
LangChainとは?料金・実装例までいま知るべきポイント総まとめ!
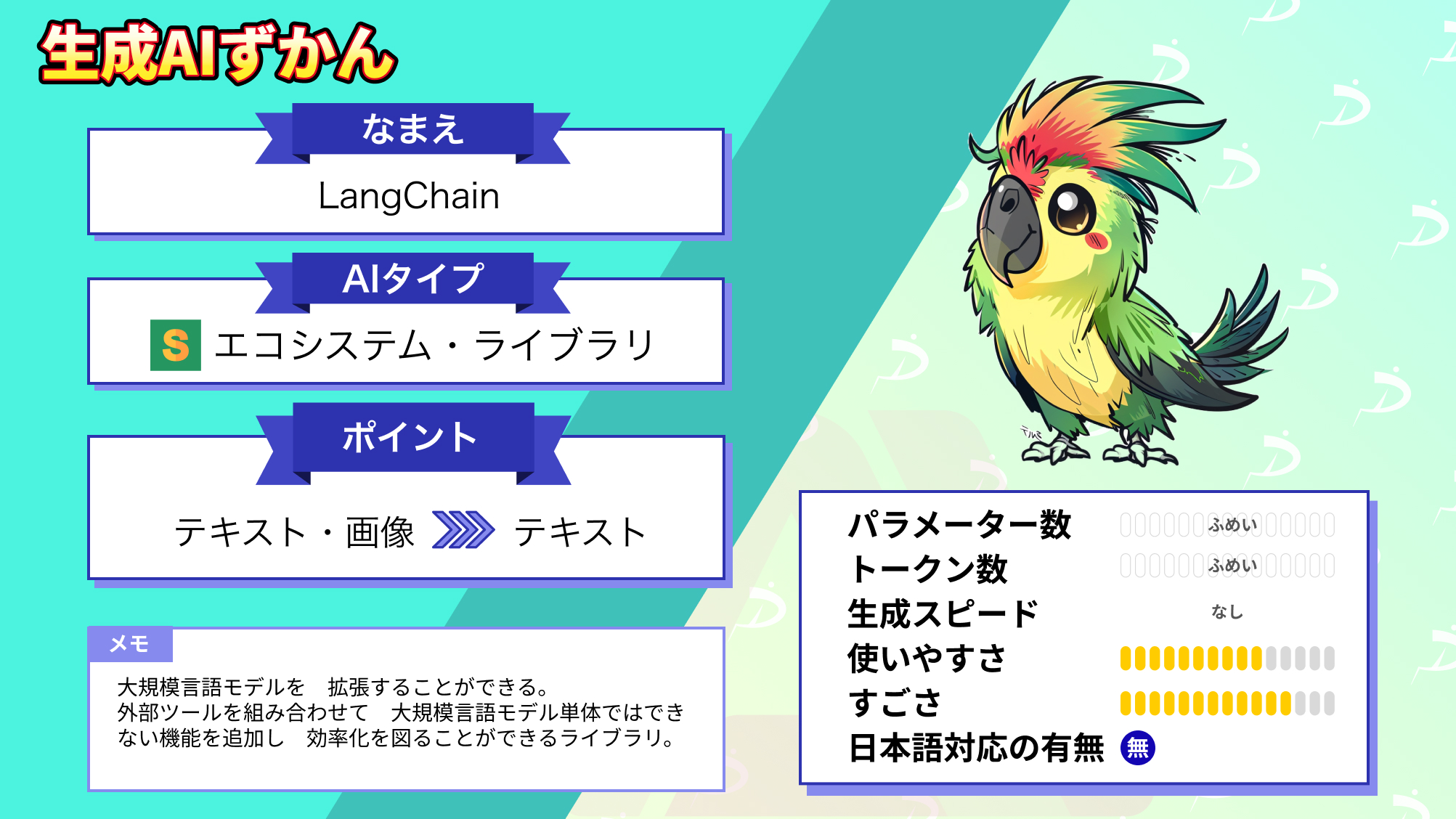
- LangChainとはデフォルトのLLM単体ではできない機能を追加して、効率化を高めるライブラリ
- 開発スピードの向上、ハルシネーションの抑制が見込める
- MITライセンスベースで公開されており、再配布や商用利用も可能
皆さんは、LangChainというライブラリをご存知でしょうか?
