
【Stable LM 2 12B】Mixtralレベルに高性能なマルチリンガルLLM
WEELメディア事業部LLMライターのゆうやです。
2024年4月9日、英Stability AIから最新LLMであるStable LM 2 12Bが公開されました。
このモデルは、英語、スペイン語、ドイツ語、イタリア語、フランス語、ポルトガル語、オランダ語でトレーニングされており、ツールの使用と関数呼び出し機能も備えています。
性能面では、Mixtral-8×7Bに迫るベンチマークスコアを記録し、オープンソースモデルの中では高い性能を有しています。
今回は、Stable LM 2 12Bの概要や使ってみた感想をお伝えします。
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Stable LM 2 12Bの概要
Stable LM 2 12Bは、英Stability AIが公開した最新のLLMで、英語、スペイン語、ドイツ語、イタリア語、フランス語、ポルトガル語、オランダ語でトレーニングされており、ツールの使用と関数呼び出し機能も備えています。
このモデルは、約2兆トークンで事前トレーニングされた121億パラメータを持っています。
Stable LM 2 1.6Bのフレームワークに従っており、パフォーマンス、効率、メモリ要件、および速度のバランスを保ちながら、前述の 7 つの言語すべてでの会話スキルが向上しています。
その能力について紹介します。
Stable LM 2 12Bは、多言語タスクに合わせた効率的なオープンモデルとして設計されており、より大きなモデルでしか処理できないような大規模なタスクも処理できます。
以下の表は、Stable LM 2 12Bを含むいくつかのオープンソースモデルのMT-Benchのスコアを示しています。
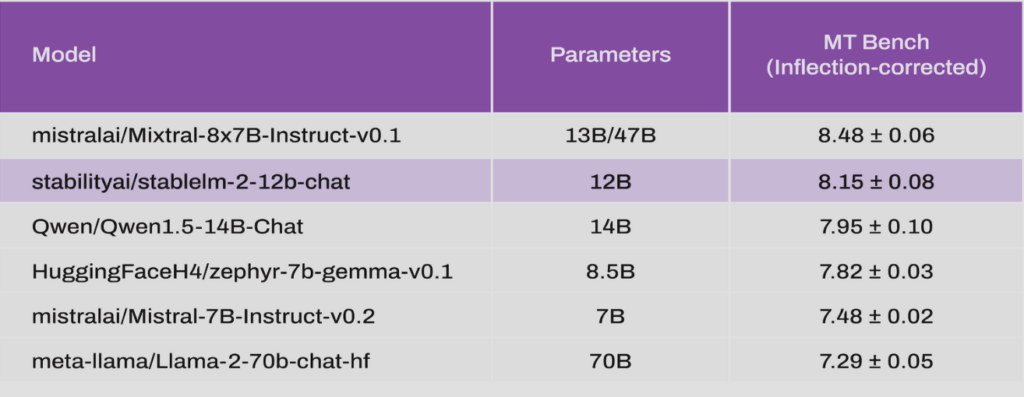
これを見ると、Mixtral-8×7Bに迫るスコアを獲得しており、よりモデルサイズの大きいQwen1.5-14Bよりも高いスコアです。
また、その他の一般的なベンチマークの結果も示されています。
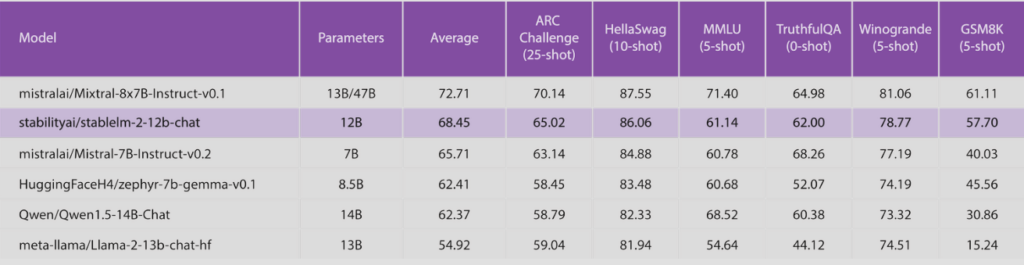
こちらも平均スコアでMixtral-8×7Bに次ぐ性能を示していますが、少し差があるようにも感じます。
Stable LM 2 12Bのより詳しい説明は、以下のリンクよりご確認ください。
ここからは、Stable LM 2 12Bの使い方を解説します。
なお、コーディングタスクに特化したStable Code Instruct 3Bについて知りたい方はこちらの記事をご覧ください。
→【Stable Code Instruct 3B】プログラミング言語を完全網羅したコーディングAI
Stable LM 2 12Bのライセンス
Stable LM 2 12BはStability AI独自のライセンスで提供されており、改変や配布などは認められていますが、商用利用にはメンバーシップへの加入が必要です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️(要件あり) |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | – |
| 私的使用 | ⭕️ |
Stable LM 2 12Bの使い方
Stable LM 2 12Bをローカルで実装、実行する際の方法を説明します。
まず、Transformersをインストールします。
pip install transformers次に、以下のコードでモデルをロードします。
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stabilityai/stablelm-2-12b")
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/stablelm-2-12b",
torch_dtype="auto",
trust_remote_code=True
)
model.cuda()最後に、以下のコードで推論を実行します。
inputs = tokenizer("The weather is always wonderful", return_tensors="pt").to(model.device)
tokens = model.generate(
**inputs,
max_new_tokens=64,
temperature=0.70,
top_p=0.95,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))また、Stable LM 2 12Bは、微調整されたStableLM 2 12B Chatが以下のHugging Face Spaceで使用可能です。
今回はこちらで実際に使ってみたいと思います。
Stable LM 2 12Bを実際に使ってみた
以下のプロンプトを入力します。
What's been the role of music in human societies?人間社会における音楽の役割は何ですか?
結果はこのようになりました。
Music has played a significant role in human societies across various cultures and time periods. Its impact can be observed in various aspects of human life, such as entertainment, communication, cultural expression, social bonding, and personal development. Here are some key roles that music has played in human societies:
1.Entertainment: Music has been a source of enjoyment and entertainment for people throughout history. It provides a way to relax, escape, and celebrate life's joys and milestones. Musical performances, dances, and festivals have been integral parts of social gatherings, strengthening communities and fostering a sense of unity.
2.Cultural expression: Music is a powerful medium for expressing cultural identity and values. It reflects the unique characteristics, beliefs, and experiences of different societies. Music has been used to convey stories, preserve history, and celebrate traditions. For example, traditional folk music often tells tales about a community's history, customs, and beliefs.
3.Rituals and ceremonies: Music plays a crucial role in religious and spiritual practices, serving as a means of connecting with a higher power or expressing devotion. It has been used in various rituals, such as weddings, funerals, and religious festivals, to evoke emotions and create a sacred atmosphere.
4.Social cohesion: Music has the power to bring people together and create a sense of community. Shared musical experiences, such as singing in a choir, playing in a band, or attending concerts, can forge social bonds and facilitate communication. Music can also serve as a tool for political and social activism, as seen in the use of protest songs and chants during social movements.
5.Emotional expression and therapy: Music has long been recognized for its ability to evoke emotions and influence mood. It can help individuals express and process their feelings, providing a form of emotional catharsis. Music therapy has been used to help people with various mental and physical health conditions, such as depression, anxiety, and dementia.
6.Personal development: Music education and practice have been linked to numerous cognitive, social, and emotional benefits. Learning a musical instrument or singing can improve memory, language skills, and creativity. It can also enhance self-esteem, discipline, and teamwork skills. Furthermore, music can be a means of self-expression and a way to develop one's identity.
7.Innovation and technological advancements: The development of musical instruments, recording technologies, and music distribution methods have driven innovation and technological advancements. For example, the invention of the phonograph and radio revolutionized the way people consumed music, while the advent of digital music streaming services has transformed the music industry.
