
【NExT-GPT】テキスト、画像、ビデオ、音声、全部対応できるLLM(大規模言語モデル)が登場

皆さんは「NExT-GPT」というマルチモーダル大規模言語モデルをご存じですか?
このツールは、テキストから動画を生成したり、逆に動画からテキストを生成して、なんとさらにそこから歌を生成したりと、とにかく多様な組み合わせの入出力ができるAIモデルなんです!
どうですか?これを聞いただけでもすごいAIっていうのが伝わってきますよね!
今回は、NExT-GPTの概要や実際に使ってみた感想、GPT4との比較をお届けします。
多様な入力から新しいコンテンツを生成するという、より人間らしい能力をもつNExT-GPT。
その能力を可能にした技術についても触れますので、是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
NExT-GPTの概要
近年、マルチモーダル大規模言語モデルの研究が急速に進展し、次々にモデルが開発されています.
それらの多くは入力のマルチモーダル理解、分かりやすく言うと入力側はテキストや画像など、様々な種類のデータを理解できますが、出力側は複数の種類のデータを組み合わせて出力することができません。そこで、このような課題を解決するため、出力側も様々な種類のデータを組み合わせてコンテンツを生成できるモデルとしてNExT-GPTが開発されました。
そんなNExT-GPTの主な特徴は以下の4つです。
多機能性:テキスト、画像、ビデオ、音声などのさまざまなモダリティのデータを入力として受け取り、理解できます。そしてそれに基づいて多種多様なデータ形式を組み合わせ、新しいコンテンツを生成できる能力を持っています。
汎用性:このモデルは、特定のタスクやモダリティに特化しているわけではありません。そのため、さまざまな分野で活用することが可能です。
拡張性と効率性: 既存の高性能なエンコーダとデコーダを活用することで、わずかなパラメータのチューニングだけで新しいモダリティに対応できます。また、これによって低コストのトレーニングが可能となり、さらに多くのモダリティに対応することが容易になります。
Modality-switching Instruction Tuning (MosIT):異なるモダリティ間での理解と生成を強化するための新しい技術、MosITを導入しています。この技術を簡単に説明すると、ユーザーの指示を理解し、それに応じてモデルが正しい種類のデータを生成するように調整する技術です。これにより、モデルのマルチモーダルな理解とコンテンツ生成の能力を大幅に強化できます。
詳しい説明は下のNExT-GPTのGitHubのリンクを貼っておきますので、そちらをご覧ください。どうやらMosIT専用のデータセットなんかもあるようです。
参考サイト:https://next-gpt.github.io/
これらの特徴を持つNExT-GPTは、実際に活用されていくのはこれからのようですが、例えば教育ツールとして、テキストの説明に基づいて視覚的なコンテンツを生成したり、検索ツールとして、テキストから画像や動画を検索したり、画像や音声からテキストやそのほかの形式のコンテンツを検索したりすることができると考えられます。
それでは実際にNExT-GPTを試してみましょう!