LangChainを使うことで、ChatGPTやClaude3といった生成AIの機能を高め、より実用的に使えるようになるのです。現代において生成AIは、プログラミングやWebライティングをはじめ、あらゆる業種において「なくてはならない存在」となっているのが現状。
他社よりもできる限り生成AIを有効活用したいですよね。そこで、ライブラリ「LangChain」の出番です!
今回の記事では、LangChainの概要や導入方法、実際に使ってみた感想をお伝えしていきます。本記事を一読することで、いつも使用している生成AIが見違えるほど高機能になり、生産性を格段にアップさせられます。
\生成AIを活用して業務プロセスを自動化/
LangChainとは
LangChainは、LLMを活用したアプリケーションやAIエージェントを構築するためのオープンソースフレームワークです。GitHubでも「framework for building agents and LLM-powered applications」と定義されています。
2025年にはLangChain v1.0およびLangGraph v1.0がリリースされ、初のメジャーバージョンに到達し、2026年3月時点ではlangchain 1.2.13、langgraph 1.1.3まで進んでいます。
ChatGPTなどの大規模言語モデル(LLM)と外部リソース(データソース、言語処理系)を組み合わせることで、ChatGPT単体ではできなかった機能を拡張させ、より高度なサービスが展開できます。
特定のタスクに特化させるという手段では、ファインチューニングという選択肢もありますが、LangChainならモデルに追加学習させることなく機能を追加できるのが魅力です。
ライブラリとは
プログラミングにおけるライブラリとは、よく使われる関数やクラス、設定ファイルなどをひとまとめにした「再利用可能な部品箱」のようなイメージです。
我々開発者は、自分で1からコードを書く代わりに、pipなどのパッケージマネージャーでインストールして、importするだけで高度な機能を呼び出すことができるというわけです。例えば、LangChainも「LLM を操作する」「ベクトル検索を組み込む」といった専門的な処理を部品として提供していて、私たちはその部品を自由に組み合わせてアプリを組み立てることができます。
ライブラリを使う最大のメリットは、開発スピードの向上とバグの削減です。動作する保証のあるコードを利用することで、短時間で安定した機能を実装でき、メンテナンスも公式アップデートを取り込むだけで済みます。
LangChainのライセンスと商用利用について
LangChainはMITライセンスで提供されており、配布や商用利用も可能になっています。詳しくはライセンスページをご確認ください。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕ |
| 改変 | ⭕ |
| 配布 | ⭕ |
| 特許使用 | ⭕ |
| 私的利用 | ⭕ |
LangChainの開発元
LangChainを開発したのは、機械学習スタートアップ企業Robust Intelligenceに勤務していたハリソン・チェイス(Harrison Chase)という人物です。
冒頭で紹介したとおり、2022年10月にオープンソースプロジェクトとして立ち上げられ、その後法人化しています。


LangChainで何ができるのか
ここでは、LangChainで何ができるのか気になっている方のために、基本的な6つの機能を紹介します。それぞれ一つの機能としてますが、機能全体を連携して動作させることも可能です。※1
LLMのカスタマイズ(Models)
Modelsとは、ChatGPTといったさまざまな大規模言語モデル(LLM)、チャットモデル、埋め込みモデルを同じインターフェース上で取り扱えるようにする機能です。これにより、モデル同士の組み合わせや、カスタマイズが実現でき、応用の幅が広がります。
外部データの検索・取得(Retrieval)
旧ドキュメントでは「Indexes」と呼ばれていた領域ですが、2026年3月現在はRetrievalという名称になっています。
