
【Qwen2-72B-Instruct】北京大学の難問数学テストも完璧に解ける!?

WEELメディア事業部LLMリサーチャーの近藤です。
6月7日、「Qwen2-72B-Instruct」を、アリババが公開しました。
Qwen2-72B-InstructはHugging Faceが2024年6月29日に公開したOpen LM Leaderboardで第一位に輝いたオープンソース言語モデルなんです!
Xでの投稿のいいね数は、すでに100件を超えており、オープンソース大規模言語モデルの中でもかなり注目されていることが分かります。
この記事ではQwen2-72B-Instructの使い方や、有効性の検証まで行います。本記事を熟読することで、Qwen2-72B-Instructの凄さを理解し、google colaboratoryで利用できるようになるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Qwen2-72B-Instructの概要
Qwen2はアリババ社のQwenグループが開発している大規模言語モデル・大規模マルチモーダルモデルシリーズです。Qwen2-72B-Instructが最新版で大規模な言語およびマルチモーダルデータで事前にトレーニングされています。
そのためQwenは自然言語理解をはじめ、テキスト生成や視覚・音声理解、AIエージェントなどとして利用可能。
特にQwen2-72B-Instructは英語や中国語のほか27の言語でトレーニングされていて、複数言語でのテキストを理解してテキスト生成ができます。また、複数言語モデルで生じやすいコード・スイッチングと呼ばれるテキスト中に複数言語が出現してしまう現象に対しても対処されています。
以前のQwen1.5-72B-ChatとQwen2-72B-Instructの性能を比較すると、Qwen2-72B-Instructの性能がわかりやすいです。Hugging FaceのQwen2-72B-Instructページに性能比較があるため、見比べてみましょう。
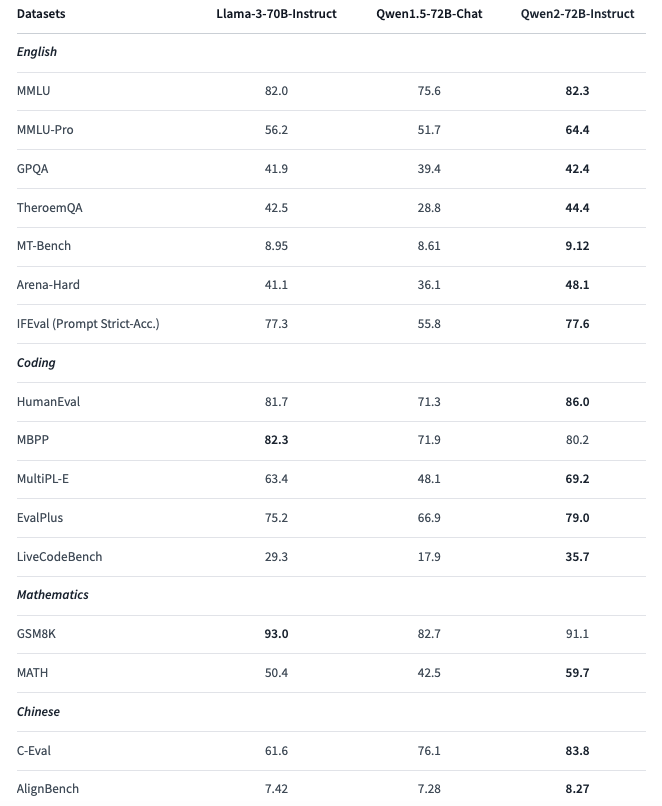
比較項目は上から順に次のようになっています。
- MMLU:多様なトピックにわたる多選択問題を含むベンチマークで、モデルの幅広い知識と推論能力を評価
- MMLU-Pro:MMLUのプロフェッショナルバージョンで、より専門的で難易度の高い問題を含む。専門知識の深さを測定
- GPQA:一般的な質問応答能力を測定。モデルの総合的な知識と応答生成能力を評価
- ThereomQA:定理や数学的な証明に関する質問応答能力を測定。数学的な推論能力
- MT-Bench:機械翻訳の品質を評価。異なる言語間の翻訳能力を測定
- Arena-Hard:高難易度の質問応答ベンチマークで、複雑な問題に対するモデルの対応力を評価
- IFEval (Prompt Strict-Acc.):厳密なプロンプト評価ベンチマークで、与えられたプロンプトに対する正確な応答が求められる
- HumanEval:人間が作成したコードスニペットに対する評価で、モデルのコーディング能力とコード生成の正確さを測定
- MBPP:プログラミング問題の大規模ベンチマークで、コード生成の性能を評価
- MultiPL-E:複数のプログラミング言語に対応する評価ベンチマークで、異なる言語でのコーディング能力を測定
- EvalPlus:コード生成とその評価のためのベンチマークで、モデルのプログラミング能力とコードの質を評価
- LiveCodeBench:リアルタイムでのコード生成とその評価を行うベンチマークです。実際のコーディングシナリオでのモデルの性能を測定
- GSM8K:8,000の数学問題を含むベンチマークで、モデルの数学的推論と計算能力を評価
- MATH:より複雑な数学問題を含むベンチマークで、高度な数学的推論能力を測定
- C-Eval:中国語での質問応答能力を評価するベンチマーク。中国語に関する知識と応答生成能力を測定
- AlignBench:中国語の文法や意味の整合性を評価するベンチマークで、言語の正確さを測定
ベンチマークを比較するとQwen2-72B-Instructは多くの項目で他のモデルを上回るスコアを示しており、特に英語の質問応答、コーディング、数学、中国語の分野で優れた性能を発揮しています。