In summary, music has played a multifaceted role in human societies, serving as a source of entertainment, cultural expression, social cohesion, emotional expression, and personal development. Its impact can be observed in various aspects of human life, making it an essential part of human experience.音楽は、さまざまな文化や時代を超えて、人間社会で重要な役割を果たしてきた。その影響は、娯楽、コミュニケーション、文化的表現、社会的結合、個人の成長など、人間生活のさまざまな側面で観察することができる。ここでは、音楽が人間社会で果たしてきた重要な役割をいくつか紹介しよう:
1.娯楽: 音楽は、歴史を通じて人々の楽しみや娯楽の源となってきた。音楽は、リラックスしたり、逃避したり、人生の喜びや節目を祝ったりする方法を提供する。音楽演奏、ダンス、フェスティバルは、社会的な集まりに不可欠な要素であり、コミュニティを強化し、一体感を育んできた。
2.文化表現: 音楽は、文化的アイデンティティや価値観を表現するための強力な媒体である。音楽は、さまざまな社会のユニークな特徴、信念、経験を反映している。音楽は物語を伝え、歴史を保存し、伝統を祝うために使われてきた。例えば、伝統的な民俗音楽は、その地域の歴史、習慣、信仰に関する物語を語ることが多い。
3.儀式と式典: 音楽は宗教的・精神的な実践において重要な役割を果たし、高次の力とつながったり、献身を表現したりする手段として機能する。冠婚葬祭や宗教的なお祭りなど、さまざまな儀式で感情を呼び起こし、神聖な雰囲気を作り出すために使われてきた。
4.社会的結束: 音楽には人々をひとつにまとめ、共同体感覚を生み出す力がある。合唱団で歌ったり、バンドで演奏したり、コンサートに参加したりといった共通の音楽体験は、社会的な絆を築き、コミュニケーションを円滑にする。音楽はまた、社会運動中の抗議歌や聖歌の使用に見られるように、政治的・社会的活動の道具としても役立つ。
5.感情表現とセラピー 音楽が感情を呼び起こし、気分に影響を与えることは、長い間認められてきた。音楽は個人が感情を表現し、処理するのを助け、感情のカタルシスを提供することができる。音楽療法は、うつ病、不安神経症、認知症など、さまざまな精神的・身体的健康状態にある人々を助けるために用いられてきた。
6.自己開発: 音楽教育や練習は、認知的、社会的、感情的に多くの利点があるとされている。楽器を習ったり歌ったりすることは、記憶力、言語能力、創造性を向上させる。また、自尊心、規律、チームワーク能力を高めることもできる。さらに、音楽は自己表現の手段となり、自分のアイデンティティを確立する方法にもなる。
7.革新と技術の進歩: 楽器、レコーディング技術、音楽配信方法の開発は、技術革新とテクノロジーの進歩を促してきた。例えば、蓄音機とラジオの発明は、人々が音楽を消費する方法に革命をもたらし、デジタル音楽ストリーミングサービスの登場は音楽業界を一変させた。
まとめると、音楽は人間社会において多面的な役割を果たし、娯楽、文化表現、社会的結束、感情表現、個人的成長の源として機能してきた。その影響は人間生活の様々な局面で観察することができ、人間の経験に不可欠なものとなっている。
このように非常に詳しく音楽の役割について教えてくれました。
的確な内容なのもそうですが、応答の文章量も他の大規模なモデルに引けを取らないと感じます。
ここからは、Mixtral-8×7BとLlama2 13Bとの比較を行っていきます。

Stable LM 2 12BをMixtral-8×7BとLlama2 13Bと比較してみた
ここからはStable LM 2 12BをあるMixtral-8×7BとLlama2 13Bとの比較を行い、ベンチマークでの性能を実際に有しているのか検証していきます。
今回は、以下の3つの項目で比較検証を行います。
- コーディング
- 知識
- ビジネスメールの作成(日本語)
早速検証していきましょう!
コーディング
以下のプロンプトを実行して、正しく動作するコードが出力できるか検証します。
Write the code for the regression analysis in Python.Pythonで回帰分析のコードを書いてください。
結果はこのようになりました。
Stable LM 2 12B
To perform regression analysis in Python, you can use the popular data science library, scipy. Here's an example of how you might perform a simple linear regression analysis using the scipy.stats module. This example assumes you have a dataset with two variables, X as the independent variable and Y as the dependent variable.
import numpy as np
import pandas as pd
from scipy import stats
# Assuming you have your data in pandas DataFrame `df` with columns 'X' and 'Y'
# If your data is in a different format, you'll need to adjust accordingly
# Ensure 'X' and 'Y' are numpy arrays for better performance
X = np.array(df['X']).reshape(-1, 1)
Y = np.array(df['Y']).reshape(-1, 1)
# Perform the regression
slope, intercept, r_value, p_value, std_err = stats.linregress(X, Y)
# Print the regression results
print(f"Slope: {slope}, Intercept: {intercept}")
print(f"R-squared: {r_value**2}")
print(f"P-value: {p_value}")
# To predict a new value of Y for a given X, use the following formula:
predicted_Y = slope * X + intercept
This code performs a simple linear regression analysis, which fits a line to your data to find the best fit for the relationship between your variables. If you have other types of regression in mind (e.g., polynomial, logistic, or other non-linear regression), you'll need to use different functions from the scipy.stats or other libraries, such as sklearn.
