
【LayerSkip】LLMの回答速度を2倍に向上させるMetaの最新技術

WEELメディア事業部LLMリサーチャーの2scです。
2024年10月21日、MetaがLLMの回答速度を約2倍に向上させる技術「LayerSkip」を公開しました。
このLayerSkipはなんと、部品追加なしで生成速度UPが可能!しかもすでに、LlamaシリーズからLayerSkipに対応したLLMが計7モデルも登場しています。
この記事ではそんなLayerSkip対応のLlamaシリーズの使い方や、有効性の検証まで行います。本記事を熟読することで、LayerSkipの凄さを理解し、サクサク動くAIツールが作れるかもしれません。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
LayerSkipの概要
「LayerSkip」はMeta(旧Facebook)が開発した、LLMの回答速度を高める手法になります。そのすごいところとしては下記のとおりです。(※1)
- 部品(層やモジュール)の追加なしで、LLMの生成速度UPを実現
- 幅広いタスクにて、ベースのLLMからの速度UPを確認済み
- CNN/DM(ニュース記事のデータセット)を要約するタスクで最大2.16倍の速度UP
- コーディングタスクで1.82倍の速度UP
- TOPv2(多分野のデータセット)の意味解析タスクで2.0倍の速度UP
- LlamaシリーズからLayerSkipを採用した下記モデルが登場
- layerskip-llama2-7B
- layerskip-llama2-13B
- layerskip-codellama-7B
- layerskip-codellama-34B
- layerskip-llama3-8B
- layerskip-llama 3.2-1B
このLayerSkipを適用したLLMについては、ベースのモデルと比べて、回答生成の速度が段違いに向上。具体的には……
このように、元のモデルの倍近い速度で生成が可能となっています。
LayerSkipのしくみ
LayerSkipは「Early Exit / 早期終了」と「Speculative Decoding / 投機的デコーディング」という2つの技術からなります。そのしくみはいたってシンプル。思考過程の前半で手短かつ大まかに結論を出したあと(Early Exit)、思考過程の後半でその結論を精査していく(Speculative Decoding)という流れで、迷いのない回答生成が実現しています。
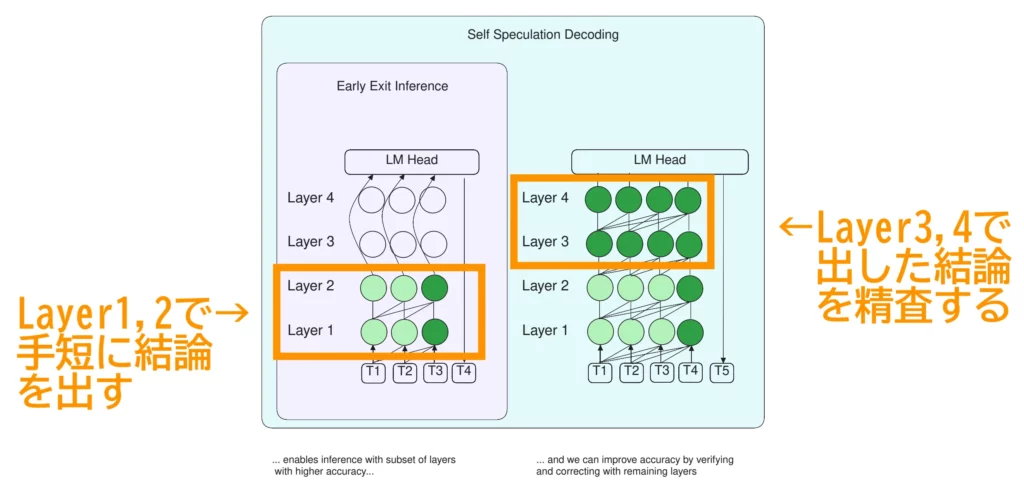