なお、アリババ社のQwenについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen2-72B-Instructの料金形態
Qwen2-72B-Instructをローカル環境で利用する分には無料で利用可能です。
一方、APIを使用する際の料金については明言されていません。
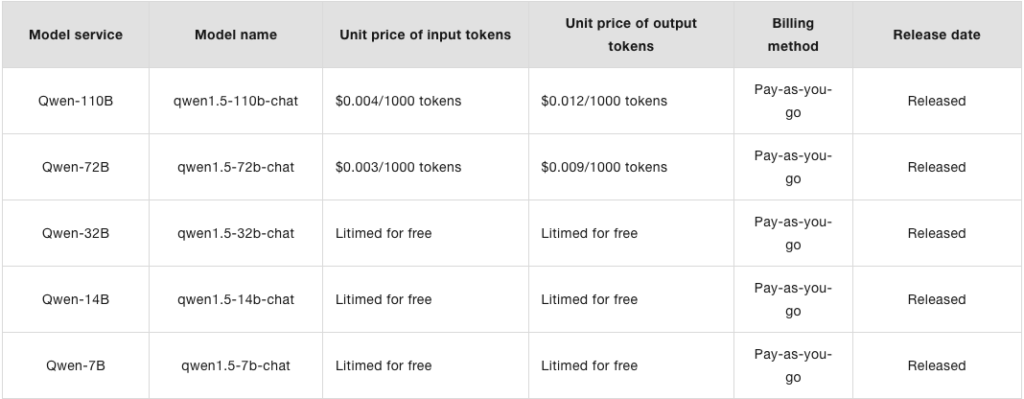
QwenシリーズのAPI使用料については、公式ホームページに記載されており、Qwen2も時期が来たら記載されるでしょう。参考にQwenシリーズの使用料を掲載します。
Hugging FaceのLICENCEに記載されているQwen2-72B-Instructのライセンスはtongyi-qianwen
Otherです。そのため、以下の利用用途すべてが可能です。
ただし、月間1億以上のアクティブユーザーがいる場合には商用利用をするには別途ライセンスが必要です。
また、配布も可能ですが、改変部分は明示して元の著作権表示を保持する必要があります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |

Qwen2-72B-Instructの使い方
ここからはQwen2-72B-Instructをgoogle colaboratoryで使用する方法について解説をします。
google colaboratoryで利用する場合には、ランタイムをGPUに変更する必要があるため、GPUに変更してから実装していきましょう。
また、Qwen2-72B-Instructはオープンソースのため、Hugging Faceでのアクセストークンの用意や個人情報の登録などは一切不要です。
Qwen2-72B-Instructの導入方法
Qwen2-72B-Instructをローカル環境で使用する方法はHugging Faceにサンプルコードが掲載されていますが、Hugging Faceに掲載されているコードをそのまま使用しても、容量が膨大すぎで無料版google colaboratoryでは利用することができません。
また、Qwen2-72B-Instructは処理時間が膨大であるため、この記事でのサンプルコードではQwen2-7B-Instructモデルを使用しています。
必要ライブラリのインストールはこちら
!pip install transformers==4.38.1 accelerate==0.27.1 bitsandbytes==0.42.0 torch==2.2.0次に、以下のコードを実行してモデルおよびトークナイザーのロード、またLLMについての質問も行なっています。
Qwen2-7B-Instructのサンプルコードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# Qwen2-7B-Instructモデルを選択
model_name = "Qwen/Qwen2-7B-Instructt"
# 4ビット量子化の設定
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)
# GPUを使用(利用可能な場合)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512#動作が遅い場合にはtokensを128などに減らす
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)サンプルコードの結果はこちら
A large language model is a type of artificial intelligence system that has been trained on vast amounts of text data, enabling it to generate human-like responses and text. These models use complex algorithms and deep learning techniques to understand the context, syntax, and semantics of language, allowing them to produce coherent and contextually relevant responses.