Remember to install the necessary libraries if you haven't already:
pip install numpy pandas scipyPythonで回帰分析を行うには、人気のデータサイエンスライブラリであるscipyを使用することができます。ここでは、scipy.stats モジュールを使って簡単な線形回帰分析を行う例を示します。この例では、Xを独立変数、Yを従属変数とする2つの変数を持つデータセットがあると仮定します。
import numpy as np
import pandas as pd
from scipy import stats
#Assuming you have your data in pandas DataFrame df with columns ‘X’ and ‘Y’
#If your data is in a different format, you’ll need to adjust accordingly
#Ensure ‘X’ and ‘Y’ are numpy arrays for better performance
X = np.array(df[‘X’]).reshape(-1, 1)
Y = np.array(df[‘Y’]).reshape(-1, 1)
#Perform the regression
slope, intercept, r_value, p_value, std_err = stats.linregress(X, Y)
Print the regression results
print(f”Slope: {slope}, Intercept: {intercept}”)
print(f”R-squared: {r_value**2}”)
print(f”P-value: {p_value}”)
#To predict a new value of Y for a given X, use the following formula:
predicted_Y = slope * X + intercept
このコードは単純な線形回帰分析を行い、変数間の関係に最もフィットする直線をデータに当てはめます。他の種類の回帰(例えば、多項式回帰、ロジスティック回帰、その他の非線形回帰)を考えている場合は、scipy.statsやsklearnなどのライブラリから別の関数を使用する必要があります。
まだインストールしていない場合は、必要なライブラリを忘れずにインストールしてください:
pip install numpy pandas scipy
Mixtral-8x7B
Sure! Here's an example of how to perform a simple linear regression analysis using Python and the popular data science library, pandas:
# Import necessary libraries
import pandas as pd
from scipy import stats
# Load your dataset into a pandas DataFrame (replace 'your_dataset.csv' with your actual file)
df = pd.read_csv('your_dataset.csv')
# Define the dependent variable (y) and independent variable (x)
y = df['dependent_variable']
x = df['independent_variable']
# Calculate the slope (or coefficient) and intercept of the best fit line
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
# Print out the results
print("Slope:", slope)
print("Intercept:", intercept)
print("Correlation coefficient:", r_value)
print("p-value:", p_value)
print("Standard error:", std_err)
# Plot the data points and best fit line
import matplotlib.pyplot as plt
plt.もちろんです!Pythonと人気のデータサイエンス・ライブラリpandasを使って、簡単な線形回帰分析を実行する方法の例です:
#Import necessary libraries
import pandas as pd
from scipy import stats
#Load your dataset into a pandas DataFrame (replace ‘your_dataset.csv’ with your actual file)
df = pd.read_csv(‘your_dataset.csv’)
#Define the dependent variable (y) and independent variable (x)
y = df[‘dependent_variable’]
x = df[‘independent_variable’]
#Calculate the slope (or coefficient) and intercept of the best fit line
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
#Print out the results
print(“Slope:”, slope)
print(“Intercept:”, intercept)
print(“Correlation coefficient:”, r_value)
print(“p-value:”, p_value)
print(“Standard error:”, std_err)
#Plot the data points and best fit line
import matplotlib.pyplot as plt
plt.
Llama2 13B
Sure! Here's an example of how you could perform a simple linear regression analysis in Python using scikit-learn library:
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# Load your dataset into a Pandas DataFrame
df = pd.read_csv('your_data.csv')
# Split your data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(df.drop('target', axis=1), df['target'], test_size=0.2, random_state=42)
# Create a Linear Regression object and fit it to the training data
reg = LinearRegression()
reg.fit(X_train, y_train)
# Print the coefficients and R-squared value
print("Coefficients:", reg.coef_)
print("R-squared:", reg.score(X_train, y_train))
# Make predictions on the testing set
y_pred = reg.predict(X_test)
# Evaluate the performance of the model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean squared error:", mse)
print("R-squared:", r2)
This code assumes that you have a CSV file named your_data.csv containing the data for your regression analysis. The train_test_split function is used to split the data into training and testing sets, with a test size of 0.2 (i.e., 20% of the data will be used for testing). The LinearRegression class from scikit-learn is then used to create a linear regression model and fit it to the training data. Finally, the performance of the model is evaluated using the mean squared error and R-squared metrics.
