
Voxtral Transcribe 2とは?超低遅延×高精度を両立する次世代音声認識モデルを徹底解説
- 超低遅延と高精度を両立するリアルタイム対応の音声認識モデル
- バッチ処理とライブ用途を同一ファミリーで使い分け可能な設計
- API利用とオープンウェイトの両対応による実務・プロダクト実装の柔軟性
2026年2月、Mistral AIから新たな音声認識モデルが公開されました。
今回発表された「Voxtral Transcribe 2」は、高精度な文字起こしと超低遅延のリアルタイム音声認識を両立する、次世代の音声認識モデル。バッチ処理向けの文字起こしと、ライブ用途を想定したリアルタイム処理を同一ファミリーでカバーしています。
これまでの音声認識モデルは「精度は高いが遅い」「リアルタイムだが実用精度に届かない」といったトレードオフのものが多かったです。Voxtral Transcribe 2は、こうした課題に対して、ストリーミング前提の設計と最適化されたモデル構成によってアプローチしています。
しかし、新しい音声モデルが登場しても、「従来のASRと何が違うのか」「どのような用途に向いているのか」「実務でどう活用できるのか」が分かりにくいケースも少なくありません。
そこで本記事では、Voxtral Transcribe 2の概要や仕組み、特徴を整理した上で、実装方法や活用事例までを解説します。本記事を読むことで、Voxtral Transcribe 2がどのような音声認識モデルで、どのような場面で力を発揮するのかが理解できます。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Voxtral Transcribe 2の概要
Voxtral Transcribe 2は、音声を高精度かつ低遅延で文字起こしすることを目的に開発された音声認識モデル。
Voxtral Transcribe 2には、録音データをまとめて処理するVoxtral Mini Transcribe V2と、ストリーミング入力に対応したVoxtral Realtimeがあります。
Voxtral Mini Transcribe V2は話者分離や単語単位のタイムスタンプに対応しており、Voxtral Realtimeは200ms未満まで遅延を抑えたリアルタイム処理を実現。
これにより、事後分析からライブ用途まで、幅広い音声処理ニーズをカバーできます。


Voxtral Transcribe 2の仕組み
ここでは、Voxtral Transcribe 2がどのような仕組みで音声をテキストに変換しているのかを解説します。
ストリーミング指向のアーキテクチャ
まず、Voxtral Transcribe 2は音声入力を逐次処理するストリーミング指向のアーキテクチャを採用しています。従来の音声認識では、音声を一定の長さに分割してからまとめて解析する方式が一般的でした。
