
VaultGemmaとは?Googleが発表した世界最大規模の差分プライバシー付きLLMの特徴と使い方

- VaultGemmaは世界最大規模の差分プライバシー付きオープンLLMで、安全性を最優先に設計
- 学習全過程でDPを適用し、個人データの逐語的記憶や情報漏洩を完全に防止
- 非DPモデルより性能は劣るが、GPT-2相当の実用性を持ち、研究・応用に利用可能
2025年9月12日、Googleが新たなオープンLLMを発表!
今回発表された「VaultGemma」は世界最大規模の「差分プライバシー(DP)付き」大規模言語モデルです。
VaultGemmaは学習の最初から最後までDPで訓練されており、個別のデータがモデルに過度に影響しないよう設計されています。
本記事ではVaultGemmaの概要から従来のLLMとの違い、使い方を解説します。本記事を最後までお読みいただければ、VaultGemmaの理解が深まります。ぜひ最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
VaultGemmaの概要
VaultGemmaは、Google ResearchとGoogle DeepMindが共同開発した世界最大規模の「差分プライバシー(DP)付き」大規模言語モデルです。
パラメータ数は約10億で、オープンウェイトで提供され、Hugging FaceやKaggleでも利用可能です。
VaultGemmaは学習の初期段階から終了に至るまで一貫して差分プライバシーを適用して訓練されており、その設計思想は個々のデータがモデルの挙動に不当に強く影響を及ぼさないようにする点にあります。
プライバシー保証については、1024トークンをひとまとまりとするシーケンス単位でεが2.0以下、δが1.1e-10以下という非常に厳格な基準を満たしており、このことが学習過程における情報漏洩のリスクを理論的に抑制。
実際に評価を行ったところ、VaultGemmaは訓練データを逐語的に記憶する兆候が一切見られず、差分プライバシーの仕組みが有効に機能していることが確認されています。
差分プライバシーについて
差分プライバシーは、2006年にMicrosoft ResearchのDworkらによって提案された数学的に定義されたプライバシー保護の枠組みです。目的は、データを分析・公開する際に、個人を特定できないようにしつつ統計的な有用性を維持することです。
差分プライバシーでは、集計や統計処理の結果に「ノイズ(乱数)」を数学的に制御して加えます。その結果、ある個人がデータセットに含まれているか否かにかかわらず、ほぼ同じ統計結果が得られるようになります。
また、攻撃者がどのような外部知識を持っていても、「その人のデータが入っているかどうか」は判別できない、という安全性を保証しており、識別不可能性の保証にもなります。


VaultGemmaの性能
下記グラフはVaultGemmaの性能を示しています。
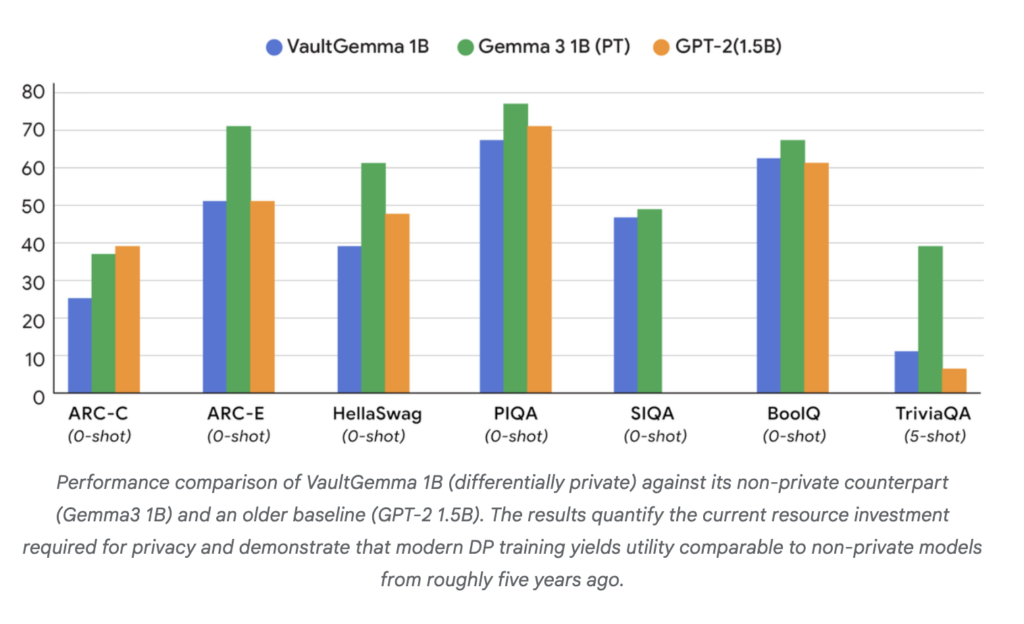
青のグラフがVaultGemmaを示しており、緑が非プライベートで最新世代のGemma 3 1B、オレンジが2019年頃に公開された旧世代モデル。
上記グラフからVaultGemmaは非プライベートで最新世代のGemma 3 1Bに性能は及ばないものの、GPT-2 1.5Bと同等の性能水準であることがわかります。
