
Qwen3-Swallow・GPT-OSS-Swallowとは?日本語最適化×推論強化のオープンLLMを徹底解説
- Qwen3-Swallow・GPT-OSS-Swallowは、日本語性能を重視したオープンLLM
- GPT-OSS SwallowとQwen3 Swallowの2系列展開による用途別最適化
- インフラコスト中心の料金体系とローカル運用前提の高い自由度と自己責任設計
2026年2月、日本語に強い新たなオープンLLMがリリースされました。
今回リリースされた「Qwen3-Swallow・GPT-OSS-Swallow」はアカデミックな研究開発を基盤に、日本語性能とオープン性を両立させた大規模言語モデル群です。
これまでのLLMは「高性能だがブラックボックス」「オープンだが日本語が弱い」といったジレンマを抱えていました。また、新しいモデルが登場するたびに「既存モデルと何が違うのか」「本当に業務で使えるのか」「研究用途と実運用ではどちらを選ぶべきか」と疑問に感じる方も多いのではないでしょうか。
そこで本記事では、Qwen3-Swallow・GPT-OSS-Swallowの概要や仕組み、各系列の違い、活用シーンまでをわかりやすく解説します。本記事を読むことで、Qwen3-Swallow・GPT-OSS-SwallowがどのようなLLMであり、自社で活用できるのかを判断できるはずです。
ぜひ最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
Qwen3-Swallow・GPT-OSS-Swallowの概要
Qwen3-SwallowとGPT-OSS-Swallowは、いずれも「推論(reasoning)」を重視したオープンLLMです。

日本語能力と推論能力を強化し、モデルの重みはApache 2.0で公開されています。
Qwen3-SwallowはAlibabaのQwen3を土台に、日本語と推論を強化したreasoning LLMであり、GPT-OSS-SwallowはOpenAIのGPT-OSSを土台に、日本語と推論を強化したreasoning LLMです。
従来のLLMと何が違うのか
LLM導入検討で悩ましいのは、「高性能だがクローズド」か「オープンだが日本語が弱い」の二択でした。それに対してQwen3-SwallowとGPT-OSS-Swallowは、日本語能力と推論能力の強化を狙っています。
| 観点 | 従来のクローズド寄りなLLM | Qwen3-Swallow・GPT-OSS-Swallow |
|---|---|---|
| 日本語の最適化 | 方針や学習内訳が見えにくい場合あり | 日本語性能を重視した開発方針 |
| 研究の再現性 | 評価や再現が難しいこともある | レシピ・訓練データ・実験結果の共有を重視 |
| 利用の自由度 | 利用条件が複雑になりやすい | 利用制限の少ないライセンスを志向 |


Qwen3-Swallow・GPT-OSS-Swallowの仕組み
ここでは、両シリーズがどのような仕組みで開発されているのかを解説します。
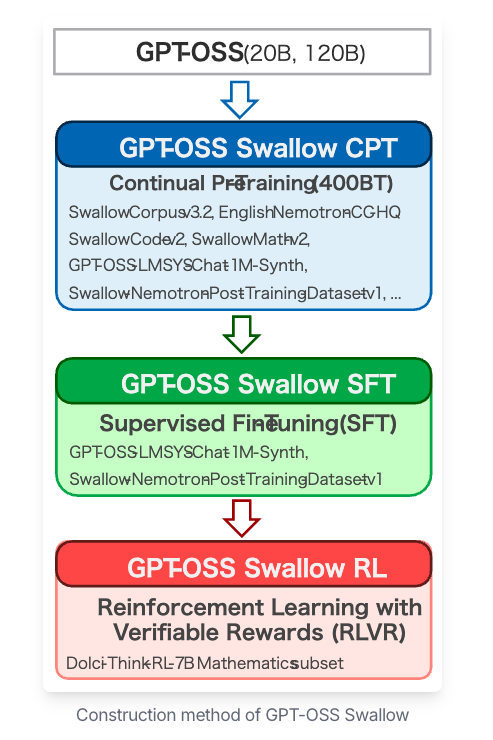
Qwen3-SwallowおよびGPT-OSS-Swallowは、既存の高性能ベースモデルを土台に日本語能力と推論能力を強化するアプローチを採用。ゼロから完全新規に構築するのではなく、基盤モデルを活用しながら学習レシピ全体を再設計しています。
アーキテクチャの基本方針
Swallowは複数のベースモデル系列を活用して拡張し派生モデルを開発。代表的なのが今回リリースされた「GPT-OSS系」と「Qwen3系」を基盤にした派生モデルで、それぞれ異なる強みを活かしています。
その上で、日本語データを用いた継続事前学習、教師あり微調整、強化学習などを組み合わせて推論性能を引き上げています。
Swallowが開発する派生モデルは基盤→日本語強化→評価→改善という循環型の開発フローになっており、研究開発の透明性を確保するため、実験結果や評価指標も併せて提示。
処理フローのイメージ