なかでもポイントは、Early Exitで余らせた推論能力を精査に回しているところでしょう。この工夫のおかげで、案出し&精査で計2モデルを要する従来のSpeculative Decodingとは違い、1モデルでの高速推論が実現しています。
LayerSkipのライセンス
公式ページによるとLayerSkipは「CC-BY-NCライセンス」のもと、無料で私的使用が可能です。ただし、商用利用・特許使用はNGとなっています。(※2)
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ❌ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ❌ |
| 私的使用 | ⭕️ |
なお、Metaの最新LLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

LayerSkip対応のLlamaシリーズの使い方
HuggingFaceのMeta公式ページでは、LayerSkipに対応したLlamaシリーズ計7モデルが公開中です。ここからは、そんなLayerSkip対応のLlamaシリーズの使い方について、GitHubのREADMEに記載されているやり方をお伝えしていきます。(※2)
モデルにアクセスする方法
LayerSkip対応のLlamaシリーズについては、以下の手順でアクセスが可能です。
- HuggingFaceのアカウントでログイン
- 下記のリンクから使いたいモデルのページにアクセス
- リクエストフォームを埋めて送信(承認・メール受信までは時間がかかります)
- 手順に沿ってユーザーアクセストークンを取得
- コマンドラインで「huggingface-cli login」を実行

回答生成の方法
ここからは、LayerSkip対応のLlamaシリーズで回答生成を行う方法についてもご紹介します。手始めに、以下のPythonコードをコマンドライン上で実行して、GitHubからLayerSkipをクローンしてしまいましょう!
$ git clone git@github.com:facebookresearch/LayerSkip.git
$ cd LayerSkipそして次は、環境周りの設定。下記を実行して、Python3.10の環境に必要なライブラリ一式をインストールします。
$ conda create --name layer_skip python=3.10
$ conda activate layer_skip
$ pip install -r requirements.txtこれで、LayerSkipを動かすのに必要な下準備は完了しました。
さて、今度はお待ちかね、LayerSkipによる回答生成です。回答生成用のコードは……
$ torchrun generate.py --model facebook/layerskip-llama2-7B \
--sample True \
--max_steps 512 \
--generation_strategy self_speculative \
--exit_layer 8 \
--num_speculations 6以上のとおり。詳細は下記をご確認ください!
| プログラム&引数 | 詳細 |
|---|---|
| generate.py | 生成用プログラム |
| –sample | サンプリングの有無 |
| –temperature | 回答の自由度 |
| –top_p | 回答候補のうち上位の確率Pに含まれるものを選ぶ絞り込み |
| –top_k | 回答候補のうち上位K個を選ぶ絞り込み |
| –help | コマンドライン引数の詳細確認 |
| benchmark.py | ベンチマーク用プログラム |
| –dataset cnn_dm_summarization | CNN/DM要約 |
| –dataset xsum_summarization | XSUM要約 |
| –dataset cnn_dm_lm | CNN/DM言語モデリング(抜粋した単語から自由に生成) |
| –dataset human_eval | HumanEvalコード生成 |
| –n_shot | shotの反復数で、デフォルトは0-shot |
| –help | コマンドライン引数の詳細確認 |
| eval.py | 評価用プログラム |
| –tasks gsm8k | 小学生向け算数のタスク |
| –tasks cnn_dailymail | ニュース記事の要約タスク |
| sweep.py | 高速化用プログラム |
| –num_speculations | 案出しと精査の配分 |
| –exit_layer | 思考(層)の深さ |
結論を急いで生成速度UPの「LayerSkip」
当記事では、LLMの回答速度を倍増させる手法「LayerSkip」についてご紹介しました。このLayerSkipは結論を手短に出してから精査していくという手法で、迷いのない回答生成が実現しています。
すでに、LayerSkip対応のLlamaシリーズが7モデルも登場していますので、今後サクサク動くチャットボットが出てくるかもしれません。GPT-4oやClaude 3.5のようなハイエンドLLMだけでなく、高速化技術の今後も要チェックですよ!
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

