
Qwen2-Mathとは?大学入試レベルの数学問題を解けるLLMを解説

\生成AIを活用して業務プロセスを自動化/
Qwen2-Mathの概要
Qwen2-Mathは中国のアリババグループが開発した大規模言語モデルであり、数学の問題の正答率がかなり高いのが特徴。
学習データとして、Qwen2シリーズで生成した数学の関連情報を学習データに用いています。
Qen2-Mathはオープン・クローズモデルの両者を含めて、もっとも正答率の高い数学に特化したモデルです。
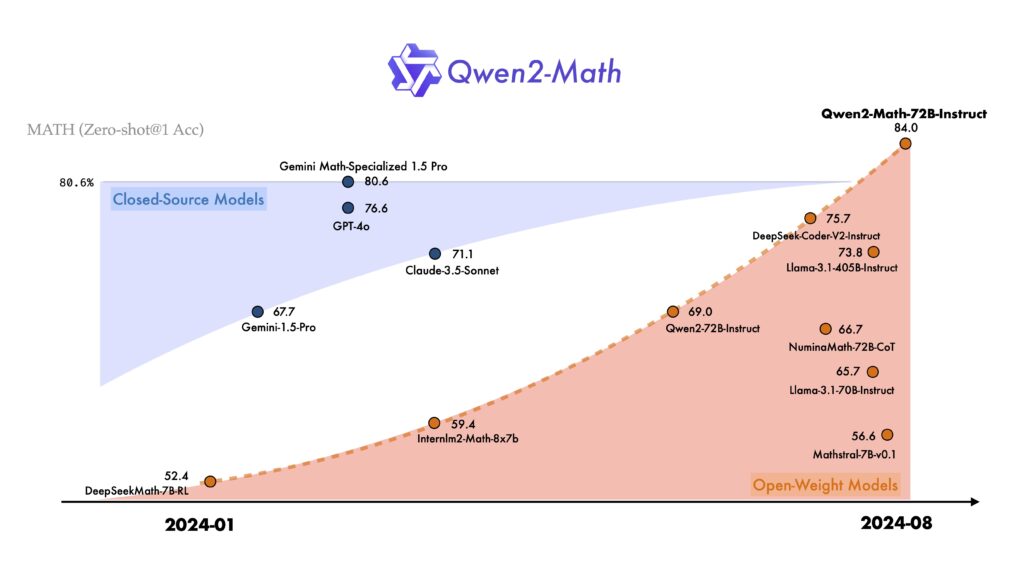
数学に特化したベンチマークでは、GPT-4oやCluade3.5-sonnet、Llama-3.1-405Bと比較して、最も良い成績を残したことも報告されています。やはり数学に特化している分、そのほかのモデルよりも性能が向上していることがよくわかります。
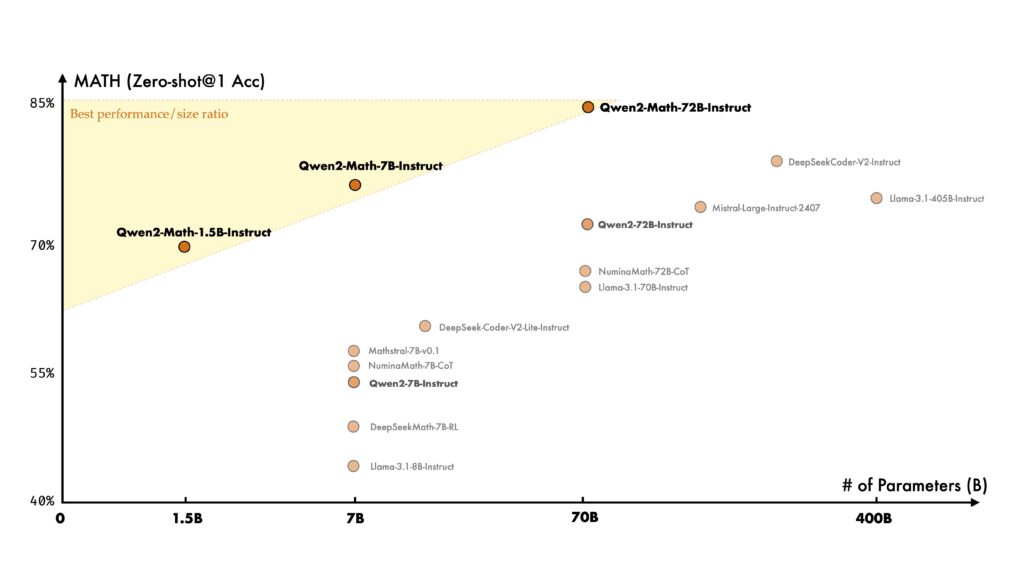
Qwen2-Mathのパフォーマンス
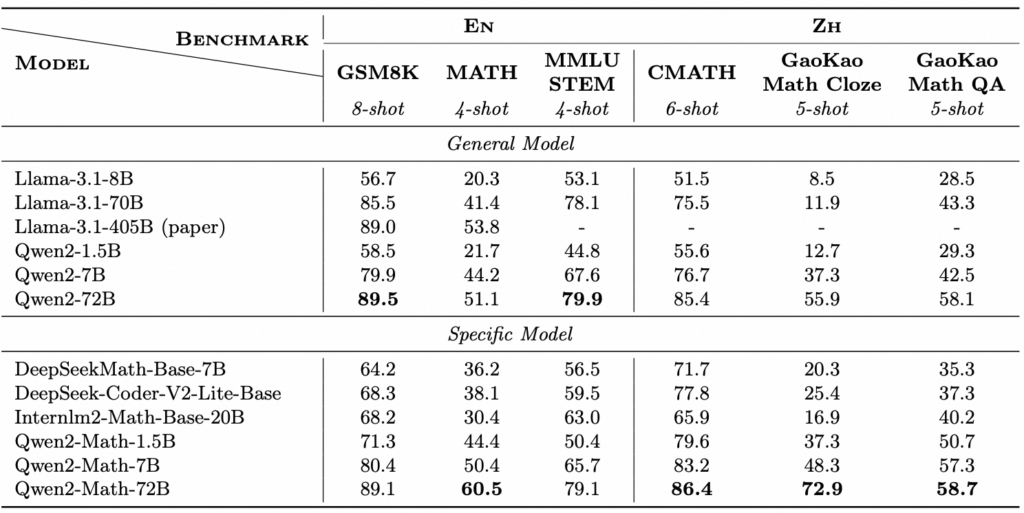
Qwen2-MathのパフォーマンスをGSM8K、Math、MMLU-STEMで英語で記載されている数学のベンチマークを、 CMATH、GaoKao Math Cloze、GaoKao Math QAを使って中国語で記載されている数学のベンチマークを評価。
その結果が下の表です。
General Modelは一般的な自然言語処理モデルであり、特定のタスクに特化していないモデルです。それに対してSpecific Modelは特定のタスクに特化したモデル間の比較であり、今回の場合は数学に特化したモデル同士の比較になります。
この結果から、General Modelの比較では次のような結果になりました。
- Llama-3.1-8B :最も小さなモデルで、全体的に他の大きなモデルよりも性能が低いです。しかし、それでもGSM8KやMMLU STEMでは50%以上のスコアを達成しています。
- Llama-3.1-70B :サイズが大きくなることで性能が向上し、特にMMLU STEM(78.1%)で高いパフォーマンスを発揮しています。
- Llama-3.1-405B (paper):論文で報告された非常に大きなモデルで、特にMATHベンチマークで53.8%と最も高いスコアを示しています(他のGeneral Modelと比較して)。
- Qwen2-1.5B :比較的小さなモデルで、全体的に低いスコアを示していますが、GSM8Kでは58.5%と健闘しています。
- Qwen2-7B :Llama-3.1-70Bと同様に、サイズの増加により性能が向上し、GSM8KやCMATHで良いスコアを達成しています。
- Qwen2-72B :この表で最も高性能なモデルで、GSM8K(89.5%)やCMATH(88.4%)で最高のスコアを示しており、他のGeneral Modelを大きく上回っています
次にSpecific Modelの結果です。
- DeepSeekMath-Base-7B・DeepSeek-Coder-V2-Lite-Base :GSM8KやMATHでの性能が比較的高く、特にDeepSeek-Coder-V2-Lite-BaseはCMATHで77.8%を達成しています。
- Internlm-Math-Base-20B:このモデルは、特にMMLU STEMで63.0%と高いスコアを示しており、他のSpecific Modelと比較しても優れた性能を持っています。