Document Loaders(PDF・CSV・Webページなどの読み込み)、Text Splitters(文書の分割)、Vector Stores(ベクトルDBへの格納・検索)を組み合わせて、外部データをもとにLLMが回答を生成するRAGパイプラインを構築できます。
テンプレートでの効率化(Prompts)
Promptsは、言語モデルへの入力を生成するためのプロンプトの管理や最適期化を行うための機能です。LLMを使用したサービスを行う際には、プロンプトの機能を付け加える必要があります。LangChainのPromptsの機能によって、プロンプトテンプレートや統一された記述方法でコーディングが可能となり、実装コストを抑えることができます。
対話履歴の記憶(Memory)
Memoryは、ユーザーとの対話の履歴を記憶する機能です。これにより、過去の会話を参照して、より一貫性のある回答生成が可能となります。過去に言語モデルが出力した結果や回答履歴を記憶しておくことで、必要に応じて再び活用することができるようになるのです。
複雑な回答への対応(Chains)
Chainsは、一度の指示だけで複雑な回答生成が可能となる複数のプロンプトを実行できる機能です。一度指示したプロンプトから生成された回答をもとに、次のプロンプトが実行され、繰り返すことで高精度の回答を生成することができます。さらに、長い文章を分割して要約したり、要約した文章を一つにまとめるといった利用方法が可能となります。
複数ツールの連携(Agents)
Agentsは、複数の異なったツールを組み合わせて実行する機能です。検索エンジンツールと、グラフを生成するツールを組み合わせて活用するといった方法が可能となります。必要な情報だけを収集して正しいグラフを生成できるまで修正を繰り返してくれるので、正確なデータを効率よく取得できます。
上記の機能はいずれもLangChainを使わずとも、長いコードを使用すれば実践できます。しかし、LangChainならそれぞれの機能だけでなく全体に連携させて実践することができるため、時間の手間を省いて効率よく実用できるのでとても便利です。
LangChainのエコシステム全体像
2026年3月現在、LangChain社はOSS単体のライブラリだけでなく、複数のプロダクトを展開しています。
| プロダクト名 | 種別 | 役割 |
|---|---|---|
| LangChain | OSS(MIT) | LLMアプリ・エージェントを素早く構築するための基盤フレームワーク |
| LangGraph | OSS(MIT) | ・エージェントのワークフローを有向グラフで制御する。状態管理・永続チェックポイント・Human-in-the-Loopに対応し、本番向けの複雑なエージェント構築に適する |
| LangSmith | 有料サービス(無料枠あり) | トレース・デバッグ・評価・運用監視の可観測性プラットフォーム |
| Deep Agents | OSS | 2026年3月リリース。LangGraphランタイム上に構築されたエージェントハーネスで、計画ツール・サブエージェント生成・ファイルシステムによるコンテキスト管理に対応 |
LangChainを使うメリット
LangChainを使うメリットを大きく3つ取り上げてご紹介します。
開発スピードが飛躍的に向上する
LangChainでは、LLM呼び出し・埋め込み生成・ベクトル検索・外部ツール連携が1つのインターフェースに抽象化されています。コマンドで、from langchain_openai import ChatOpenAI とするだけで最新モデルへ接続することができますし、公式テンプレートをコピペしてパラメータを少し変えるだけで動かすことができます。
さらに、LangServeでチェーンをそのままFastAPI化できるため、バックエンドを待たずにフロント実装と並列開発が可能な点も強みです。
ハルシネーションを抑制し信頼性を確保
標準のRAGパイプラインは「ドキュメント分割→埋め込み→検索→回答」のフローを自動で実行し、クエリと同時に根拠文書をLLMへ渡します。これによって、ハルシネーションが大幅に減少しています。