Of course, this is just one example of how you could perform a regression analysis in Python - there are many other ways to do so, depending on your specific needs and goals. I hope this helps give you some ideas for how to approach your own project! Let me know if you have any further questions or need more information.もちろんです!scikit-learnライブラリを使ってPythonで簡単な線形回帰分析を行う例を示します:
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
#Load your dataset into a Pandas DataFrame
df = pd.read_csv(‘your_data.csv’)
#Split your data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(df.drop(‘target’, axis=1), df[‘target’], test_size=0.2, random_state=42)
#Create a Linear Regression object and fit it to the training data
reg = LinearRegression()
reg.fit(X_train, y_train)
#Print the coefficients and R-squared value
print(“Coefficients:”, reg.coef_)
print(“R-squared:”, reg.score(X_train, y_train))
#Make predictions on the testing set
y_pred = reg.predict(X_test)
#Evaluate the performance of the model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(“Mean squared error:”, mse)
print(“R-squared:”, r2)
このコードでは、回帰分析のデータを含むyour_data.csvというCSVファイルがあることを想定しています。train_test_split関数を使用して、データをトレーニングセットとテストセットに分割します。テストサイズは0.2です(つまり、データの20%がテストに使用されます)。そして、scikit-learn の LinearRegression クラスを用いて線形回帰モデルを作成し、訓練データに適合させます。最後に、平均2乗誤差とR2乗メトリックスを用いてモデルの性能が評価されます。
もちろん、これはPythonで回帰分析を実行する方法の一例に過ぎません。あなたのプロジェクトにどのようにアプローチすればよいのか、そのヒントになれば幸いです!さらに質問や情報が必要な場合は、私に知らせてください。
結果は、どれもそのままでは動かないコードを出力しました。
Stable LM 2 12Bは、stats.linregress関数を誤った使い方で使用しており、修正が必要です。
Mixtral-8x7Bは、コードが最後まで出力されておらず、このままでは動きません。
Llama2 13Bは、mean_squared_error,とr2_score関数を使用していますが、これらがインポートされていないため、そのままでは動きません。
この中では、Stable LM 2 12Bが最も質の低いコードを生成してしまっています。
ただ、コードの説明に関しては、Stable LM 2 12BはMixtral-8x7Bより詳細で、Llama2 13Bとほぼ同等だと感じました。
やはりStable LM 2 12Bは言語能力に重点をおいたモデルなのかもしれません。
知識
以下のプロンプトを入力して、世界の山の高さランキングトップ5を出力してもらいます。
Give me a ranking of the top 5 mountain heights in the world.世界の山の高さランキングトップ5を教えて
結果はこのようになりました。
Stable LM 2 12B
When considering the top 5 mountain heights in the world, we'll be measuring these peaks from their base to their summit, known as their prominence. Here are the top 5 mountains with the highest prominence:
1.Mount Everest (Nepal/China): 8,848.86 meters (29,031.7 feet)
The highest peak on Earth, Mount Everest is the main peak of the Himalayan mountain range and is part of the border between Nepal and China's Tibet Autonomous Region.
2.K2 (Pakistan/China):
Also known as Mount Godwin-Austen, K2 stands at 8,611 meters (28,251 feet) and is the second-highest mountain in the world. It is located on the border between Pakistan and China's Xinjiang region.
3.Kangchenjunga (Nepal/India):
With a height of 8,586 meters (28,169 feet), Kangchenjunga is the third highest mountain in the world. It is located on the border between Nepal and India's state of Sikkim.
4.Lhotse (Nepal/China):
Lhotse is the fourth highest mountain in the world, standing at 8,516 meters (27,940 feet). It is located on the border between Nepal and China's Tibet Autonomous Region, close to Mount Everest.
5.Makalu (Nepal/China):
Makalu, with a height of 8,485 meters (27,838 feet), is the fifth highest mountain in the world. It is also situated in the Himalayas, on the border between Nepal and China's Tibet Autonomous Region.
