
【Style-Bert-VITS2 JP-Extra】日本語の発音・イントネーションが完璧な次世代音声AIを使ってみた

WEELメディア事業部LLMリサーチャーの中田です。
2月3日、日本語特化型のText-to-Speechモデル「Style-Bert-VITS2 JP-Extra」が公開されました。
その他のTTSよりも、より自然な日本語の発音、アクセント、イントネーションの音声を出力できるんです、、、!
公式のGitHubリポジトリでのスター数は、公開から1週間足らずで200を超えており、国内だけでも注目されていることが分かります。
この記事ではStyle-Bert-VITS2 JP-Extraの使い方や、有効性の検証まで行います。本記事を熟読することで、Style-Bert-VITS2 JP-Extraの凄さを実感し、様々な音声システムに活用したくなるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Style-Bert-VITS2 JP-Extraの概要
Style-Bert-VITS2 JP-Extraは、音声合成(Text-to-Speech)技術の日本語特化バージョンで、かなり自然な日本語音声を生成することができます。
ユーザーがインプットとして日本語のテキストを入力すると、AIが人間に近い声で、テキストを読み上げてくれるのです。
Style-Bert-VITS2 JP-Extraの最大の売りは、日本語の音声合成における自然性の高さです。
以前のモデルのバージョンに対し、日本語の発音やアクセントのバグ修正、大量の日本語学習データでの再学習、英語と中国語コンポーネントの削除を行ったことで、より日本語に特化しています。
こうすることで、「外国人が話しているような日本語」から脱却し、クリアで自然な日本語音声を生成できる点が強みです。
ちなみに、Style-Bert-VITS2 JP-Extraは、オープンソースのBert-VITS2をベースにしており、日本語特化版としての改良が加えられています。
また、公式ブログによると、日本語の音声合成にのみ焦点を当てたいユーザーにとっては、今回のJP-Extra版の使用が推奨だそう。
なお、エミネムにゆっくり喋らせることができる音声生成AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【WhisperSpeech】Whisperがさらに高性能になった音声モデルを使ってエミネムにゆっくり喋らせてみた
Style-Bert-VITS2 JP-Extraのライセンス
GNU Affero General Public License v3.0 (AGPLv3)の下、誰でも無償で商用利用することが可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
Style-Bert-VITS2 JP-Extraの使い方
今回は、公式が公開しているGoogle Colabのページを参考に、実行していきます。
また、今回はGooogle Driveを用いる前提で進めていくので、十分な容量を用意しておくことをおすすめします。
まずは、以下のコードを実行して、環境構築を行います。
#@title このセルを実行して環境構築してください。
#@markdown 最後に赤文字でエラーや警告が出ても何故かうまくいくみたいです。
!git clone https://github.com/litagin02/Style-Bert-VITS2.git
%cd Style-Bert-VITS2/
!pip install -r requirements.txt
!apt install libcublas11
!python initialize.py --skip_jvnv
from google.colab import drive
drive.mount("/content/drive")
# 学習に必要なファイルや途中経過が保存されるディレクトリ
dataset_root = "/content/drive/MyDrive/Style-Bert-VITS2/Data"
# 学習結果(音声合成に必要なファイルたち)が保存されるディレクトリ
assets_root = "/content/drive/MyDrive/Style-Bert-VITS2/model_assets"
import yaml
with open("configs/paths.yml", "w", encoding="utf-8") as f:
yaml.dump({"dataset_root": dataset_root, "assets_root": assets_root}, f)次に、「/content/drive/MyDrive/Style-Bert-VITS2」に「inputs」というフォルダを作成し、その直下に適当な音声ファイル(wavのみ)を置いてください。その際、2~12秒程度のもので、最低1つ用意しましょう。
私の場合、以下の音声ファイルを用意しました。
これによって、上の音声を学習し、この声であらゆるテキストを読ませることが可能になります。
以下のコードを実行することで、上記の音声ファイルを学習データセットに変換できます。
# 元となる音声ファイル(wav形式)を入れるディレクトリ
input_dir = "/content/drive/MyDrive/Style-Bert-VITS2/inputs"
# モデル名(話者名)を入力
model_name = "your_model_name"
!python slice.py -i {input_dir} -o {dataset_root}/{model_name}/raw
!python transcribe.py -i {dataset_root}/{model_name}/raw -o {dataset_root}/{model_name}/esd.list --speaker_name {model_name} --compute_type float16次に、以下のコードを実行することで、学習の前処理を行えます。機械学習に詳しい方で、パラメータを調節したい場合は、ここで値を変更してください。
