
【PLaMo-13B】日英対応できる国産LLM登場!日本最先端のAIを比較レビューしてみた

皆さんは、PLaMo-13BというLLMをご存じですか?
2023年9月28日に公開されたばかりで、約130億個のパラメータからなる、日本語と英語に特化した日本発のLLMなんです!
噂によると、Weblab-10BやLlama 2に匹敵する性能だとか…!
日本語に特化してくれているのは、我々日本人からするととても嬉しいですよね。
今回は、PLaMo-13Bの概要や性能、他のLLMとの比較をご紹介します。
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
PLaMo-13Bの概要
PLaMo-13Bは、日本のPreferred Networksが開発した約130億個のパラメータを持つ大規模事前学習済み言語モデルです。
このモデルは、2023年9月28日に公開されたばかりの最新のモデルで、日本語と英語に特化して学習されており、同規模の他のLLMと比較して、日本語と英語能力で世界トップクラスの性能を有しています。
そんなPLaMo-13Bには、以下のような特徴があります。
ライセンス:Apache License Version 2.0で公開されており、誰でも研究や商用利用が可能なオープンソースソフトウェアとして提供されています。
日本語・英語能力:現在公開されている同規模のパラメータ数の事前学習済み言語モデルと比較して、日本語と英語の2言語を合わせた能力で、世界トップクラスの高い性能を示しています。
データセット:Preferred Networksは公開データセットのみを独自に収集・加工し、1.4兆トークンの日英2言語のデータセットを作成し、PLaMo-13Bに学習させました。その結果、高い日本語・英語能力を獲得しました。
学習:PLaMo-13Bの学習は、分散学習やデータ量子化などの様々な工夫によって効率的に学習され、学習に必要なリソースや時間を削減する手法を開発しています。
パラメータ数:130億のパラメータを持っており、現在ではコンパクトといえるサイズのモデルでありながら、日英2言語のベンチマークで高い性能を実現しています。このモデルは、一般的なコンシューマー向けGPUでも利用可能です。
