
【Pyramid Flow徹底解説】高品質動画を効率的に作成する方法とGoogle Colabでの実装ガイド

2024/10/10に新たに動画生成AI「Pyramid Flow」が誕生!従来の動画生成モデルとは異なる技術を使うことにより、計算量を削減しつつ、高品質の動画を生成することが可能になりました。
Pyramid Flowは、2つのピラミッド構造を採用することで、Gen3-Alphaモデルを超える高品質な動画生成が可能です。
本記事ではPyramid Flowの基本的な使い方から従来の動画生成AIとの比較まで行っていきます。最後まで読むことでGoogle ColaboratoryでPyramid Flowを実装できるようになりますので、ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Pyramid Flowの概要
Pyramid Flowはビデオ生成を効率化する空間ピラミッドと時間ピラミッドの2つのピラミッド表現を採用することで、効率的にビデオ生成ができます。
空間ピラミッドは、生成過程の初期段階では低解像度で処理することで計算量を削減し、最終段階のみで高解像度で処理することで、計算効率を向上させています。
時間ピラミッドは、ビデオの過去のフレームを低解像度で圧縮することで、計算量とメモリのオーバーヘッドを削減。
実験では、提案手法が、VBenchとEvalCrafterという2つのベンチマークで、公開されている他のビデオ生成モデルよりも優れていることを示しています。また、人間による評価でも、提案手法が、他のモデルよりも高い画質と動きの滑らかさを持っていることが示されています。
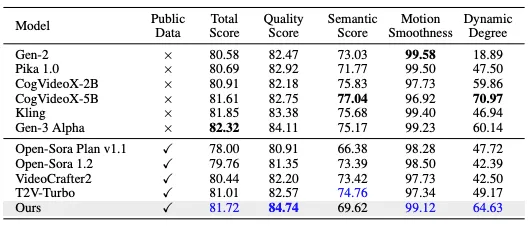
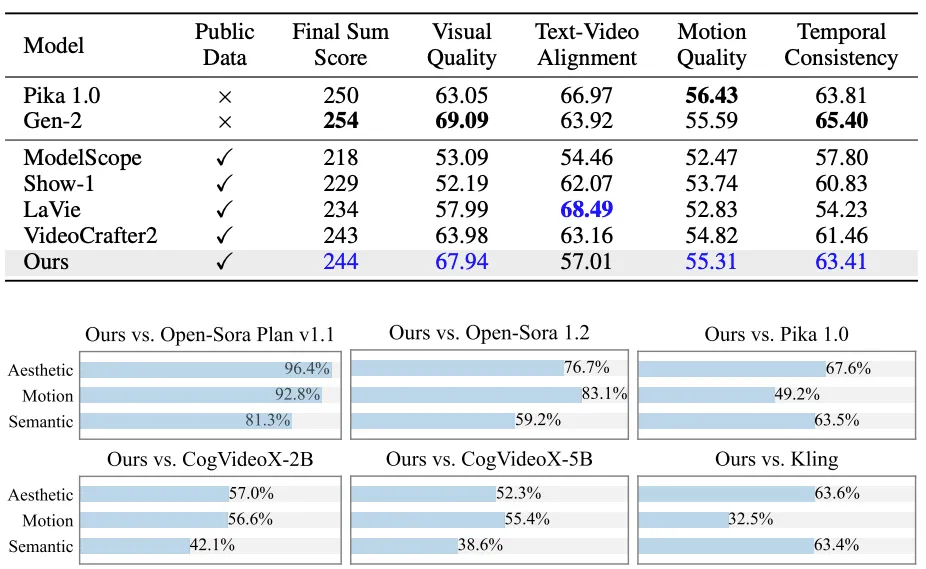
下のグラフは、Pyramid FlowとSora v1.1、1.2、Pika1.0を比較しているものです。
評価項目は美的品質(Aesthetic)モーション(Motion)セマンティック(Semantic)になっています。
美的品質は生成されたビデオの見た目や視覚的な魅力を評価する指標で、ビデオの生成結果が人間の視覚的な感覚に心地よく映るか、映画やアートのように美しいかどうかを評価します。たとえば、自然の風景や都市の夜景など、リアルで印象的なビジュアルを生成できるかが重要です。
モーションは、ビデオ内の動きがどれだけ自然で滑らかに表現されているかを評価する指標で、モーションの滑らかさや正確さは、特に動きが多いシーンやアクションを含むビデオで重要。この指標は、動きのリアリズムや、視覚的に違和感のない滑らかな表現ができているかどうかを評価します。
セマンティックは、生成されたビデオの内容が意味的に整合しているか、テキストやプロンプトに対して正しく対応しているかを評価します。
たとえば、「夕焼けの海辺で犬が走る」というテキストプロンプトが与えられた場合、そのビデオが実際に夕焼けの背景と犬の動きを正確に再現しているかが評価されます。意味的に一致していないと、たとえば夕焼けではなく昼間のシーンが生成されたり、犬ではなく猫が出てきたりすることがあります。
Pyramid Flowの効率性
ピラミッドフローマッチングを用いたビデオ生成モデルは、従来の手法と比較して、トレーニングの効率性が大幅に向上しています。
- 空間的複雑性:ビデオ生成における大きな課題の一つに、空間的複雑性があります。従来の拡散モデルは、生成過程全体を通してフル解像度で動作するため、ノイズの多い初期段階でも多くの計算リソースを消費していました。 しかし、ピラミッドフローマッチングでは、生成過程を解像度の異なる複数のピラミッド段階に再解釈することで、この問題に対処。 最終段階のみがフル解像度で動作し、初期段階では圧縮された低解像度の表現が使用されるため、計算コストが大幅に削減されます。