v0.3系では、Structured Tool Callに対応し、モデルがJSONで引用URLや信頼スコアを返してくれるため、UIで1次ソースを提示するようなアプリを実装できます。また、検証フェーズにおいても、ファクトチェック用ログが自動で残るので、品質保証コストを圧縮できるのもポイントです。
運用・監視まで一気通貫で対応
LangSmithのトレース機能は、チェーンごとのトークン数・レイテンシ・エラーを自動記録する機能です。開発時に全量を収集して、本番では sampling_rate=0.1 に落とすだけで、可観測性を確保することができます。
LangGraphと組み合わせれば、エージェントの思考ステップをグラフ表示し、リトライやチェックポイント保存を数行で実装可能です。
LangChainの料金体系
LangChain自体はMITライセンスの無料OSSであり、フレームワークの利用に料金はかかりません。実際にコストが発生するのは、接続するモデルAPI(OpenAI、Anthropicなど)、検索API、ベクトルDB、そしてLangSmithといった周辺サービスです。API価格は随時変動するため、以下は参考値として公式サイトでの最新確認を推奨します。
本記事に記載しているLangChainのデモを動かすには、「OpenAI API」と「SerpAPI」のそれぞれのキーの取得が必要です。そしてそれぞれのキーの取得には、以下の料金がかかります。ただし、提示された無料の範囲であれば料金をかけることなく使用することが可能です。
OpenAI APIの費用
OpenAI APIは従量課金制となっています。利用するモデルによって入出力ともに費用が変わりますのでご注意ください。
| モデル | 入力 | 出力 |
|---|---|---|
| gpt-4o | $2.50/1M トークン | $10.00/1M トークン |
| gpt-4o-mini | $0.150/1M トークン | $0.600/1M トークン |
SerpAPIの費用
SerpAPIは無料プランがあるので、まずは無料プランで試してみることをおすすめします。
| プラン | 月額 | 検索数 |
|---|---|---|
| Free Plan | 無料 | 100検索 /月 |
| DEVELOPER | $75 /月 | 5,000検索 /月 |
また、Meta社のLlamaシリーズやGoogleのGemmaなど、ローカルで動作するオープンソースモデルを活用すれば、外部APIキーなしでもLangChainを使うことが可能です。Ollamaなどのツールと組み合わせれば、手元の環境だけで開発・検証を完結させることもできます。
LangChainを実際に使ってみた
LangChainはローカルでインストールし実行することもできますが、GoogleColabでも動かすことが可能です。
LangChainを実行するのに必要なスペック
今回、GoogleColabでLangChainを動かしてみました。その際の動作環境は下記の通りです。
- GoogleColab
- GPU:T4
LangChainをpythonで使う
では早速GoogleColab上でLangChainを使う準備をしていきましょう。
まず、LangChainとOpenAI APIをインストールします。
!pip install langchain
!pip install langchain-community
!pip install openai次に、OpenAI API KEYを設定します。
「*************」の部分は各自のAPI KEYを入力してください。
import os
os.environ["OPENAI_API_KEY"] = "*************"これで準備完了です。
では、LangChainの基本であるLLMを呼び出してみましょう。
from langchain.llms import OpenAI
# LLMを準備する
llm = OpenAI(temperature=0.9)
# LLMを呼び出し
print(llm.predict("今までにない全く新しい生成AIの名前を日本語で考えてください。"))生成結果はこちらです。
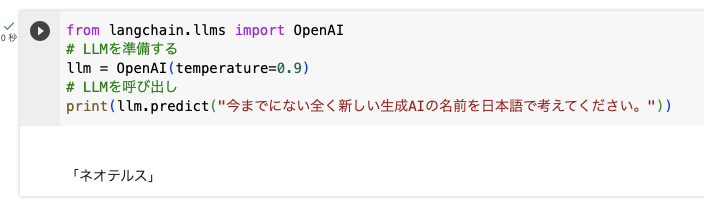
ネオテルス・・・!ナイスセンス!!