これまで、LLMといえば海外で作られたものが主流で、特にOSSのものでは日本語に対応していないものが多かったですが、やはり日本で使うには日本語に対応したものを使いたいので、日本語と英語特化のPLaMo-13Bは、痒い所に手が届く、そんなLLMですね!
ただ、世界トップクラスの能力と言われてもいまいちピンとこない方が多いと思うので、ここからはPLaMo-13Bの性能と、他の同規模のLLMと実際に使ってみての比較を見ていきましょう。
なお、その他の日本語対応LLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【やってみた】Japanese Stable LM Alpha、Stability AIの日本語言語モデルを実践解説
PLaMo-13Bの性能
今回は、以下のPreferred Networks公式ドキュメントを参考に、性能を紹介していきます。
参考サイト:Plamo-13Bを公開しました
まずは、こちらのグラフをご覧ください。
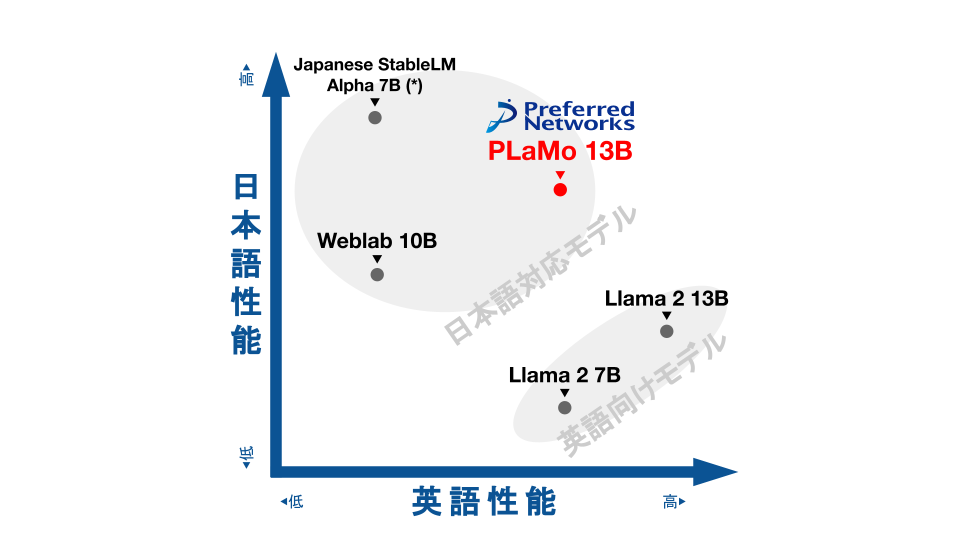
こちらのグラフは、同規模の日本語対応モデルおよび英語向けモデルとPLaMo-13Bのベンチマークスコアから算出された日本語・英語性能を分かりやすくしたものです。
これを見ると、PLaMo-13Bが日本語と英語どちらの能力も高いレベルでバランスよく持っていることが分かります。
次に、各LLMのベンチマークスコアの表をご覧ください。
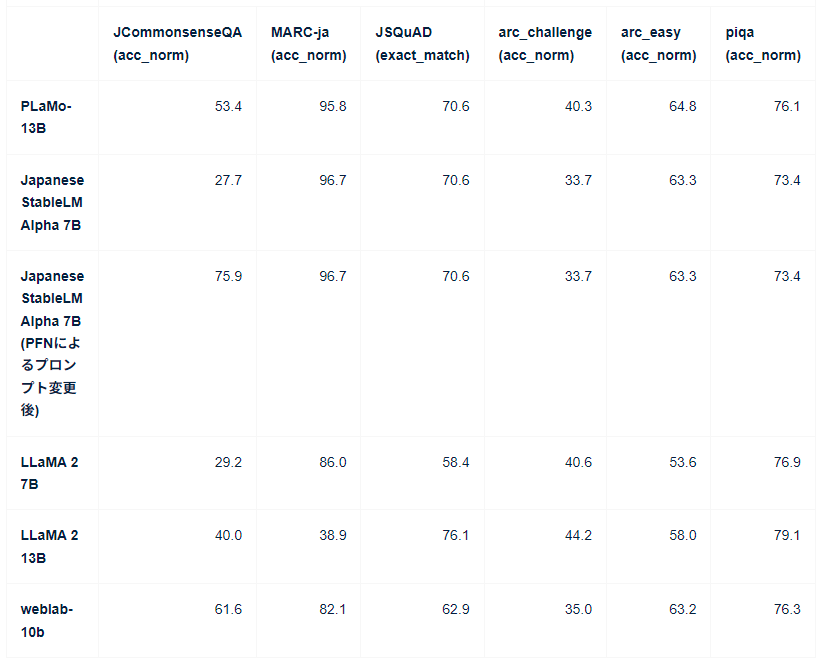
この結果から、開発者の方は以下のような考察をしています。
- 日本語のベンチマークにおいて、日本語を学習したその他のLLMと同等程度の性能を持つ
- 英語のベンチマークにおいて、Llama7Bと同等程度の性能を持つ
- Llama2 13Bと比較すると英語ベンチマークは劣る
日本語においても、英語においても半分程度の規模のLLMと同じくらいの性能なので、やはり複数言語を学習させるのは簡単な事ではないという印象を受けました。
ただ、今回比較対象とされているJapanese StableLM Instruct Alpha 7BやWeblab-10Bは、日本語LLMとしては最大規模なので、それらと遜色ない日本語性能を持ちながら、それら以上の英語性能を持っているPLaMo-13Bは、高性能と言えます。
英語性能が高性能な理由は、英語のデータセットを多く学習していることも関係していそうです。