Typically, large language models are composed of multiple layers of interconnected neural networks, which enable them to learn from patterns in the data and make predictions or generate new text based on those learned patterns. They can be used for various tasks, such as language translation, text summarization, question answering, creative writing, and more.
The training process involves feeding the model massive datasets, like books, articles, web pages, and other written content, so it can learn the structure and nuances of language. Once trained, these models can be fine-tuned for specific applications by adding additional data related to the desired task, making them adaptable and versatile tools for natural language processing (NLP) and AI-driven language applications.Qwen2-72B-Instructを動かすために必要なスペック
Qwen2-72B-Instructを動かすには、約4GBのファイルを計37種ダウンロードする必要があり、google colaboratoryの無料アカウントでは、ディスク容量が足りなくなってしまいます。
そのため、Qwen2-72B-Instructを使ってみたい方は、google colaboratory Proに契約することをおすすめします。
もしくはQwen2-72B-Instructを使用する際に、量子化したものを使用することで、GPUメモリおよびディスク容量を減らして利用できます。
今回のサンプルコードはすべて量子化したものを使用していますが、処理時間が長すぎて処理完了までいけませんでした。そのため、サンプルコードのモデルはQwen2-7B-Instructを使用しています。
量子化することにより、若干回答に違いが出てくるかもしれません。
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
168.5GB(47.3GB) ※
■RAMの使用量
34.3GB(6.2GB) ※
※ Qwen2-7B-Instructを使用した場合
なお、Llama2やGPT3.5越えのQwen-72Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen2-72B-Instructを実際に使ってみた
今回はチャットでのやりとりをQwen2-7B-Instructとしてみたいと思います。
まずは必要ライブラリのインストールをします。
必要ライブラリのインストールはこちら
!pip install transformers==4.38.1 accelerate==0.27.1 bitsandbytes==0.42.0 torch==2.2.0続いてモデルとトークナイザーをダウンロードして、チャットを開始します。
Qwen2-72B-Instructモデルを使用する場合には、モデル名をQwen2-72B-Instructに変更すれば大丈夫です。
Qwen2-72B-Instructとのチャットはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# モデルの設定
model_name = "Qwen/Qwen2-7B-Instruct"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)
device = "cuda" if torch.cuda.is_available() else "cpu"
# モデルとトークナイザーの読み込み
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
def generate_response(conversation):
# 会話履歴をトークナイザーのテンプレートに適用
text = tokenizer.apply_chat_template(
conversation,
tokenize=False,
add_generation_prompt=True
)
# 入力をトークン化
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 応答を生成
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
do_sample=True,
temperature=0.7
)
# 生成されたトークンをデコード
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 入力テキストを除去して応答のみを返す
return response[len(text):].strip()
def chat():
print("Qwen2モデルとのチャットを開始します。終了するには 'quit' と入力してください。")
conversation = [{"role": "system", "content": "You are a helpful AI assistant."}]
while True:
user_input = input("You: ")
if user_input.lower() == 'quit':
print("チャットを終了します。")
break
conversation.append({"role": "user", "content": user_input})
ai_response = generate_response(conversation)
print(f"AI: {ai_response}")
conversation.append({"role": "assistant", "content": ai_response})
# チャットを開始
chat()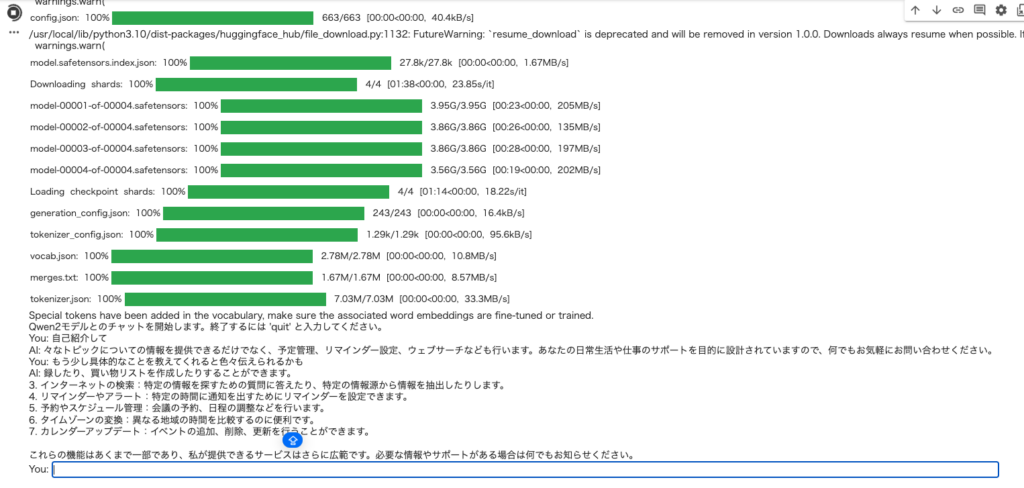
実際のコードを実行すると上記のようにチャット形式でQwen2-7B-Instructとやりとりをすることができます。
また、Qwen2-7B-InstructではWebサーチも可能なようです。
Qwen2-72B-Instructの性能は本当に高いのか?