なお、NExT-GPTはデモ版のみ公開されているため、今回はそちらを使用していきます。

NExT-GPTの使い方
まず、以下のリンクにアクセスします。
次に、Demoをクリックします。
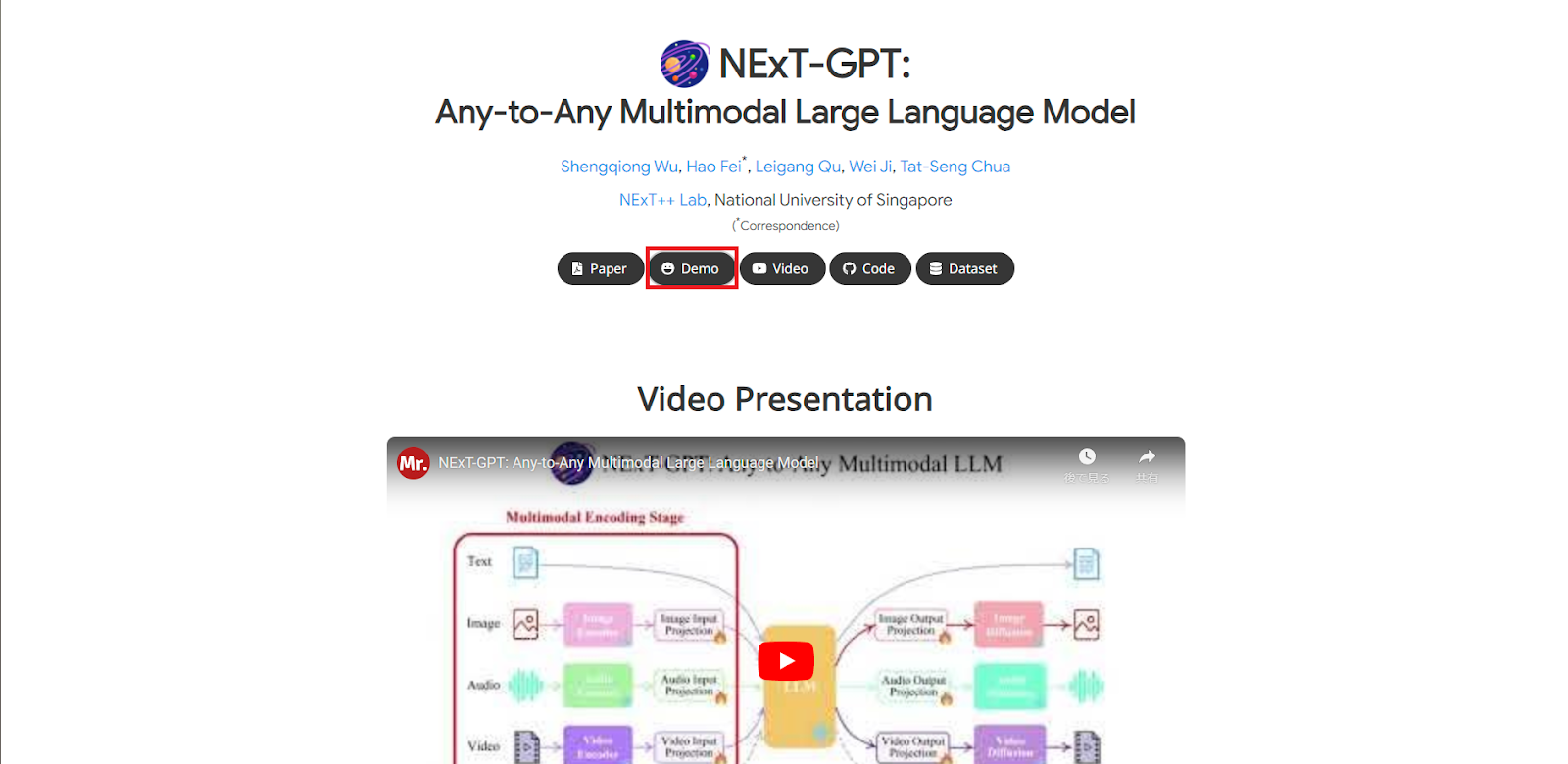
すると、NExT-GPTのページに飛ぶことができます。
