
Qwen3-Max-Preview徹底レビュー!性能・ライセンス・使い方・検証レポートを公開
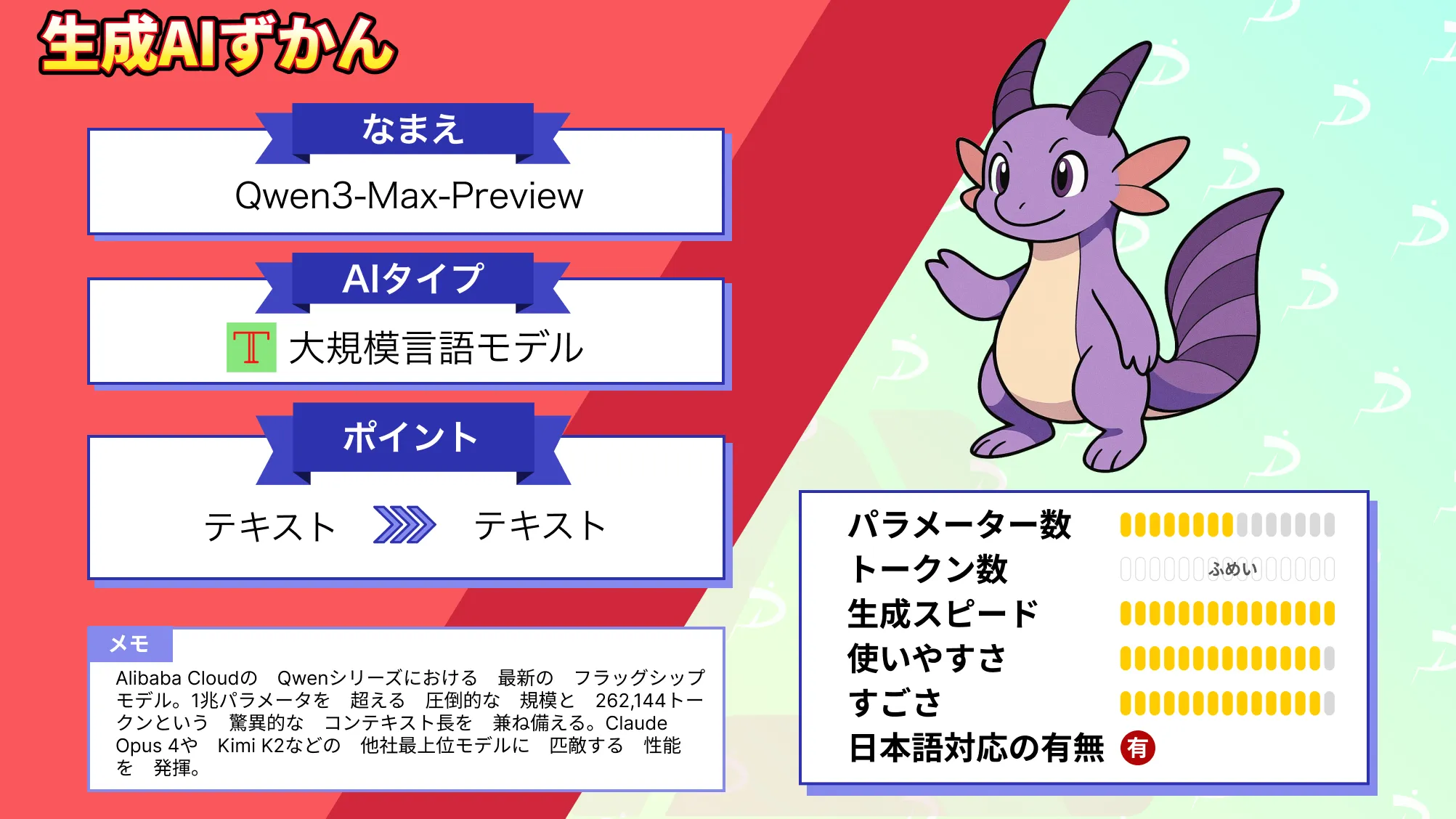
- Alibaba CloudのQwenシリーズにおける最新のフラッグシップモデル
- 1兆パラメータを超える圧倒的な規模と262,144トークンという驚異的なコンテキスト長を兼ね備える
- Claude Opus 4やKimi K2などの他社最上位モデルに匹敵する性能を発揮
2025年9月6日、Alibabaが最新の大規模言語モデル「Qwen3-Max-Preview」を公開しました!