一方、本モデルは音声が到着するそばから解析を進める構造となっており、これが超低遅延を実現する要因です。
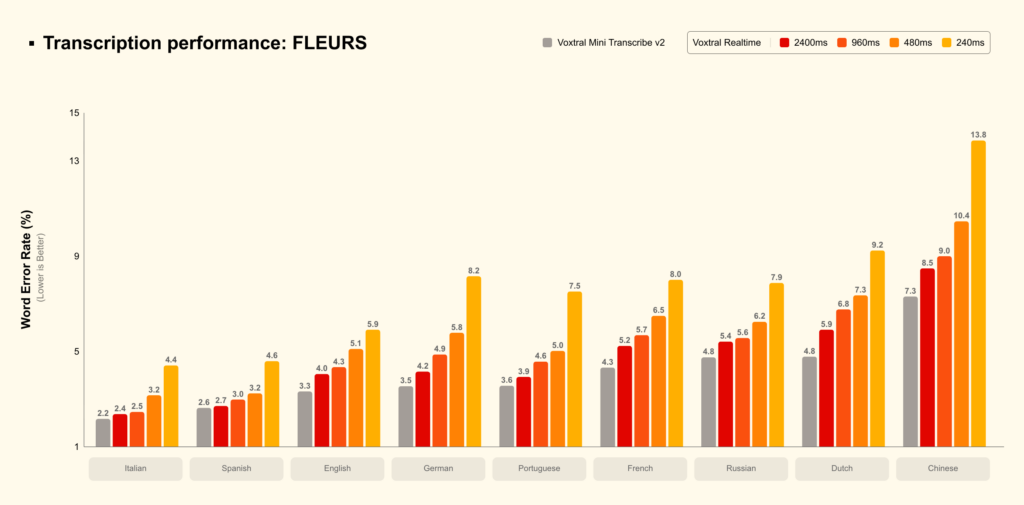
Voxtral Mini Transcribe V2は200ms程度の遅延でエラー率がかなり低いですが、ストリーミング対応のVoxtral Realtimeも低遅延かつ低いエラー率を達成していることがわかります。
処理フローと要素技術
処理の流れとして、入力された音声信号はまず音響特徴に変換され、その後、音声専用に設計されたエンコーダーによって時系列情報として処理されます。
続いて言語モデル部分が文脈を考慮しながらテキストを生成し、最終的に単語単位のタイムスタンプや話者情報を付与。バッチ処理向けモデルでは、ここに話者分離や長時間音声への対応が組み込まれています。
なお、感情豊かな音声を生成できるオープンソースTTSモデルであるMaya1について詳しく知りたい方は、下記の記事を合わせてご確認ください。
Voxtral Transcribe 2の特徴
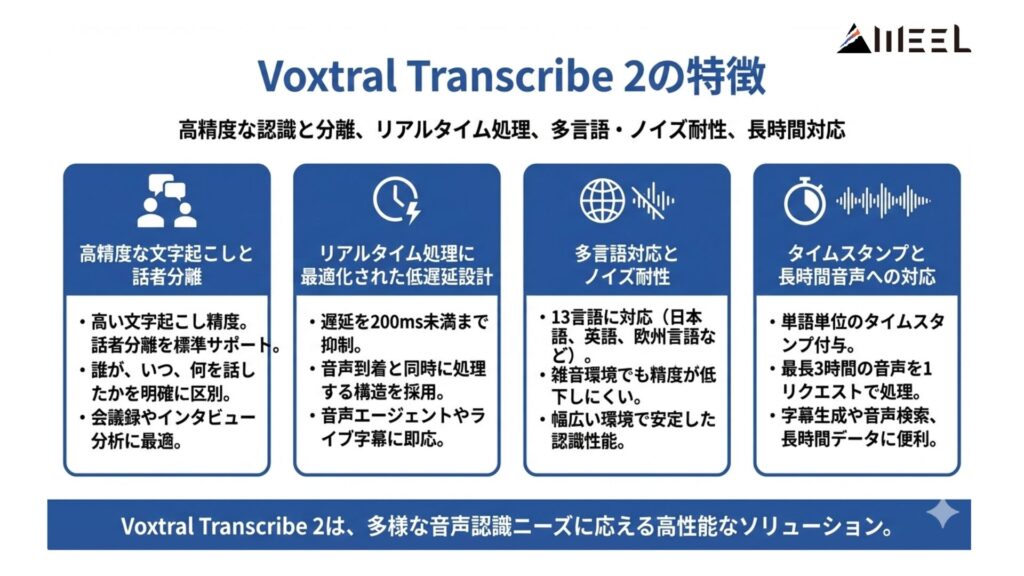
ここでは、Voxtral Transcribe 2が持つ主要な特徴を整理します。単なる音声認識にとどまらず、実際の実用性を意識して開発されており、Voxtral Transcribe 2には主に4つの特徴があります。
高精度な文字起こしと話者分離
Voxtral Mini Transcribe V2は、高い文字起こし精度に加えて話者分離を標準サポート。誰が、いつ、何を話したかを明確に区別できるため、会議録やインタビュー分析での利便性が向上します。
特に複数人が参加する音声データでは、単なる全文テキスト化では不十分なケースも多く、話者分離が可能なのは実用的と言えるのではないでしょうか。
リアルタイム処理に最適化された低遅延設計
Voxtral Realtimeは、遅延を200ms未満まで抑えられるリアルタイム音声認識モデル。オフラインモデルを流用する方式ではなく、音声到着と同時に処理を進める構造が採用されています。
その結果、音声エージェントやライブ字幕のように即応性が求められる用途でも、実用的な精度を維持できます。
多言語対応とノイズ耐性
Voxtral Transcribe 2は13言語に対応しており、英語だけでなく日本語や欧州言語を含む幅広い言語で安定した認識性能を発揮。
さらに、工場やコールセンターのような雑音環境でも精度が大きく低下しにくい点が特徴です。
タイムスタンプと長時間音声への対応
単語単位でのタイムスタンプ付与に対応しているため、字幕生成や音声検索との相性が良好です。
また、バッチ処理モデルでは最長3時間の音声を1リクエストで処理できる仕様となっており、長時間会議や講演データの扱いやすくなっています。
Voxtral Transcribe 2の安全性・制約
ここでは、Voxtral Transcribe 2を利用する際に把握しておきたい安全性の考え方と技術的な制約について解説します。