また、下記のグラフは異なるモデルにおける記憶率の比較です。
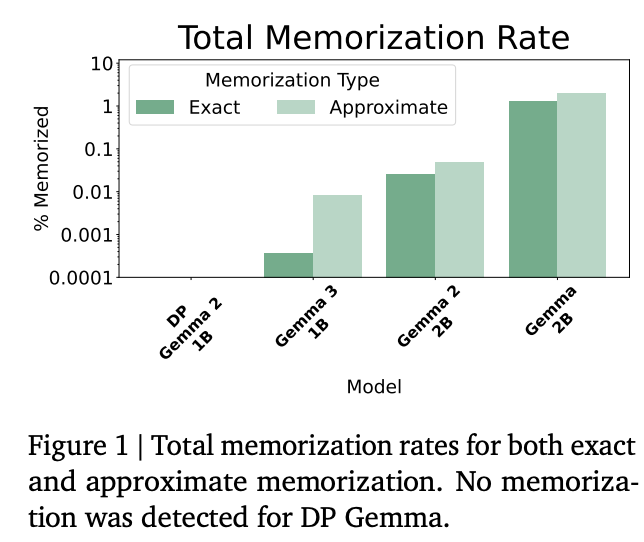
上記のグラフから、差分プライバシーを導入したVaultGemmaでは、訓練データの逐語的な漏洩が完全に防がれていること、非プライベートモデルはサイズが大きくなるほど記憶率が増え、情報漏洩リスクが高まること、DPは大規模LLMに特に重要な安全策であり、VaultGemmaはその有効性を実証しているということがわかります。


VaultGemmaのライセンス
VaultGemmaのライセンスはGemmaです。※1
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️※条件付き |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
上記はvaultgemmaのライセンスについてです。基本的には記載の内容は全て可能ですが、配布だけ注意が必要です。配布を行う場合には、以下の事項を明記する必要があります。
- 禁止用途(Prohibited Use Policy)の遵守を明記
- 再配布相手に本ライセンス全文の提供
- 変更したファイルには「改変済み」であることを明記
- 再配布時には “Gemma is provided under…” の注意文を含む「NOTICE」ファイルを同梱
なお、Google発の小型×高性能な埋め込みモデル「EmbeddingGemma-300m」について詳しく知りたい方は、下記の記事を合わせてご確認ください。

VaultGemmaの使い方
では実際にVaultGemmaを使っていきます。Hugging Faceにモデルが用意されていますが、Gated ModelのためHugging Faceのトークンが必要です。事前に取得しておきましょう。
まずはGitHubから開発版をインストールします。
!pip install git+https://github.com/huggingface/transformers@v4.56.1-Vault-Gemma-previewあとは実行です。
サンプルコードはこちら
import torch
from huggingface_hub import login
from transformers import AutoModelForCausalLM, AutoTokenizer
# Hugging Faceにログイン
login("hf_")
# モデルとトークナイザを読み込み
model_name = "google/vaultgemma-1b"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_auth_token=True)
model = AutoModelForCausalLM.from_pretrained(model_name, use_auth_token=True)
tokenizer.pad_token = tokenizer.eos_token
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
model.eval()
prompt = "差分プライバシーとは何ですか?"