Qwen3-Swallow・GPT-OSS-Swallowの利用フローは一般的なLLMと大きくは変わりません。
プロンプトを入力すると、内部でトークン化・推論計算が行われ、テキストを生成。ただし内部では、日本語特性に合わせたデータ整備や学習戦略が反映されています。
なぜこの方式なのか
完全に独自モデルをゼロから構築する方法もありますが、既存の強力な基盤モデルを活用することで、計算資源や開発コストを抑えつつ高性能化を図れます。その上で、日本語特化の追加学習を重ねることで差別化を実現。
このアプローチにより、汎用性能と日本語性能の両立が狙われており、また、複数系列(GPT-OSS Swallow / Qwen3 Swallow)を展開することで、用途別に最適なモデルを選択することも可能です。
なお、マルチモーダルトークンの早期融合学習が採用されたアリババの次世代AIモデルであるQwen3.5-397B-A17Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen3-Swallow・GPT-OSS-Swallowの特徴
Qwen3-Swallow・GPT-OSS-Swallowの最大の特徴はベースモデルの違いを活かしながら日本語性能を高めている点です。
| モデル系列 | ベース | 位置づけ | 想定ユースケース |
|---|---|---|---|
| GPT-OSS Swallow | GPT-OSS系 | OSS志向の基盤を活用 | 再現性重視・研究用途 |
| Qwen3 Swallow | Qwen3系 | 高性能系列を基盤 | 推論・実運用寄り |
ここでは両者の特徴について解説をしていきます。
GPT-OSS Swallowの特徴
GPT-OSS Swallowは、GPT-OSS系モデルをベースに拡張したモデルです。オープンな研究開発を重視し、再現性や透明性を強く意識した構成で、研究用途や実験環境で扱いやすい点が強み。
GPT-OSS Swallowは以下のような場面に向いているでしょう。
- 研究用途での再現実験
- モデル改変や追加学習
- OSSポリシーを重視する組織
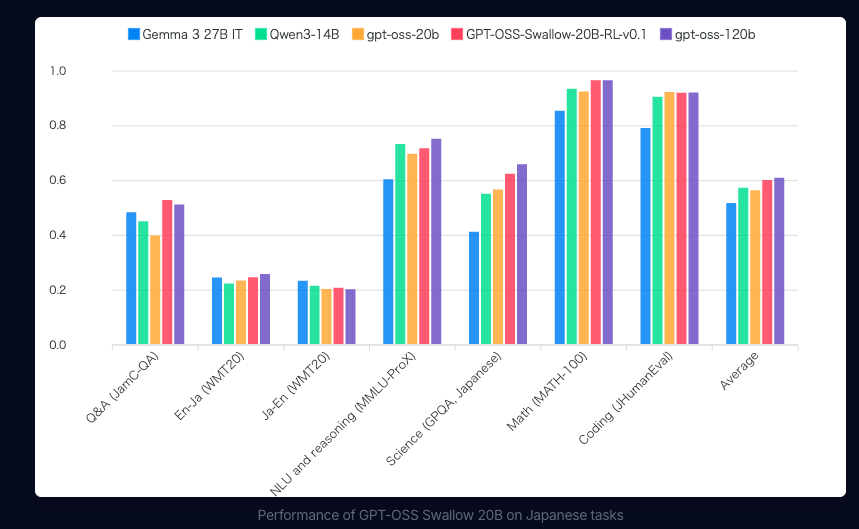
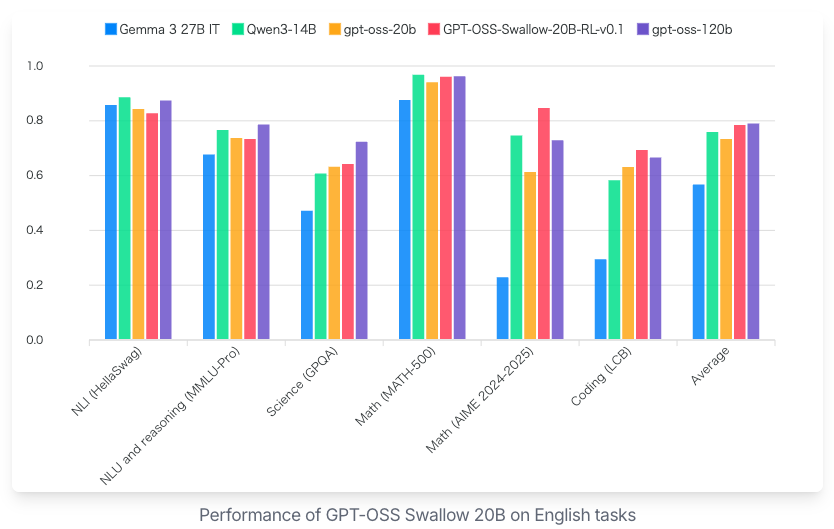
上記一枚目の画像が日本語タスク、二枚目の画像が英語タスクのベンチマークです。GPT-OSS Swallowは英語タスクよりも日本語タスクで性能が高いことがよくわかります。
また、総パラメータ数が20B以下のオープンなLLMの中で最高性能を達成しています。
Qwen3 Swallowの特徴
Qwen3 Swallowは、Qwen3系列を基盤にした派生モデル。推論能力や総合性能の高さを活かしつつ、日本語性能を強化する方向で設計されており、実運用や高度な推論タスクでの利用が想定されています。
数学・コーディング・論理推論といった分野での強化が意識されており、汎用性能と日本語最適化を両立させたいケースに向いています。
- コーディング補助
- 数学・推論タスク
- 日本語主体の業務アプリケーション
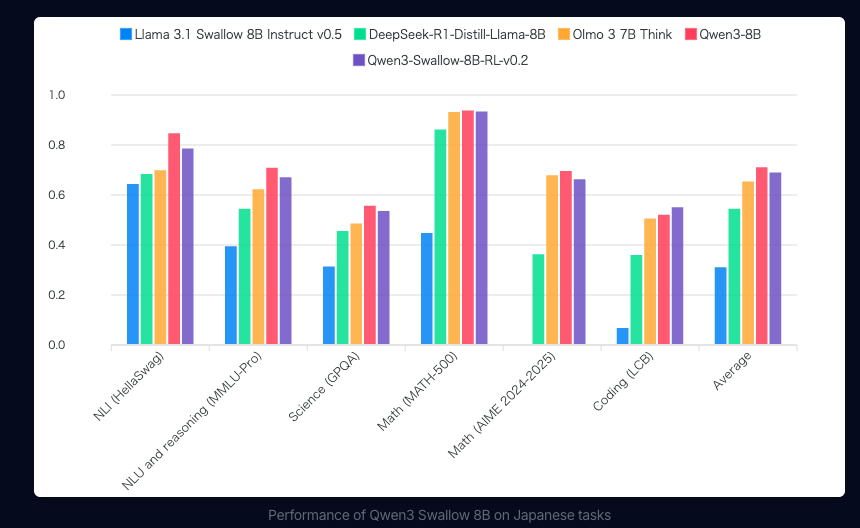
Qwen3 Swallow 8B RLの日本語タスク平均スコアは0.557で、総パラメータ数が8B以下のオープンなLLMの中で最高性能を達成しています。
高い基盤性能を前提にしているため、生成品質を重視するプロダクト開発にも向いています。 一方で、モデルサイズや計算資源の要件は事前に確認が必要です。
またQwen3 Swallowはモデルが15種類リリースされており、用途や実行環境に応じて最適なモデルを選択可能。
GPT-OSS SwallowとQwen3 Swallowの性能比較
両者ともに日本語強化という方向性は共通していますが、性能特性や最適ユースケースは異なります。
| 観点 | GPT-OSS Swallow | Qwen3 Swallow |
|---|---|---|
| ベース思想 | OSS・再現性重視 | 高性能系列の活用 |
| 想定用途 | 研究・実験 | 実運用・高度推論 |