オンプレミス運用とデータ管理
安全性の観点では、Voxtral Transcribe 2はオンプレミスやエッジ環境での運用を想定した構成が用意されています。特にVoxtral Realtimeはオープンウェイトとして提供されており、クラウドに音声データを送信せずに処理が可能。
このため、機密性の高い会話データや個人情報を含む音声を扱う場合でも、外部サービスへの依存を抑えた運用ができます。
一方で、データ保持や暗号化、ログ管理といった詳細なセキュリティ実装については、公式情報では具体的に明示されていません。
話者分離の制約
制約面として押さえておきたいのが、話者分離の性能です。複数人が同時に話す、いわゆる重なり発話が発生した場合、モデルは基本的に一人の話者として処理する傾向があります。
そのため、全発話を厳密に分離したい用途では、出力結果の取り扱いに注意が必要です。
遅延と精度のトレードオフ
また、リアルタイムモデルは低遅延を優先する設計となっているため、設定する遅延値によっては精度とのトレードオフが生じます。遅延を極端に短くすると誤認識が増える可能性があり、用途に応じたパラメータ調整が重要なポイントです。
Voxtral Transcribe 2の料金
ここでは、Voxtral Transcribe 2の料金体系について解説します。
従量課金制の料金体系
Voxtral Transcribe 2はAPIベースで提供されており、モデルごとに分単位の従量課金が設定されています。バッチ処理向けのVoxtral Mini Transcribe V2と、リアルタイム処理向けのVoxtral Realtimeでは単価が異なります。
| モデル名 | 用途 | 料金 |
|---|---|---|
| Voxtral Mini Transcribe V2 | バッチ処理向け文字起こし | 音声1分あたり 0.003ドル |
| Voxtral Realtime | リアルタイム音声認識 | 音声1分あたり 0.006ドル |
Voxtral RealtimeはAPIが提供されていませんが、デモサイトなどで利用する場合にAPIキーが必要となり、その時の料金です。
いずれも高精度な音声認識モデルとしては比較的低価格帯に位置付けられており、大量の音声データを処理するケースでもコストを抑えやすくなっています。
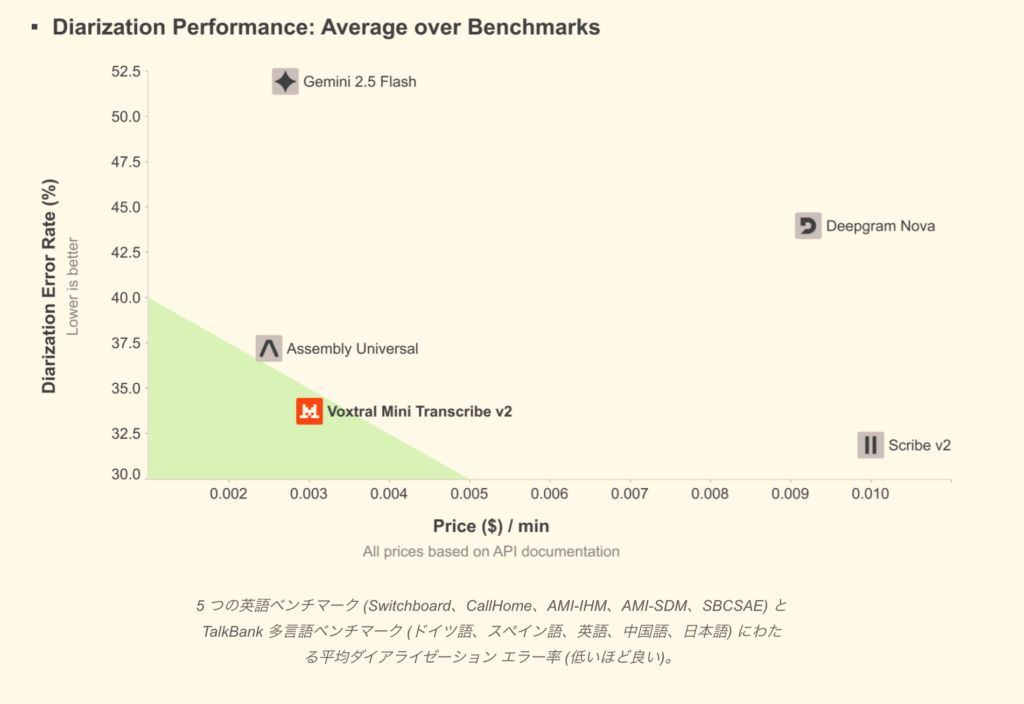
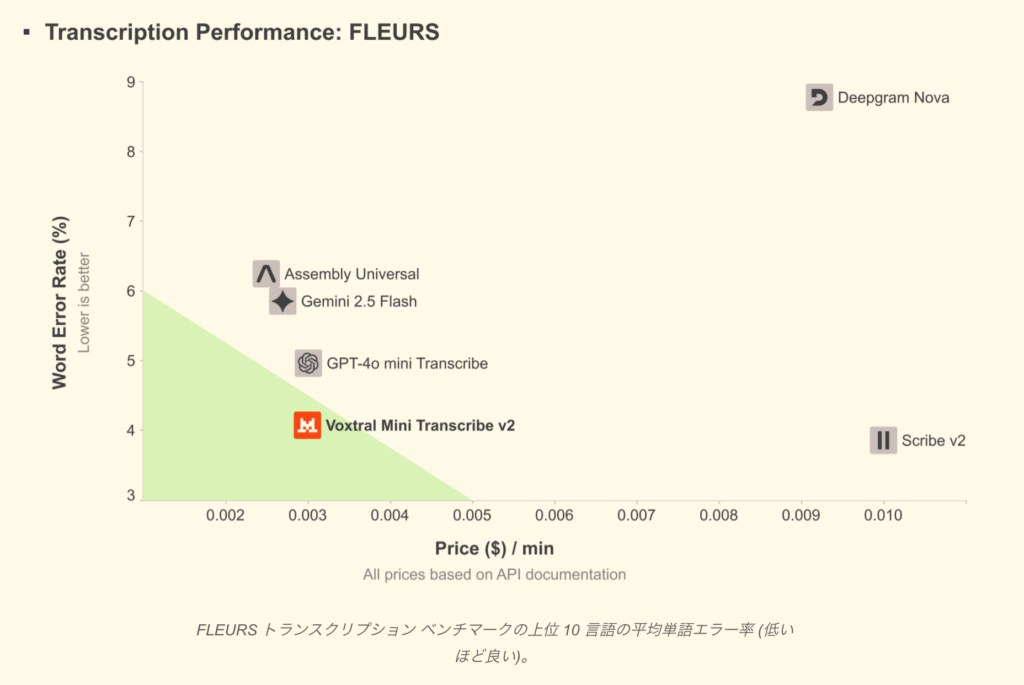
また、GPT-4o mini Transcribe、Gemini 2.5 Flash、Assembly Universal、Deepgram Novaよりも精度が高く、ElevenLabsのScribe v2よりも約3倍高速に音声を処理しながら、5分の1のコストで同等の品質です。
オープンウェイト版の提供