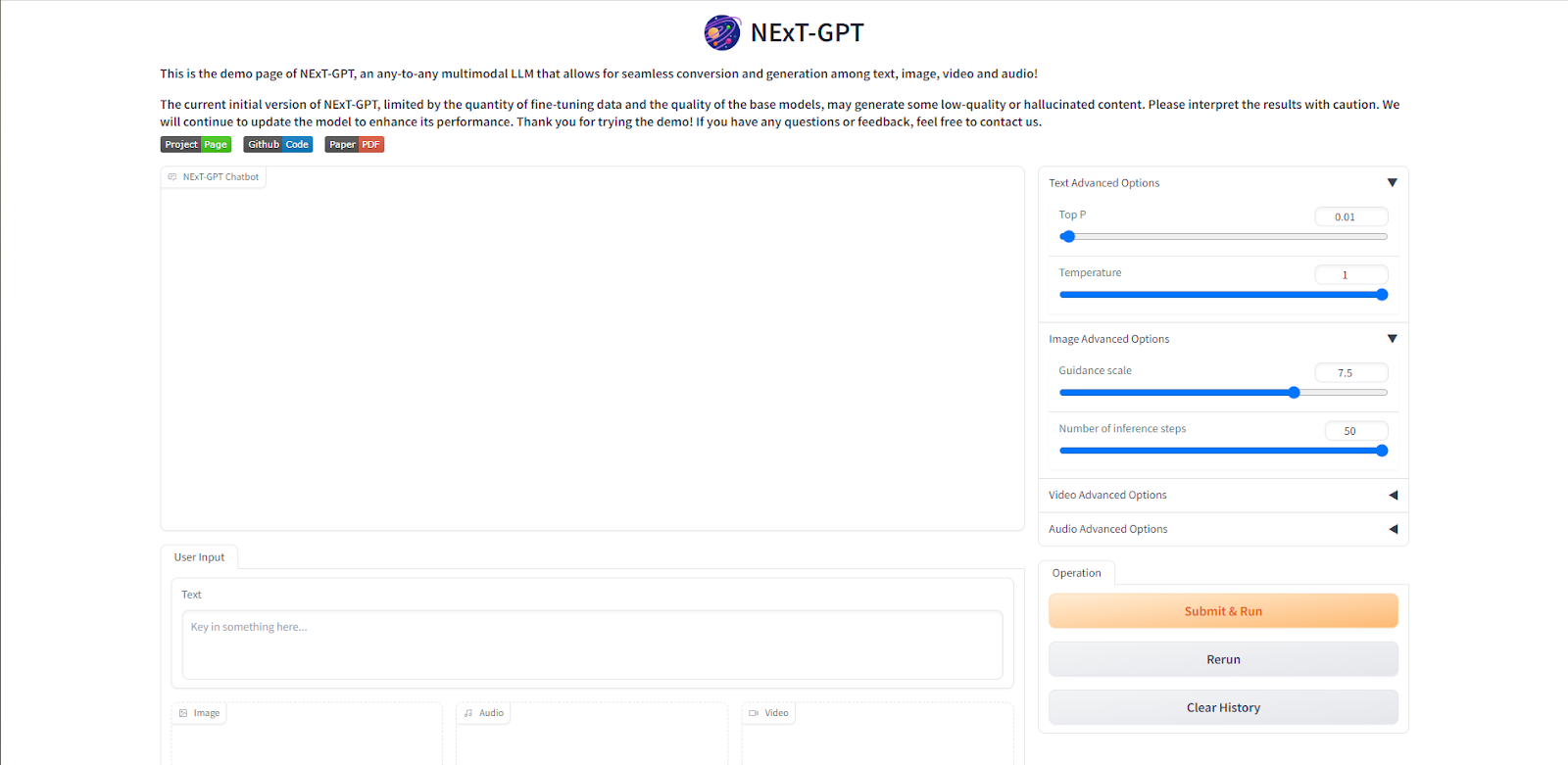
デモ画面で操作できるのは、下の画像の枠で囲われている部分で、赤枠のところでテキスト・画像・音声・動画形式の入力を行い、青枠のところで出力のパラメータの設定ができ、緑枠のところで実行と再実行、出力履歴のクリアが行えます。

それでは、実際にこのデモ版を使ってNExT-GPTの機能を試していきましょう!