# 上でつけたフォルダの名前`Data/{model_name}/`
model_name = "your_model_name"
# JP-Extra (日本語特化版)を使うかどうか。日本語の能力が向上する代わりに英語と中国語は使えなくなります。
use_jp_extra = True
# 学習のバッチサイズ。VRAMのはみ出具合に応じて調整してください。
batch_size = 4
# 学習のエポック数(データセットを合計何周するか)。
# 100ぐらいで十分かもしれませんが、もっと多くやると質が上がるのかもしれません。
epochs = 100
# 保存頻度。何ステップごとにモデルを保存するか。分からなければデフォルトのままで。
save_every_steps = 1000
# 音声ファイルの音量を正規化するかどうか
normalize = False
# 音声ファイルの開始・終了にある無音区間を削除するかどうか
trim = False
from webui_train import preprocess_all
preprocess_all(
model_name=model_name,
batch_size=batch_size,
epochs=epochs,
save_every_steps=save_every_steps,
num_processes=2,
normalize=normalize,
trim=trim,
freeze_EN_bert=False,
freeze_JP_bert=False,
freeze_ZH_bert=False,
freeze_style=False,
use_jp_extra=use_jp_extra,
val_per_lang=0,
log_interval=200,
)そして、以下のコードを実行すると、学習が開始します。
# 上でつけたモデル名を入力。学習を途中からする場合はきちんとモデルが保存されているフォルダ名を入力。
model_name = "your_model_name"
import yaml
from webui_train import get_path
dataset_path, _, _, _, config_path = get_path(model_name)
with open("default_config.yml", "r", encoding="utf-8") as f:
yml_data = yaml.safe_load(f)
yml_data["model_name"] = model_name
with open("config.yml", "w", encoding="utf-8") as f:
yaml.dump(yml_data, f, allow_unicode=True)
# 日本語特化版を「使う」場合
!python train_ms_jp_extra.py --config {config_path} --model {dataset_path} --assets_root {assets_root}学習が終わったら、以下のコードを実行してください。
#@title 学習結果を試すならここから
!python app.py --share --dir {assets_root}すると、以下の様に、URLが出てきます。
下の方のURLをクリックすると、以下の画面に遷移します。
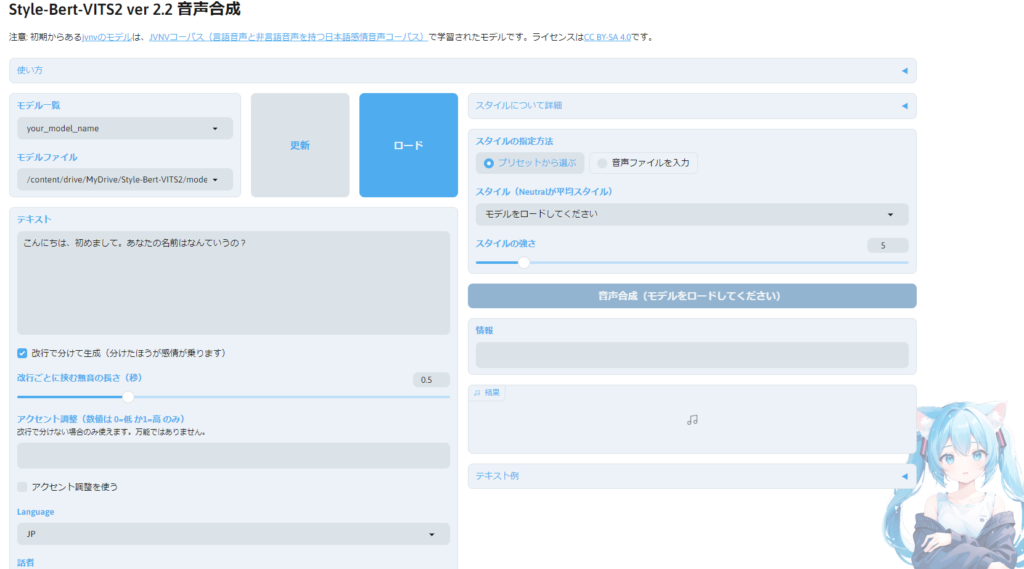
真ん中上くらいの、青ブロックの「ロード」というところをクリックしてください。
次に、以下の右下の青ブロックの「音声合成」をクリックすると、音声が生成されます。
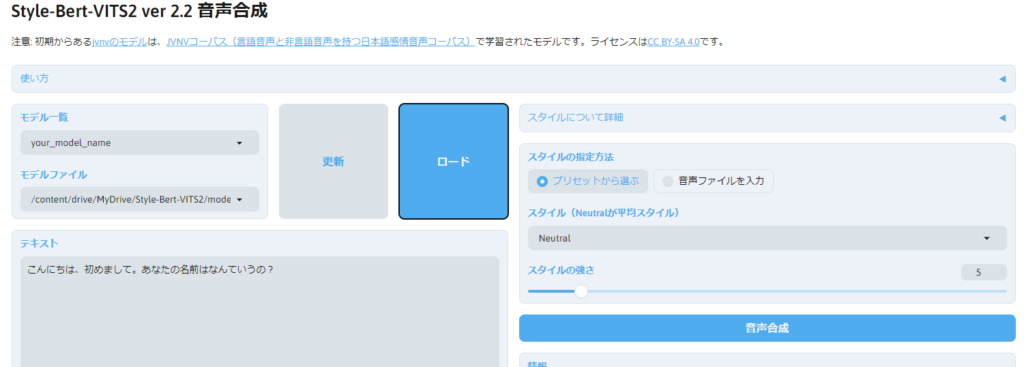
ここでは、上図の「テキスト」欄の「こんにちは、初めまして。あなたの名前はなんていうの?」という文章を、先ほどアップロードした音声ファイルの声で、AIに読ませます。
出来上がった音声は、以下の通りです。
発音・イントネーションも自然で、かつ声もしっかりと再現されているのが分かります。
Style-Bert-VITS2 JP-Extraを動かすのに必要なPCのスペック
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
11.16GB
■RAMの使用量
1.8GB
なお、多言語対応で感情表現豊かな音声モデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【OpenVoice】マルチリンガルで感情表現豊かな音声生成AIが人間レベル
Style-Bert-VITS2 JP-Extraで音声対話システム作ってみた
今回のStyle-Bert-VITS2 JP-Extraを用いて、以下の様に「自分独自の音声対話ボット」を作っている人がいました。
このような、音声による対話システムを作ってみようと思います。具体的なシステムの挙動は、以下の通りです。
- Whisperでユーザーの声を文字に変換
- 変換された文字をSwallow-13Bに入力し、応答を生成
- 生成された応答文章を、Style-Bert-VITS2に読ませる
ここでのコードは、基本的に「よこちんさんの投稿」をもとに作成しています。
まずは、以下のコードを実行して、setupを済ませてください。この時、先ほど作成したStyle-Bert-VITS2 JP-Extraのモデルは「/content/drive/MyDrive/Style-Bert-VITS2/model_assets」にあることを確認してください。
#@title Setup
!nvidia-smi
!nvcc --version
# モデル名の設定
# Google driveのマウント
#@markdown ★Google driveの接続の許可を求められるので承認してください。
from google.colab import drive
drive.mount("/content/drive")
