
スマホでも動く!Stable Audio Open Smallの使い方と特徴を徹底解説
- 生成速度が高速なText to Audioモデル
- オープンソース
- スマホでも音声生成が可能
2025年5月15日、Stability AIから新たなモデルが登場しました!
今回発表されたモデルはText to Audioモデルの「Stable Audio Open Small」。
モデルサイズは約341Mパラメータと軽量で、44.1kHzステレオ音声を最大11秒まで生成可能であり、Arm CPUのみで動作もするため、スマートフォン上でも音声の生成が可能です。
本記事では、Stable Audio Open Smallの概要から使い方について解説します。ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Stable Audio Open Smallの概要
Stable Audio Open SmallはStability AIがArmと共同開発したText to Audioモデル。
このモデルは、従来のStable Audio Openの約1/3となる341Mパラメータで構成されており、特にArm CPU搭載スマートフォンやエッジデバイスでのオンデバイス生成に最適化されています。
生成速度も向上しており、最大11秒の44.1kHzステレオ音声をスマートフォン上で約8秒以内に生成可能という生成速度を実現。これは商用利用可能な他社を含む従来のモデルと比較しても最速クラスのText to Audioモデルです。
Stable Audio Open Smallの技術
Stable Audio Open Smallにはいくつもの技術が使われています。
- オートエンコーダ
- T5ベース テキストエンコーダ
- Diffusion Transformer
- Rectified Flows
- Adversarial Relativistic-Contrastive Post-Training
- Ping-Pong Sampling
- KleidiAI + XNNPACK
- Dynamic Int8量子化
- 学習データ前処理
この中でも特にStable Audio Open Smallにおいて重要な技術がAdversarial Relativistic-Contrastiveです。
Adversarial Relativistic-ContrastiveはStable Audio Open Smallの高速化と品質維持の鍵となる技術。
従来のDistillation手法ではなく、ARCにより、わずか8ステップで高品質な44.1kHzステレオ音声を生成可能とし、さらにプロンプト適合性を高めながら多様性も有しています。これにより、H100 GPUで75ms、モバイルデバイスでも約8秒で生成可能な性能を達成。
Stable Audio Open Smallの性能
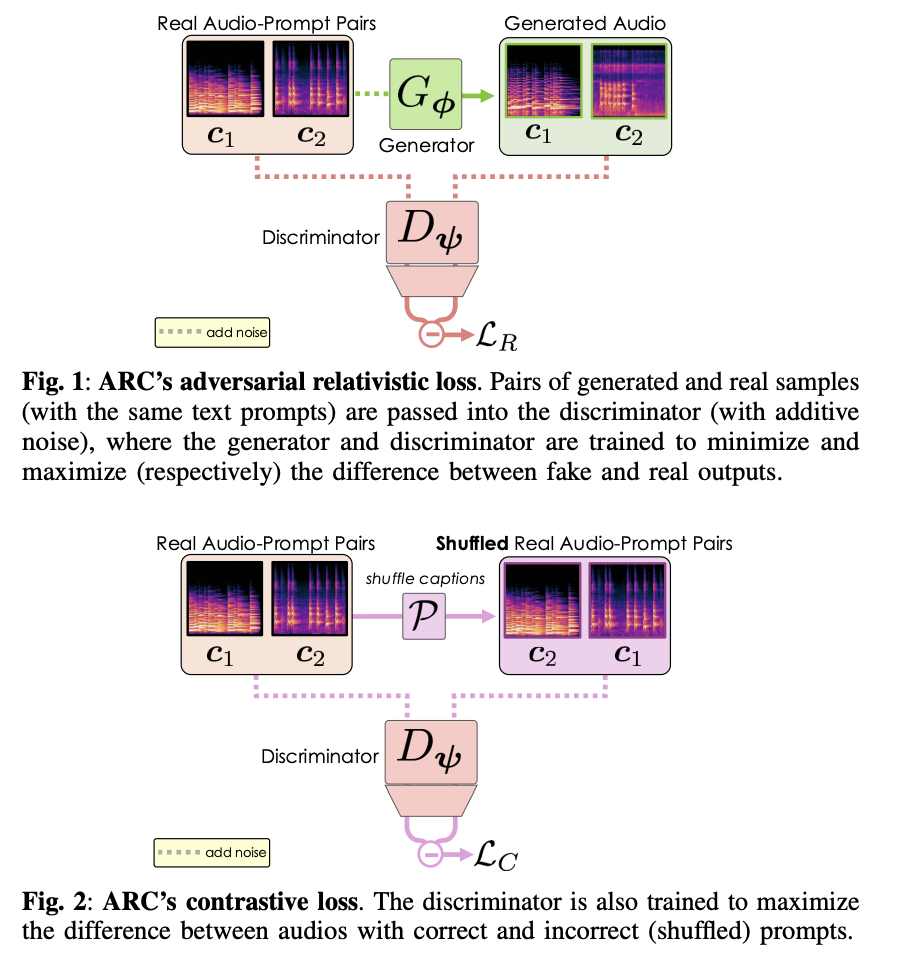
下記はStable Audio Open Smallの各手法の定量・定性評価を網羅的に示す図表です。

ARCは、FDopenl3やCCDS、Diversity、RTFという重要な指標において、他の手法より優れたトレードオフ性能を示しており、Stable Audio Open SmallにおいてARCが性能を決定づける技術であることが示されています。
