
【BitNet b1.58】1ビットでLLaMAよりも性能が優れているLLMを使ってみた

WEELメディア事業部LLMライターのゆうやです。
2024年2月28日、Microsoftから「BitNet b1.58」という大規模言語モデル(LLM)が公開されました!
このモデルは、なんと1ビットで推論するLLMであり、同じモデルサイズとトレーニングトークンの従来の16ビットモデルと比較して、同様かそれ以上の性能を実現しています。
つまり、この手法を用いれば、従来よりはるかに少ない計算リソースで高性能なLLMが構築できるということです!
この手法がさらに洗練され、浸透していけば、この論文の題名のような1ビットLLMの時代が到来するかもしれません。
今回は、公開された論文から、BitNet b1.58の概要や技術的な部分を解説します!
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
BitNet b1.58の概要
今回解説する「The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits」という論文では、従来のモデルと比較して、性能を維持したまま非常に効率的に動作する「BitNet b1.58」というモデルを構築しています。
参考論文:The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
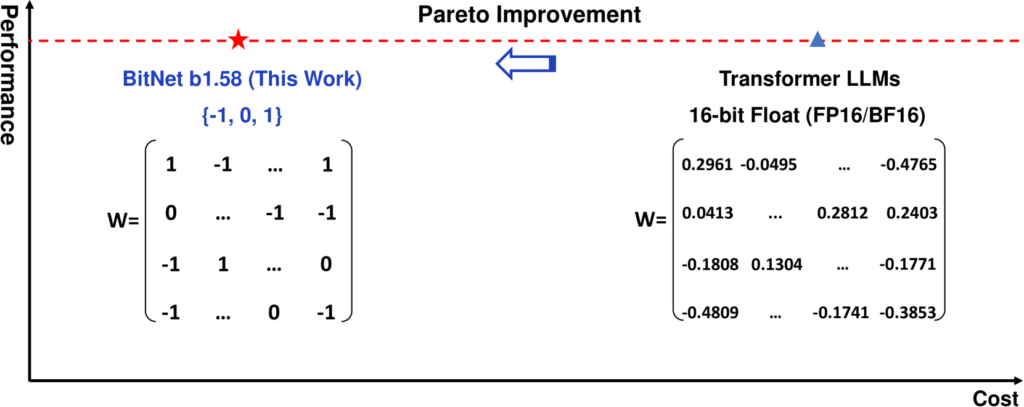
BitNet b1.58は、新世代の大規模言語モデル(LLM)であり、大規模言語モデルの新時代を切り開く新たな手法で構築されています。
このモデルは、従来の16ビットモデルと同等の性能を、はるかに少ない計算リソースで達成できることが特徴です。
具体的には、各パラメータが三値(-1, 0, 1)を取る1.58ビットのLLMであり、従来のモデルと比べて計算を簡単にしてメモリ使用量を減少させ、処理速度が向上させています。
わかりやすく説明すると、従来モデルは以下の画像のように、入力に対して様々な値をかけて足し引きする必要がありますが、1.58ビットモデルであれば、(-1, 0, 1)しか値がないので、足し算のみで計算が行えます。
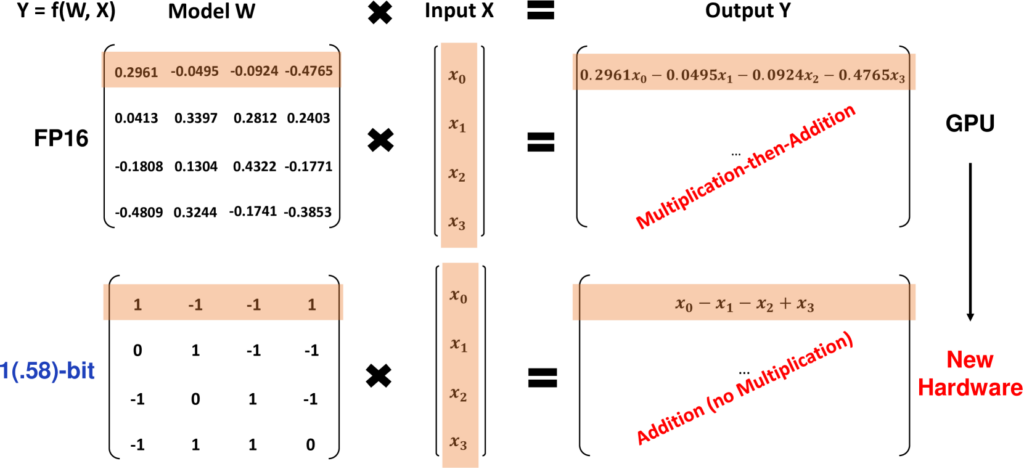
引用元:https://arxiv.org/html/2402.17764v1
これにより、従来の16ビットモデルと同じ結果を得るのに必要な計算リソースが大幅に減少するというわけです。
ちなみに、BitNet自体は以前から研究されていましたが、性能ではTransformersモデルに勝てないため、あまり話題になっていませんでした。
しかし、BitNet b1.58は、BitNetのパラメータに特徴フィルタリングを可能にする0を導入することで、性能を大幅に向上させ、従来モデルと同等の性能を出せるようになったことで一気に話題になりました。
この手法は、近年急速に増大しているエネルギー消費による環境および経済への影響を抑えることにもつながり、さらにはスマートフォンといったスペック上制限があるハードウェア上でも動作できるようになり、新たなサービスやアプリケーションの開発も可能になります。
この革命的な手法の登場で、論文のタイトルの通り、1ビットLLMの時代が到来するかもしれません!