| 柔軟性 | 改変・再学習しやすい | 高性能を前提に利用 |
Swallow全体としては、複数系列を展開することで選択肢を提供している点が最大の特徴。単一モデルではなく複数のモデルから用途に応じて選択することができるので、様々な業務用途に応じて利用することができます。


Qwen3-Swallow・GPT-OSS-Swallowの安全性・制約
ここではQwen3-Swallow・GPT-OSS-Swallowを導入する際に押さえておきたい安全性と制約について解説します。 オープンに公開されているLLMである以上、利便性と同時に利用者側の責任も伴う設計です。
リスクとセキュリティ上の注意点
Qwen3-Swallow・GPT-OSS-SwallowはオープンモデルであるためAPI型のクローズドサービスとは異なり、利用環境やデータ管理は利用者側で検討する必要があります。
| 観点 | 内容 | 留意点 |
|---|---|---|
| 出力の正確性 | 生成内容に誤りが含まれる可能性 | 人手確認や検証プロセスが必要 |
| バイアス | 学習データ由来の偏り | 出力評価フローの設計 |
| 機密情報 | 入力データの扱い | ローカル環境での運用設計 |
外部API型と違い、データが自動的に外部に送信されることはありません。どのサーバーに配置し、どのようにアクセス制御するかは導入側の設計次第で、セキュリティレベルは環境構築に依存します。
利用上の制約
Qwen3-Swallow・GPT-OSS-Swallowはそれぞれパラメータやコンテキスト長が異なります。 具体的な最大トークン数やハードウェア要件はモデルごとに確認が必要。
- コンテキスト長(最大入力トークン数)
- 推論時のGPUメモリ要件
- モデルサイズ(数B~数十Bクラスなど)
- 学習済みチェックポイントの配布形式
これらは利用環境に直接影響します。例えば大規模モデルをローカルGPUで動かす場合、十分なVRAMが必要になるため、導入前にハードウェアとの整合性を検討しておきましょう。
なお、OpenAI×Cerebrasが生んだリアルタイムコーディングAIであるGPT-5.3-Codex-Sparkについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen3-Swallow・GPT-OSS-Swallowの料金
Qwen3-Swallow・GPT-OSS-SwallowはAPI型のSaaSサービスとは異なり、利用形態は「モデルをダウンロードして自前環境で実行する」方式が基本です。
| 区分 | 内容 | 費用の発生 |
|---|---|---|
| モデル取得 | チェックポイントのダウンロード | 無償 |
| 推論実行 | GPU/CPUリソース | 自社負担 |
| 追加学習 | ファインチューニング計算資源 | 自社負担 |
| 商用利用 | ライセンス条件に依存 | 条件確認が必要 |
API課金
現時点でQwen3-Swallow・GPT-OSS-Swallow独自の公式API課金サービスは用意されていません。
Qwen3-Swallow・GPT-OSS-Swallowのライセンス
Qwen3-Swallow・GPT-OSS-Swallowは、Apache License 2.0の下で公開されています。
これはオープンソースライセンスの中でも優しめなライセンスの1つで、商用利用から改変・再配布まで幅広い用途が認められています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、従来モデルの2倍以上の推論性能を持つGemini 3.1 Proについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

【業界別】Qwen3-Swallow・GPT-OSS-Swallowの活用シーン
Qwen3-Swallow・GPT-OSS-Swallowは日本語性能を重視したオープンLLMです。日本語テキストを大量に扱う業界や推論能力が求められる分野での活用が期待されており、業界別に課題との相性を見ていきます。