さて、性能の紹介はこのくらいにして、実際にPLaMo-13Bを使っていきましょう!
もっと詳しく性能や仕組みについて知りたい方は、公式ドキュメントをご覧ください。
それではまずは使い方から紹介します。

PLaMo-13Bの導入方法
以下の公式Hugging Faceを参考に導入していきます。

PLaMo-13Bの実行には、A100GPUが必要なので今回はGoogle Colab Proを使用していきます。

まず、ノートブックを新規作成し、編集→ノートブックの設定からA100GPUを指定します。
まずTransformersをインストールします。
pip install transformers>=4.32.0次に以下のコードを実行してモデルをロードしてください。
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("pfnet/plamo-13b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("pfnet/plamo-13b", trust_remote_code=True)
text = "これからの人工知能技術は"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_tokens = model.generate(
inputs=input_ids,
max_new_tokens=32,
do_sample=True,
top_k=50,
top_p=0.95,
temperature=1.0,
)[0]
generated_text = tokenizer.decode(generated_tokens)
print(generated_text)これで導入が完了です。
今回は以下のような文章を出力してくれました。
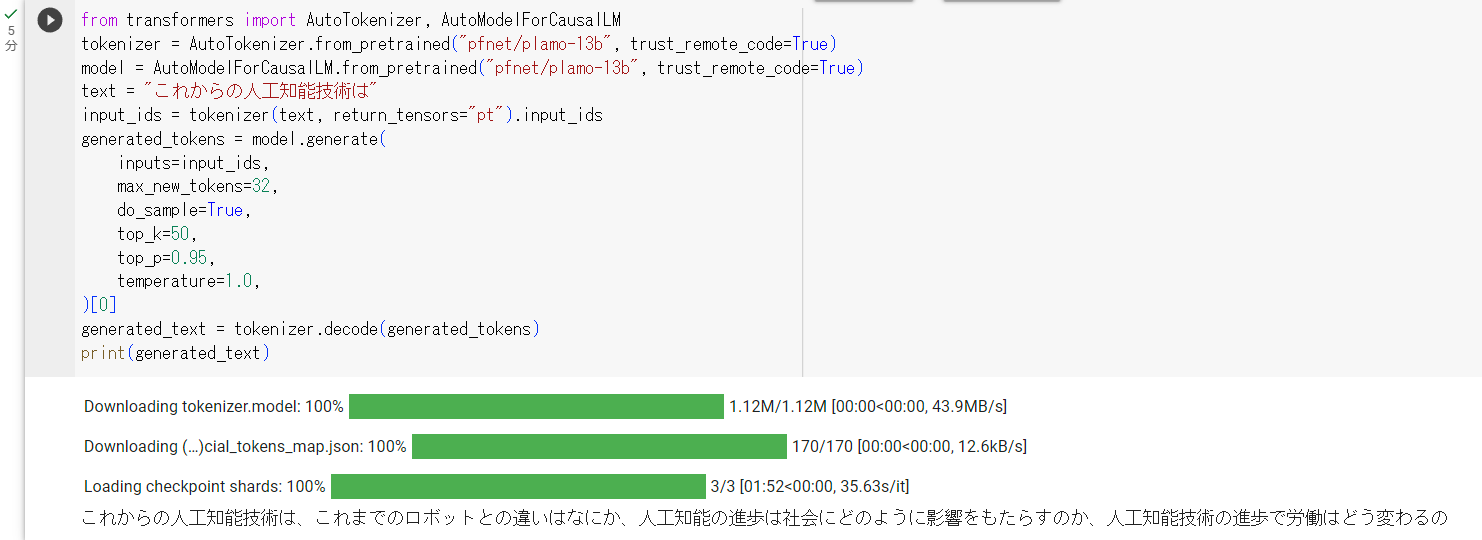
文章が途中で切れているのは、トークン数を絞っているので仕方がないですが、この短い文章を出力するのに5分もかかっていることが気になります。
では無事に導入することができたので、他のLLMとの比較をしていきましょう!
なお、この後の比較でも紹介するWeblab-10Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【日本語版LLM】東大松尾研のWeblab-10b、使い方・実践をまとめて解説
PLaMo-13Bの推しポイントである日本語・英語性能は本当に高性能なのか?
今回は、日本語対応のLLMであるWeblab-10Bと、Llama2-13Bをベースにして日本語と英語出力に対応しているXwin-LM-13Bとの比較を行っていきます。
以下のプロンプトを日本語とそれと同じ意味の英語を入力して出力結果を比較します。
日本語:あなたの自己紹介をして
英語:Introduce yourself.
日本語:クライアントに送信する丁寧語・謙譲語を正しく使用したビジネスメールを作成してください。
英語:Compose a polite business email to be sent to a client in English.
日本語:間違って理解されてしまうという意味の言葉は何?
英語:What word means to be understood incorrectly?
それでは早速比較していきましょう。
あなたの自己紹介をして
私の意図としては、AI自身の自己紹介をしてほしかったのですが、どれも架空の人物を作ってその自己紹介を生成してしまいました。
PLaMo-13B
日本語