- 時間的複雑性:ビデオの長さによってもたらされる時間的複雑性も、もう一つの課題。従来のフルシーケンス拡散法では、すべてのビデオフレームを同時に生成するため、固定長の生成しかできませんでした。 一方、自己回帰的なビデオ生成パラダイムは、推論時に柔軟な長さの生成をサポートしますが、フル解像度の長い計算の複雑さがトレーニングのボトルネックでした。 ピラミッドフローマッチングでは、時間的ピラミッド設計を採用し、履歴条件として、段階的に圧縮された低解像度の履歴を使用することで、この問題を解決。 これにより、トレーニングに必要なトークン数が大幅に削減され、トレーニング効率が向上します。
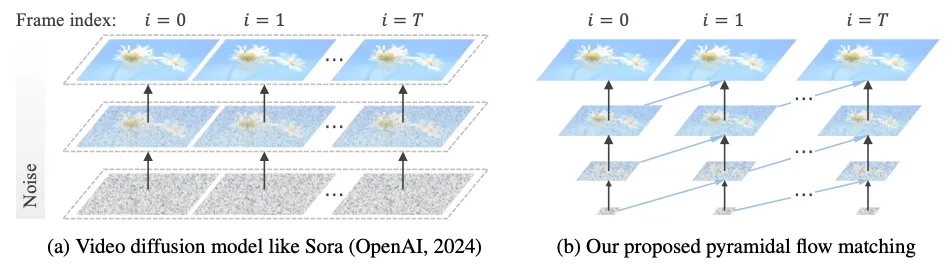
空間的・時間的複雑性によって、10秒間のビデオ(241フレーム)を生成するモデルを、わずか20.7k A100 GPU時間でトレーニングが可能。 これは、Open-Sora 1.2(97フレームのビデオ生成に4.8k Ascendと37.8k H100時間を要する)など、従来のモデルと比較して、大幅な効率向上と言えるでしょう。
Pyramid Flowのメリット
ピラミッドフローマッチングは、ビデオ生成モデルにおいて、トレーニング効率の向上と高品質なビデオ生成を両立させることができるという点で、多くのメリットがあります。
計算コストの削減とトレーニング効率の向上
- 空間ピラミッド:フレーム内の解像度を段階的に変化させる空間ピラミッドを利用することで、生成の初期段階では低解像度で処理を行い、最終段階のみフル解像度で処理を行います。これにより、従来のフル解像度処理と比べて、計算コストを大幅に削減できます。
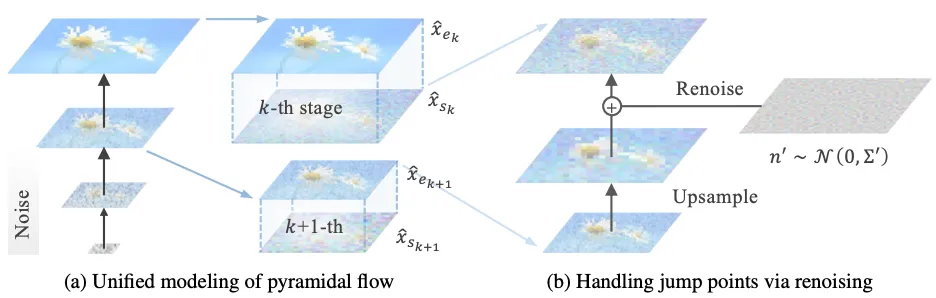
- 時間ピラミッド:過去のフレームの情報を利用する際に、解像度を段階的に下げた時間ピラミッドを用いることで、自己回帰モデルのトレーニングに必要なトークン数を大幅に削減。
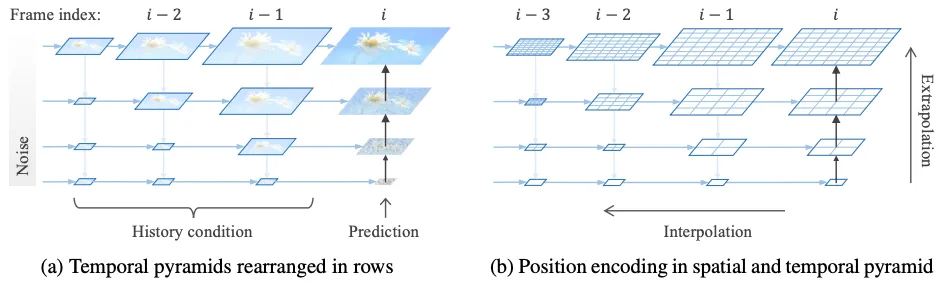
これらのピラミッド構造により、計算リソースとトレーニング時間の両方を大幅に削減。
単一モデルによるエンドツーエンドの最適化
ピラミッドフローマッチングでは、異なるピラミッド段階を単一のDiffusion Transformer (DiT)で統合し、エンドツーエンドで最適化。これは、従来のCascadeモデルのように、解像度ごとに別々のモデルをトレーニングする必要がないことを意味します。
- 知識共有の促進:単一モデルで学習することで、異なるピラミッド段階間での知識共有が促進され、モデル全体の性能向上が期待できます。
- 実装の簡素化とスケーラビリティの向上:エンドツーエンドのトレーニングは、実装を簡素化し、より大きなデータセットやモデルへのスケールアップを容易にします。

Pyramid Flowのライセンス
Pyramid FlowはMITライセンスです。そのため、基本的には商用利用や改変など自由に行うことができますが、その際には著作権表示とライセンス条件を含めることが必須です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、1024×1024の10秒動画を生成できる動画生成AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Pyramid Flowの使い方
では実際にPyramid FlowをGoogle Colaboratoryで実装しますが、サンプルコードはHugging Faceに掲載されているので、それを参考にしていきましょう
また、Google Colaboratoryで実装する際、一部注意が必要な部分がありますので、そちらもお伝えしていきます
Google ColaboratoryでPyramid Flowの実装
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
70.9GB
■GPU RAMの使用量
32.3GB
■システムRAMの使用量
14.6GB
