
1枚の写真からその場にいるような3D動画へHunyuanWorld-Voyagerの性能や使い方を徹底解説!
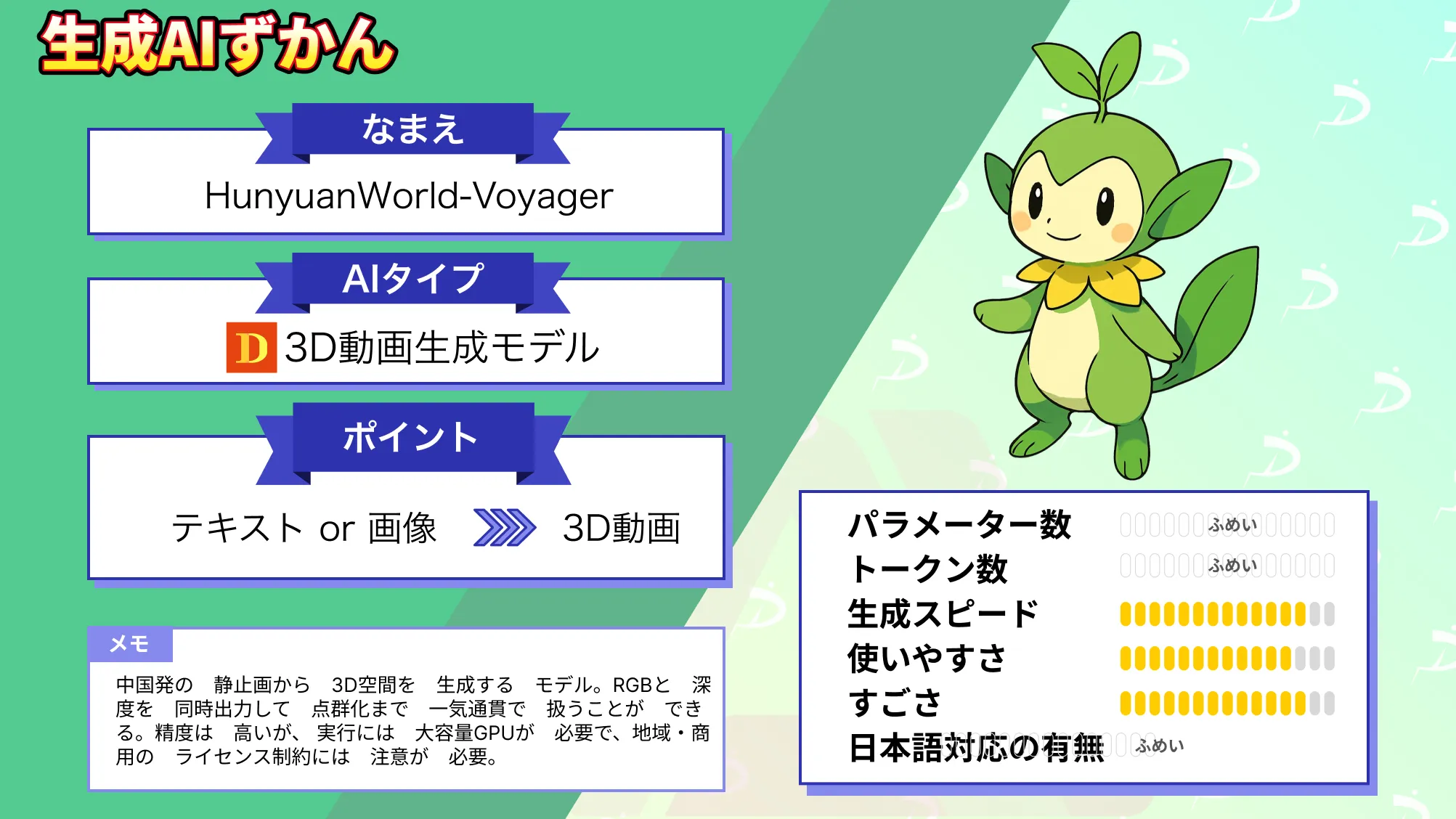
- 静止画から3D空間を生成するモデルで、RGBと深度を同時出力し点群化までを一気通貫で扱える
- ワールドキャッシュにより、長距離のカメラ移動でも整合性が高い
- 実行には大容量GPUが必要で、地域・商用のライセンス制約にも注意が必要
2025年9月2日、中国テンセントのAI研究チーム「混元(Hunyuan)」がオープンソースモデル「HunyuanWorld-Voyager」をリリースしました!