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 推論
import torch
with torch.inference_mode():
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=True,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.3,
no_repeat_ngram_size=3,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.eos_token_id
)
print("---- with special tokens ----")
print(tokenizer.decode(outputs[0], skip_special_tokens=False))
print("---- clean output ----")
print(tokenizer.decode(outputs[0], skip_special_tokens=True))結果はこちら
---- with special tokens ----
<bos>差分プライバシーとは何ですか?
2019年、4月3日に同社が公開された「『未来の世界』」をリリースした。
この作品は日本語小説であることで話題になっており、『宇宙の世界』(英語:universe)に収録されているため、「第8巻から発表される」(NHK朝日総合局)- 「物語・ストーリーへの違い(英語版)」として発売する予定となるのは5th月の放送番組だとの考えとなったことと述べています。「人生の中の人たちの夢や魂が見つかるという価値観で生まれた人たちには何か違うものがあるだろう」。
しかしそれについてその存在感などについては批判していたこともあり、今回の読者にとってはあまり認識できないのだと思います。(ただし記事内であり得る内容もわかりました。)
<strong>【原作】</strong> <em>The Future of Worlds</em> is a Japanese short story by Takako Horiuchi. It was published in 76 issues on December, but has not been seen since March this year due to the coronavirus pandemic (Coronavirus). The issue includes an interview with Yōichi Nakai and other members from Japan’s Ministry for Foreign Affairs about their plans towards World War II. After that they explain how it will be different when we are back together again after COVID-19 ends
---- clean output ----
差分プライバシーとは何ですか?
2019年、4月3日に同社が公開された「『未来の世界』」をリリースした。
この作品は日本語小説であることで話題になっており、『宇宙の世界』(英語:universe)に収録されているため、「第8巻から発表される」(NHK朝日総合局)- 「物語・ストーリーへの違い(英語版)」として発売する予定となるのは5th月の放送番組だとの考えとなったことと述べています。「人生の中の人たちの夢や魂が見つかるという価値観で生まれた人たちには何か違うものがあるだろう」。
しかしそれについてその存在感などについては批判していたこともあり、今回の読者にとってはあまり認識できないのだと思います。(ただし記事内であり得る内容もわかりました。)
<strong>【原作】</strong> <em>The Future of Worlds</em> is a Japanese short story by Takako Horiuchi. It was published in 76 issues on December, but has not been seen since March this year due to the coronavirus pandemic (Coronavirus). The issue includes an interview with Yōichi Nakai and other members from Japan’s Ministry for Foreign Affairs about their plans towards World War II. After that they explain how it will be different when we are back together again after COVID-19 endsうーん、結果は芳しくありませんでした。
このあたりの調整は、次の検証で設定を変更しながら確認します。
パラメータなどを調整してVaultGemmaの出力が変化するか検証
前述のサンプルコードでは出力結果がイマイチな結果でした。そこで、パラメータなどを調整してVaultGemmaの出力がどのように変化するかを検証したいと思います。
まずは「do_sample=False」に変更した時の結果を見ていきます。
結果はこちら
---- with special tokens ----
<bos>差分プライバシーとは何ですか?
<h2><strong>1.</strong> <em><b>「</b></em></h2><h3>20歳未満の男性が、</h3><h3>35歳の女性(48)を契約する場合に、「</h4><h3>6年以上以上の高齢者」と称して約7割で働いている。</h3>
* 「会社は同業者が雇うことのない人です。」という理由から知られるためである。「そのうちも仕事をすることはできないので、自分の生活や社会への影響について相談します」。
<h4>【例】</h4><h5>・</h5><h6>1.</h6>まずは20日半間に3時間間経つことを確認し、当該人の年齢に応じて業務を行うことができませんか? それらは同じ場合はお答えください。(このときにはご質問下さい。)
▼画像:株式会社エジプト<eos>
---- clean output ----
差分プライバシーとは何ですか?