- Qwen2-Math-72B :GSM8Kで89.1%、CMATHで86.4%と非常に高いスコアを示しており、特にGaoKao Math Clozeで72.9%と優れた性能を発揮しています。これにより、このモデルが数学タスクに非常に強いことが示されています。
- GSM8K:小学校レベルの算数問題を集めたデータセットです。このデータセットは、数理的推論や問題解決能力を評価するために使用され、NLPモデルがこれらの問題にどれだけ正確に解答できるかを評価するために使用。
- Math:数学に関連する一般的なベンチマークやデータセットを指すことが多いです。さまざまなレベルの数学問題を含んでおり、機械学習モデルの数学的推論能力を評価するために使用。
- MMLU-STEM:MMLUベンチマークのSTEM(科学、技術、工学、数学)分野に関連する部分です。MMLUは多岐にわたるタスクを含むベンチマークであり、STEM分野の問題に対するモデルの理解と解答能力を評価。
- CMATH:中国の数学教育に関連するベンチマークやデータセットです。特に中国の教育制度で使用される数学問題が含まれており、これらの問題に対するモデルのパフォーマンスを評価するために使用。
- GaoKao Math Cloze:中国の大学入試「高考(GaoKao)」における数学のクローステスト問題に特化したデータセット。クローステストとは、文章中に空欄があり、その空欄に適切な数値や式を埋める形式の問題です。このデータセットは、モデルのクローステストに対するパフォーマンスを評価するために使用。
- GaoKao Math QA:中国の大学入試「高考(GaoKao)」における数学の問題に基づいた質問応答形式のデータセットです。問題を読み取って正しい解答を導き出す能力を評価するために使用。
複数の機械学習モデルとの比較
さらに複数の機械学習モデルが数学に関する2つの異なるベンチマーク(AIME24とAMC23)でどのような性能を示したかを比較したものがこちらの表です。
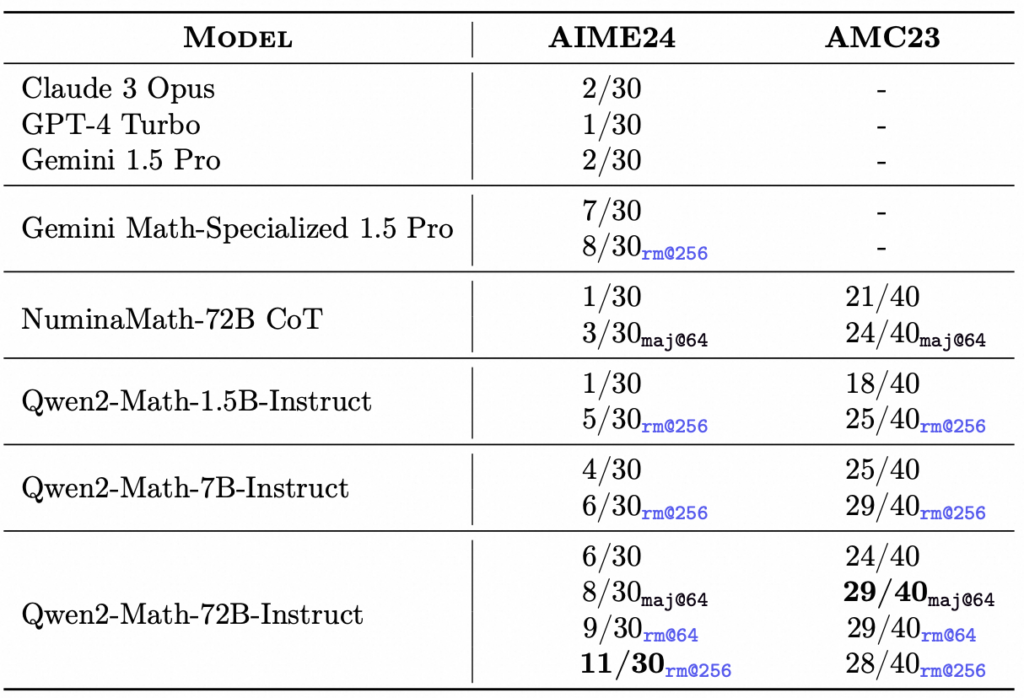
AIME24は数学に関する問題集AIME24(American Invitational Mathematics Examination)のスコアです。
x/30という形式でスコアが表記されており、30問中いくつの問題に正解したかを示しています。
AMC23は数学に関する問題集AMC23(American Mathematics Competitions)のスコア。
x/40という形式でスコアが表記されており、40問中いくつの問題に正解したかを示しています。
- Claude 3 Opus・GPT-4 Turbo・Gemini 1.5 Pro:これらのモデルは、AIME24で2/30または1/30のスコアを示しており、全体的に低いパフォーマンスを示しています。また、AMC23でのスコアは提供されていません。
- Gemini Math-Specialized 1.5 Pro:このモデルは、数学に特化したバージョンであり、AIME24では7/30や8/30(rm@256で再評価された場合)というスコアを達成しています。これは、上記の一般モデルよりも明らかに高いスコアです。
- NuminaMath-72B CoT:AIME24で1/30や3/30(maj@64で再評価)というスコアを示していますが、AMC23では21/40や24/40と、比較的高いスコアを達成しています。これは、モデルがより大規模な問題集に対して適応できることを示唆しています。