また、リアルタイムモデルについてはオープンウェイト版が用意されておりHugging Faceから取得できます。この場合、モデル自体の利用料金は発生せず、自前のGPU環境やインフラコストのみで運用が可能です。


Voxtral Transcribe 2のライセンス
Voxtral Transcribe 2はApache 2.0ライセンスで公開されていて、商用利用・改変・再配布・特許利用・私的利用のすべてが許可されています。Apache 2.0ライセンスはオープンな条件で利用を認められているライセンスです
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
Apache 2.0ライセンスのもと、商用利用を含めて幅広い用途で利用できますが、生成物の内容や利用方法については利用者側が責任を負う点に注意が必要です。
まず、違法・有害なコンテンツの生成や法令に反する利用は認められていません。また、既存IPや実在人物を用いた生成物を商用利用する場合は、権利者のガイドラインや肖像権・プライバシーへの配慮が不可欠です。
なお、高速かつ高評価を獲得したオープンソースTTSであるChatterbox Turboについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Voxtral Transcribe 2の実装方法
Voxtral Transcribe 2はWeb UI上でも利用可能です。
フリー音声のCM原稿(せっけん)を文字起こししてもらいました。
正答率は90%程度という感じです。
文字起こしの結果はこちら
無加のシャボン玉石ならもう安心天然の保成分が含まれるためにいを与え健やかに保ちます
おのことでおみの方はぜひ一度無加シャボン玉石をお試しくださいお求めは0120-0055-95までAPI経由で利用するには以下です。
サンプルコードはこちら
# ライブラリのインストール
!pip -q install mistralai
# サンプルコード
from mistralai import Mistral
API_KEY = ""
client = Mistral(api_key=API_KEY)
audio_path = ""
with open(audio_path, "rb") as f:
res = client.audio.transcriptions.complete(
model="voxtral-mini-2602",
file={
"content": f,
"file_name": "001-sibutomo.mp3",
},
diarize=True,
timestamp_granularities=["segment"],
)
print(res.text)結果はこちら
無加のシャボン玉石ならもう安心天然の保成分が含まれるためにいを与え健やかに保ちます おのことでおみの方はぜひ一度無加シャボン玉石をお試しくださいお求めは0120-0055-95まで実装自体は非常に簡単にできます。また、出力結果はWeb UIで行った時と同等でした。