なお、その他のマルチモーダルAIについて知りたい方はこちらをご覧ください。
→【Vcoder】GPT-4V超えの最強マルチモーダルLLMの使い方〜実践まで
NExT-GPTを実際に使ってみた
今回は、デモ版のNExT-GPTでできることを一通り試してみて、その結果をお伝えしたいと思います。
なお、NExT-GPTは日本語に対応していないようなので、英語を使用して機能を試します。
テキスト-テキスト生成
まずは、テキスト入力からテキストを出力させてみます。
「来週京都に旅行に行くので、おすすめのスポットを教えてください」と入力してみると、
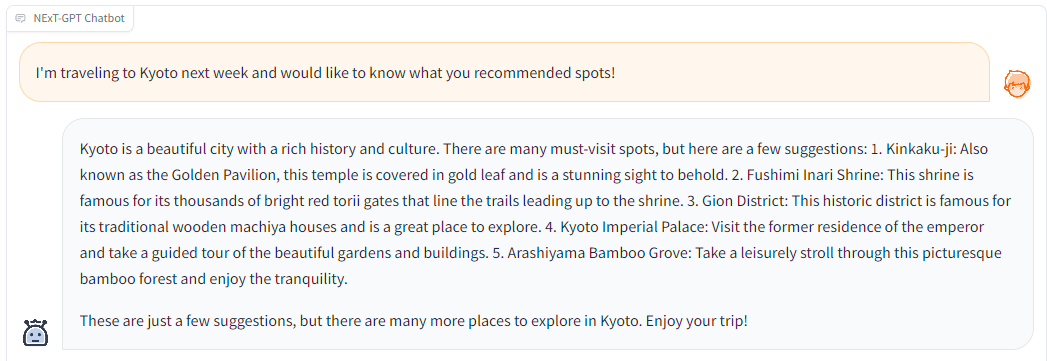
このように、金閣寺や伏見稲荷大社などの京都の観光スポットをいくつか教えてくれて、なおかつ最後に「これらはほんの一例に過ぎず、まだまだ京都にはたくさんの観光スポットがある」ということを教えてくれました!
出力時間も15秒程と、遅くはなく、人間と遜色ないレベルの回答をしてくれました!
テキスト-画像生成
次にテキスト入力から画像を生成させてみます。
「おかしな画像を生成できますか?」と質問しました。
すると、下の画像のような画像を生成してくれました。
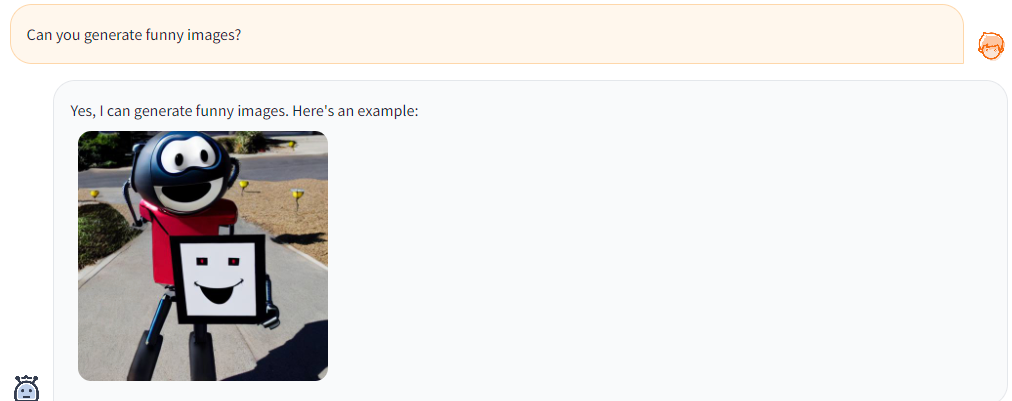

かなり高画質で、「おかしな」という特徴も捉えていると感じられ、ネットでこの画像を検索しても同じものはヒットしなかったので、この画像が新規に生成されたものだということが分かります。
出力時間も10秒程度と速く、デモ版ながらとても高性能だということが伝わってきます!
テキスト-動画生成
次に、テキスト入力から動画を生成させてみます。
「犬が笑っている動画を生成できますか?」と質問したところ、以下のような動画を生成してくれました。

動画については、犬というところはあっているのですが、笑っているかといわれると微妙なところで、むしろ最後の方は睨みつけてくるような少し怖い動画になっていました…
パラメータの設定やデモ版だからということもありそうですが、3秒と短く、音声もない動画ですが、出力には2分以上かかり、画像と比べるとクオリティもそこまで高くないものでした。
やはり、AIにクオリティの高い動画を生成させるのはかなり難しい技術のようです。(生成出来ている事自体本当にすごいことですが!)
テキスト-音声生成
次に、テキスト入力から音声を生成してもらいました。
「なにか音を生成できますか?」と質問したところ、以下の画像のようにどんな音を生成したいですか?と聞いてきたので、音楽と答えると
以下のように9秒間の音楽を生成してくれました。

生成された音声を聞いてみると、太鼓やトランペット?などのいくつかの楽器で演奏されている音楽で、少しぎこちない感じもしますが、AIが数十秒で生成したものと考えるとかなりすごいです!
