
SubQとは?世界初の完全サブクアドラティックLLMの仕組み・特徴・性能を徹底解説
- SubQは世界初の完全サブクアドラティックLLM。コンテキスト長が増えても計算コストが線形にしかスケールしない新しいアーキテクチャを採用している
- 独自アテンション機構「SSA」により、1Mトークンで従来比52.2倍のプリフィル高速化を実現しながらフロンティアモデル級の精度を維持
- コードベース・法務文書・研究論文など百万トークン規模の長文脈推論が実用的なコストで扱えるようになる
2026年5月、Subquadratic社から世界初の完全サブクアドラティックLLMが発表されました。
今回登場した「SubQ」は、これまでのトランスフォーマー系LLMが抱えてきた根本的な制約であるコンテキスト長が増えると計算コストが二乗で膨らむという問題を初めてアーキテクチャレベルで解決したモデルです。
コード・法務文書・研究コーパスなど、百万トークン規模の長文脈を、フロンティアモデル級の精度と大幅に低いコストで処理できます。
これまでの大規模言語モデルには、「長文脈処理は計算コストが急激に膨らむ」「RAGやチャンキングなどの回避策が不可欠」「ウィンドウを超えた情報は事実上失われる」といった制約がありました。
一方でSubQは、SSA(Subquadratic Sparse Attention)と呼ばれる独自のアテンション機構により、計算量をO(n²)からO(n)の線形スケーリングへと変えました。1Mトークンのコンテキストで従来比62.5倍のFLOP削減と52.2倍のプリフィル高速化を達成。
しかし、新しいアーキテクチャのモデルが登場するたびに、「従来のLLMと何が本質的に違うのか」「精度を落とさずに本当に高速化できるのか」「どのような業務に活用できるのか」といった疑問を感じる方も多いのではないでしょうか。
そこで本記事では、SubQの概要や仕組み、特徴を整理しながら、ベンチマーク結果と具体的な活用シーンについて詳しく解説します。
最後までお読みいただくことで、SubQがどのような思想で設計され、どのような場面でその価値が最大化するのかが理解できるはずです。
\生成AIを活用して業務プロセスを自動化/
SubQとは

SubQは、2026年5月にSubquadratic社が発表した世界初の完全サブクアドラティックLLMです。
「Efficiency is Intelligence(効率こそが知性)」をスローガンに掲げ、コンテキスト長に対して計算コストが線形にしかスケールしないアーキテクチャを採用。従来のトランスフォーマーが持つ二次スケーリング問題をアーキテクチャレベルで解決した初のモデルです。
最初にリリースされたモデルはSubQ 1M-Previewで、コンテキストウィンドウは1Mトークン。研究段階では12Mトークンでの動作も確認されており、他のフロンティアモデルが1Mトークン付近で性能劣化を起こすのに対し、SubQはその先まで安定して動作します。
開発したSubquadratic社は、Meta・Google・Oxford・Cambridge・ByteDance・Adobe・Microsoftに所属するPh.D.研究者を含む11人のリサーチャーで構成。
シード資金として2,900万ドル(約43億円)を調達しており、AnthropicやOpenAI・Stripe・Brexの初期投資家とも関係を持つ投資家陣が支援しています。
CEOのJustin Dangel氏はヘルステック・保険テック・消費財にわたる5社の創業・CEO経験を持ちます。CTOのAlex Whedon氏はMeta出身で、TribeAIにてGenAI責任者として40社以上のエンタープライズAI実装を主導しています。
| 比較項目 | SubQ(SSAアーキテクチャ) | 従来のトランスフォーマー系LLM |
|---|---|---|
| アテンション計算量 | O(n)—線形スケーリング | O(n²)—二次スケーリング |
| 1Mトークン時のFLOP削減 | 62.5×削減 | 基準(削減なし) |