HunyuanWorld-Voyagerは、1つの静止画から、まるでその中を自由に歩き回っているかのような3D動画を作り出す画期的なツールとして、世界中のAI・3D技術コミュニティで大きな話題を呼んでいます。
本記事では、HunyuanWorld-Voyagerの概要や性能、使い方まで徹底的に解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
HunyuanWorld-Voyagerの概要
HunyuanWorld-Voyager(以下、Voyager)は、テンセント社が開発した最新の3D生成AIモデルで、入力として1枚の画像を与えるだけで、そのシーンの中を移動する短い動画を作り出すことができます。
具体的には、ユーザーが移動経路や視点の動きといった「カメラパス」を自由に指定すると、それに沿って、画像の中の風景を3次元的に拡張した動画を生成します。例えば、建物の写真を入力して「前方に進む」カメラパスを与えれば、まるでカメラが写真の中に入り込んで前進していくような映像が得られます。
生成される動画は、RGBカラー映像と対応する深度マップがフレームごとにペアになっていて、各物体までの距離情報がきちんと整合された状態で出力されます。そのため、出力された動画から直接ポイントクラウドデータを再構成して3Dモデル化することも可能で、従来必要だった複雑な写真測量処理(例えばCOLMAPのようなツールによる画像からの3D再構築など)を省略できるメリットがあります。

Voyagerは、技術的には、拡散モデル(Diffusion Model)を用いた動画生成フレームワークとなっています。一貫した3D空間表現を維持するために、特殊な「3Dメモリ」機構を備えているのが特徴です。
まず、入力画像から得られた初期シーン情報を保持する「ワールドキャッシュ」と呼ばれるメモリに、生成途中で得られる点群データをどんどん蓄積していきます。このワールドキャッシュでは、視点移動に伴って不要になった点を自動で削除し、新たに見えてくる部分の点を追加する「ポイントカリング(いわゆる間引き)機能」を持っています。
そして、映像を生成する各フレームで、その蓄積済みの点群を2D画像に投影し直し、次のフレーム生成時の参照として利用します。こうしたフィードバックループによって、シーンの大枠となる幾何構造を常に参照しながら動画を生成できるため、カメラが大きく動いても、オブジェクト同士の位置関係が崩れない「世界と一貫性のある」映像が得られます。


HunyuanWorld-Voyagerの性能
Voyagerの性能は、多くの客観的な指標で現時点の最高クラスであることが確認されています。スタンフォード大学の研究者らが提案した「WorldScore」ベンチマーク(3Dワールド生成システムの総合評価指標)においては、スコア77.62を記録し、比較対象となった他のモデルを抑えて第1位となりました。
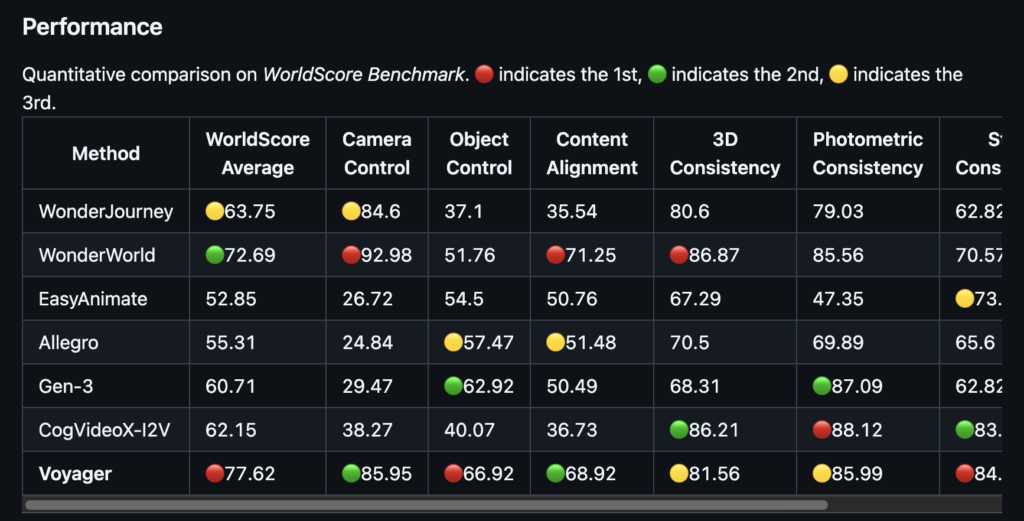
例えば、従来トップ水準とみなされていたTencent社の別モデルWonderWorld(72.69)や、北京大学のCogVideoX-I2V(62.15)といったオープンソースモデルよりも高いスコアで、特に、スタイルの一貫性や主観的な映像品質の項目で優れていたと報告されています。
WorldScore以外の個別指標でも、Voyagerの映像生成クオリティは突出しています。カメラ視点を操作できる既存のオープンソース動画生成モデル4種類との比較では、PSNR(画質)、SSIM(構造類似度)、LPIPS(知覚画像距離)などの主要な画質評価値でVoyagerが他モデルを上回りました。
シーン内の奥行きの正確さや、物体配置の整合性といった3D一貫性の面でも、他手法より優秀な結果を収めています。公式発表でも「主要指標において競合モデルを圧倒する全面的な優位性を示した」と述べられており、この分野で最先端の性能を持つことが裏付けられています。
なお、関連モデル「Hunyuan 3D」について詳しく知りたい方は、以下の記事も参考にしてみてください。
HunyuanWorld-Voyagerのライセンス
Voyagerは、オープンソースで公開されていますが、そのライセンスは一般的なOSSライセンスとは異なる「Tencent HunyuanWorld-Voyager Community License」という独自のものが適用されています。