<h2><strong>1.</strong> <em><b>「</b></em></h2><h3>20歳未満の男性が、</h3><h3>35歳の女性(48)を契約する場合に、「</h4><h3>6年以上以上の高齢者」と称して約7割で働いている。</h3>
* 「会社は同業者が雇うことのない人です。」という理由から知られるためである。「そのうちも仕事をすることはできないので、自分の生活や社会への影響について相談します」。
<h4>【例】</h4><h5>・</h5><h6>1.</h6>まずは20日半間に3時間間経つことを確認し、当該人の年齢に応じて業務を行うことができませんか? それらは同じ場合はお答えください。(このときにはご質問下さい。)
▼画像:株式会社エジプト差分プライバシーの説明から大きく逸脱しています。
次に「temperature=0.3」に変えて生成の散らばりを抑制しつつ自然さを維持するように変更します。
結果はこちら
/usr/local/lib/python3.12/dist-packages/transformers/models/auto/tokenization_auto.py:1018: FutureWarning: The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/transformers/models/auto/auto_factory.py:492: FutureWarning: The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.
warnings.warn(
---- with special tokens ----
<bos>差分プライバシーとは何ですか?
<h2><strong>1.</strong> <em><b>「</b></em></h2><h3>20歳未満の男性が、</h3><h3>35歳の女性(48)を契約する場合に、「</h4><h3>6年以上以上の高齢者」と称して約7割で働いている。</h3>
* 「会社は同業者が雇うことのない人です。」という理由から知られるためである。「そのうちも仕事をすることはできないので、自分の生活や社会への影響について相談します」。
<h4>【例】</h4><h5>・</h5><h6>1.</h6>まずは20日半間に3時間間経つことを確認し、当該人の年齢に応じて業務を行うことができませんか? それらは同じ場合はお答えください。(このときにはご質問下さい。)
▼画像:株式会社エジプト<eos>
---- clean output ----
差分プライバシーとは何ですか?
<h2><strong>1.</strong> <em><b>「</b></em></h2><h3>20歳未満の男性が、</h3><h3>35歳の女性(48)を契約する場合に、「</h4><h3>6年以上以上の高齢者」と称して約7割で働いている。</h3>
* 「会社は同業者が雇うことのない人です。」という理由から知られるためである。「そのうちも仕事をすることはできないので、自分の生活や社会への影響について相談します」。
<h4>【例】</h4><h5>・</h5><h6>1.</h6>まずは20日半間に3時間間経つことを確認し、当該人の年齢に応じて業務を行うことができませんか? それらは同じ場合はお答えください。(このときにはご質問下さい。)
▼画像:株式会社エジプト前述の内容と大きな差はありません。次は固有名詞・日付の乱発を抑え、内容の一貫性を高めるために「top_p=0.8」に変更します。
結果はこちら
---- with special tokens ----
<bos>差分プライバシーとは何ですか?
<h2><strong>1.</strong> <em><b>「</b></em></h2><h3>20歳未満の男性が、</h3><h3>35歳の女性(48)を契約する場合に、「</h4><h3>6年以上以上の高齢者」と称して約7割で働いている。</h3>
* 「会社は同業者が雇うことのない人です。」という理由から知られるためである。「そのうちも仕事をすることはできないので、自分の生活や社会への影響について相談します」。
<h4>【例】</h4><h5>・</h5><h6>1.</h6>まずは20日半間に3時間間経つことを確認し、当該人の年齢に応じて業務を行うことができませんか? それらは同じ場合はお答えください。(このときにはご質問下さい。)
▼画像:株式会社エジプト<eos>
---- clean output ----
差分プライバシーとは何ですか?