また、Voxtral Realtimeはデモサイトが用意されているので、APIキーを入力するだけで利用可能です。
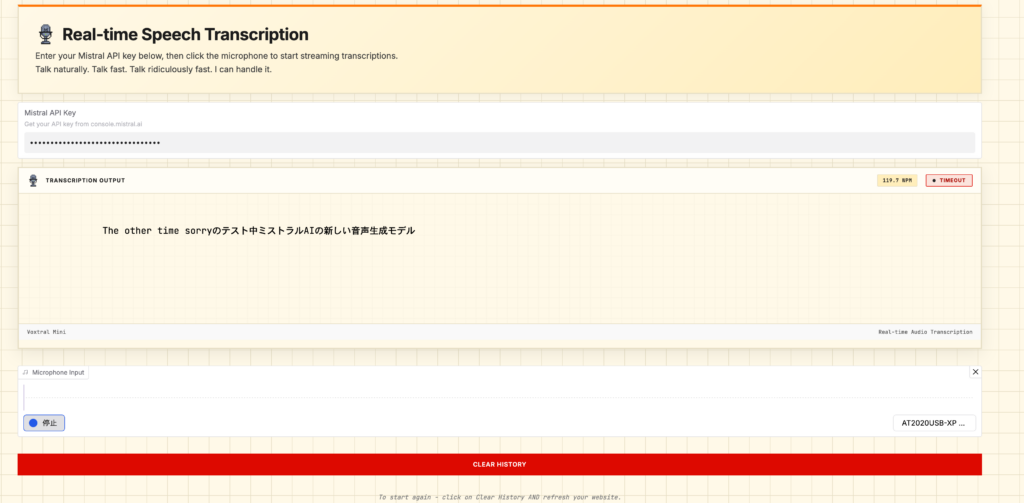
私の滑舌が悪いのか、結構誤字がありました。
Voxtral Transcribe 2の活用シーン
ここでは、Voxtral Transcribe 2がどのような場面で活用できるのかを考えていきます。
会議やインタビューの文字起こし
まず第一に考えられるのが、会議やインタビューの文字起こしです。Voxtral Mini Transcribe V2は話者分離と単語単位のタイムスタンプに対応しており、「誰がどのタイミングで発言したか」を明確に記録できます。
リアルタイム字幕生成
次に、リアルタイム字幕生成への応用が考えられます。Voxtral Realtimeは200ms未満の低遅延設定が可能なため、ライブ配信やオンラインイベントでの即時字幕表示に適しているでしょう。
多言語対応も備えていることから、国際イベントやグローバル配信での利用もできそうです。
音声エージェントや対話型システムへの組み込み
音声エージェントや対話型システムへの組み込みも現実的な活用例です。低遅延で音声をテキスト化できるため、音声入力を前提としたAIアシスタントやIVRシステムとの相性がよいのではないでしょうか。
Voxtral Transcribe 2を実際に使ってみた
Voxtral Transcribe 2の文字起こしとVibeVoice-ASRを比較してみたいと思います。
音声ファイルはこちらから入手しています。
まずは一つ目です。
VibeVoice-ASRの結果はこちら
[{"Start":0,"End":10.77,"Speaker":0,"Content":"無添加のシャボン玉石鹸なら、もう安心。天然の保湿成分が含まれるため、肌に潤いを与え、すこやかに保ちます。"},
{"Start":10.99,"End":24.01,"Speaker":0,"Content":"お肌のことでお悩みの方は、ぜひ一度、無添加シャボン玉石鹸をお試しください。お求めは、0120-0055-9500。"}]Voxtral Transcribe 2の結果はこちら
無加のシャボン玉石ならもう安心天然の保成分が含まれるためにいを与え健やかに保ちます
おのことでおみの方はぜひ一度無加シャボン玉石をお試しくださいお求めは0120-0055-95までこちらの音声はVibeVoice-ASRの方が正確に文字起こしができています。
続いて2つ目です。
VibeVoice-ASRの結果はこちら
[{"Start":0,"End":8.8,"Speaker":0,"Content":"F博士が発見開発した乳酸菌。ヨーグルトやマイドリンクなんかに入っているものと同じなんですか?"},