このライセンスは、本モデルやその派生モデルの利用について、いくつか重要な制限事項を設けています。まず地域的な制限として、ヨーロッパ連合(EU)・イギリス・韓国における利用を明確に禁止しています。つまり、これらの地域では本モデルを使用・配布できません。また、商用利用に関しても規模によって条件が課せられており、特に月間アクティブユーザーが極めて多いサービスでの商用展開にはTencentとの追加契約が必要とされています。以下に主要な利用条件をまとめます。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️(条件付き) | ※利用地域に制限あり ※大規模ユーザーベースの利用は事前にTencentの許諾が必要 |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
HunyuanWorld-Voyagerの料金
Voyager自体はオープンソースで無償提供されています。GitHubのリポジトリやHugging Faceのモデルページから誰でもコードや学習済みモデルを入手でき、利用にあたってライセンス料などのコストは発生しません。商用利用であっても前述のコミュニティライセンスの範囲内であれば特に利用料金は不要です。
| 区分 | 料金 | 備考 |
|---|---|---|
| ソフトウェア本体 | 無料 | |
| 商用利用のライセンス料 | 無料(条件付き) | 利用条件はコミュニティライセンスに準拠(大規模サービスの場合は要Tencent許諾) |
| サポート費用 | なし | 公式の無償DiscordやWechatグループで情報交換可能 |
ご覧の通り、モデルそのものの利用に料金は発生しません。これはOpenAIのAPIサービス等と異なり、自分で環境を用意して動かすセルフホスト型のAIモデルであるためです。その代わりに、高性能GPUを搭載したマシンが必要になるので、その調達コスト(オンプレミスのGPU購入費用やクラウドの使用料)が事実上の「利用料金」と言えるかもしれません。
HunyuanWorld-Voyagerの使い方
Voyagerを実際に使用するには、ある程度の技術的ステップが必要ですが、公式が公開している手順に沿って進めれば比較的スムーズに動かせます。
公式手順
① 環境の準備
まずは実行環境として、LinuxマシンとNVIDIA GPUを用意します。GPUのメモリは最低60GB、推奨80GBと非常に大きいため、クラウドの場合A100 80GB相当のインスタンスなどを利用するとよいでしょう。
次にソフトウェア環境を整えます。Pythonの仮想環境(例えばconda環境)を作成し、Python 3.11系をインストールします。続いて、PyTorchをはじめとした必要ライブラリをインストールします。公式推奨では、CUDA 12.4対応のPyTorch 2.4.0を使用しており、以下のコマンドで依存関係を満たすよう指示されています。
# 仮想環境を作成しPython 3.11.9を用意(conda利用の場合)
conda create -n voyager python=3.11.9
conda activate voyager
# PyTorch 2.4.0 + CUDA12.4 対応版をインストール
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
# Pythonパッケージの依存関係をインストール
pip install -r requirements.txt
pip install transformers==4.39.3上記は一例ですが、要は適切なバージョンのPyTorchと関連ライブラリ(Torchvisionやトランスフォーマーなど)をインストールし、Voyagerの実行に必要な環境を用意するステップです。公式READMEによれば、追加でFlashAttention v2やxDiT(マルチGPU推論用ツール)のインストールも推奨されています。これは高速化のためなので、まずシングルGPUで試す場合は省略しても構いません。
② リポジトリの取得
環境準備ができたら、GitHubリポジトリからVoyagerのコード一式を取得します。以下のようにgitコマンドでクローンできます。
git clone https://github.com/Tencent-Hunyuan/HunyuanWorld-Voyager.git