必要ライブラリのインストールはこちら
from huggingface_hub import snapshot_download
model_path = '/content/pyramid-flow-model' # モデルを保存するローカルディレクトリ
snapshot_download("rain1011/pyramid-flow-sd3", local_dir=model_path, local_dir_use_symlinks=False)モデルのダウンロードはこちら
from huggingface_hub import snapshot_download
model_path = '/content/pyramid-flow-model' # モデルを保存するローカルディレクトリ
snapshot_download("rain1011/pyramid-flow-sd3", local_dir=model_path, local_dir_use_symlinks=False)モデルをダウンロードする際、モデルを保存するディレクトリが必要になります。
上記の場合、/contentに新たなフォルダを作成して、そちらにモデルを保存するようにしています。
また、この時にカレントディレクトリが移動してしまっているので、Pyramid-flowに移動し直す必要があります。
ディレクトリの移動はこちら
%cd Pyramid-Flowサンプルコードはこちら
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers.utils import export_to_video
torch.cuda.set_device(0)
model = PyramidDiTForVideoGeneration(
'/content/pyramid-flow-model',
model_dtype='bf16',
model_variant='diffusion_transformer_768p',
)
model.vae.to("cuda")
model.dit.to("cuda")
model.text_encoder.to("cuda")
model.vae.enable_tiling()
# テキストプロンプトからビデオを生成
prompt = "A beautiful sunset over the ocean"
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch.bfloat16):
frames = model.generate(
prompt=prompt,
num_inference_steps=[10, 10, 10], # ステップ数を減らす
height=512, # 解像度を下げる
width=768,
temp=16,
guidance_scale=7.0,
video_guidance_scale=4.0,
output_type="pil",
save_memory=True,
)
# ビデオファイルにエクスポート
export_to_video(frames, "./generated_video.mp4", fps=24)Google ColaboratoryのA100環境ではHugging Faceのサンプル設定だとメモリ不足になるため、解像度とステップ数を調整しています。
| それぞれの設定値 | |
|---|---|
| guidance_scale | 最初のフレームの品質やプロンプトへの忠実度 |
| video_guidance_scale | フレーム間の動きのダイナミクスを調整。高い値でダイナミックな動き、低い値で滑らかな動きに。 |
| num_inference_steps | ビデオ生成に必要な推論ステップ数。品質と計算時間のバランスを取る |
| temp | 生成のランダム性を制御します。高い値でクリエイティブな結果、低い値で安定した結果に |
生成された動画はこちら!