本モデルは単なる世代交代ではなく、1兆パラメータを超える圧倒的な規模と262,144トークンという驚異的なコンテキスト長を兼ね備えた最新の大規模言語モデルとなっています。
従来のQwenシリーズが持つ多言語対応力や推論性能をさらに強化し、ClaudeやGemini、DeepSeekといった競合モデルを上回る性能を有するとのこと。
本記事では、そんなQwen3-Max-Previewの概要や性能、使い方まで徹底解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Qwen3-Max-Previewの概要
Qwen3-Max-Previewは、Alibaba CloudのQwenシリーズにおける最新のフラッグシップモデルです。

前モデルを大きく上回る1兆以上のパラメータを持ち、従来モデル比で中国語・英語を含む多言語の理解力向上や複雑な命令への適応力強化が図られています。公式発表によれば、主観的判断やツール活用が必要なタスクに優れ、生成コンテンツにおけるハルシネーションも大幅に低減しているとのことです。
現状では、非思考モデルとして提供されており、深い推論機能は将来追加予定とされています。上位互換モデルとしてプログラミング補助や長文要約、自然言語対話など、多岐にわたる用途での利用が想定されています。
なお、Qwen3モデルについて詳しく知りたい方は、以下の記事も参考にしてみてください。

Qwen3-Max-Previewの性能
公式ベンチマークでは、Qwen3-Max-Previewは、前世代モデル(Qwen3-235B-A22B)を上回る成績を示し、Claude Opus 4やKimi K2など他社最上位モデルに匹敵する性能を発揮しています。特に、数学(AIME25)、プログラミング(LiveCodeBench)など複数のタスクで同モデルが首位を独占し、総合力の高さが示されています。
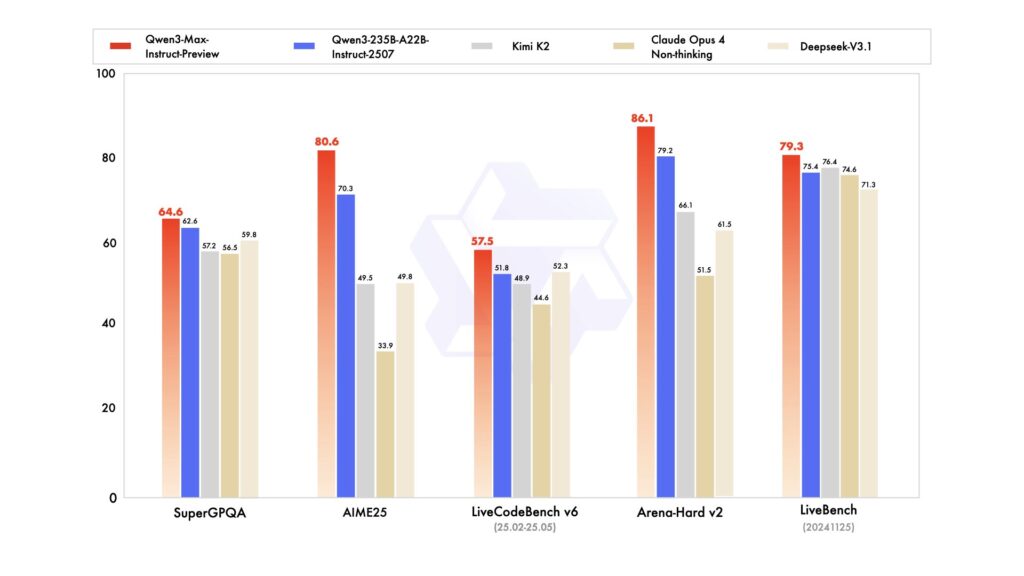
また、技術仕様としては最大入力258,048トークン・出力32,768トークン、最大文脈ウィンドウ262,144トークンをサポートし、コンテキストキャッシュ機能により対話の連続性も高速化されています。初期テストでは、応答速度も極めて速く、ChatGPTと比較して迅速に回答を返すとの報告も出ています。
さらに、コミュニティの検証では、算数や24パズルといった難問をGPT-5やGeminiより高い精度で解いたという報告も上がっていて、総合的な処理能力の向上が裏付けられています。


Qwen3-Max-Previewのライセンス
2025年9月9日現在で、Qwen3-Max-Previewはオープンソースではなく、Alibabaの有料APIまたは提携プラットフォーム経由でのみ利用可能なプレビュー版モデルです。したがって、モデル本体の入手や改変・再配布は許可されておらず、使用には、提供されるAPIを通じた許諾条件に従う必要があります。以下に主な利用形態ごとの可否をまとめます。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | 有料API経由で可能 |
| 改変 | ❌️ | |
| 配布 | ❌️ | |
| 特許使用 | ❌️ | |
| 私的使用 | ⭕️ |
上述の通り、現在は、API経由の商用/個人利用のみが認められており、モデルの改変や再頒布はできません。ただし、ライセンス形態は今後の正式リリースで変更される可能性があるので、最新情報は公式サイトなどで確認するようにしましょう。
Qwen3-Max-Previewの料金
Qwen3-Max-Previewの利用料金は、入力トークン数に応じた階層型の従量課金となっています。入力トークンが増えるほど単価が上昇していくイメージです。
| 入力トークン数 | 入力単価(100万トークン) | 出力単価(100万トークン) |
|---|---|---|
| 0-32k | $0.861 | $3.441 |
| 32k-128k | $1.434 | $5.735 |
| 128k-252k | $2.151 | $8.602 |
このように、短い入力では比較的低コストですが、トークン数が増えると料金が急増する仕組みとなっています。なお、Alibaba Cloudでは、新規ユーザー向けに初期180日間で100万トークンまで無料となる枠が提供されています。
利用にあたっては、想定する入力長に応じてコストを計算し、必要に応じてプロンプトの最適化やContext Cache機能の利用を検討するとよいと思います。