ここからは、論文で紹介されているBitNet b1.58の性能について解説していきます。
なお、Microsoftの最強小型LLMであるPhi-2について知りたい方はこちらの記事をご覧ください。
→【Phi-2】パラメーター数が25倍のLlama-2-70Bと同等の性能を持つ、Microsoftの最強小型LLM
BitNet b1.58の性能
論文では、BitNet b1.58とFP16(16ビット) LLaMA LLMを様々なサイズで比較しています。
また、公平な比較を行うため、RedPajama データセット でモデルを1000億トークンで事前訓練しました。
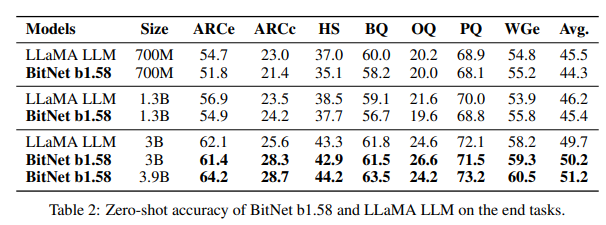
この比較検証では、以下の言語タスクでのゼロショットパフォーマンスを評価します。
- ARC-Easy:比較的簡単な科学的質問で、AIの科学的知識と推論能力を測定します。
- ARC-Challenge:より難しい科学的質問で、AIの科学的知識と推論能力を測定します。
- Hellaswag:与えられた物語やシナリオの次に起こる最も論理的な出来事をAIが予測する能力を測定します。
- Winogrande:文脈に基づいて単語の意味を理解し、常識的な判断ができるかをテストし、より微妙な言語のニュアンスと常識を理解する能力を評価します。
- PIQA (Physical Interaction Question Answering):物理的な世界の相互作用についての質問で、AIが物理的な事象をどれだけ理解しているかを測定します。
- OpenBookQA: 特定の知識領域に関する質問で、AIが「オープンブック」テストのように情報をどのように活用するかをテストします。これは、学習した知識をどれだけ効果的に使えるかを測るものです。
- BoolQ: Yes/No形式の質問で、AIがテキストをどれだけ正確に理解しているかを測定します。
また、WikiText2とC4データセットを用いて、パープレキシティ(PPL)の検証も行います。
- WikiText2:Wikipediaの記事から抽出されたテキストで構成されており、原文のマークアップや構造を保持しています。言語モデルのトレーニングや評価に適しています。
- C4データセット:インターネット上の様々なウェブサイトから収集されたテキストが含まれており、非常に広範囲なトピックと語彙をカバーしています。
パープレキシティ(PPL)とは、モデルがテキストをどれだけ「理解」しているか、予測する際の不確実性がどれくらいかを測定する指標です。
数値が低いほど性能が良いということになります。
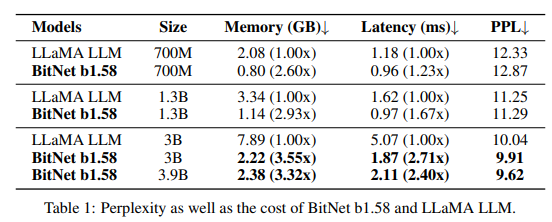
これらのタスクで比較検証を行った結果、以下の表のように特に3B、3.9Bモデルが、性能面も消費リソース面もLLaMA LLMに勝る結果になりました。
引用元:https://arxiv.org/html/2402.17764v1
1.3B以下のサイズの小さいモデルは、メモリ消費やレイテンシではLLaMA LLMに勝っていますが、肝心の推論能力では負けてしまっています。
3B、3.9Bモデルでは、推論能力を含むすべての指標でLLaMA LLMを上回りました。
特に、3.9BモデルはLLaMA LLM 3Bより大幅に高い性能を示しており、メモリ消費が3.32倍少ないことに加え、2.4倍高速で、かつ推論能力も上回っています。
この結果から、従来のモデルに対して数倍程度の効率化と、性能向上を同時に達成していることが分かり、まさにLLMの新時代を築くポテンシャルを持つ手法です!