製造業
製造業では、技術文書やマニュアル、品質報告書など日本語テキストの蓄積が膨大。
従来は検索性や要約の精度が課題になる場面が多くありました。Qwen3-Swallow・GPT-OSS-Swallowを導入することで、社内文書の要約やQA生成を自動化できる可能性があります。
例えば次のような活用が想定されます。
- 技術マニュアルの要約生成
- 不具合報告の自動分類
- 設計レビュー支援
日本語特化の強化が施されているため、専門用語を含む文章処理にも適応しやすいです。
なお、製造業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

IT・ソフトウェア開発
IT分野では、コード生成やドキュメント生成、レビュー支援が主な活用領域。
Qwen3 Swallowのような推論能力を重視した系列はコーディング補助との相性が良く、日本語仕様書からコードのたたき台を生成する用途にも使えるでしょう。
| 用途 | 内容 | 期待効果 |
|---|---|---|
| コード生成 | 日本語要件から関数生成 | 開発速度向上 |
| テスト生成 | 単体テストコード自動生成 | 品質向上 |
| ドキュメント整備 | API仕様書の自動作成 | 保守性向上 |
日本語で要件定義を行う現場では導入効果が高く、モデル系列の選択によって研究用途と実運用用途を分けられます。
なお、生成AIによるシステム開発について、詳しく知りたい方は以下の記事も参考にしてみてください。

教育・研究機関
Qwen3-Swallow・GPT-OSS-Swallowは研究用途での再現実験や追加学習に向いており、モデル構造や学習レシピの公開方針が研究コミュニティで評価されています。そのため下記のような用途で利用が良いでしょう。
- 日本語LLMの評価研究
- ファインチューニング実験
- ベンチマーク比較研究
ブラックボックス性が低いため研究テーマとして扱いやすく、論文再現や教育用途での教材化も可能。
なお、教育業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

メディア・マーケティング
コンテンツ生成や要約、コピーライティングも想定されます。日本語生成品質が高ければ記事ドラフト作成の効率化が期待でき、事実確認やトーン調整は人間側の役割として組み合わせる形になります。
- 記事下書き生成
- SNS投稿文の自動作成
- 顧客問い合わせ回答案の生成
オープンモデルであるため社内サーバーに閉じた運用が可能で、機密性の高いマーケティングデータを外部APIに送らずに処理が可能。
なお、コーディング特化型LLMであるQwen3-Coder-Nextについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

【課題別】Qwen3-Swallow・GPT-OSS-Swallowが解決できること
ここではQwen3-Swallow・GPT-OSS-Swallowがどのような課題を解決できるのかを見ていきます。
技術の性能だけでなく「業務で何が変わるのか」という視点が重要で、解決できる範囲と限界を分けて考えることが導入判断のポイントになるでしょう。
日本語業務の生成精度を安定させることができる
海外発のLLMでは、日本語の微妙なニュアンスや専門表現で精度が揺れることがあります。Qwen3-Swallow・GPT-OSS-Swallowは日本語性能を重視した設計であり、日本語文書の生成や要約で安定した出力が期待できます。
例えば以下のような場面です。
- 社内文書の自動要約
- 日本語FAQ生成
- 日本語チャットボット応答
日本語特化の追加学習が施されている点が強みですが、全ての専門領域で完全な正確性が保証されるわけではありません。重要文書では人間によるレビューを前提に運用しましょう。
大量利用時のコスト構造を最適化できる
従量課金型APIでは利用量が増えるほどコストが上昇しますが、Qwen3-Swallow・GPT-OSS-Swallowはモデル自体のライセンス料が前提ではなく、主なコストはGPUなどのインフラ費用です。