| 1Mトークン時のプリフィル速度 | 52.2倍高速 | 基準 |
| コンテキスト長(実用) | 1M〜12M(研究段階) | 128K〜1M(多くは性能劣化あり) |
| 長文脈での情報取得方式 | コンテンツ依存の選択的アテンション | 全ペア比較(密なアテンション) |
100万トークン対応の次世代オープンソースAIであるDeepSeek-V4について、詳しく知りたい方は以下の記事も参考にしてみてください。

SubQの仕組み
SubQの中核にあるのは、SSA(Subquadratic Sparse Attention)と呼ばれるアテンション機構です。「コンテンツ依存の選択」という考え方が、従来のアテンションと根本的に異なります。
従来の密なアテンション(Dense Attention)では、すべてのトークンが他のすべてのトークンと比較を行います。全ペアの計算が必要となり、コストはシーケンス長の二乗で増加。100万トークンのコンテキストでは、その計算量は膨大です。
SSAはその前提を取り除きます。各クエリに対して「実際に意味のある情報を持つ位置」だけを選択し、そこにのみアテンションを計算。残りの大部分をスキップすることで線形スケーリングを実現しています。
SubQがトークンを処理する基本的な流れは以下のとおりです。
- 入力シーケンス全体から、各クエリトークンが「どこを参照すべきか」をコンテンツの意味に基づいて判断する
- 信号を実際に持つ位置のみを選択し、それ以外の位置はスキップする
- 選択された位置に対してのみアテンション計算を実行し、次の表現を生成する
- 選択された位置の数に比例したコストで処理が完了する(シーケンス全長に依存しない)
これにより、SSAは以下の3つの性質を同時に実現しています。
| 項目 | 内容 |
|---|---|
| 線形スケーリング | アテンションコストはシーケンス全長ではなく選択位置数に比例するため、長文脈が経済的に扱えます |
| コンテンツ依存ルーティング | どこを参照するかを位置ではなく意味(コンテンツ)で決定。情報がシーケンスのどこに出現しても適切に取得可能。 |
| 任意位置からのスパース取得 | リカレントモデルや圧縮アプローチとは異なり、シーケンスの遠い過去に登場した特定情報を正確に取得できます |
3段階のトレーニング設計
長文脈のコンテキストウィンドウを持つだけでは不十分で、モデルがそれを確実に「使える」かどうかが重要です。SubQはこの問題に対処するため、3段階のトレーニングを経ています。
| 項目 | 内容 |
|---|---|
| 事前学習(Pre-training) | 基盤となる言語モデリング能力と、SSAの選択機構が使う長文脈表現の獲得 |
| 教師あり微調整(SFT) | 指示への追従・構造化された推論・エンタープライズワークロードに必要なコード生成パターンへの最適化 |
| 強化学習(RL) | 信頼性の高い長文脈取得とローカル推論への過度な依存を避け、コンテキストを積極的に活用、教師ありの例だけでは誘発しにくい行動を対象とした最適化 |
特に強化学習の段階が重要です。
長文脈の失敗は一見もっともらしく見えます。モデルは遠くにある決定的な根拠よりも直近のコンテキストを使いやすいため、そちらに依存しがちです。SSAのRLステージはこうした失敗モードを直接対象としています。
百万トークンの学習を支えるインフラ設計
長文脈のトレーニングは、モデリングの問題であると同時にシステムの問題でもあります。百万トークンのシーケンス長では、メモリ圧力・デバイス間のシーケンス分割・勾配不安定性・数値精度・カーネル効率といった制約が顕在化します。

SubQのシステムは1Mトークン以上で安定してトレーニングが可能で、分散シーケンス並列処理によりシーケンスを複数デバイスにシャードできます。トレーニングパイプライン全体にわたってメモリスケーリングも線形に維持。


SubQの特徴
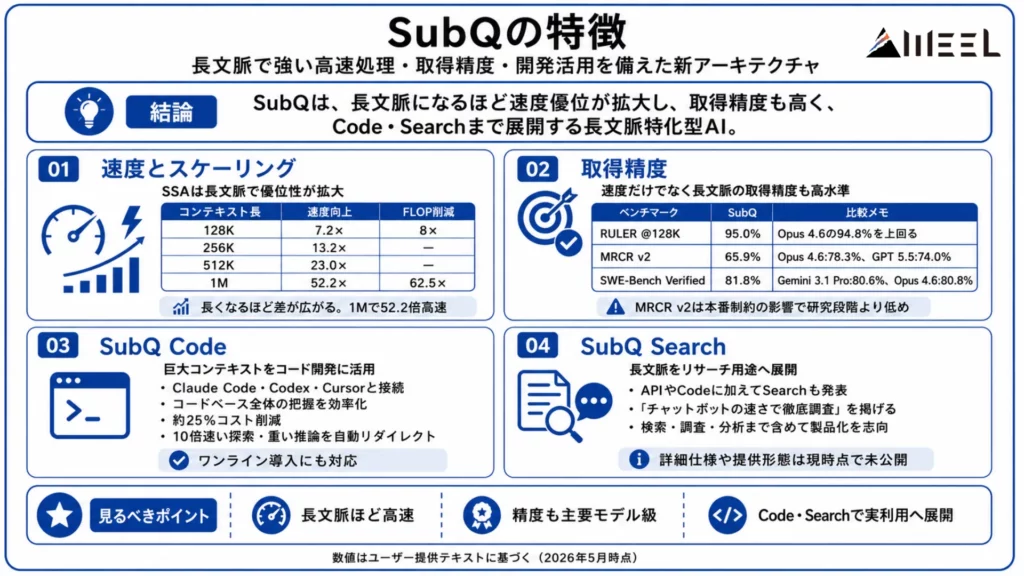