本研究では、さらに大きなモデルを構築してコストを評価することも行っています。
その結果を項目別に紹介します。
メモリとレイテンシ
本研究では、モデルサイズを7B、13B、70Bとさらに拡大して、それぞれのメモリ消費量とレイテンシを計測して比較しました。
以下のグラフは、各サイズのBitNet b1.58とLLaMA LLMのメモリ消費量(上)とレイテンシ(下)を表したものです。
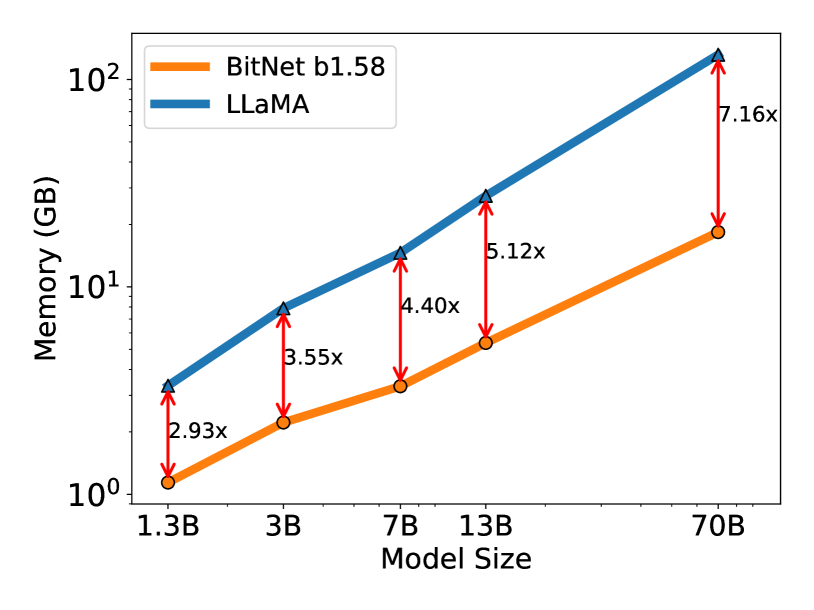
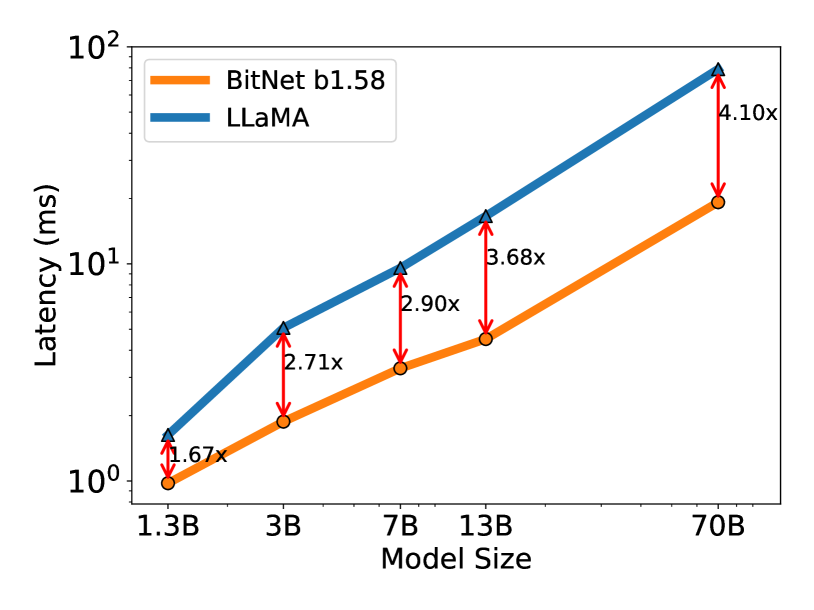
これらの結果から、モデルサイズが大きくなるにつれてメモリ消費の効率は大幅に向上し、BitNet b1.58 70BモデルではLLaMA LLM 70Bと比較してなんと7.16倍も消費量が少ないです。
また、レイテンシについても大幅に高速化しており、同様に70Bモデルで比較すると、4.1倍もBitNet b1.58の方が高速になっています。
これでも十分すぎるほどコストを削減で着ているように思えますが、まだコストを削減するための最適化の余地があると論文では述べられています。
これよりさらにコストが削減できるとは恐ろしい…
エネルギー消費
比較検証では、BitNet b1.58とLLaMA LLMの両方の算術演算エネルギー消費量も行っています。
BitNet b1.58は、LLaMA LLMと比較して行列乗算における算術演算エネルギー消費がなんと71.4倍も少ないという結果になりました!