Qwen3-Max-Previewの使い方
Qwen3-Max-Previewは、公式チャットUIまたは、Alibaba Cloud Model Studioから利用することができます。
公式チャットUI
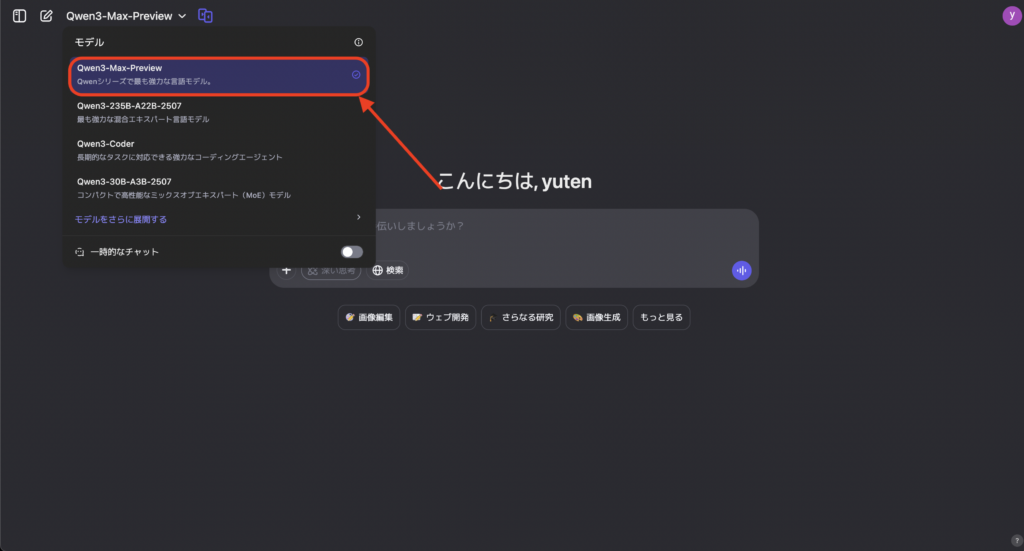
公式チャットUI(Qwen Chat)では、ウェブブラウザ上で会話形式のインターフェースにアクセスできます。
Qwen Chatへログイン後、モデル選択メニューから「Qwen3-Max-Preview」を選び、プロンプトを入力することで対話を開始できます。特別な設定は不要で、基本的な会話や指示出しを通じてモデルの性能を体感できます。
Alibaba Cloud Model Studio
Alibaba Cloud Model Studioを使う場合は、まずAlibaba CloudのアカウントでModel Studioにサインアップし、ダッシュボードでQwen3-Max-Previewモデルを選択します。
Playground画面では、Qwen3-Max-Previewを選んで直接対話を行うこともできますし、APIキーを取得してプログラムから呼び出すこともできます。公式ドキュメントには、Python用OpenAI互換SDK(DashScope)の利用例が掲載されており、例えば以下のようにモデル名を指定してリクエストを作成できます。
from openai import OpenAI
client = OpenAI(api_key="あなたのAPIキー", base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1")
completion = client.chat.completions.create(model="qwen3-max-preview", messages=[...])モデル名を「qwen3-max-preview」にすることで、Qwen3-Max-Previewへリクエストできます。
さらに、OpenRouterのようなOpenAI互換プラットフォームからも「qwen/qwen3-max」という名前で同モデルを呼び出すことができます。
Qwen3-Max-Preview vs GPT-5で比較検証してみた
今回はQwen3-Max-Previewの比較相手として、GPT-5-Thinkingを使っていきます。
難問数学タスク
プロンプト:
あなたは厳密採点に最適化された数学アシスタントです。
指示:思考過程は出力しないでください。各設問について最終解とごく短い根拠(20語以内)、信頼度(0〜1)のみをJSONで返してください。数式は TeX ではなく通常文字で表記し、数値は既約分数または小数(必要なら小数10桁以内)で示してください。
出力はJSONのみ、前後に余計な文言は出さないでください。
出力スキーマ
{
"task": "math",
"answers": [
{"id": "M1", "answer": "<number>", "rationale": "<<=20 words>", "confidence": 0.0},
{"id": "M2", "answer": "<number>", "rationale": "<<=20 words>", "confidence": 0.0},
{"id": "M3", "answer": "<number>", "rationale": "<<=20 words>", "confidence": 0.0}
]
}
問題
M1:整数の組
(
𝑥
,
𝑦
)
(x,y) が
𝑥
2
+
𝑦
2
=
45
2
x
2
+y
2
=45
2
を満たし、かつ
𝑥
≡
𝑦
(
m
o
d
3
)
x≡y(mod3) を満たす順序対の個数を求めよ。
M2:級数
𝑆
=
∑
𝑘
=
1
50
1
𝑘
(
𝑘
+
1
)
S=∑
k=1
50
k(k+1)
1
を正確に求めよ(既約分数で可)。
M3:級数
∑
𝑘
=
1
∞
1
𝑘
(
𝑘
+
1
)
(
𝑘
+
2
)
∑
k=1
∞
k(k+1)(k+2)
1
を正確に求めよ。
制約:中間計算手順の開示は禁止。数表記の曖昧な単位やテキストは入れないでください。Qwen3-Max-Previewの結果はこちら(出力まで7秒ほど)

GPT-5-Thinkingの結果はこちら(出力まで1分12秒)