cd HunyuanWorld-Voyagerリポジトリ内にはソースコードのほか、例示用の画像やスクリプト類が含まれています。また、日本語ドキュメントはありませんが、英語のREADMEや中国語READMEも用意されていますので適宜参照してください。
③ 学習済みモデルのダウンロード
Voyagerをローカルで動かすためには学習済みモデル(重みファイル)が必要です。これらはHugging Face上で公開されているのでダウンロードします。公式リポジトリでは、Hugging FaceのCLIツールを使ったダウンロード方法を案内しています。
huggingface-cli download tencent/HunyuanWorld-Voyager --local-dir ./ckpts上記コマンドにより、Hugging Face上のtencent/HunyuanWorld-Voyagerリポジトリからモデルファイル群が./ckptsフォルダに保存されます。ファイルサイズが大きいため時間がかかりますが、完了すれば実行に必要なデータ準備はOKです。
④ 入力データの準備
次に、モデルに与える入力画像とカメラパスの指定を行います。リポジトリ内のexamplesフォルダにいくつかサンプル画像とそれに対応するprompt.txtが用意されています。
まずは、動作確認を兼ねてこれらサンプルを使うのがおすすめです。もし自分の好きな画像で試す場合は、その画像ファイルを例えばexamples/mycase/フォルダを作って配置しましょう。そして、カメラパス(視点移動の種類)を選択します。
公式のスクリプトdata_engine/create_input.pyを使うと、指定したタイプのカメラ動作に沿った「カメラ軌道付き入力データ(初期の深度付き映像)」を自動生成できます。利用可能なカメラパスの種類として、forward(前進), backward(後退), left(左に平行移動), right(右に平行移動), turn_left(左旋回), turn_right(右旋回)などが用意されています。例えば前方に進む視点移動を指定するには、以下の通り。
cd data_engine
python3 create_input.py --image_path "入力画像のパス" --render_output_dir "examples/mycase/" --type "forward"上記によってexamples/mycase/フォルダ内に、入力画像から生成した短い疑似映像(カメラが前進する様子の深度付き動画)が作られます。この映像が、次の推論ステップでVoyagerモデルに与える「世界の初期観測データ」となります。
⑤ 推論の実行
いよいよVoyagerモデルによる動画生成を実行します。リポジトリ直下に用意されているsample_image2video.pyスクリプトを使い、先ほど準備した入力データフォルダとテキストプロンプトを指定して実行します。基本的なコマンド構文は以下の通りです。
cd HunyuanWorld-Voyager
python3 sample_image2video.py \
--model HYVideo-T/2 \
--input-path "examples/mycase" \
--prompt "ここにシーンの説明テキスト(プロンプト)を記入" \
--infer-steps 50 \
--i2v-stability \
--flow-reverse --flow-shift 7.0 \
--seed 0 \
--embedded-cfg-scale 6.0 \
--use-cpu-offload \
--save-path ./results以上のコマンドを実行すると、モデルが推論を行い始めます。GPUメモリが不足する場合は--use-cpu-offloadオプションにより一部処理をCPUに逃がしています。生成にはハードウェア性能にもよりますが、数分~数十分程度かかります。完了すると指定した--save-pathに生成されたRGB動画(mp4ファイル)と対応深度マップなどが出力されます。
⑥ 結果の確認・3D再構築
出力フォルダ内にある動画ファイルを再生してみましょう。入力画像の中をカメラが動き回る、不思議な映像が得られているはずです。深度マップ付きで出力している場合は、点群データに変換することもできます。