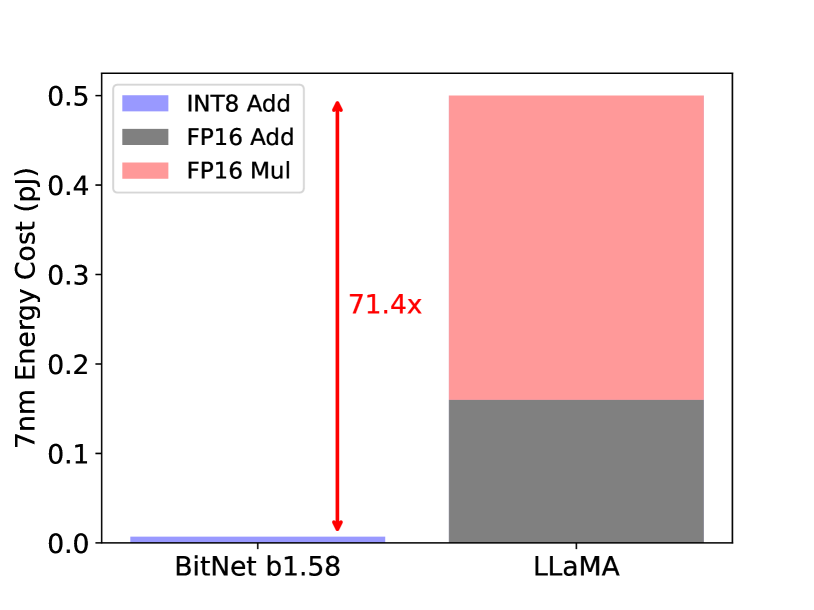
また、512 トークンを含むモデルのエンドツーエンドのエネルギーコストも比較し、モデルが大きくなるほどエネルギー効率が良くなることが示されました。
これは、計算で必要な部分(nn.Linear)の割合がモデルサイズに応じて増加する一方、モデルが大きくなると他のコンポーネントのコストが小さくなるからです。
スループット
BitNet b1.58 70BはLLaMA LLMと比較して最大11倍のバッチサイズをサポートでき、スループットが最大8.9倍高くなります。

引用元:https://arxiv.org/html/2402.17764v1
この結果は、BitNet b1.58は従来のモデルと同じ条件下でより多くのデータを高速で処理できることを示しています。
BitNet b1.58は、モデル性能と推論コストに関して新しいスケーリング法則を実現にします。
今回の比較検証の結果に基づき、1.58ビットと16ビットの異なるモデル・サイズの間に以下の等価性を持たせることができます。
- 13B BitNet b1.58は、3B FP16 LLMよりも、レイテンシ、メモリ使用量、エネルギー消費量の点で効率的です。
- 30B BitNet b1.58は、7B FP16 LLMよりも、レイテンシ、メモリ使用量、エネルギー消費量の点で効率的です。
- 70B BitNet b1.58は、13B FP16 LLMよりも、レイテンシ、メモリ使用量、エネルギー消費量の点で効率的です。
2Tトークンでのトレーニング
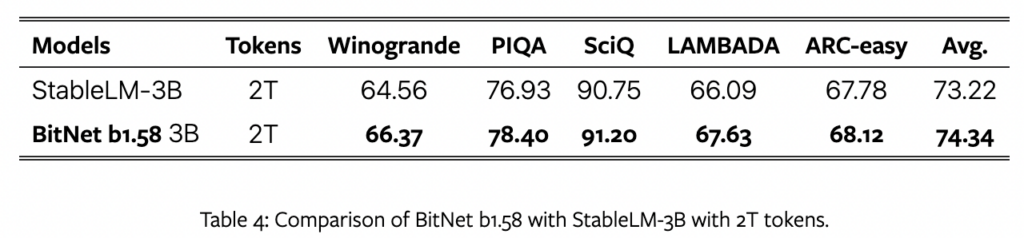
本研究では、最後にStableLM-3Bのデータレシピに従って、BitNet b1.58を2兆トークンでトレーニングし、Winogrande、PIQA、SciQ、LAMBADA、ARC-easyという5つのベンチマークでStableLM-3Bとの性能比較を行いました。
結果は、以下の表のように、全てのエンドタスクでBitNet b1.58の方が優れた結果を示し、BitNet b1.58の高い一般化能力(パターン認識などの機械学習をしたコンピューターによる、未学習の類似の問いについても正しい答えを導く能力)を持つことを示しています。
今回の比較検証の結果から、この手法は、まさにLLMの新時代を切り開くような画期的な手法であることが証明されました。
最後に、BitNet b1.58(1ビットLLM)の将来性について解説します。