どちらも数値としては全問正解(M1=12、M2=50/51、M3=1/4)ですが、表現と型が少しずつ異なっています。Qwen3-Max-Previewは answer を文字列で統一(”12″ / “50/51” / “1/4″)しているのに対して、GPT-5は混在(12 は数値、50/51 は文字列、0.25 は小数)しているのがわかります。出力としては統一されているQwen3-Max-Previewが1歩リードといったところですかね。
さらに、出力までの所要時間も圧倒的にQwen3-Max-Previewが速い印象でした。推論モードであるGPT-5-Thinkingモードを選択しているので、GPT-5側の時間がかかるのはもちろんありますが、Qwen3-Max-Previewの出力までのスピード感は圧倒的です。
24パズルタスク
続いて、コミュニティ検証されていた24パズルタスクについても試していきます。プロンプトは以下の通りです。
あなたは24ゲームのソルバーです。
指示:各セットの4つの整数をそれぞれ一度だけ使い、+ - * / と括弧のみでちょうど 24を作ってください。分数計算は可、累乗や階乗などは禁止。小数誤差は不可(厳密 24)。解がなければ "expression": "NO_SOLUTION" としてください。
出力はJSONのみ、前後にテキストを付けないでください。各セットごとに式と評価値を返してください。
出力スキーマ
{
"task": "24-game",
"results": [
{"id": "A", "numbers": [3,3,8,8], "expression": "<infix or NO_SOLUTION>", "value": 24},
{"id": "B", "numbers": [1,3,4,6], "expression": "<infix or NO_SOLUTION>", "value": 24},
{"id": "C", "numbers": [2,2,6,6], "expression": "<infix or NO_SOLUTION>", "value": 24}
]
}
ルール再掲
各数字はちょうど一度使用。
使用可能:+ - * / と括弧のみ。除算のゼロ割は禁止。
評価は厳密(分数可)。24 以外は不正解。
「思考過程の説明」は出力禁止。Qwen3-Max-Previewの結果はこちら(出力まで9秒ほど)

GPT-5-Thinkingの結果はこちら(出力まで40秒)

A、Bは両者正解ですが、CのGPT-5だけ誤りという結果でした。
Qwen3-Max-Previewの (6+6)*(2+2)/2 は4つの数字を各1回使って24になっているので正解。GPT-5の 62+62 は 数字をくっつけて「62」 にしているのでルール違反、しかも124なので誤答となっています。
コーディングタスク
最後にコーディングタスクについても試していきましょう。プロンプトは以下の通りです。
あなたはテスト自動採点前提のコーディングアシスタントです。
指示:Python 3.11で四則演算式評価器を実装してください。eval/ast.literal_eval の使用は禁止。シャントリングヤード法か等価アルゴリズムでパースし、+ - * / ^、括弧、単項マイナス、実数(小数点)を扱います。演算子の優先順位は ^(右結合) > * / > + -、括弧は最優先。除算は浮動小数。
出力はコードブロックのみ(Python)。説明文や余計なログは一切出さないでください。
要件
ライブラリ禁止(re は可)。外部依存なし。
関数シグネチャ:def eval_expr(s: str) -> float:
例外時は ValueError を送出(不正トークン、未閉括弧、ゼロ除算など)。
丸めはしない(内部は浮動小数、戻り値は float)。
ファイル末尾に簡易スモークテストを含め、if __name__ == "__main__": で以下を検証し標準出力に行ごとに結果のみを出力:
1+2*3 → 7.0
-3^2 → -9.0(単項マイナスは ^ より弱い)
(1-3/4) → 0.25
2^(3^2) → 512.0(右結合)
((3-8/3)) → - -? はパース可能か(例外なく評価できること)
1/0 は ValueError
出力フォーマット(厳守)
# コードのみ(説明やコメントは任意、ただし実行時に出力を汚さないこと)
禁止:思考過程の開示、ベンチマーク値の推定、外部APIやオンライン実行環境への依存。
目的:同一入力に対し、両モデルが正しくパーサを設計・実装できるか、境界条件・演算子結合規則・エラー処理を含めて比較可能にする。Qwen3-Max-Previewの結果はこちら
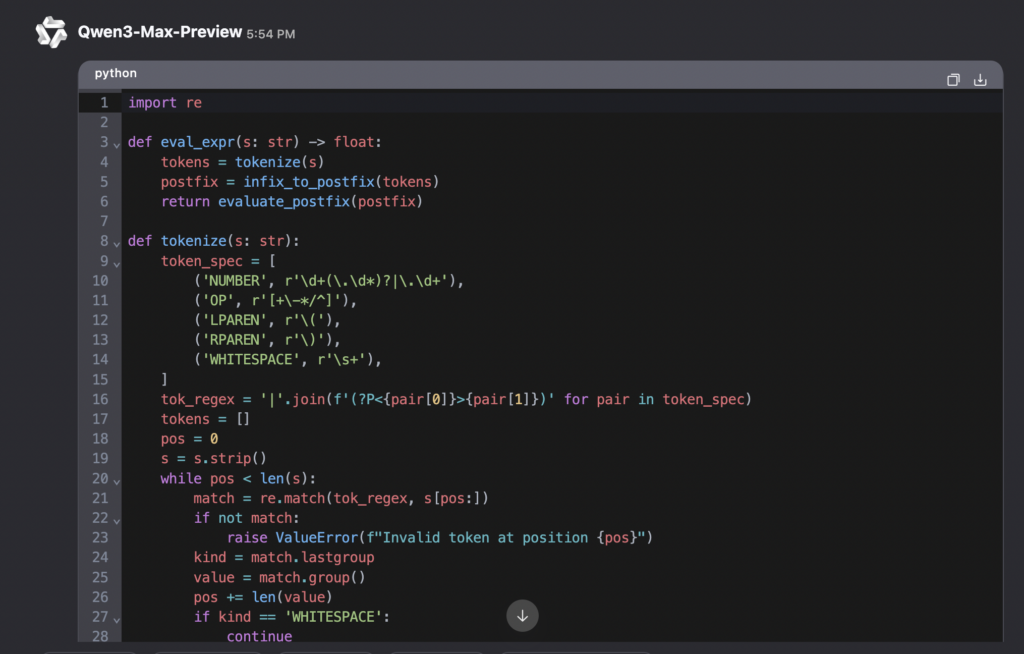