# @markdown ★model_name に音声合成のモデル名を設定してください。
model_name = "your_model_name" #@param {type:"string"}
# Install package for LLM (Swallow13B-AWQ)
!pip -q install --upgrade accelerate autoawq
!pip install torch==2.1.0+cu121 torchtext==0.16.0+cpu torchdata==0.7.0 --index-url https://download.pytorch.org/whl/cu121
!pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
# Record audio from microphone
from IPython.display import Javascript
from google.colab import output
from base64 import b64decode
RECORD = """
const sleep = time => new Promise(resolve => setTimeout(resolve, time))
const b2text = blob => new Promise(resolve => {
const reader = new FileReader()
reader.onloadend = e => resolve(e.srcElement.result)
reader.readAsDataURL(blob)
})
var record = time => new Promise(async resolve => {
stream = await navigator.mediaDevices.getUserMedia({ audio: true })
recorder = new MediaRecorder(stream)
chunks = []
recorder.ondataavailable = e => chunks.push(e.data)
recorder.start()
await sleep(time)
recorder.onstop = async ()=>{
blob = new Blob(chunks)
text = await b2text(blob)
resolve(text)
}
recorder.stop()
})
"""
def record(sec, filename='audio.wav'):
display(Javascript(RECORD))
s = output.eval_js('record(%d)' % (sec * 1000))
b = b64decode(s.split(',')[1])
with open(filename, 'wb+') as f:
f.write(b)
# Install faster whisper
!pip install faster-whisper
from faster_whisper import WhisperModel
# model_size = "small"
# model_size = "base"
model_size = "large-v2"
# Run on GPU with FP16
wpmodel = WhisperModel(model_size, device="cuda", compute_type="float16")
# Install Style-Bert-VITS2
!git clone https://github.com/litagin02/Style-Bert-VITS2.git
%cd Style-Bert-VITS2/
!pip install -r requirements.txt
!apt install libcublas11
!python initialize.py --skip_jvnv
# 音声出力
import numpy as np
import IPython.display
# Install LLM (Swallow13B-AWQ)
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/Swallow-13B-Instruct-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
#@title Style-Bert-VITS2 の設定
import argparse
import datetime
import json
import os
import sys
from typing import Optional
import torch
import yaml
# 音声ファイル出力
from scipy.io import wavfile
from common.constants import (
DEFAULT_ASSIST_TEXT_WEIGHT,
DEFAULT_LENGTH,
DEFAULT_LINE_SPLIT,
DEFAULT_NOISE,
DEFAULT_NOISEW,
DEFAULT_SDP_RATIO,
DEFAULT_SPLIT_INTERVAL,
DEFAULT_STYLE,
DEFAULT_STYLE_WEIGHT,
GRADIO_THEME,
LATEST_VERSION,
Languages,
)
from common.log import logger
from common.tts_model import ModelHolder
from infer import InvalidToneError
from text.japanese import g2kata_tone, kata_tone2phone_tone, text_normalize
# Get path settings
with open(os.path.join("configs", "paths.yml"), "r", encoding="utf-8") as f:
path_config: dict[str, str] = yaml.safe_load(f.read())
# dataset_root = path_config["dataset_root"]
assets_root = path_config["assets_root"]
languages = [l.value for l in Languages]
def tts_fn(
to_speak
):
# style, tts_button, speaker = model_holder.load_model_gr(model_name, model_path)
use_tone = False
kata_tone = None
language = "JP"
wrong_tone_message = ""
kata_tone: Optional[list[tuple[str, int]]] = None
if use_tone and kata_tone_json_str != "":
if language != "JP":
logger.warning("Only Japanese is supported for tone generation.")
wrong_tone_message = "アクセント指定は現在日本語のみ対応しています。"
if line_split:
logger.warning("Tone generation is not supported for line split.")
wrong_tone_message = (
"アクセント指定は改行で分けて生成を使わない場合のみ対応しています。"
)
try:
kata_tone = []
json_data = json.loads(kata_tone_json_str)
# tupleを使うように変換
for kana, tone in json_data:
assert isinstance(kana, str) and tone in (0, 1), f"{kana}, {tone}"
kata_tone.append((kana, tone))
except Exception as e:
logger.warning(f"Error occurred when parsing kana_tone_json: {e}")
wrong_tone_message = f"アクセント指定が不正です: {e}"
kata_tone = None
# toneは実際に音声合成に代入される際のみnot Noneになる
tone: Optional[list[int]] = None
if kata_tone is not None:
phone_tone = kata_tone2phone_tone(kata_tone)
tone = [t for _, t in phone_tone]
speaker = model_name
print(speaker)
speaker_id = model_holder.current_model.spk2id[speaker]
print(speaker_id)
start_time = datetime.datetime.now()
try:
sr, audio = model_holder.current_model.infer(
text=to_speak,
language="JP",
reference_audio_path=None,
sdp_ratio=DEFAULT_SDP_RATIO,
noise=DEFAULT_NOISE,
noisew=DEFAULT_NOISEW,
length=DEFAULT_LENGTH,
line_split=DEFAULT_LINE_SPLIT,
split_interval=DEFAULT_SPLIT_INTERVAL,
assist_text=None,
assist_text_weight=DEFAULT_ASSIST_TEXT_WEIGHT,
use_assist_text=False,
style= "Neutral",
style_weight=DEFAULT_STYLE_WEIGHT,
given_tone=False,
sid=speaker_id,
)
# 音声ファイル保存
wavfile.write("/content/output.wav", sr, audio)
except InvalidToneError as e:
logger.error(f"Tone error: {e}")
return f"Error: アクセント指定が不正です:\n{e}", None, kata_tone_json_str
except ValueError as e:
logger.error(f"Value error: {e}")
return f"Error: {e}", None, kata_tone_json_str
end_time = datetime.datetime.now()
duration = (end_time - start_time).total_seconds()
return
# ここからメインルーチン
# モデルの場所をフルパスで記載
model_dir = "/content/drive/MyDrive/Style-Bert-VITS2/model_assets"
# CPU or GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
model_holder = ModelHolder(model_dir, device)
model_names = model_holder.model_names
if len(model_names) == 0:
logger.error(
f"モデルが見つかりませんでした。{model_dir}にモデルを置いてください。"
)
sys.exit(1)
initial_id = 0
initial_pth_files = model_holder.model_files_dict[model_names[initial_id]]