BitNet b1.58(1ビットLLM)の将来性
BitNet b1.58(1ビットLLM)で実現できることと、今後の取り組みについて解説します。
Mixture-of-Experts(MoE)LLMの課題解決
Mixture-of-Experts(MoE)は、特定のタスクや問い合わせに最も適した「専門家」を選択して活用する高度な機械学習アーキテクチャの一種です。
MoEモデルは、より効率的かつ効果的に問題を解決できるという利点がありますが、メモリ消費量とチップ間通信のオーバーヘッドが高いため、その導入と応用が制限されています。
これらの課題は、1.58ビットLLMのエカニズムを適用することで解決できます。
具体的には、メモリフットプリントが削減されるため、MoE モデルの展開に必要なデバイスの数が減ります。さらに、ネットワーク間でアクティベーションを転送するオーバーヘッドも大幅に削減されます。
さらには、モデル全体を1つのチップ上に配置できれば、オーバーヘッドは発生しません。
1.58ビットLLMではこれが可能になります。
LLMでの長いシーケンスのネイティブサポート
現在、LLMは長いシーケンスを処理する能力を持つことが重要になっています。しかし、長いシーケンスつまり長文を処理する際はメモリ消費が増大してしまうことが課題です。
1,58ビットLLMは、アクティベーションを16ビットから8ビットに削減し、同じリソースでコンテキスト長を2倍にすることができるため、この課題を解決できます。
また、アクティベーション4をビット以下にする研究も行っており、さらなる高効率化が進むようです。
スマートフォン等の小型デバイス向けLLM
1.58ビットLLMは、メモリと計算能力に制限があるスマートフォン等のデバイス上でのLLMの性能を大幅に向上させる可能性があります。
これにより、これまでこれらのデバイスでは実現不可能だったようなアプリケーションが開発可能になり、私たちの生活を一変させる可能性があります。
1ビットLLM用の新しいハードウェア
GroqのようなLLM用の特定ハードウェア(LPUなど)の研究が行われていますが、かなり有望な結果と大きな可能性を実証しています。
そこでMicrosoftでは、BitNetで有効になっている新しい計算パラダイムに特化して最適化された新しいハードウェアとシステムの設計に向けた行動を呼びかけています。
この最適化されたハードウェアが開発されたら、BitNet b1.58(1ビットLLM)はさらに高性能、高効率を兼ね備えたモデルになることでしょう!