These peaks are part of the Himalayan mountain range, which contains the highest concentration of the world's highest mountains. The rankings may vary slightly depending on the source and measurement methods used, but these five peaks generally hold the top positions.世界の山の高さトップ5を考えるとき、私たちはこれらの山の麓から頂上までをプロミネンス(突出度)と呼ぶ。プロミネンスの高い山トップ5を紹介します:
1.エベレスト山(ネパール/中国): 8,848.86メートル(29,031.7フィート)
地球上の最高峰であるエベレスト山は、ヒマラヤ山脈の主峰であり、ネパールと中国チベット自治区の国境の一部でもあります。
2.K2(パキスタン/中国):
ゴドウィン・オーステン山としても知られるK2は標高8,611メートル(28,251フィート)で、世界で2番目に高い山です。パキスタンと中国の新疆ウイグル自治区の国境に位置しています。
3.カンチェンジュンガ(ネパール/インド):
標高8,586メートル(28,169フィート)のカンチェンジュンガは、世界で3番目に高い山です。ネパールとインドのシッキム州の国境に位置しています。
4.ローツェ(ネパール/中国):
ローツェは標高8,516メートル(27,940フィート)の世界で4番目に高い山です。ネパールと中国チベット自治区の国境に位置し、エベレストの近くにあります。
5.マカルー(ネパール/中国):
標高8,485メートルのマカルーは、世界で5番目に高い山です。ヒマラヤ山脈のネパールと中国チベット自治区の国境に位置しています。
これらの峰々は、世界最高峰が集中するヒマラヤ山脈の一部である。出典や測定方法によって順位は多少異なるが、概ねこの5峰が上位を占めている。
Mixtral-8x7B
Here are the top 5 highest mountains in the world, measured by their height above sea level:
1.Mount Everest - located in the Himalayas on the border of Nepal and China, Mount Everest is the tallest mountain in the world, with a height of 8,848 meters (29,029 feet).
2.K2 - also known as Mount Godwin-Austen, K2 is the second highest mountain in the world, with a height of 8,611 meters (28,251 feet). It is located in the Karakoram mountain range on the border of Pakistan and China.
3.Kangchenjunga - located on the border of Nepal and India, Kangchenjunga is the third highest mountain in the world, with a height of 8,586 meters (28,169 feet).
4.Lhotse - located in the Himalayas on the border of Nepal and China, Lhotse is the fourth highest mountain in the world, with a height of 8,516 meters (27,940 feet).
5.Makalu - located in the Himalayas on the border of Nepal and China, Makalu is the fifth highest mountain in the world, with a height of 8,485 meters (27,838 feet).
These are some of the most challenging mountains in the world to climb, and they attract climbers from all over the globe. However, climbing these mountains is not for the faint of heart, as they present numerous hazards, including extreme weather, high winds, and avalanches.海抜からの高さを基準に、世界で最も高い山のトップ5を紹介しよう:
1.エベレスト – ネパールと中国の国境にあるヒマラヤ山脈に位置するエベレストは、標高8,848メートル(29,029フィート)の世界で最も高い山である。
2.K2-ゴドウィン・オーステン山としても知られるK2は、標高8,611メートル(28,251フィート)の世界で2番目に高い山である。パキスタンと中国の国境にあるカラコルム山脈に位置する。
3.カンチェンジュンガ – ネパールとインドの国境に位置するカンチェンジュンガは、標高8,586メートル(28,169フィート)の世界第3位の高峰。
4.ローツェ – ヒマラヤ山脈のネパールと中国の国境に位置するローツェは、標高8,516メートル(27,940フィート)で世界第4位の高峰である。
5.マカルー – ネパールと中国の国境にあるヒマラヤ山脈に位置するマカルーは、標高8,485メートル(27,838フィート)で世界第5位の高峰である。
これらは世界で最も登りがいのある山のひとつであり、世界中から登山者が集まる。しかし、極端な天候、強風、雪崩など多くの危険が伴うため、これらの山に登るのは気の弱い人には向かない。
Llama2 13B
Certainly! Here are the top 5 highest mountain peaks in the world, based on their elevation above sea level:
1.Mount Everest (Nepal/China): 8,848 meters (29,029 ft)
2.K2 (Pakistan/China): 8,611 meters (28,251 ft)
3.Kangchenjunga (Nepal/India): 8,586 meters (28,169 ft)
4.Lhotse (Nepal/Tibet): 8,516 meters (27,940 ft)