SubQの最大の強みは、従来のトランスフォーマーと根本的に異なるスケーリング特性にあります。速度・精度・アーキテクチャ比較の観点から主要な特徴を見ていきます。
1Mトークンで52.2倍のプリフィル高速化
SSAは、FlashAttention-2比で1Mトークン時に52.2倍の入力処理速度を達成しています。これは長文脈システムがインタラクティブなツールとして振る舞えるか、オフラインのバッチジョブのように感じられるかの差です。
| コンテキスト長 | プリフィル速度向上(FlashAttention比) | アテンションFLOP削減(標準比) |
|---|---|---|
| 128K | 7.2× | 8× |
| 256K | 13.2× | — |
| 512K | 23.0× | — |
| 1M | 52.2× | 62.5× |
注目すべきは、コンテキストが長くなるほど優位性が拡大する点です。128K時点では7.2倍だった速度差が1Mでは52倍超に広がります。長文脈ワークロードほどSubQの優位性が大きくなります。
フロンティアモデル級の長文脈取得精度
速度だけでなく、取得精度でも主要フロンティアモデルと同水準以上を達成しています。

多段階取得・集約・変数追跡・選択フィルタリングを評価するRULER @ 128Kでは95.0%を記録。Claude Opus 4.6の94.8%を上回っています。
| ベンチマーク | SubQ(SSA) | Claude Opus 4.6 | Claude Opus 4.7 | GPT 5.4 | GPT 5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| RULER @ 128K | 95.0% | 94.8% | — | — | — | — |
| MRCR v2 | 65.9% | 78.3% | 32.2% | 36.6% | 74.0% | 26.3% |
| SWE-Bench Verified | 81.8% | 80.8% | 87.6% | 未公開 | 未公開 | 80.6% |
巨大コンテキストをコード開発に落とす
SubQは、モデル本体だけでなく「SubQ Code」というCLIベースの製品も発表しています。
これは長文脈レイヤーとしてClaude Code、Codex、Cursorなどに接続し、コードベース全体の把握や高トークン消費タスクの探索を効率化することを狙ったものです。
SubQ Codeは約25%のコスト削減、10倍速い探索、重い推論ターンの自動リダイレクト、ワンラインインストールといった導入面のメリットがあります。
SWE-Bench Verifiedでフロンティアモデルと同水準の81.8%
ソフトウェアエンジニアリング性能を評価するSWE-Bench Verifiedでは81.8%を達成。Gemini 3.1 Pro(80.6%)やOpus 4.6(80.8%)を上回るスコアです。
このベンチマークは単純な取得テストではなく、実際のGitHub Issueに対してコードベース全体を理解しながらバグを特定し、パッチを生成する能力を評価します。
SubQの長文脈アーキテクチャが、ソフトウェアエンジニアリングタスクで実際に機能していることが示されています。
SubQ Searchは長文脈をリサーチ用途
SubQは、APIやCodeに加えて「SubQ Search」も発表しています。
これは長文脈検索ツールとして位置づけられており、公式には「Deep Research capabilities with chatbot speed(日本語訳:チャットボットのスピードを活かした徹底的な調査能力)」と説明されています。
長文脈モデルはコード理解や文書読解だけでなく、大量情報を横断して扱うリサーチ業務でも発揮されます。SubQ Searchの存在は、同社がSubQを単なる基盤モデルとしてではなく、検索・調査・分析のユーザー体験まで含めてプロダクト化しようとしていることを示しています。