LangChainにGitHubリポジトリを学習させる
今度はLangChainにGitHubリポジトリを学習させてみます。LangChainとOpenAI APIをインストールするところまでは、上記の手順と同じです。
次にIndexesを使うためのライブラリをインストールします。
pip install chromadb
pip install tiktoken上記コードを入力して実行したあとは、GitHubリポジトリを読み込むためのライブラリのインストールしましょう。
pip install GitPythonあとは前述した手順と同じようにOpenAIのAPIキーを指定します。
その後、以下のコードを実行してLangChainに読み込ませるGitHubリポジトリのURLとブランチ名を準備、最後にqueryの部分に質問を入力してください。
import os
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.document_loaders import GitLoader
from langchain.llms import OpenAI
clone_url = "https://github.com/hwchase17/langchain"
branch = "master"
repo_path = "./temp/"
filter_ext = ".py"
if os.path.exists(repo_path):
clone_url = None
loader = GitLoader(
clone_url=clone_url,
branch=branch,
repo_path=repo_path,
file_filter=lambda file_path: file_path.endswith(filter_ext),
)
index = VectorstoreIndexCreator(
vectorstore_cls=Chroma, # Default
embedding=OpenAIEmbeddings(disallowed_special=()), # Default
).from_loaders([loader])
query = "質問を入力"
llm = OpenAI(temperature=0.9)
answer = index.query(query, llm=llm)
print(answer)LangChainの使い方
LangChainにはいくつか機能があるのですが、今回はその中の「Retrieval」と「Agents」を使ってChatGPTを拡張していきます。
LangChainのRetrievalの使い方
まず、LangChainのRetrievalを使ってPDFを読み込み、その情報をもとに回答を生成できるようにしましょう。
今回はRetrievalの中の機能のひとつである、PDFの長文を読み込んで検索する機能「Document Loader」を使ってみます。
LangChainとOpenAIのモデルを利用するので、環境構築としてGoogleColaboratoryでプロジェクトを立ち上げ、次のコマンドを入力して必要なパッケージなどをセットアップします。
基本となるlangChainとopenaiの他に、Documents Loaderを使用するためには次の3つのパッケージが必要になります。
- pypdf
- tiktoken
- faiss-cpu
まとめてインストールしてしまいましょう。
!pip install langchain
!pip install openai
!pip install langchain-openai
!pip install pypdf
!pip install tiktoken
!pip install faiss-cpu
次にOPENAI_API_KEYを設定します。「*****」の箇所は各自発行したKEYを入力してください。
import os
os.environ["OPENAI_API_KEY"] = "*******"