特に、ARCは多様性維持とリアルタイム性を両立し、Prestoのような品質優先型よりも、創造的用途(音楽や効果音生成)に適しています。


Stable Audio Open Smallのライセンス
Stable Audio Open SmallのライセンスはStability AI Community Licenseです。
Stability AI Community Licenseは年間収入が100万ドル未満の個人や組織は研究用、非商用利用、商用利用が可能です。
もし年間収入が100万ドルを超える場合、商用利用にはStability AIからエンタープライズライセンスの取得が必要なので注意してください。
また、Stability AIのライセンスは3つあります。
- 非商用ライセンス:個人開発者や研究者向けライセンスで無料
- コミュニティライセンス:年間収入が100万ドル未満の個人や組織向けで無料
- エンタープライズライセンス:年間収入が100万ドルを超える企業向けでカスタム価格
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | 不明(明記なし) |
| 私的使用 | ⭕️ |
なお、Whisper超えのOpenAIの次世代音声認識モデルのについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Stable Audio Open Smallの使い方
Stable Audio Open SmallはHugging Faceにあるので、それを使っていきます。
google colaboratoryで実装しようと思いましたが、依存関係が複雑すぎてうまく行かず、ローカル環境で実行をしました。GitHubにGradioで動かすコードも掲載されていたので、そちらを使用。
コードはこちら
conda create -n audio_tools python=3.10
conda activate audio_tools
git clone https://github.com/Stability-AI/stable-audio-tools.git
cd stable-audio-tools
pip install stable-audio-tools
pip install .
import os
os.environ["HF_TOKEN"] = ""
python run_gradio.py --pretrained-name stabilityai/stable-audio-open-1.0インストールなどが終わると、GradioのURLが表示されます。そちらにアクセスすると下記画面になります。
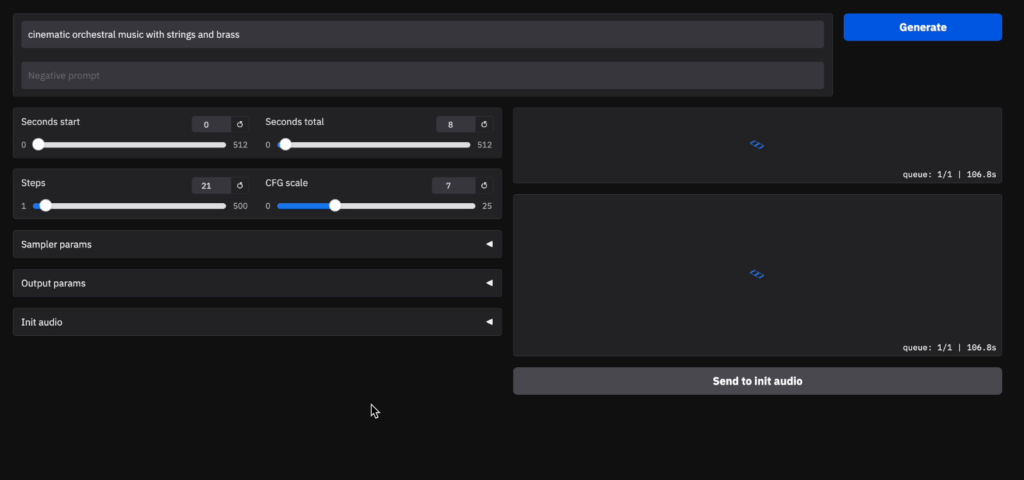
実際に音声を生成してみると、下記画像右下隅に書いてあるように1時間30分程度かかるようです。8秒程度の音声で。
ちょっとこれでは時間がかかりすぎるので、Vast.aiでGPUを使って実装してみます。
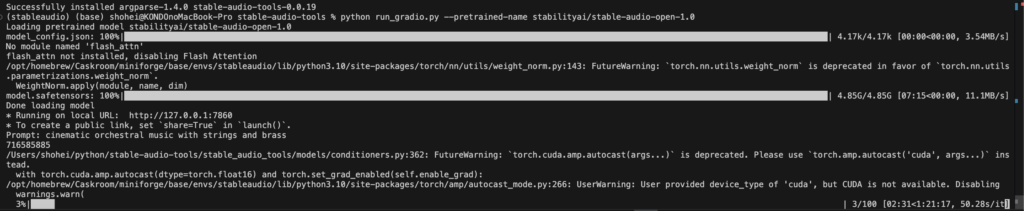
Vast.aiで実行するのも上記とほぼ一緒ですか「!」や「%」がつくので再掲です。
コードはこちら
!git clone https://github.com/Stability-AI/stable-audio-tools.git
%cd stable-audio-tools
!pip install .
import os
os.environ["HF_TOKEN"] = ""