ただし、公式ページにSubQ Searchについては記載されていますが、これ以上の詳細な仕様や提供形態は現時点で公開されていません。

300体のエージェント群で12時間自律稼働する次世代オープンウェイトLLMであるKimi K2.6について、詳しく知りたい方は以下の記事も参考にしてみてください。

SubQの安全性・制約
SubQ 1M-Previewは2026年5月時点でプライベートベータ段階にあります。包括的なモデルカードは近日公開予定とされており、安全性評価の全貌は現時点で明らかにされていません。
ベンチマーク結果については第三者機関による検証済みのデータが公開されており、RULER・MRCR v2・SWE-Bench Verifiedの各スコアはその検証を経ています。
| 制約・注意点 | 詳細 |
|---|---|
| アクセス形態 | プライベートベータ。早期アクセス申請が必要 |
| モデルカード | 包括的な安全性評価・仕様は近日公開予定 |
| プロダクションと研究スコアの差 | MRCR v2でプロダクション版(65.9%)と研究版(83%)に差があり |
| 対応用途 | 長文脈取得・コーディング・リサーチ特化。マルチモーダル用途は明記なし |


SubQの料金
SubQ 1M-Previewは、2026年5月時点でプライベートベータとして提供されており、公開された料金プランはありません。
提供形態はAPI・SubQ Code(CLI)の2種類。いずれも現時点では早期アクセスの申請を通じて利用できます。料金に関する詳細は公開されていません。詳しくは公式サイトのSales & Enterprise窓口への問い合わせが必要です。
| プロダクト | 概要 | 料金 |
|---|---|---|
| SubQ API | 開発者・エンタープライズ向けのフルコンテキストAPI | 詳細は公開されていません(早期アクセス申請が必要) |
| SubQ Code | コードベース全体を1コンテキストに読み込むCLIコーディングエージェント | 詳細は公開されていません |
SubQのライセンス
SubQ 1M-Previewのライセンス情報は、2026年5月時点で公式に公開されていません。
Subquadratic社の公式サイトでは「Terms of Use」「Privacy Policy」「Acceptable Use Policy」が公開されていますが、Apache 2.0やMIT Licenseのような明確なOSSライセンスは確認できません。
利用規約上では、ユーザーが入力したコンテンツや生成結果(Output)の権利はユーザー側に帰属すると明記されています。一方で、モデル本体やアルゴリズム、基盤技術の権利はSubquadratic側が保持しており、リバースエンジニアリングやモデルを競合AI開発へ利用する行為は禁止されています。
Claude Sonnet 4.5を超えた空間知能と圧倒的コーディング性能を持つQwen3.6-35B-A3Bについて、詳しく知りたい方は以下の記事も参考にしてみてください。
SubQの使い方
SubQは現在、API・SubQ Codeの2つの入口でプライベートベータとして提供されています。いずれも公式サイトから早期アクセスを申請することで利用を開始できます。
筆者はまだアクセス権を得られていないので、公式サイトから得られる情報を元にお伝えします。
SubQ APIを利用する
SubQ APIは、開発者・エンタープライズチーム向けのフルコンテキストAPIです。1Mトークンのコンテキストウィンドウを活用した独自ワークフローの構築に対応しています。
- 公式サイト(subquadratic.com)の「Request early access」から申請を行う
- アクセスが承認されたら、APIドキュメントに従ってAPIキーを取得する
- 標準的なLLM APIの形式でSubQにリクエストを送信し、長文脈タスクを処理する
SubQ Codeを利用する
