
モデル名の由来でもある数学者ラマヌジャンにちなんで、「1729という数字が数学的に特別な理由は何?」という質問を投げかけてみましょう。これはラマヌジャンの有名なエピソード(ハーディ・ラマヌジャン数)に関する問いです。
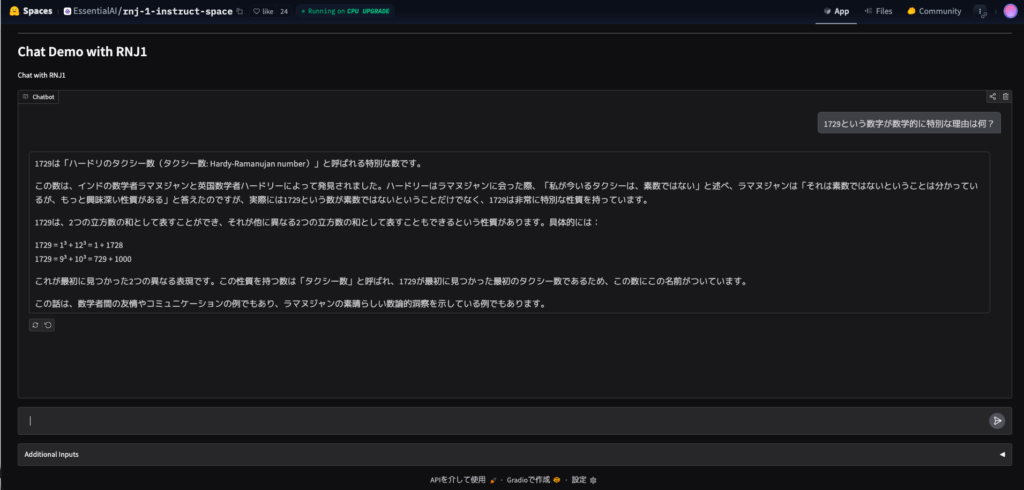
1729は「ハードリのタクシー数(タクシー数: Hardy-Ramanujan number)」と呼ばれる特別な数です。
この数は、インドの数学者ラマヌジャンと英国数学者ハードリーによって発見されました。ハードリーはラマヌジャンに会った際、「私が今いるタクシーは、素数ではない」と述べ、ラマヌジャンは「それは素数ではないということは分かっているが、もっと興味深い性質がある」と答えたのですが、実際には1729という数が素数ではないということだけでなく、1729は非常に特別な性質を持っています。
1729は、2つの立方数の和として表すことができ、それが他に異なる2つの立方数の和として表すこともできるという性質があります。具体的には:
1729 = 1³ + 12³ = 1 + 1728
1729 = 9³ + 10³ = 729 + 1000
これが最初に見つかった2つの異なる表現です。この性質を持つ数は「タクシー数」と呼ばれ、1729が最初に見つかった最初のタクシー数であるため、この数にこの名前がついています。
この話は、数学者間の友情やコミュニケーションの例でもあり、ラマヌジャンの素晴らしい数論的洞察を示している例でもあります。こちらもわずか3秒ほどで出力が完了しました。
結果をみてみると、1729が「1^3+12^3」と「9^3+10^3」という2通りの立方数の組み合わせで表せること、そしてそれが由来となったハーディとラマヌジャンの逸話まで含めて説明してくれていますね。
今回は、簡易的にデモページでの実行に留めましたが、このレベルの推論をローカル実行することもできるのは、改めてありがたいことですよね。
気になる方はぜひ、他のタスクでの推論やローカル実行も試してみてください。
まとめ
Essential AIのRnj-1は、80億パラメータを持つオープンソースの言語モデルです。
Transformerの生みの親の1人が率いるチームが開発しただけあって、その完成度と野心的な部分は非常に高いものを感じます。
80億パラメータでありながら、コード生成や数理推論といった難易度の高い分野で、既存の同規模モデルを上回る性能を持っています。
ぜひみなさんも一度、ご自身の環境で試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