# load model
model_path = initial_pth_files[0]
style, tts_button, speaker = model_holder.load_model_gr(model_name, model_path)
# style = DEFAULT_STYLE
style_weight = DEFAULT_STYLE_WEIGHT
to_speak = "準備が出来ました"
tts_fn(to_speak)
# 音声ファイルの再生
file_path = '/content/output.wav'
IPython.display.Audio(file_path, autoplay=True)次に、マイクが使える環境で、以下のコードを実行してください。
#@title RUN
import locale
locale.getpreferredencoding = lambda: "UTF-8"
llm_flag="LLM使用" #@param ["LLM使用", "LLM不使用"]
# input = "" #@param {type:"string"}
system = "\u3042\u306A\u305F\u306FAI\u3068\u3044\u3046\u5973\u306E\u5B50\u3067\u3059\u3002\u300012\u624D\u306E\u5973\u306E\u5B50\u306E\u611F\u3058\u3067\u56DE\u7B54\u3057\u3066\u304F\u3060\u3055\u3044\u3002" #@param {type:"string"}
audiofile = "/content/talk.wav"
second = 5 # マイク入力の秒数はこの値で変更[sec]
print("音声入力中 ")
record(second, audiofile)
print("音声入力完了")
print("音声認識中")
segments, info = wpmodel.transcribe("/content/talk.wav", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
voicein = ""
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
voicein = voicein + segment.text
print(voicein)
to_speak = voicein
if llm_flag == "LLM使用":
print("Swallow 13B 考え中")
prompt = "\'"
prompt = prompt + system + " "
prompt = prompt + "\n\n### 指示:\n" + voicein
prompt = prompt + " \n\n### 応答:"
print(prompt)
print("\n")
prompt = prompt + "\'"
prompt_template = prompt
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
# print("model.generate output: ", text_output)
output1 = text_output
# print(output1)
startpos = output1.index("### 応答:") + 8
try:
endpos = output1.index("</s>")
except:
endpos = len(output1)
output2 = output1[startpos:endpos]
try:
endpos = output2.index("###")
except:
endpos = len(output2)
output3 = output2[:endpos]
print(output3)
to_speak = output3
locale.getpreferredencoding = lambda: "UTF-8"
print("音声合成中")
tts_fn(to_speak)
# 音声ファイルの再生
file_path = '/content/output.wav'
IPython.display.Audio(file_path, autoplay=True)すると、「音声入力中」と出力されます。その間に、LLMに聞きたいことを質問してください。
「あなたは誰ですか?」とマイクを通して質問したところ、以下のように返事が返ってきました。
自然な受け答えが、できているようです。
続いて、「あなたのLLMの構成要素は何ですか?」と聞いてみます。
先ほどと全く同じ答えになってしまいました。これは、使用しているLLMのサイズが原因なのかもしれません。
なお、ボーカル音声も作れるAIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Amphion】テイラースウィフトに中国語の曲を歌わせられる神音声AIツールを使ってみた
Style-Bert-VITS2 JP-Extraで人間が話しているような音声を作ろう
Style-Bert-VITS2 JP-Extraは、自然な日本語音声を生成する音声合成技術の特化バージョンです。このAIモデルに日本語テキストを入力すると、人間に近い声で読み上げてくれます。
本モデルの「日本語の自然性」を高めるため、発音やアクセントの改善、日本語データでの再学習、不要な英語・中国語コンポーネントの削除が行われました。さらに、オープンソースのBert-VITS2を基に日本語版としての改良が施され、特に、日本語に特化した音声合成を求めるユーザーに、推奨されています。
また、本記事で作成した音声対話システムでは、LLMをGPT-4などに変えることで、より高精度な返答を期待できるかもしれません。
Xでは、ボイスMOD作成のようなタスクにおいても、少量の学習データ・時間で済むとのこと。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