import re
def eval_expr(s: str) -> float:
tokens = tokenize(s)
postfix = infix_to_postfix(tokens)
return evaluate_postfix(postfix)
def tokenize(s: str):
token_spec = [
('NUMBER', r'\d+(\.\d*)?|\.\d+'),
('OP', r'[+\-*/^]'),
('LPAREN', r'\('),
('RPAREN', r'\)'),
('WHITESPACE', r'\s+'),
]
tok_regex = '|'.join(f'(?P<{pair[0]}>{pair[1]})' for pair in token_spec)
tokens = []
pos = 0
s = s.strip()
while pos < len(s):
match = re.match(tok_regex, s[pos:])
if not match:
raise ValueError(f"Invalid token at position {pos}")
kind = match.lastgroup
value = match.group()
pos += len(value)
if kind == 'WHITESPACE':
continue
elif kind == 'NUMBER':
tokens.append(('NUMBER', float(value)))
elif kind == 'OP':
tokens.append(('OP', value))
elif kind == 'LPAREN':
tokens.append(('LPAREN', value))
elif kind == 'RPAREN':
tokens.append(('RPAREN', value))
return tokens
def infix_to_postfix(tokens):
precedence = {'+': 1, '-': 1, '*': 2, '/': 2, '^': 3}
right_associative = {'^'}
output = []
stack = []
i = 0
while i < len(tokens):
token_type, value = tokens[i]
if token_type == 'NUMBER':
output.append(value)
elif token_type == 'OP':
if value == '-' and (i == 0 or tokens[i-1][0] in ['OP', 'LPAREN']):
# 単項マイナス処理
j = i + 1
while j < len(tokens) and tokens[j][0] == 'OP' and tokens[j][1] == '-':
j += 1
if j >= len(tokens) or tokens[j][0] not in ['NUMBER', 'LPAREN']:
raise ValueError("Invalid unary minus")
if tokens[j][0] == 'NUMBER':
num = tokens[j][1]
count_minus = j - i
if count_minus % 2 == 1:
num = -num
output.append(num)
i = j
else: # 括弧が続く場合
count_minus = j - i
is_negative = count_minus % 2 == 1
i = j
# 括弧内の式を再帰的に処理
paren_level = 0
start = i
while i < len(tokens):
if tokens[i][0] == 'LPAREN':
paren_level += 1
elif tokens[i][0] == 'RPAREN':
paren_level -= 1
if paren_level == 0:
break
i += 1
if paren_level != 0:
raise ValueError("Mismatched parentheses")
inner_tokens = tokens[start+1:i]
inner_postfix = infix_to_postfix(inner_tokens)
inner_value = evaluate_postfix(inner_postfix)
if is_negative:
inner_value = -inner_value
output.append(inner_value)
i += 1
continue
else:
while (stack and stack[-1] != '(' and
stack[-1] in precedence and
(precedence[stack[-1]] > precedence[value] or
(precedence[stack[-1]] == precedence[value] and value not in right_associative))):
output.append(stack.pop())
stack.append(value)
elif token_type == 'LPAREN':
stack.append('(')
elif token_type == 'RPAREN':
while stack and stack[-1] != '(':
output.append(stack.pop())
if not stack:
raise ValueError("Mismatched parentheses")
stack.pop() # pop '('
i += 1
while stack:
if stack[-1] in '()':
raise ValueError("Mismatched parentheses")
output.append(stack.pop())
return output
def evaluate_postfix(postfix):
stack = []
for token in postfix:
if isinstance(token, float):
stack.append(token)
else:
if len(stack) < 2:
if token == '-' and len(stack) == 1:
# これは通常起こらないはず(単項マイナスはトークン化で処理済み)
a = stack.pop()
stack.append(-a)
else:
raise ValueError("Insufficient operands")
else:
b = stack.pop()
a = stack.pop()
if token == '+':
stack.append(a + b)
elif token == '-':
stack.append(a - b)
elif token == '*':
stack.append(a * b)
elif token == '/':
if b == 0:
raise ValueError("Division by zero")
stack.append(a / b)
elif token == '^':
stack.append(a ** b)
if len(stack) != 1:
raise ValueError("Invalid expression")
return stack[0]
if __name__ == "__main__":
test_cases = [
"1+2*3",
"-3^2",
"(1-3/4)",
"2^(3^2)",
"((3-8/3))",
"1/0"
]
for expr in test_cases:
try:
result = eval_expr(expr)
print(result)
except ValueError as e:
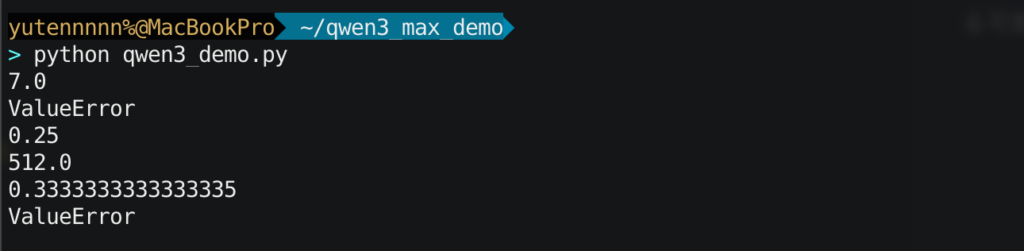
print("ValueError")上記コードの実行結果はこちら
GPT-5-Thinkingの出力結果はこちら
import re
from typing import List, Tuple, Union
Token = Union[float, str]
# Shunting-yard based evaluator with unary minus, ^ right-assoc, (), real numbers.
def eval_expr(s: str) -> float:
if not isinstance(s, str):
raise ValueError("Input must be string")
tokens = _tokenize(s)
rpn = _to_rpn(tokens)
return _eval_rpn(rpn)
# ---- Helpers ----
_num_re = re.compile(r"""
\s*(
(?:
(?:\d+\.\d*) | # 123. or 123.45