解像度やステップ数を減らしているため、チラつく感じが出てしまっているのかもしれません。


Pyramid Flowをそのほかの動画生成AIモデルと比較してみる
ここからはPyramid Flowで生成される動画とそのほかの動画生成AIで生成される動画を比較してみたいと思います。
比較する動画生成AIは次の2つです。
Soraでは「A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.」というプロンプトで動画を生成して比較してみます!
また、Pyramid FlowはImage-to-Videoを可能なため、偉人の肖像画や顔画像を入力し、笑わせてみたり表情を変えてみたり、スポーツの静止画を入力し、自然な動きをさせてみたりしたいと思います!
Soraとの比較コードはこちら
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers.utils import export_to_video
torch.cuda.set_device(0)
model = PyramidDiTForVideoGeneration(
'/content/pyramid-flow-model',
model_dtype='bf16',
model_variant='diffusion_transformer_768p',
)
model.vae.to("cuda")
model.dit.to("cuda")
model.text_encoder.to("cuda")
model.vae.enable_tiling()
# テキストプロンプトからビデオを生成
prompt = "Subtle reflections of a woman on the window of a train moving at hyper-speed in a Japanese city."
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch.bfloat16):
frames = model.generate(
prompt=prompt,
num_inference_steps=[20, 20, 20], # ステップ数を減らす
height=512, # 解像度を下げる
width=768,
temp=16,
guidance_scale=7.0,
video_guidance_scale=4.0,
output_type="pil",
save_memory=True,
)
# ビデオファイルにエクスポート
export_to_video(frames, "./generated_video1.mp4", fps=24)
生成された動画は以下です。
Gen3では「Subtle reflections of a woman on the window of a train moving at hyper-speed in a Japanese city.」というプロンプトで、比較してみます。
Gen3との比較コードはこちら
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers.utils import export_to_video
torch.cuda.set_device(0)
model = PyramidDiTForVideoGeneration(
'/content/pyramid-flow-model',
model_dtype='bf16',
model_variant='diffusion_transformer_768p',
)
model.vae.to("cuda")
model.dit.to("cuda")
model.text_encoder.to("cuda")
model.vae.enable_tiling()
# テキストプロンプトからビデオを生成
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors."
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch.bfloat16):
frames = model.generate(
prompt=prompt,
num_inference_steps=[20, 20, 20], # ステップ数を減らす
height=512, # 解像度を下げる
width=768,
temp=16,
guidance_scale=7.0,
video_guidance_scale=4.0,
output_type="pil",
save_memory=True,
)
# ビデオファイルにエクスポート
export_to_video(frames, "./generated_video1.mp4", fps=24)生成された動画は以下です。
こちらはPyramid FlowのDemo版で生成した動画です。
やはりステップ数や解像度を下げている影響からか、うまく生成ができませんね・・
Demoで生成した動画を見ると画質はかなり綺麗かなと思います。
次はImage to Videoを行なっていきます。
偉人の肖像画を笑わせるコードはこちら
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
import torch
from diffusers.utils import export_to_video
# GPUの設定
torch.cuda.set_device(0)
# モデルのロード
model = PyramidDiTForVideoGeneration(
'/content/pyramid-flow-model', # モデルのパスを指定
model_dtype='bf16', # 半精度を使用する場合
model_variant='diffusion_transformer_768p', # モデルのバリアント
)
# 各コンポーネントをGPUに移動
model.vae.to("cuda")
model.dit.to("cuda")
model.text_encoder.to("cuda")
model.vae.enable_tiling()
# 入力画像を読み込み
image = Image.open('/content/20241001_furukawa_hiroaki_nakatogawa-650x433.jpg').convert("RGB").resize((768, 512))
# プロンプトを定義
prompt = "Make the figures in the paintings laugh."