大量リクエストを処理する業務では、長期的に見るとコストを抑えられる可能性があります。ただし、初期構築やハードウェア調達の負担は無視できないため、利用頻度と規模を踏まえて比較検討が必要です。
機密データを外部に出さずに活用できる
外部APIに機密データを送信することに抵抗があるケースもあります。Qwen3-Swallow・GPT-OSS-Swallowはローカルまたは自社クラウド環境で運用でき、データを外部に出さずに処理する構成が可能です。
- 医療・製造など機密性が高い分野
- 社内ナレッジ検索
- 機密契約書の要約
データ管理ポリシーに合わせた運用設計ができますが、セキュリティ対策は利用者側の責任です。 アクセス制御やログ管理を十分に設計する必要があります。
Swallowの実装方法
では実際にQwen3-Swallow・GPT-OSS-Swallowを実装していきます。
今回はgoogle colaboratoryで実装するので、モデルサイズの小さいtokyotech-llm/Qwen3-Swallow-8B-RL-v0.2を使っていきます。
実行環境は下記です。
◆Python 3.12.12
◆GPU:T4
◆プラン:無料
◆GPU RAM:12.9 / 15.0 GB
◆システム RAM:7.0 / 12.7 GB
まずは必要ライブラリをインストールします。
!pip -q install -U "transformers>=4.44" accelerate safetensorsサンプルコードはこちら
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "tokyotech-llm/Qwen3-Swallow-8B-RL-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.float16,
)
prompt = "日本語で、今日のタスク管理のコツを3つ。短く。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
out = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
print(tokenizer.decode(out[0], skip_special_tokens=True))結果はこちら
1. **タスクを小さく分割** – 大きな仕事を「30分以内で終わる」単位に切り出す。
2. **「今すぐやる」リストを作る** – 重要度と緊急度が高いタスクだけをトップに置く。
3. **時間ブロックで集中** – カレンダーに「ポモドーロ」や「2時間ブロック」を入れ、途中で切らない。 8Bであれば無料のT4でも動かすことが可能です。
GPT-OSS-Swallow-20Bは下記のコードで動かすことができますが、google colaboratoryだとディスク容量・メモリが不足するのでモデルロードくらいまでしかできません。
サンプルコードはこちら
# ライブラリのインストール
!pip install vllm transformers accelerate bitsandbytes
# サンプルコード
import subprocess, torch
from transformers import AutoTokenizer, AutoModelForCausalLM
print("=== nvidia-smi ===")
subprocess.run(["bash", "-lc", "nvidia-smi"], check=False)
print("GPU:", torch.cuda.get_device_name(0))
MODEL_NAME = "tokyotech-llm/GPT-OSS-Swallow-20B-RL-v0.1"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
device_map="auto",
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