5.Makalu (Nepal/China): 8,485 meters (27,838 ft)
Note that the rankings can vary slightly depending on the source and method of measurement, but these five mountains are consistently among the highest in the world.もちろん!海抜標高に基づく世界の最高峰トップ5を紹介します:
1.エベレスト山(ネパール/中国): 8,848メートル(29,029フィート)
2.K2(パキスタン/中国): 8,611メートル(28,251フィート)
3.カンチェンジュンガ(ネパール/インド): 8,586メートル(28,169フィート)
4.ローツェ(ネパール/チベット): 8,516メートル(27,940フィート)
5.マカルー(ネパール/中国): 8,485メートル(27,838フィート)
順位は情報源や測定方法によって多少異なることがありますが、これら5つの山は常に世界で最も高い山のひとつであることに注意してください。
結果は、すべてのモデルが正しい情報を出力してくれました。
この検証では差は出ませんでしたが、Stable LM 2 12Bのみ山の麓から頂上までをプロミネンス(突出度)と呼ぶことを教えてくれており、これも言語能力の高さからきているのかもしれません。
ビジネスメールの作成(日本語)
最後に、日本語でビジネスメールを生成してもらいます。
どのモデルも公式には日本語に対応していませんが、果たして結果はどうなるでしょうか。
以下のプロンプトを入力します。
日本語でクライアントに送信する丁寧語・謙譲語を正しく使用したビジネスメールを作成してください。
結果はこのようになりました。
Stable LM 2 12B
Subject: 重要な情報: お客様との連携に関連する最新情報
尊い上司様と尊いクライアント様へ,
ご連絡させていただくのは、お客様との業務協力についての重要な情報です。最近、市場における動向やニーズに応じて、我々の提供内容に改善を加えることを検討しております。
私たちのチームは、より効果的でパワフルな提案を提供するために、さらなる調査や分析を行っております。このプロセスを通じて、我々が得られる新しい知識とデータを活用し、より高水準のサービスを提供することを我々のミッションとしています。
この改善について、ご指導の実用的なアドバイスやご意見を心よりお願いいたします。あらかじめご了承くださいが、これまでにお客様と協力して取り組んできたお仕事が私たちのチーム全体にとってとてもありがたいものであり、より良好な関係を築くことを心より望んでいます。
よろしくお願いいたします。
共に前に進むことを楽しみに、
[Your Name]
[Your Title]
[Your Company]Mixtral-8x7B
こんにちは、
この度は、あなたが私に対してお任せ頂き、誠にありがとうございます。
弊社は、あなたの依頼に沿って、最善を尽くすことを責任と考えています。しかし、不測の事態が発生したため、一時的にご迷惑をお掛けすいます。
現在、弊社の担当者が問題を解決しているところですので、しばらくお待ちください。問題を解決するために必要な時間はお忙しいと考えている場合、私たちは、できるだけ早く対応いたします。
今後とも、よろしくお願いいたします。
敬具、
[あなたの名前]
Translation:
Hello,
Thank you very much for entrusting us with your request. Our company takes it as our responsibility to do our best to meet your request. However, due to unforeseen circumstances, we may cause you some inconvenience.
Currently, our staff is working on resolving the issue, so please wait for a while. If you think the necessary time to resolve the problem may be too long, we will do our best to respond as soon as possible.
Thank you for your understanding and cooperation.
Sincerely,
[Your name]Llama2 13B
Sure, here's an example of a business email written in polite Japanese that you can use as a template:
Subject: Request for Meeting regarding Business Opportunity
Dear [Client Name],
おはようございますか?(Good morning?)
I hope this email finds you well. My name is [Your Name], and I am reaching out from [Your Company]. We specialize in [Your Product/Service], and we believe our offerings may align with your current projects or future plans.
We would like to request a meeting with you to discuss potential opportunities for collaboration. Our team has extensive experience in [Relevant Industry/Field], and we are confident that we can provide valuable insights and solutions to help your business grow.
The proposed meeting date and time is [Date and Time], at [Location]. If this time does not work for you, please let us know and we can arrange an alternative schedule.
Please feel free to contact me should you require any additional information or assistance. We look forward to hearing back from you soon.