(?:\.\d+) | # .45
(?:\d+) # 123
)
)
""", re.VERBOSE)
_sym_re = re.compile(r"\s*([+\-*/^()])")
def _tokenize(s: str) -> List[Token]:
tokens: List[Token] = []
i = 0
n = len(s)
while i < n:
# number
m = _num_re.match(s, i)
if m:
tokens.append(float(m.group(1)))
i = m.end()
continue
# symbol
m = _sym_re.match(s, i)
if m:
tokens.append(m.group(1))
i = m.end()
continue
# whitespace?
if s[i].isspace():
i += 1
continue
raise ValueError(f"Invalid token at position {i}: {s[i:]!r}")
return tokens
# operator precedence and associativity
# Note: unary minus 'u-' is right-associative and has lower precedence than '^' but higher than * /
_OP_INFO = {
'+': (1, 'L', 2),
'-': (1, 'L', 2),
'*': (2, 'L', 2),
'/': (2, 'L', 2),
'^': (4, 'R', 2),
'u-': (3, 'R', 1),
}
def _to_rpn(tokens: List[Token]) -> List[Token]:
output: List[Token] = []
stack: List[str] = []
prev_type = 'START' # 'NUM', 'OP', 'LPAREN', 'RPAREN', 'START'
for tok in tokens:
if isinstance(tok, float):
output.append(tok)
prev_type = 'NUM'
continue
if tok in ('+', '-', '*', '/', '^'):
# determine unary minus
if tok == '-' and prev_type in ('START', 'OP', 'LPAREN'):
op = 'u-'
else:
if prev_type in ('START', 'OP', 'LPAREN'):
# Unary plus unsupported; binary op cannot follow another op/(
if tok != '-':
raise ValueError("Operator position invalid")
op = tok
p1, assoc1, _ = _OP_INFO[op]
while stack and stack[-1] != '(':
top = stack[-1]
p2, assoc2, _ = _OP_INFO[top]
if (assoc1 == 'L' and p1 <= p2) or (assoc1 == 'R' and p1 < p2):
output.append(stack.pop())
else:
break
stack.append(op)
prev_type = 'OP'
continue
if tok == '(':
stack.append('(')
prev_type = 'LPAREN'
continue
if tok == ')':
# pop until '('
found = False
while stack:
op = stack.pop()
if op == '(':
found = True
break
output.append(op)
if not found:
raise ValueError("Unmatched closing parenthesis")
prev_type = 'RPAREN'
continue
raise ValueError("Unknown token type")
# drain stack
while stack:
op = stack.pop()
if op == '(':
raise ValueError("Unmatched opening parenthesis")