!python run_gradio.py --pretrained-name stabilityai/stable-audio-open-1.0 --shareあとはモデルがダウンロードされればURLが表示されるので、そちらにアクセス。
実際に生成している様子がこちらです。やはりGPUを使っているからでしょうか。生成はめちゃくちゃ早いですね。
音声はこちら。
Stable Audio Open Smallでいろんなプロンプトを検証
Stable Audio Open Smallでできるのは音声の生成なので、いろんなプロンプトでどういった音声が出力されるかを検証してみます。
実際に使用したプロンプトはこちら。
“Gentle rain falling on a tin roof”
「トタン屋根に降る優しい雨の音」
“Busy coffee shop ambience with espresso machine”
「エスプレッソマシンのあるにぎやかなカフェの雰囲気」
“Children playing in a park with birds chirping”
「鳥のさえずりと共に公園で遊ぶ子供たちの声」
“Magical spell casting with sparkles and energy buildup”
「きらめきとエネルギーの蓄積を伴う魔法の詠唱」
それぞれの結果はこちら
Gentle rain falling on a tin roof
Busy coffee shop ambience with espresso machine
Children playing in a park with birds chirping
Magical spell casting with sparkles and energy buildup
4つほど生成しましたが、上記の2つはうまくいった気がします。屋根に当たる雨音が忠実に再現されていましたら、2つ目はコーヒー豆を掬う音、エスプレッソが抽出される音が生成されていたと思います。
一方で3つ目は鳥の鳴き声は聞こえてきましたが、子供の声は聞こえず、4つ目に関してはちょっとよくわからないという結果でした。
ただプロンプトを適切に入れればほしい音が生成できるということがよくわかりました。
また、公式では最大11秒の音声生成と記載されていましたが20秒の音声を作ることができました。もしかしたら生成した音声は44.1kHzステレオ音声ではないのかもしれません。
なお、文脈を理解するSesame AIのCSM-1Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではStable Audio Open Smallの概要から使い方について解説をしました。M2 Macのローカル環境でも実行することはできましたが、非常に時間がかかってしまったので、やはりGPUを使えると良いですね。
google colaboratoryでの実装はなかなか難しそうなので、Vast.aiなどを使って、ぜひ皆さんもStable Audio Open Smallで音声を生成してみてください。


最後に
いかがだったでしょうか
音声生成AIは、アプリ内サウンド演出や音声ガイド、UX強化コンテンツの自動生成などに活用され、プロダクトの没入感やブランド体験を向上させる鍵となります。スマホでも動作する軽量モデルなら、導入障壁も最小限です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