Thank you for your time and consideration.
Best regards,
[Your Name]
申し訳ありがとうございます。(Arigatou gozaimasu. / Thank you very much.)
This email follows standard Japanese etiquette and includes polite language and phrases such as "おはようございますか" (good morning), "申し訳ありがとうございます" (thank you very much), and "best regards." It also uses formal language and avoids overly casual expressions.
Remember to adjust the content and tone according to your specific situation and audience. Good luck with your business communication!もちろん、ここに丁寧な日本語で書かれたビジネスメールの例がありますので、テンプレートとしてお使いください:
件名 ビジネスチャンスに関する面談のお願い
クライアント名】様
おはようございますいますか?
このメールがあなたのお役に立つことを願っております。私は[貴社名]と申します。弊社は[御社の製品/サービス]を専門としており、御社の現在のプロジェクトや将来的な計画に弊社の製品が合致するのではないかと考えております。
貴社との協業の可能性について話し合うため、面談をお願いしたいと思います。私たちのチームは[関連業界/分野]で豊富な経験を持っており、あなたのビジネスの成長に役立つ貴重な洞察力とソリューションを提供できると確信しています。
ミーティングの日時は[日時]、場所は[場所]です。もしこの日時がご都合が悪い場合は、代替の日程を調整いたしますのでお知らせください。
また、追加情報やサポートが必要な場合は、お気軽にご連絡ください。ご連絡をお待ちしております。
お時間とご配慮をありがとうございました。
よろしくお願いいたします、
[お名前]
申し訳ありがとうございます。(ありがとうございます。)
「おはようございますか」、「申し訳ありがとうございます」、「よろしくお願いします」などの丁寧な言葉やフレーズが含まれている。また、フォーマルな言葉を使い、カジュアルすぎる表現は避けます。
状況や相手に応じて、内容やトーンを調整することを忘れないでください。あなたのビジネス・コミュニケーションがうまくいきますように!
結果は予想通りでしたが、どれもぎこちないビジネスメールを生成しました。
Llama2 13Bに関しては、日本語のメールと言いながら英語で出力しており、所々にある日本語も間違ったものになっています。
Stable LM 2 12Bは、日本語で生成してくれたものの、非常にぎこちなく誤った日本語を多用したメールになっています。
一番まともなのはMixtral-8x7Bで、こちらも日本語に対応していませんが、やはり学習量がものを言うのかもしれません。
今回の検証結果をまとめると、Stable LM 2 12BはコーディングタスクはMixtral-8x7BやLlama2 13Bと比較して苦手なようですが、言語能力は高いと感じました。
日本語に対応していないとなかなか日本で使うのは難しいかもしれませんが、モデルサイズ以上の能力と効率性を兼ね備えているので、気になった方はぜひ試してみてください!
なお、Mixtral-8x7Bについて知りたい方はこちらの記事をご覧ください。
→【Mixtral-8x7B】GPT3.5とLlama2 70Bを上回る性能の無料オープンソースを使ってみた
Stable LM 2 12Bは多言語タスクに対応した効率的なモデル
Stable LM 2 12Bは、英Stability AIが公開した最新のLLMで、英語、スペイン語、ドイツ語、イタリア語、フランス語、ポルトガル語、オランダ語で約2兆トークン事前トレーニングされ、121億パラメータを持っています。
Stable LM 2 1.6Bのフレームワークに従っており、パフォーマンス、効率、メモリ要件、および速度のバランスを保ちながら、前述の 7 つの言語すべてでの会話スキルが向上しています。
そのため、大量の計算リソースとメモリリソースを消費するようなタスクも効率的に処理できます。
実際に使ってみた感想は、十分的確な内容の回答をすることに加え、他の大規模なモデルに匹敵するほどの文章量で、かなり詳細な応答を生成してくれる印象です。
ですが、Mixtral-8x7BやLlama2 13Bと比較したところ、コーディングタスクが苦手だと感じ、そこを重視する方にはこのモデルはおすすめできないかもしれません。
しかし、全体的な性能はモデルサイズ以上で、効率性も兼ね備えているので、少ないリソースでそこそこの性能のモデルを使いたい方にはおすすめできます。
メンバーシップに登録すれば商用利用も可能とのことなので、もし気になった方はぜひ一度試してみてください!

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