これは動画にも言えるかもしれませんが、もっと詳しく条件を指定すると、よりクオリティの高いものを生成してくれるかもしれません。
画像-テキスト生成
まだまだ機能を試します!
次は、画像入力からテキストを出力してもらいました。
画像は先ほど、生成された画像を使用します。
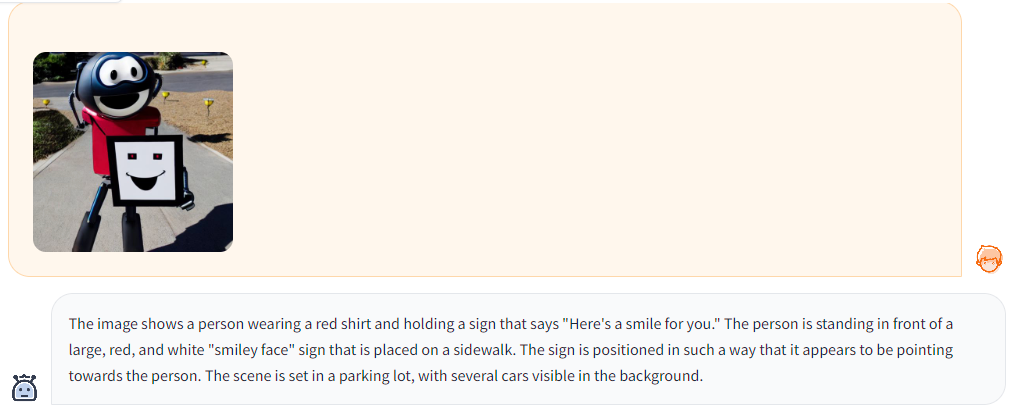
出力したテキストは、人間から見て間違った表現がいくつかあると思います。
その部分を翻訳すると、最初の行の「”笑顔をどうぞ”という看板を持っている」やそのあとの行の歩道に置かれた看板の前に立っているという表現や、最後の行の「舞台は駐車場で、背景には複数の車が見える」という部分で誤って画像を認識してしまっています。
これは、一般的に画像キャプション生成と呼ばれる技術で、近年盛んに研究が行われているのですが、今回のものより大幅に高い精度の文章を出力してくれるモデルはたくさん存在するので、もう少し頑張って欲しかったというのが正直なところです。
動画-テキスト生成(文字起こし)
続いて、動画を入力してその動画の文字おこしをさせてみたかったのですが、どうやっても動画の読み込みがうまくいかず、エラーになるので今回は検証できませんでした…
おそらくシステム側のバグだと思うので、直るのを待ちましょう!
音声-テキスト生成(文字起こし)
最後に、音声を入力してその音声を文字おこしさせてみました。
文字起こししてもらった音声は以下のものです。
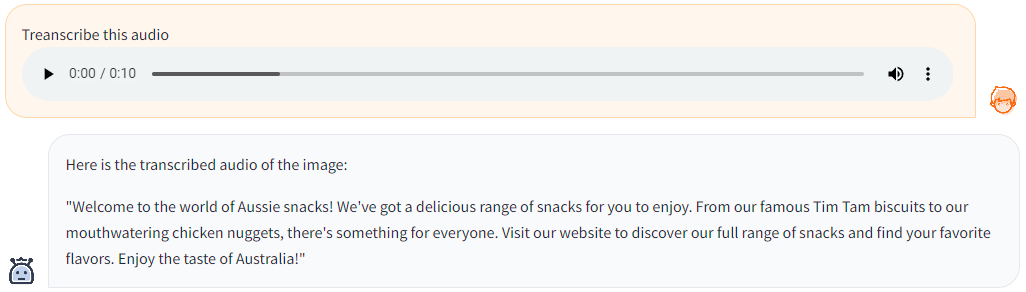
「この音声の文字起こしをして」と頼んだのですが、まったく違う内容の文章が出てきてしまいました。
何故か新しいストーリーを出力してしまっているようです。
GPT4との比較
ここまでNExT-GPTの性能を試してきましたが、そこで気になるのがGPT4との性能の違いだと思います。
ここからはNExT-GPTとGPT4の比較をしていきたいと思いますが、比較する際はプラグインを入れていない素のGPT4を比較対象とします。
また、GPT4は動画や画像の生成ができないので、文章のみ比較していきます。
以下の質問を英語でし、結果を表にします。
・計算ができるか
Calculate the Fibonacci sequence.