なお、Microsoftの小型LLMであるOrca-2-13bについて知りたい方はこちらの記事をご覧ください。
→【Orca-2-13b】Microsoftの最新小型LLMがLlama 2を超える性能を叩き出す
BitNet b1.58のライセンス
公式リポジトリのライセンスページによると、誰でも無償で商用利用することが可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ❌ |
| 私的使用 | ⭕️ |
BitNet b1.58の使い方
今回は、はちさんのnote記事を参考にして、Google Colabで実行していきます。
具体的には、既存日本語LLM「Swallow」のLinearを、BitNetに置き換えて推論させてみます。
まずは、以下のコードを実行して、ライブラリをインストールしましょう。
!pip install torch transformers sentencepiece accelerate protobuf
!pip install git+https://github.com/kyegomez/BitNet.git次に、以下のコードを実行して、Swallowのロードやプロンプトの設定をします。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from bitnet.replace_hf import replace_linears_in_hf
model_name = "tokyotech-llm/Swallow-7b-instruct-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, device_map="auto")
PROMPT_DICT = {
"prompt_input": (
"以下に、あるタスクを説明する指示があり、それに付随する入力が更なる文脈を提供しています。"
"リクエストを適切に完了するための回答を記述してください。\n\n"
"### 指示:\n{instruction}\n\n### 入力:\n{input}\n\n### 応答:"
),
"prompt_no_input": (
"以下に、あるタスクを説明する指示があります。"
"リクエストを適切に完了するための回答を記述してください。\n\n"
"### 指示:\n{instruction}\n\n### 応答:"
),
}
def create_prompt(instruction, input=None):
"""
Generates a prompt based on the given instruction and an optional input.
If input is provided, it uses the 'prompt_input' template from PROMPT_DICT.
If no input is provided, it uses the 'prompt_no_input' template.
Args:
instruction (str): The instruction describing the task.
input (str, optional): Additional input providing context for the task. Default is None.
Returns:
str: The generated prompt.
"""
if input:
# Use the 'prompt_input' template when additional input is provided
return PROMPT_DICT["prompt_input"].format(instruction=instruction, input=input)
else:
# Use the 'prompt_no_input' template when no additional input is provided
return PROMPT_DICT["prompt_no_input"].format(instruction=instruction)最後に、以下のコードを実行して、BitLinearに置き換え、「現在の日本の総理大臣は誰ですか?」と質問してみます。
# Replace Linear layers with BitLinear
replace_linears_in_hf(model)
model.to("cuda:0")
start_time = time.time()
instruction_example = "日本の総理大臣は誰ですか?"
prompt = create_prompt(instruction_example)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=128,
temperature=0.99,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
generation_time = time.time() - start_time
print(f"generation_time: {generation_time:.2f}")
output_speed = len(tokens) / generation_time
print(f"Output speed: {output_speed:.2f} tokens per second")回答結果は、以下の通りです。
応答:2023年2月現在、日本の総理大臣は岸田文夫です。
岸田は、2012年から2017年まで外務大臣を務め、2012年から2014年には衆議院議員を務めました。彼は2015年から2017年まで防衛大臣を務め、2017年から2021年まで外務大臣を務め、2018年から2019年には衆議院議員を務めました。BitNet b1.58を動かすのに必要なPCのスペック
こちらは、BitNet b1.58を動かした場合のスペックです。
■Pythonのバージョン
Python3.8以上
■使用ディスク量
22.07GB
■RAMの使用量
32.3GB
なお、70BLLMの性能を超えるMicrosoftの最強小型LLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Phi-2】パラメーター数が25倍のLlama-2-70Bと同等の性能を持つ、Microsoftの最強小型LLM
BitNet b1.58による高速な学習を試してみた
ここでは、BitNetで使われているBitLinearレイヤーを用いて、Titanicのテーブルデータセットを使った学習を行ってみます。そして、通常のNNとの性能比較を行ってみます。
まずは、以下のコードを実行して、通常のNormalModelと、BitLinearレイヤーを追加したBitNetを学習をさせ、比較しましょう。
%pip install bitnet
%pip install loguru
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import seaborn as sns
from bitnet import BitLinear
# データ前処理の関数
def preprocess_data():
df = sns.load_dataset('titanic')
df = df[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'fare']]
df['sex'] = df['sex'].map({'male': 0, 'female': 1})