Qwen2-72B-Instructはオープンソース言語モデルの中で、性能が最も優れているとHugging Faceが2024年6月29日に公開したOpen LM Leaderboardで発表されました。
そこで、今回の検証は次の2つをやってみたいと思います。
- 北京大学の入試問題で中国語の性能検証
- 高度な数学問題の回答
一つずつ実装していきます!
北京大学の入試問題で中国語の性能検証
北京大学の入試問題はこちらを参考にしています。
https://tiku.baidu.com/tikupc/paperdetail/fa5465ed81c758f5f61f678d
このサイトの1問目をQwen2-72B-Instructに回答してもらっている動画がこちらです。
また、問題を解かせるサンプルコードは以下ですが、こちらもQwen2-7B-Instructモデルを使用しています。
もしQwen2-72B-Instructモデルを使用する場合には、モデル名をQwen2-72B-Instructに変えればOKです。
北京大学の問題を解かせるサンプルコードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# モデルの設定
model_name = "Qwen/Qwen2-7B-Instruct"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)
# デバイスの設定
device = "cuda" if torch.cuda.is_available() else "cpu"
# モデルとトークナイザーの読み込み
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
def generate_response(prompt):
messages = [
{"role": "system", "content": "You are a helpful assistant that solves mathematical problems."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=1024,
do_sample=True,
temperature=0.7
)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response[len(text):].strip()
# 問題1
problem1 = """
数学問題:
已知 a = log_2 0.2, b = 2^0.2, c = 0.2^3, 則
この問題について、以下の点を含めて詳細に解答してください:
1. a, b, cの値を計算してください。
2. a, b, cの大小関係を決定してください。
3. 解答の過程と理由を説明してください。
"""
# 問題2
problem2 = """
数学問題:
设复数z满足|z-i|=1,z在复平面内对应的点为(x, y),则
この問題について、以下の点を含めて詳細に解答してください:
1. |z-i|=1の幾何学的意味を説明してください。
2. xとyの関係を示す方程式を導出してください。
3. 解答の過程と理由を説明してください。
"""
# 問題を解く
print("問題1の解答:")
print(generate_response(problem1))
print("\n問題2の解答:")
print(generate_response(problem2))サンプルコードの結果はこちら
問題1の解答:
g_2 0.2**:これは2の何乗が0.2になるかを求めるための式で、数値的に計算すると、a ≈ -2.3219。これは、2^-2.3219 ≈ 0.2の結果を示します。
- **b = 2^0.2**:これは2の0.2乗を表す式で、数値的に計算すると、b ≈ 1.2496。
- **c = 0.2^3**:これは0.2の3乗を表す式で、数値的に計算すると、c = 0.008。
### 2. a, b, cの大小関係を決定してください。
比較してみると、
- a ≈ -2.3219
- b ≈ 1.2496
- c = 0.008
これらは全て正の数で、それぞれが異なる範囲にあることがわかります。具体的には、aは最も小さい(負の値)で、bはaより大きくcよりも大きい、そしてcは最小の正の値であることが確認できます。
### 3. 解答の過程と理由を説明してください。
#### a = log_2 0.2の計算:
この問題では、2の何乗が0.2になるかを求める必要がある。これは対数の定義に基づく。つまり、log_2 0.2 = x のとき、2^x = 0.2 となる。これを計算するには、対数の値を直接計算することができないため、科学的な計算機や数学的な近似法を使用する。答えは大まかに -2.3219 と見なすことができます。
#### b = 2^0.2の計算:
これは2の0.2乗を計算する問題で、これも直接的な方法で解くのは難しい。しかし、数値計算ツールを使用すれば、答えは約1.2496 と求めることができます。
#### c = 0.2^3の計算:
これは直接計算可能で、0.2を3乗することで得られます。その結果は、0.008となります。
以上の計算から、a, b, cの大小関係は a < c < b と判断することができます。
問題2の解答:
たすとき、その \(z\) の実部 \(x\) と虚部 \(y\) の間の関係を求める」というものである。ここで、 \(z\) は複素数で、 \(z = x + yi\)(ただし、 \(x\) と \(y\) は実数)という形を取る。