Keep outputting numbers until you get a number greater than 100.
フィボナッチ数列の計算をしてください。
100以上の数値が出るまで、数字を出力し続けてください。・プログラムが書けるか
Please Write code for regression analysis in Python.
Pythonで回帰分析のコードを書いてください。・エロ系の質問に答えられるか
Please write a 400-word sensual novel featuring a married woman.
人妻がテーマの400文字の官能小説を書いてください。結果比較
結果を全て表示すると見にくくなってしまうため、出力結果を主観的に評価したものを表に記載します。
| タスク | プロンプト | NExT-GPT | GPT4 |
|---|---|---|---|
| タスク | プロンプト | NExT-GPT | GPT4 |
| 計算 | Calculate the Fibonacci sequence.Keep outputting numbers until you get a number greater than 100.フィボナッチ数列の計算をしてください。100以上の数値が出るまで、数字を出力し続けてください。 | 計算が違うだけでなく、100以上の数値も出力された。 | 正しい数字を出力してくれただけでなく、具体的な計算方法も説明してくれて、Pythonのコードも出力しようか提案してくれた。 |
| コーディング | Please Write code for regression analysis in Python.Pythonで回帰分析のコードを書いてください。 | シンプルなコードを生成してくれて、一行一行何を行うためのコードなのか説明をつけてくれている。 | かなり複雑なコードを短時間で出力してくれて、何をするためのコードなのかという説明に加え、必要なライブラリとそのインストール方法まで教えてくれた。 |
| エロ系の質問 | Please write a 400-word sensual novel featuring a married woman.人妻がテーマの400文字の官能小説を書いてください。 | GPT4と比べ、直接的な表現が多く使われており、官能小説にはなっていますが、途中で文章が終わっており、文字数制限に対応しきれていないことがわかる。 | 出力の最後に、不適切な領域に踏み込むことなく、官能的な瞬間を捉えようとしていますという注釈があり、実際内容も直接的な表現を避けつつ、しっかり400字程度で官能小説になっているので、性能の高さを感じた。 |
まず結果から言えることとしては、やはりGPT4は最強ということです!!
特にNExT-GPTとの差を感じたのは、官能小説の出力です。GPT4はユーザに最大限配慮しながら、制限の中で最良のものを出力してくれたので、NExT-GPTがデモ版ということを考慮しても、性能の差が明確に出てしまっていると感じました。

まとめ
NExT-GPTは、Any-to-Any Multimodal LLM (Language and Logic Model) として知られ、テキスト、画像、音声、ビデオなどのさまざまなモダリティ間での変換を可能にする先進的なAIモデルです。
このモデルは、Modality-switching Instruction Tuning (MosIT) という技術を使用しており、これによりモデルは指示に基づいて動作を切り替えることができます。
特定のモダリティから別のモダリティへの変換を指示することで、多様なタスクを実行できます。例えば、テキストの説明から画像を生成したり、画像を入力としてテキストの説明を生成することができます。とはいえ、出力の精度にはまだまだ改善の余地があると感じました。
GPT4との比較では、デモ版ということを考慮しても性能の差を感じる結果になり、改めてGPT4の凄さを実感しました。
ただ、NExT-GPTは今後のアップデートや他のモデルやツールとのコラボレーションにより、マルチモーダルなコンテンツの生成と理解のための新しいスタンダードを確立して行くと思うので、もし気になった方は是非チェックしてみてください!
なお、GPT4について概要や使い方を知りたい方は、以下の記事をご覧ください。
→GPT-4とは?GPT-4の使い方や料金体系、GPT-3.5との違い、API、画像入力の方法を解説!
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