{"Start":8.8,"End":10.81,"Content":"[Music]"},
{"Start":10.81,"End":22.8,"Speaker":0,"Content":"なんですか、この写真は?いろんな乳酸菌の働きを比較した表ですね。うわー、白玉菌っていてほしくないやつですね。"}]Voxtral Transcribe 2の結果はこちら
F博士が発見開発したヨーグルトやいドリンクなんかに入っているものと同じなんですか?
なんですか?
この写真はいろんなのきを比した表ですねうわー、白玉っていてほしくないやつですねこちらもVibeVoice-ASRの方が精度高く文字起こしができていますね。ただ両者とも悪玉菌を白玉菌と文字起こししている気がします。
最後に3つ目です。
VibeVoice-ASRの結果はこちら
[{"Start":0.0,"End":12.11,"Speaker":0,"Content":"イスタンブールは、世界で唯一、アジア大陸とヨーロッパ大陸にまたがる町で、この二つの大陸を分けているのがボスポラス海峡です。"},
{"Start":12.59,"End":21.81,"Speaker":0,"Content":"アジアとヨーロッパの間を進んでいく壮大な体験ができるボスポラス海峡クルーズを堪能していただく予定です。"}]Voxtral Transcribe 2の結果はこちら
イスタンブールは世界で唯一アジア大陸とヨーロッパ大陸にまたがる街でこの2つの大陸を分けているのがボスポラス海です
アジアとヨーロッパの間を進んでいく大な体ができるボスポラス海クルーズを能していただく予定です今回もVibeVoice-ASRの方が精度高く文字起こしできており、精度は100%でした。
なお、フルデュプレックス音声モデルであるPersonaPlex-7Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではVoxtral Transcribe 2の概要から仕組み、実際の使い方や活用事例について解説をしました。Voxtral Transcribe 2は低コストで利用でき、かつそのコスト以上の性能を発揮するため、さまざまな場面で活躍してくれそうです。
その一方で、コストに対する性能は高いですが、VibeVoice-ASRと比較すると精度はあと一歩というところなので、利用用途に応じて使い分けるのが良さそうです。
ぜひ皆さんも本記事を参考にVoxtral Transcribe 2を使ってみてください!

最後に
いかがだったでしょうか?
Voxtral Transcribe 2は、コストと性能のバランスに優れた音声認識モデルであり、用途を選べば実務でも十分に活用できる選択肢です。一方で、音声の種類や利用シーンによっては精度差が出る場面もあるため、導入前の検証は欠かせません。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