df.dropna(inplace=True)
X = df.drop('survived', axis=1).values
y = df['survived'].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
return train_test_split(X_scaled, y, test_size=0.2, random_state=42)
X_train, X_test, y_train, y_test = preprocess_data()
# データをテンソルに変換
X_train_tensor = torch.tensor(X_train, dtype=torch.float)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
X_test_tensor = torch.tensor(X_test, dtype=torch.float)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# モデル定義の基本クラス
class BaseModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, LinearLayer, dropout_rate=0.5):
super(BaseModel, self).__init__()
self.fc1 = LinearLayer(input_dim, hidden_dim)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(dropout_rate)
self.fc2 = LinearLayer(hidden_dim, hidden_dim)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(dropout_rate)
self.fc3 = LinearLayer(hidden_dim, output_dim)
def forward(self, x):
x = self.dropout1(self.relu1(self.fc1(x)))
x = self.dropout2(self.relu2(self.fc2(x)))
x = self.fc3(x)
return x
# 通常のモデル
class NormalModel(BaseModel):
def __init__(self):
super(NormalModel, self).__init__(6, 64, 2, nn.Linear)
# BitNetモデル
class BitNetModel(BaseModel):
def __init__(self):
super(BitNetModel, self).__init__(6, 64, 2, BitLinear)
# 学習
def train(model, train_loader, X_test_tensor, y_test_tensor, num_epochs=2000):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
with torch.no_grad():
correct = 0
total = 0
outputs = model(X_test_tensor)
_, predicted = torch.max(outputs.data, 1)
total += y_test_tensor.size(0)
correct += (predicted == y_test_tensor).sum().item()
print(f'Accuracy: {100 * correct / total:.2f}%')
model = NormalModel()
train(model, train_loader, X_test_tensor, y_test_tensor)
model = BitNetModel()
train(model, train_loader, X_test_tensor, y_test_tensor)今回は、特に学習の工夫を行っていません。結果は以下の通りです。
- NormalModelのAccuracy:77.34
- BitNetのAccuracy:70.77
通常のNNの方が、7%ほど高かったです。また、学習スピードもほとんど変わらず、むしろNormalModelの方が少し速かったです。
やはり、ただレイヤーを置き換えるだけでは要領を得ないのかもしれません。使い方セクションでも参考にさせていただいたはちさんのnote記事でも、以下の様に述べられていました。
結論を先に述べますが、ただ置き換えただけだと使い物にならなかったです。やはり事前学習から行う量子化手法なんだと思います。
引用:https://note.com/hatti8/n/ndba2c57d87c5
今のところ、公式の実装は公開されていないです。そのため、今のうちにモデルの挙動などを確認するのが、重要なのかもしれません。
なお、Llama 2を超える小型LLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Orca-2-13b】Microsoftの最新小型LLMがLlama 2を超える性能を叩き出す
新世代のLLMとなりうるBitNet b1.58を今すぐ試そう
BitNet b1.58は、Microsoftが開発したLLMであり、16ビットモデルと同等の性能をはるかに少ない計算リソースで達成できる技術を採用しています。LLaMA LLMの70Bモデルと比較して、メモリ消費は7.16倍少なく、レイテンシは4.1倍高速で、行列乗算のエネルギー消費も71.4倍削減されています。
生成AI時代のエネルギー問題やGPU不足を、解決する可能性を秘めているそう。
検証では、「ただレイヤーを置き換えるだけでは要領を得ないだろう」という結果になりました。ただ、今のうちにモデルの挙動などを確認するのが重要になるでしょう。
ちなみに、あるXの投稿では、「1bit技術によって計算効率が良くなり、GPUが不要になるのではないか」という意見も見受けられます。
一方で、Qiitaの@tech-Miraさんの記事では、「筆者の見解」として、以下のように述べています。
1bitの技術を用いることで達成されたその驚異的なエネルギー効率の高さは、既存の大規模言語モデル(LLM)とは一線を画しています。この技術が今後のAI技術の発展にどのように影響を与えるかについては以降の発表がとても楽しみです。
一方で、「GPUが不要になるかもしれない」という意見に関しては、ある程度の限定的な視点からの意見と言えます。BitNet b1.58は、確かに従来の計算資源に依存しない新たな方向性を示していますが、これは主に推論時の処理においての話であり、モデルの構築や学習においては、GPUは依然として重要な役割を果たすことが予想されます。
引用:https://qiita.com/tech-Mira/items/67dec9c5a5f025d2727a
むしろ工場やIoTなどのオフライン環境においてのエッジコンピューティングやモバイルデバイスでのAIの利用拡大に大きな影響を与えるため、GPUの価値はより一層高まるのでは、と考えています。
BitNetの2bit技術を用いることで、推論においてはGPUが不要になるかもしれないが、学習においては依然としてGPUの価値は高いのではないか、とのこと。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