オプション手順(WebUI)
コードを直接実行する方法のほかに、VoyagerにはGradioを使った簡易なWeb GUIデモも用意されています。コマンドライン操作に不慣れな場合や、インタラクティブに試したい場合はこちらが便利です。
GitHub公式リポジトリ内のapp.pyを実行するとローカルホスト上でGradioアプリが立ち上がります。
git clone https://github.com/Tencent-Hunyuan/HunyuanWorld-Voyager.git
cd HunyuanWorld-Voyager
python3 app.pyブラウザで表示されるGUI上で、まず入力画像をアップロードし、次にカメラ移動方向を選択して「条件動画」を生成します。続いてテキストプロンプトを入力し、「Generate」を押すとモデルが推論を行い、RGB-D動画が生成されて画面上に再生されます。このGUIデモでは、内部でcreate_inputとsample_image2videoの手順を対話的に実行してくれるため、一連の流れをわかりやすく体験することができます。
オプション手順(WebUI②)
さらに簡単な手順として、公式サイトのTry It Nowボタンから、簡易に試すことができるWebUIを立ち上げることができます。2025年9月時点では、1日20回無料で生成できるようです。
ボタンを押すと、アカウント登録を求められるので、利用規約を確認の上、メールアドレスを登録しましょう。支払い方法の登録は必要ありません。登録が完了すると、以下の画像のようなデモ画面が立ち上がります。
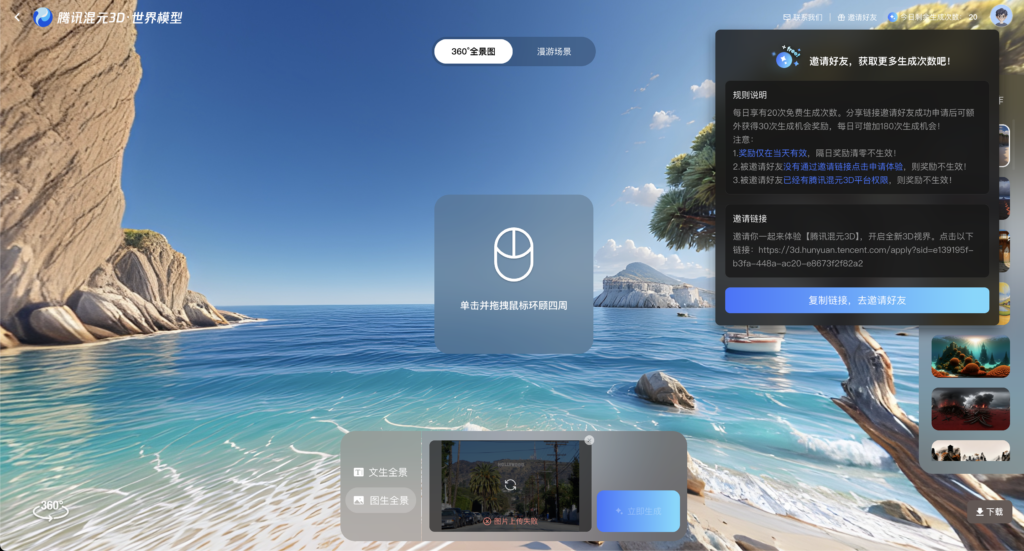
テキストまたは画像を入力として、generateボタンを押すと、3D生成がスタートします。数十秒程度で3D動画が完成します。
以上が基本的な使い方です。繰り返しになりますが、公式で推奨されている手順で動かすためには、非常に高スペックなマシンが必要になりますので、手元に環境がない場合はAWSやGCPのGPUインスタンスなどのクラウドサービスや、Google ColabのハイメモリGPUプラン等を利用するようにしましょう。
HunyuanWorld-Voyagerを使ってみた
実際にHunyuanWorld-Voyagerを使ってみましょう。今回は、1番お手軽なオプション手順(WebUI②)の方法で試してみます。
まずは、ロサンゼルスの街中の画像をインプットにしてみます。画像はこちら。

結果はこちら。
20秒ほどで生成してくれました。実際のビーチウッドドライブのイメージとは異なりますが、ある程度自然な街中ビューを作ってくれていますね。
もう1つだけ試してみましょう。お次はワイキキビーチのこちらの画像をインプットとします。

結果はこちら。
実在する場所を完璧に再現することは難しそうですが、雰囲気を掴んでそれっぽい360°ビューは作ってくれますね。これを数十秒で生成できるのはなかなか良いです。
最後にテキストプロンプトからの3D動画生成も試しておきましょう。プロンプトはこちら。
Generate a 3D of Waikiki Beach in Hawaii.
(ハワイのワイキキビーチの3Dを生成して)結果はこちら。
ざっくりですが、実際のワイキキビーチのイメージは捉えられていますね。ワイキキの街中感はないですが、最後に見える山のようなものが、位置関係的にもダイヤモンドヘッドに見えなくもありません。
いかがでしょう?シーン内の奥行きの正確さや、物体配置の整合性はある程度確認できましたね。
気になる方は、ぜひ一度試してみてください。
まとめ
HunyuanWorld-Voyagerは、一枚の画像から奥行き情報まで備えた3Dシーン動画を生成するという、これまでにない斬新なモデルです。
本モデルは、独自のワールドキャッシュ機構によって3D的な整合性をキープして、高品質なRGB-D動画を生み出すことに成功しています。従来技術との差別化も素晴らしく、特に空間の一貫性や直接的な3D出力能力においてVoyagerは群を抜いていました。
コミュニティでは、簡易実行スクリプトやWindows対応の試みなども報告されているようですので、今後ユーザーフレンドリーなツールが充実していくことも期待されます。
気になる方はぜひ一度試してみてください。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