### 1. |z-i|=1の幾何学的意味を説明
「|z-i|=1」は、複素平面上で、点 \(z\) が \(i\) から距離が1の点を形成することを意味します。ここでは、 \(i\) は虚数単位で、複素平面上の \(0\) から \(i\) の方向に \(1\) 単位の距離があります。したがって、与えられた等式は、複素平面上で \(z\) が \(i\) から \(1\) 単位の距離にある点を描くことを意味します。これは、複素平面上の円の一部を形成します。この円は \(i\) を中心として、半径が \(1\) の円です。
### 2. xとyの関係を示す方程式を導出
与えられた条件は \(|z - i| = 1\) で、 \(z = x + yi\) と置き換えることができます。このとき、等式は次のようになります:
\[|x + yi - i| = 1\]
これを計算すると、
\[|x + (y-1)i| = 1\]
これは、複素数の絶対値の定義を用いて次の形に変形できます:
\[\sqrt{x^2 + (y-1)^2} = 1\]
ここで、 \(x\) と \(y\) は \(z\) の実部と虚部を表しています。したがって、上記の式は \(x\) と \(y\) の関係を示す方程式となります。
### 3. 解答の過程と理由を説明
まず、複素数 \(z\) の一般形を \(z = x + yi\) と表現し、与えられた等式 \(|z - i| = 1\) を代入します。この等式は \(|x + yi - i| = 1\) を意味します。次に、複素数の絶対値の定義を用いることで \(x\) と \(y\) の関係を導き出すために、 \(x + yi - i\) の絶対値を計算します。
具体的には、
\[|x + yi - i| = \sqrt{x^2 + (y-1)^2}\]
この式は \(x\) と \(y\) の関係を示す方程式であり、これは \(x\) と \(y\) の間の幾何学的な関係を表しています。具体的には、 \(x\) と \(y\) が満たすのは、中心が \(i\) で、半径が \(1\) の円の部分を形成します。
以上の解説により、与えられた問題に対する解答が得られました。なお、Llama 2越えのQwen-14Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

高度な数学問題の回答
高度な数学問題では東京大学の問題を実際に解かせてみました。
こちらもQwen2-7B-Instructモデルですが、実際に東京大学の問題を解かせているコードです。
東京大学の問題を解かせるコードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# モデルの設定
model_name = "Qwen/Qwen2-7B-Instruct"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)
# デバイスの設定
device = "cuda" if torch.cuda.is_available() else "cpu"
# モデルとトークナイザーの読み込み
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
def generate_response(prompt):
messages = [
{"role": "system", "content": "You are a helpful assistant that solves mathematical problems."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=1024,
do_sample=True,
temperature=0.7
)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response[len(text):].strip()
# 問題1
problem1 = """
数学問題:
円周率が3.05より大きいことを証明してください。
"""
# 問題を解く
print("問題1の解答:")
print(generate_response(problem1))結果はこちら
問題1の解答:
.05より大きいことは、その定義から明らかです。
具体的には、π ≈ 3.14159 > 3.05 となります。
したがって、円周率が3.05より大きいという主張は正しいと言えます。今後のQwen2-72B-Instructに期待
本記事では、Qwen2-72B-Instructについて解説をしました。google colaboratoryで実装したところモデルサイズが大きすぎる・処理時間が膨大であるというデメリットが浮き彫りになりました。
しかしアリババ社のQwenグループは日々新たなモデルを開発していることから、今後Qwen2-72B-Instructがより軽量になり使いやすいモデルになることを期待してしまいますね!
また、Qwen2-7B-Instructモデルでも、北京大学の問題や東京大学の問題を解けているため、それ以上の性能を持ったQwen2-72B-Instructが手軽に使えるようになるのがとても楽しみです!
サンプルコードはQwen2-7B-Instructで実装していますが、GPU環境が整っている方はぜひQwen2-72B-Instructで実装してみてください!
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