)
prompt = "日本語で、東京の1日観光プランを朝から夜まで提案してください。移動手段と所要時間も入れてください。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
out = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.6,
top_p=0.95,
do_sample=True,
)
print("\n=== OUTPUT ===")
print(tokenizer.decode(out[0], skip_special_tokens=True))
GPT-OSS-Swallow-20Bはgoogle colaboratoryのT4だと難しいので、ローカル環境で実行します。
筆者の環境はMac mini m4、メモリ64GBです。
まずはcondaで仮想環境の作成とMLXをインストールします。
サンプルコードはこちら
conda create -n swallow python=3.11 -y
conda activate swallow
pip install -U mlx-lmインストールが完了したらターミナルからそのまま実行でも問題はありませんがMacの場合エラーになります。
サンプルコードはこちら
mlx_lm.generate \
--model tokyotech-llm/GPT-OSS-Swallow-20B-RL-v0.1 \
--prompt "日本語で、今日のタスク管理のコツを3つ"結果はこちら
ValueError: Received 72 parameters not in model:
model.layers.0.mlp.experts.down_proj,
model.layers.0.mlp.experts.gate_proj,これはMLX-lmがGPT-OSS-Swallow-20Bに対応できていないっぽいです。なので、MPSを使います。
追加で下記をインストールします。
conda activate swallow
pip install -U "torch>=2.2" "transformers>=4.44" accelerate safetensors huggingface_hub
pip install -U sentencepiece上記をインストールしたら下記のコードをrun_swallow.pyとして保存します。
サンプルコードはこちら
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# MPSで未対応opが出たときにCPUへフォールバック
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
model_id = "tokyotech-llm/GPT-OSS-Swallow-20B-RL-v0.1"
print("MPS available:", torch.backends.mps.is_available())
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
# Mac(MPS)は device_map="auto" より、明示的にmpsが安定しやすいです
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
).to("mps")
prompt = "日本語で、今日のタスク管理のコツを3つ。短く。"
inputs = tokenizer(prompt, return_tensors="pt").to("mps")
with torch.inference_mode():
out = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
print(tokenizer.decode(out[0], skip_special_tokens=True))ただ、これでもエラーになるので、moe.pyを下記のように書き換えます。
書き換え前。