<h2><strong>1.</strong> <em><b>「</b></em></h2><h3>20歳未満の男性が、</h3><h3>35歳の女性(48)を契約する場合に、「</h4><h3>6年以上以上の高齢者」と称して約7割で働いている。</h3>
* 「会社は同業者が雇うことのない人です。」という理由から知られるためである。「そのうちも仕事をすることはできないので、自分の生活や社会への影響について相談します」。
<h4>【例】</h4><h5>・</h5><h6>1.</h6>まずは20日半間に3時間間経つことを確認し、当該人の年齢に応じて業務を行うことができませんか? それらは同じ場合はお答えください。(このときにはご質問下さい。)
▼画像:株式会社エジプトこれも微妙なので、プロンプトの与え方を変えてみます。下記のように変更します。
prompt = (
"System: 日本語で簡潔に。定義→要点3つ→一文要約の順で答えてください。\n"
"User: 差分プライバシーとは何ですか?\n"
"Assistant: "
)結果はこちら
---- with special tokens ----
<bos>System: 日本語で簡潔に。定義→要点3つ→一文要約の順で答えてください。
User: 差分プライバシーとは何ですか?
Assistant: 10歳未満です!
I'm a student of the University. I have been studying for about two years now, and my main goal is to become an accountant by graduation in three months time! My major field would be accounting but it doesn’t seem like that much interest right? So what do you think should we study first before going into business school or university courses??<eos>
---- clean output ----
System: 日本語で簡潔に。定義→要点3つ→一文要約の順で答えてください。
User: 差分プライバシーとは何ですか?
Assistant: 10歳未満です!
I'm a student of the University. I have been studying for about two years now, and my main goal is to become an accountant by graduation in three months time! My major field would be accounting but it doesn’t seem like that much interest right? So what do you think should we study first before going into business school or university courses??期待通りの結果にならないため、日本語非対応の可能性を考慮し、英語で入力してみます。
プロンプトの与え方を下記のように戻します。
prompt = "What is differential privacy?"結果はこちら
---- with special tokens ----
<bos>What is differential privacy?
A. The ability to control the amount of information that can be shared between two people
B. A person’s right not only about what they share, but also how much and when it should change over time
C. An individual has a limited capacity for self-disclosure in order to protect their identity from others who might use or misuse this info<eos>
---- clean output ----
What is differential privacy?
A. The ability to control the amount of information that can be shared between two people
B. A person’s right not only about what they share, but also how much and when it should change over time
C. An individual has a limited capacity for self-disclosure in order to protect their identity from others who might use or misuse this info日本語訳はこちら
---- 特殊トークン付き ----
<bos>差分プライバシーとは何ですか?
A. 二人の間で共有できる情報の量を制御する能力
B. 個人が共有する内容だけでなく、その量や時間の経過に伴う変化についても持つ権利
C. 個人は、この情報を悪用する可能性のある他人から身元を保護するため、自己開示に制限を設ける能力を持つ<eos>
---- クリーン出力 ----
差分プライバシーとは何か?
A. 二人の間で共有できる情報の量を制御する能力
B. 個人が共有する内容だけでなく、その量や時間の経過に伴う変化についても権利を有すること
C. 個人は、この情報を悪用する可能性のある他者から身元を保護するため、自己開示能力に制限がある大きく改善したと判断できます!
技術レポートや公式サイトに目を通しても、日本語非対応とは記載がないのですが、ベンチマークなど基本的に英語で実施されているため、もしかしたら日本語が非対応なのかもしれません。
なお、ローカル利用可能なオープンウェイト推論モデルであるgpt-oss-120b/gpt-oss-20bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではVaultGemmaの概要から従来モデルとの違い、使い方について解説しました。検証の結果、日本語には対応しているものの出力が安定せず、使用はあまり推奨できないと判断しました。
ぜひ皆さんも本記事を参考にVaultGemmaを使ってみてください!

最後に
いかがだったでしょうか?
VaultGemmaを実際に試して、そのプライバシー保護性能と活用可能性を体感してみましょう。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