- Qwen2-Math-1.5B-Instruct:AIME24で1/30や5/30(rm@256で再評価)というスコアを示しており、AMC23では18/40や25/40のスコアを達成しています。小規模なモデルにしては、適応力があることがわかります。
- Qwen2-Math-7B-Instruct:AIME24で4/30や6/30(rm@256で再評価)、AMC23で25/40や29/40というスコアを示しており、モデルがより強力であることを示しています。
- Qwen2-Math-72B-Instruct:最も強力なモデルであり、AIME24で6/30から11/30というスコアを示し、AMC23でも24/40から29/40というスコアを達成しています。このモデルは、特に数学のタスクにおいて非常に高い性能を発揮しており、maj@64やrm@256での再評価でも一貫して高いスコアを維持しています。
この結果からQwen2-Math-72B-Instruct は、他のモデルと比較して圧倒的に高い性能を示しています。
これは、数学に特化した問題に対する深い理解と優れた解答能力を持っていることを示しています。
他のモデル(例えばClaude 3 OpusやGPT-4 Turbo)は、一般的なNLPタスクでは優れているかもしれませんが、数学的な問題には特化していないため、低いスコアとなっています。
また、Gemini Math-Specialized 1.5 Pro や NuminaMath-72B CoT も高い性能を示しており、特に再評価の設定でパフォーマンスが向上していることがわかります。
Qwen2-Mathのライセンス
Qwen2-MathはMITライセンスで提供されているので、基本的に以下のことは行うことができます。
ただし、著作権表示と許諾表示をすべてのコピーに含める必要があります。また、このソフトウェアは「現状のまま」提供され、いかなる保証もありません。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、一般モデルのQwen2について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen2-Mathの使い方
Qwen2-Mathをgoogle colaboratoryで実装します。Qwen2-Math-72Bはパラメータ数が大きすぎ、google colaboratoryでは処理が終了しないため、Qwen2-Math-7Bモデルを使って解説をします。
また、google colaboratoryでQwen2-Mathを動かす場合には、ランタイムをGPUに設定する必要があります。無料のgoogle colaboratoryではGPUメモリが15GBしかなく、処理を完了することができない可能性があります。
また、コンソールにQwen2-Math-7Bモデルの解答が表示されない問題があったため、今回はGradioにモデルを読み込ませて使っていきます。
Qwen2-Mathを動かすのに必要な動作環境
Qwen2-Mathを実行した時の環境は以下です。
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
47.9GB
■システムRAMの使用量
3.0GB
■GPU RAMの使用量
14.8GB