SubQ Codeは、コードベース全体を単一のコンテキストウィンドウに読み込むCLIベースのコーディングエージェントです。
マルチエージェントシステムの調整オーバーヘッドを排除し、リポジトリ全体を1パスで計画・実行・レビューできます。エンジニアが「どこを参照しているか」を逐一指定しなくても、コードベース全体を視野に入れた作業が可能です。
- 公式サイトからSubQ Codeの早期アクセスを申請する
- CLIツールをインストールし、対象リポジトリのディレクトリで起動する
- コードベース全体をコンテキストに読み込んだ状態で、自然言語でコーディング指示を与える
【業界別】SubQの活用シーン
SubQが特に力を発揮するのは、「単一のドキュメントを超えた複雑な参照関係を持つ大規模コーパス」を扱う領域でしょう。ここでは業界別に活用が期待されるシーンを紹介します。
ソフトウェア開発・エンジニアリング
ソフトウェア開発では、コードベース全体を単一コンテキストに収めてレビューや修正を行うことが最大のユースケースになります。
ある関数が一つのモジュールで定義され、数十の他モジュールで呼び出され、さらに別ファイルのテストで制約されているような構造は、従来のLLMではRAGや分割処理なしには扱えませんでした。SubQ Codeはリポジトリ全体を1パスで把握し、インターフェース違反のない修正やリファクタリングを実行できます。
SWE-Bench Verifiedで81.8%を達成していることから、実際のGitHub Issueレベルの複雑な問題にも対応できます。
法務・コンプライアンス
法務分野では、複数文書にまたがる参照関係を持つ大量の契約書や規制文書の解析に活用が期待されます。
ある義務が定義条項・例外条項・数ページ先の参照条項に依存するような複雑な契約書も、SubQの長文脈アーキテクチャなら全体を視野に入れた推論が可能です。
チャンキングやRAGで生じる参照構造の消失を防ぎながら、複数文書を横断した整合性確認ができると考えられます。
研究・学術
研究ワークフローでは、多数の論文にわたる証拠を照合して結論を導く作業でSubQの長文脈推論が活きます。
仮説の立案・証拠の収集・前提の検証・結果の解釈・次の実験設計という研究サイクルを一つのコンテキスト内で保持しながら進められます。RAGベースのシステムでは困難だった「複数論文にまたがる矛盾の発見」や「遠隔した文書間の関係性把握」も期待できるでしょう。
エンタープライズ文書処理
大企業での文書処理では、数万ページに及ぶ社内文書・財務データ・データベーステーブルを単一パスで扱える点が大きなアドバンテージです。
従来は「ベクターDB+チャンキング+RAGパイプライン」という複雑なスタックが必要でした。
SubQのアーキテクチャにより、こうしたエンジニアリングコストを削減しながら情報の完全性を保った処理が実現できます。これまでコスト上の理由から現実的でなかったハイボリュームな長文脈ワークロードが、経済的に運用できる可能性があります。
Metaが発表したパーソナル超知性AIであるMuse Sparkについて、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】SubQが解決できること
SubQが解決できる代表的な課題を紹介します。長文脈AIの限界から生じる実務上の問題に対し、SubQがどのようにアプローチするかを見ていきます。
RAGパイプラインへの依存から脱却できる
従来のシステムでは、大規模コーパスを扱う際に「チャンキング → ベクターDB → 検索 → 再ランク → モデルへの送信」という複雑なスタックが必要でした。
SubQは百万トークン規模のコーパスを直接コンテキストに収められるため、RAGパイプラインの多くが不要になります。
RAGシステムが保持できるのは意味的類似性のみで、位置・階層・隣接コンテキスト・参照構造は失われます。SubQはこうした情報の損失なく、コーパス全体を一度に処理できます。
コンテキスト境界での情報ロスを防げる