全く見当違いの文章が生成されてしまった。
英語

特に指示してはいないが、シナリオを自動的に生成して、大学生が自己紹介している場面が生成された。
意図した回答ではなかったが、文章がしっかりしていて、シナリオを生成する能力が高そうです。
Xwin-LM-13B
日本語

私の意図とは違いますが、かなり自然な日本語で驚きました。
英語

こちらも自然な自己紹介になっています。
Weblab-10B
日本語

これも不自然な日本語で、英語を直訳した感じがあります。
英語
こちらは少しぎこちない感じはありますが、日本語のものよりはましです。
クライアントに送信する丁寧語・謙譲語を正しく使用したビジネスメールを作成してください。
PLaMo-13B
日本語

メールの作成ではなく、メール作成のアドバイスが出力されました。
3つのなかで唯一意図していない回答を出力しましたが、文章自体は自然で分かりやすい。
英語

長くて少し見にくいですが、こちらもアドバイスが出力されました。
文章自体は、詳しくて分かりやすいです。
Xwin-LM-13B
日本語

「お疑問」などの少しおかしなワードはありますが、少し直せばそのまま使えそうなほどのものを生成してくれました。
英語

こちらもほぼそのまま使えそうなほどのものを生成してくれました。
Weblab-10B
日本語

すごい直訳感があり、かなり違和感のある日本語です。
英語

英語の方は短いですが、それなりのものを生成してくれています。
間違って理解されてしまうという意味の漢字2文字の言葉は何?
正解は「誤解」と「misunderstood」です。
PLaMo-13B
日本語

正解!
英語

正解!
Xwin-LM-13B
日本語

惜しい笑
英語

正解!
Weblab-10B
日本語

正解!
英語

何か長々と生成されました。不正解!
考察
これらの結果を総合的に見ると、日本語・英語性能ともにXwin-LM-13Bが最も優秀だと感じました。
Xwin-LM-13Bは、日本語に特化しているわけではないですが、とても自然な日本語で、ほとんどの場合でユーザーの意図を汲んだものを生成してくれます。
Weblab-10Bは、日本語性能に重きを置いているはずですが、生成されたものは、英語を直訳したようなぎこちない日本語だったので、正直日本語より英語での出力の方がより自然な文章でした。
PLaMo-13Bに関しては、こちらの意図しない出力をすることが多かったですが、日本語の文章はこの3つのモデルの中で一番自然だと感じました。なので、入力を認識する部分の能力がもっと良くなると、より強力なLLMになると思います。
PLaMo-13Bのこれからに期待!
PLaMo-13Bは、日本のPreferred Networksが開発した約130億個のパラメータを持つ大規模事前学習済み言語モデルです。
このモデルは、日本語と英語の能力に重きをおいており、ベンチマークスコアでは、同規模のLLMと比較して、世界トップクラスの日本語・英語性能を有しています。
しかし、実際の性能比較ではユーザーの意図していない回答をすることが多く、他のLLMと比較して、文章自体は非常に自然ですが、入力を理解する能力が少し低く、現実的な性能はベンチマークスコアほど高くはないと感じました。
今後、さらに強力なモデルの開発が行われる予定なので、期待しましょう!

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