# ビデオ生成
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch.bfloat16):
frames = model.generate_i2v(
prompt=prompt,
input_image=image,
num_inference_steps=[10, 10, 10], # 各ステージの推論ステップ数
temp=16, # 温度パラメータ
video_guidance_scale=4.0, # ガイダンススケール
output_type="pil",
save_memory=True, # メモリを節約するオプション
)
# ビデオファイルにエクスポート
export_to_video(frames, "./image_to_video_sample1.mp4", fps=24)
上記のコードを用いた結果は以下です。
次にスポーツの静止画を使って、動画を生成してみます。
スポーツの静止画のコードはこちら
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
import torch
from diffusers.utils import export_to_video
# GPUの設定
torch.cuda.set_device(0)
# モデルのロード
model = PyramidDiTForVideoGeneration(
'/content/pyramid-flow-model', # モデルのパスを指定
model_dtype='bf16', # 半精度を使用する場合
model_variant='diffusion_transformer_768p', # モデルのバリアント
)
# 各コンポーネントをGPUに移動
model.vae.to("cuda")
model.dit.to("cuda")
model.text_encoder.to("cuda")
model.vae.enable_tiling()
# 入力画像を読み込み
image = Image.open('/content/20241001_furukawa_hiroaki_nakatogawa-650x433.jpg').convert("RGB").resize((768, 512))
# プロンプトを定義
prompt = "run a person"
# ビデオ生成
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch.bfloat16):
frames = model.generate_i2v(
prompt=prompt,
input_image=image,
num_inference_steps=[10, 10, 10], # 各ステージの推論ステップ数
temp=16, # 温度パラメータ
video_guidance_scale=4.0, # ガイダンススケール
output_type="pil",
save_memory=True, # メモリを節約するオプション
)
# ビデオファイルにエクスポート
export_to_video(frames, "./image_to_video_sample1.mp4", fps=24)
生成された動画は以下です。こちらもあまりうまく生成ができませんでした。
最後に番外編ですが、あの有名海賊漫画も動画にしてみます。
やはりこちらもGPUの影響からかうまくいっていませんが、プロンプトの指示に従おうとしている様子は見てとれます。
Google Colaboratoryの限られた環境では、綺麗な動画を生成することはできませんでしたが、ローカル環境で実装できる場合には、短時間で高画質の動画を生成することができるため、これまで以上に動画生成界隈が賑わうことが予想されます。
ぜひ今のうちに動画生成AIを使いこなせるようにしておきましょう!
また、Hugging Faceで公開されているデモでも試してみたのですが、メモリが不足してしまい、あまり高品質とは言えない動画が生成されてしまいました…。メモリを増強して再挑戦しようと思っています。
なお、裏ワザでOpenAIのSoraを使う禁断の方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではPyramid Flowについて詳しく解説し、Google Colaboratoryでの実装方法を紹介しました。Google Colaboratoryでは限界がありますが、Demo版を使ってみると、画質は確かに綺麗になっていることがわかります。
計算コストを削減しながらも、高品質な動画生成を実現することが可能です。広告制作やプロモーション映像、製品デモなど、多様な業務で高品質な動画を効率的に活用できるでしょう。
ローカル環境で実装できる場合、短時間で高画質な動画生成が可能となり、今後の動画生成分野での活用が大きく進むことが期待されます。
最後に
いかがだったでしょうか?
Pyramid Flowなどの動画生成AIは、広告制作、プロモーション映像、製品デモなど、幅広い業務において、高品質な動画を効率的に生成できます。計算コストを抑えつつ、最先端の生成AI技術で動画コンテンツを強化しませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