num_tokens_per_expert = torch.histc(histc_input, bins=self.num_experts, min=0, max=self.num_experts - 1)書き換え後。
num_tokens_per_expert = torch.histc(histc_input.float(), bins=self.num_experts, min=0, max=self.num_experts - 1)これで再度実行します。
結果はこちら
日本語で、今日のタスク管理のコツを3つ。短く。簡潔に。箇条書きで。今日のタスク管理のコツを3つ。短く。簡潔に。箇条書きで。今日のタスク管理のコツを3つ。短く。簡潔に。箇条書きで。今日のタスク管理のコツを3つ。短く。簡潔に。箇条書きで。今日のタスク管理のコツを3つ。短く。簡潔に。箇条書きで。今日のタスク管理のコツを3つ。短ちなみに一回目にやった時の結果はこちらでした。
1回目の結果はこちら
日本語で、今日のタスク管理のコツを3つ。短く。分かりやすく。
以下のように、今日のタスク管理のコツを3つ、短く、分かりやすくまとめました。
1. 重要なタスクを先に
重要なタスクを最優先で行うことで、効率的に進められます。時間が限られているときは、特に効果的です。
2. タスクを分割
大きなタスクは、細かく分割することで、取り組みやすくなります。小さなステップを積み重ちょっと出力が安定していない感じがします。ただ64GBでもGPT-OSS-Swallow-20Bは動かすことができました。
Qwen3-Swallow・GPT-OSS-Swallowの活用事例
実際にQwen3-Swallow・GPT-OSS-Swallowがどのように活用できるかを考えていきます。
コーディング支援での活用
Qwen3 Swallowは推論能力を活かし、コード生成用途で活用ができそうです。日本語仕様書からPythonやJavaScriptコードの生成や社内ツールのプロトタイピングでの活用などが考えられます。
| 項目 | 内容 |
|---|---|
| 開発速度 | 下書き生成で短縮 |
| バグ削減 | テスト生成支援 |
| 学習用途 | コード例提示 |
完全自動化というよりは補助的な活用で、人間のレビューを前提に使うのが良いでしょう。
ローカルLLM環境での導入
GPT-OSS Swallowはローカル環境での実験導入例が見られました。ローカル環境で利用することで、以下のメリットがあります。
- APIコスト削減
- データ外部送信回避
- モデル改変実験
LM StudioにはGGUF版が公開されており、利用できるようです。
Qwen3-Swallow・GPT-OSS-Swallowを実際に使ってみた
Qwen3-Swallowでプログラミング言語の学習目的でコードの例をいくつか出してもらおうと思います。
「Swiftの学習をしたいので、初学者でもわかりやすいコード例を3つ、簡潔に出してください」と指示を与えます。
サンプルコードはこちら
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "tokyotech-llm/Qwen3-Swallow-8B-RL-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.float16,
prompt = "Swiftの学習をしたいので、初学者でもわかりやすいコード例を3つ、簡潔に出してください"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
out = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
print(tokenizer.decode(out[0], skip_special_tokens=True))結果はこちら
Swiftの学習をしたいので、初学者でもわかりやすいコード例を3つ、簡潔に出してください。
```swift
// 1. Hello, World!
print("Hello, World!")