従来のLLMでは、コンテキストウィンドウを超えた情報はチャンク分割・要約・オーケストレーションで補う必要があり、「チャンクには正しいテキストがあるが、それが重要な理由は失われている」という問題が生じます。
SubQは長いシーケンス全体を一括で処理し、コンテンツ依存の選択によって文書のどこにあっても関連情報を取得可能です。エージェントワークフローで各ステップ間にコンテキストを圧縮する必要もなく、情報の連続性が保たれます。
大規模コードベースを一括で解析できる
SubQ Codeは、リポジトリ全体を単一コンテキストウィンドウに読み込んで計画・実行・レビューを1パスで行えます。マルチエージェントシステムに伴う調整オーバーヘッドを排除し、ステップをまたいだエラーの複合化を防ぎます。
従来のコーディングエージェントは、コードベースの一部を参照しながら作業するため「ローカルには正しいパッチだが、他モジュールで定義されたインターフェースを違反している」という問題が起きがちです。
SubQはコードベース全体を視野に入れた修正が可能です。
| 課題 | SubQで解決できること | 留意点 |
|---|---|---|
| RAGスタックの複雑性 | 大規模コーパスを直接コンテキストに収めてRAGなしで処理 | 現時点ではプライベートベータのためアクセス制限あり |
| コンテキスト境界での情報ロス | 百万トークン規模の文書全体を一括処理し、参照構造を保持 | プロダクション版MRCR v2は研究版より低いスコア |
| コードベース横断の整合性 | リポジトリ全体を1コンテキストで把握しパッチ生成 | SWE-Bench VerifiedでOpus 4.7(87.6%)には及ばない |
| 長文脈処理のコスト | 線形スケーリングにより従来比で大幅なFLOP削減を実現 | 詳細なコスト・料金は未公開 |
スマートフォンでも動作するGoogleの最強オープンモデルであるGemma 4について、詳しく知りたい方は以下の記事も参考にしてみてください。

SubQのよくある質問
ここではSubQのよくある質問について回答していきます。SubQの使用を検討している場合には、ぜひ参考にしてみてください。
SubQが拓く長文脈AIの新時代
SubQは、2026年5月にSubquadratic社が発表した「世界初の完全サブクアドラティックLLM」です。SSAによる線形スケーリング・コンテンツ依存ルーティング・任意位置からの正確な取得を同時に実現し、1Mトークンで62.5倍のFLOP削減と52.2倍のプリフィル速度向上を達成。
RULER・MRCR v2・SWE-Bench Verifiedの各ベンチマークで、フロンティアモデル級の精度を維持しています。
単なる「速いLLM」ではなく、SubQは「百万トークン規模のコンテキストを実用的なコストで扱える」という新しい設計前提を持つモデルといえるでしょう。
RAGパイプラインやチャンキング、マルチエージェントオーケストレーションといった回避策が必要だった根本的な制約である二次スケーリング問題を初めてアーキテクチャレベルで解消しています。
今後は、百万トークンを超えた超長文脈への拡張と、エンタープライズ向けのプロダクション提供が本格化していくでしょう。コンテキスト長の制約が取り除かれることで、これまで実現不可能だったAIアプリケーションの設計空間が根本から広がっていくと考えられます。
ぜひ皆さんも本記事を参考にSubQに早期アクセスリクエストをして、使って見てください!

最後に
いかがだったでしょうか?
SubQを活用することで、これまでRAGやチャンキングなどの複雑なスタックが必要だった大規模長文脈タスクを、シンプルかつ高速に処理できるようになります。一方で、プライベートベータ段階であり料金や詳細仕様が未公開のため、導入を検討する際は早期アクセス申請を通じた情報収集も重要な選択肢です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