output.append(op)
return output
def _eval_rpn(rpn: List[Token]) -> float:
st: List[float] = []
for tok in rpn:
if isinstance(tok, float):
st.append(tok)
continue
if tok not in _OP_INFO:
raise ValueError("Invalid operator in RPN")
_, _, arity = _OP_INFO[tok]
if arity == 1:
if len(st) < 1:
raise ValueError("Insufficient operands")
a = st.pop()
st.append(-a)
continue
# binary ops
if len(st) < 2:
raise ValueError("Insufficient operands")
b = st.pop()
a = st.pop()
if tok == '+':
st.append(a + b)
elif tok == '-':
st.append(a - b)
elif tok == '*':
st.append(a * b)
elif tok == '/':
if b == 0.0:
raise ValueError("Division by zero")
st.append(a / b)
elif tok == '^':
# Python's pow handles floats; ValueError for invalid domains left to float (not required here)
st.append(a ** b)
else:
raise ValueError("Unknown operator")
if len(st) != 1:
raise ValueError("Malformed expression")
return float(st[0])
if __name__ == "__main__":
tests = [
"1+2*3", # 7.0
"-3^2", # -9.0 (unary minus weaker than ^)
"(1-3/4)", # 0.25
"2^(3^2)", # 512.0 (right associative)
"((3-8/3))", # should parse without exception
"1/0", # ValueError
]
for t in tests:
try:
res = eval_expr(t)
print(res)
except ValueError:
print("ValueError")上記コードの実行結果はこちら
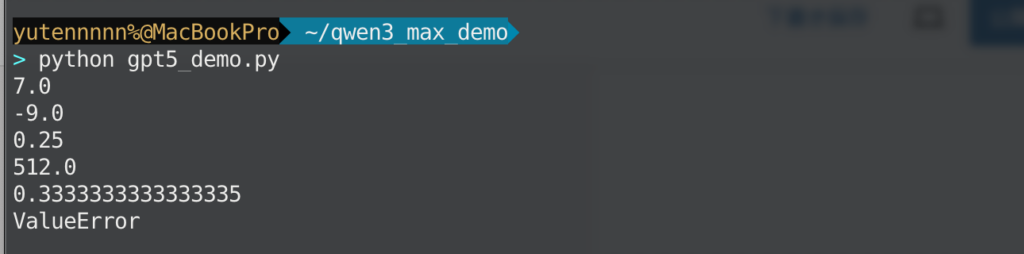
今回のコーディングタスクでは、GPT-5が6ケースすべて仕様どおりで満点。Qwen3-Max-Previewが1ケース失敗で減点となりました。
Qwen3-Max-Previewは、トークナイズの段階で -3 を「負の数」へ折りたたんでしまう実装になっていますね。
これだと -3^2 を (-3)^2 の形で解釈しやすくなってしまい、さらに、単項マイナス処理は
括弧のときにその場で部分式を評価する特殊ロジックが混ざっており、シャントリングヤードの
「演算子で順序だけ決める」という設計を崩しています。結果として ValueError が出ているものと思います。
以上3つのタスクにおいて、数学タスクではQwen3-Max-Previewがやや優勢、コーディングタスクはGPT-5がやや優勢といった結果になりました。ただ、どちらも1発出しの精度としては間違いなくハイレベルで、ちょっとした差だと思います。
まとめ
Qwen3-Max-Previewは、Alibaba Cloudが公開したQwenシリーズ最大級の言語モデルであり、1兆を超えるパラメータと262Kトークンの超長文脈対応により、翻訳・要約・コード生成・対話など広範なタスクで優れた性能を示しています。
公式ベンチマークでも先行モデルを上回り、多くのテストで上位にランクインしています。一方で現状はプレビュー版での提供形態のため、利用には有料APIを通じたアクセスが前提となり、モデルの改変や再頒布は基本的に許可されていません。
今後、正式リリースでの機能追加やライセンス変更にも期待しつつ、ぜひ一度本モデルを試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