Qwen2-Mathのgoogle colaboratoryでの実装
まずは必要ライブラリのインストールを行います。
ライブラリのインストールはこちら
!pip install transformers
!pip install torch
!pip install gradio次にモデルをダウンロードしていきます。この時「model_name」を「Qwen/Qwen2-Math-72B-Instruct」に変更することで、Qwen2-Math-72Bモデルを使うことができます。
Qwen2-Math-7B-Instructのダウンロードはこちら
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2-Math-7B-Instruct"
device = "cuda"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)最後にGradioを実行して終了です。「Running on public URL」が発行されるので、そちらにログインすれば「Qwen2-Math-7B」モデルで数学の計算を行うことができます。
Gradioの実行はこちら
import gradio as gr
def qwen2_chat(user_input):
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_input}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
# モデルの名前を確認
print(f"Model name: {model_name}")
# モデルの構造を確認
print(model)
iface = gr.Interface(fn=qwen2_chat, inputs="text", outputs="text")
iface.launch()Qwen2-Mathに数学のゲキムズ問題を解かせてみた
Qwen2-Mathは数学に特化しているモデルであるため、今回は数学オリンピックの問題やGPT-4oとの解答の比較などをしていきたいと思います。
GPT4-oとQwen2-Mathに解かせる問題はこちらです。上から問1、2、3です。
- 6÷2(1 + 2):こちらは正答率8%と言われている問題です。
- どの桁に現れる数字も素数であるような正の整数を素敵な数とよぶ。3桁の正の整数 n であって、n+2024nとn−34がともに素数であるものはちょうど2つある。このような n をすべて求めよ。(2024年日本数学オリンピック予選問2)
- tan1°は有理数か?(2006年京都大過去問)
では実際に解かせていきます。
Qwen2-Mathのコードは使い方で記載したコードと同じです。
[Qwen2-Mathの実行動画]
こちらがQPT4-oに解かせた結果です。

Qwen2-Mathの解答がこちら

問1に関してはどちらも正解
問2ではどちらも不正解
問3はどちらも正解という結果でした。今回使用しているモデルがQwen2-Math-7Bなので、その影響もありそうです。
もしQwen2-Math-72Bで実行できる方は、ぜひ検証してみてください。
ちなみに問1の解答は1もしくは9
問2が309と311
問3が無理数です。
なお、安くて速いGPT-4o miniについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