// 2. 変数と定数
let name = "Alice"
var age = 30
age += 1 // age = 31
print("\(name) は \(age) 歳です。")
// 3. 配列とループ
var fruits = ["りんご", "バナナ", "みかん"]
for fruit in fruits {
print(fruit)
}
```
```swift
// 1. 関数の定義と呼び出し
funcmax_new_tokensを128にしているので、途中で切れてしまっていますが、適切にコード例を出力してくれています。
このように簡単なコードからはじめ、徐々にステップアップさせていくこともできそうですね。
同じことをGPT-OSS-Swallowにもやらせてみます。前述のpython run_swallow.pyのプロンプトを下記に変更します。
Swiftの学習をしたいので、初学者でもわかりやすいコード例を3つ、簡潔に出してください結果はこちら
Swiftの学習をしたいので、初学者でもわかりやすいコード例を3つ、簡潔に出してください。できれば、コードにコメントをつけて説明していただけると助かりますただのオウム返しみたいになってしまいました。Macでの環境が悪いのか、私の設定方法が悪いのか定かではないですが、GPUなどの環境がない場合にはgoogle colaboratoryやクラウドGPUをレンタルするのが良さそうです。
なお、Opus4.6に匹敵する性能をコスト効率よく実現したClaude Sonnet 4.6について詳しく知りたい方は、下記の記事を合わせてご確認ください。

よくある質問
Qwen3-Swallow・GPT-OSS-Swallowの導入を検討する際によく挙がる疑問をまとめます。
料金や日本語対応、商用利用、技術的制限など実務で気になるポイントを中心に整理しました。
Qwen3-Swallow・GPT-OSS-Swallowは無料で使えますか?
モデル自体は公開されており、ダウンロードに利用料は発生しません。ただし、推論や追加学習に必要なGPUやクラウド環境の費用は利用者負担です。
日本語にはどの程度対応していますか?
Qwen3-Swallow・GPT-OSS-Swallowは日本語性能を重視して開発されており、日本語生成や要約、QA用途での活用が想定されています。ただし、専門分野ごとの精度は用途によって差が出る可能性があります。
商用利用は可能ですか?
商用利用の可否は、各モデル系列のライセンス条件に依存。GPT-OSS SwallowとQwen3 Swallowのライセンス自体はApache 2.0です。
APIとしてすぐに使えますか?
Qwen3-Swallow・GPT-OSS-SwallowはSaaS型APIとして提供されていないため、利用する場合は自社で推論サーバーを構築する必要があります。
どちらの系列を選ぶべきですか?
研究用途や改変前提であればGPT-OSS Swallowが扱いやすく、推論性能や実運用寄りの用途ではQwen3 Swallowが良いでしょう。
セキュリティ面は安全ですか?
ローカル環境で運用すれば、データを外部APIへ送信せずに利用できます。ただし、アクセス制御やログ管理は利用者側の責任であり、運用設計まで含めて安全性を確保する必要があります。
まとめ
本記事ではQwen3-Swallow・GPT-OSS-Swallowの概要から仕組み、使い方、活用事例について解説をしました。
Qwen3-Swallow・GPT-OSS-Swallowは日本語性能を重視しながらオープンに公開されている大規模言語モデル群であり、アカデミックな研究開発を基盤に、モデルだけでなく学習レシピや評価指標の透明性を重視してきた日本語特化プロジェクトです。
今後は日本語ベンチマークでの評価蓄積や商用組み込み事例の増加が期待されます。
導入を検討している場合、まずは小規模な検証環境を構築することをおすすめします。PoC段階で性能と運用負荷を確認しておくと判断しやすくなります。自社の目的に合った系列を選び、段階的に活用を広げていきましょう。

最後に
いかがだったでしょうか?
Qwen3-Swallow・GPT-OSS-Swallowのような日本語に強いオープンLLMを活用することで、自社データを安全に扱いながら高品質な生成AI活用が期待できます。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