環境構築は、これで終了です。
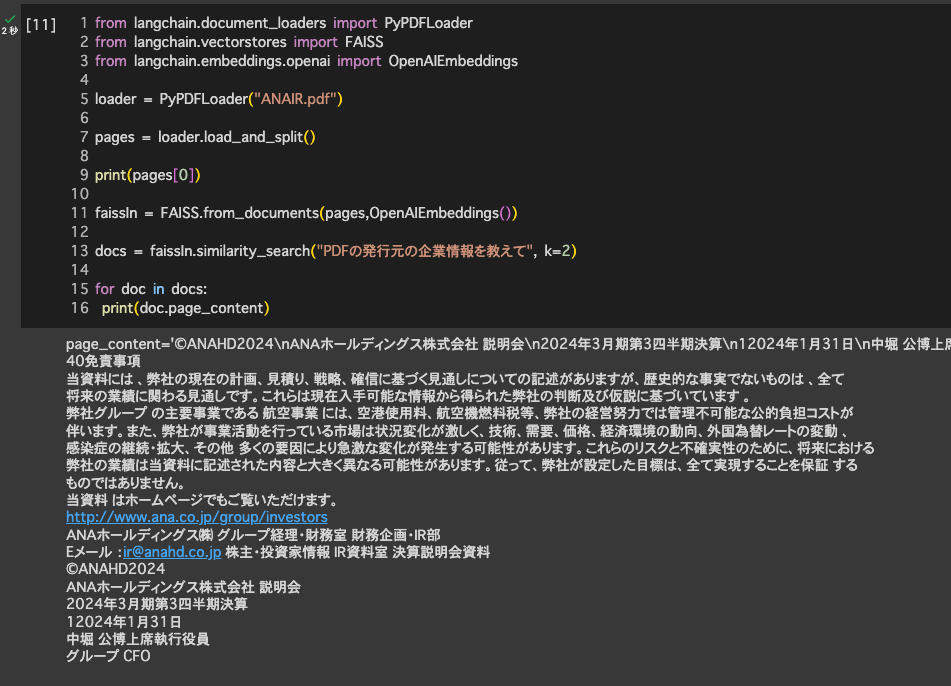
今回は仮に、航空大手ANAの決算情報のPDFファイルをダウンロードしてきて、「ANAIR.pdf」という名前でアップロードしました。
アップしたPDFファイルから企業情報を取得してもらいましょう。
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
loader = PyPDFLoader("ANAIR.pdf")
pages = loader.load_and_split()
print(pages[0])
faissIn = FAISS.from_documents(pages,OpenAIEmbeddings())
docs = faissIn.similarity_search("PDFの発行元の企業情報を教えて", k=2)
for doc in docs:
print(doc.page_content)実行結果は下記のようになりました。
LangChainのAgentsの使い方
次に、LangChainのAgentsを使ってインターネットの情報を利用してみましょう。今回は弊社のドメインから、会社名を検索して調べてもらい、その後、各種企業情報を取得してもらいます。
追加の設定
検索結果を取得するための追加パッケージと、SerpAPIのAPIキーを設定します。
!pip install google-search-results
import os
import pprint
os.environ["SERPAPI_API_KEY"] = "ここは各自取得したAPIキーを入力してください"
ドメインから会社名を取得
プログラムの全体は下記の通りです。
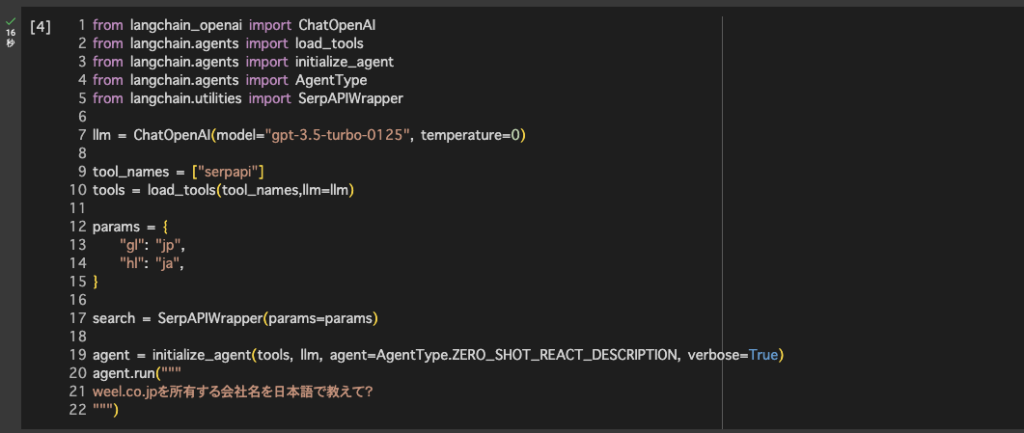
一つずつ解説していきますね。まず、from〜の部分で必要なagentやtoolをインポートします。
from langchain_openai import ChatOpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.utilities import SerpAPIWrapper次にChatGPTのモデルを指定します。
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)そして、Google検索機能を提供するツールである「SerpApi」を指定します。
tool_names = ["serpapi"]
tools = load_tools(tool_names,llm=llm)出力結果が英語になることもあるので、日本語で結果を返すパラメータを指定したSerpAPIWrapperを設定します。
params = {
"gl": "jp",
"hl": "ja",
}
search = SerpAPIWrapper(params=params)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("""
weel.co.jpを所有する会社名を日本語で教えて?
""")■結果
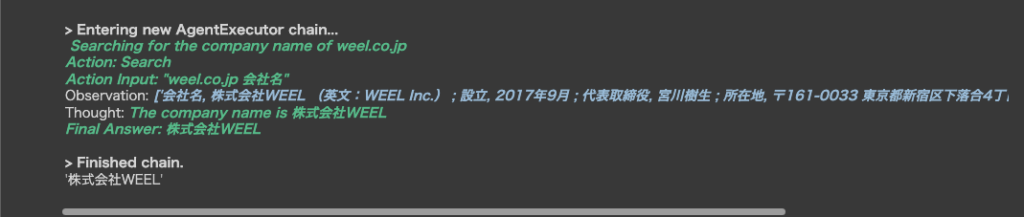
設立日を取得
会社名が株式会社WEELとわかったので、設立日を教えてもらいます。

上記の続きにagunt.run(“”)で追加のプロンプトを入力します。
agent.run("""
株式会社WEELの設立を教えて?
""")■設立日の取得結果

一番最初に「検索するのが早そう」というAIの感想が表示されて思わず笑ってしまいました・・・。
実行結果を見ているとAIが何を考えて検索しているのか、どういう情報を取得できてどうしたいのかなどを把握できるのでとても面白いですね。
さて、結果は「2017年9月に設立されました」と、しっかり情報が返ってきています!
資本金、業務内容を取得
同じ手順で株式会社WEELの資本金とサービス内容を取得してみましょう。
■資本金の取得結果
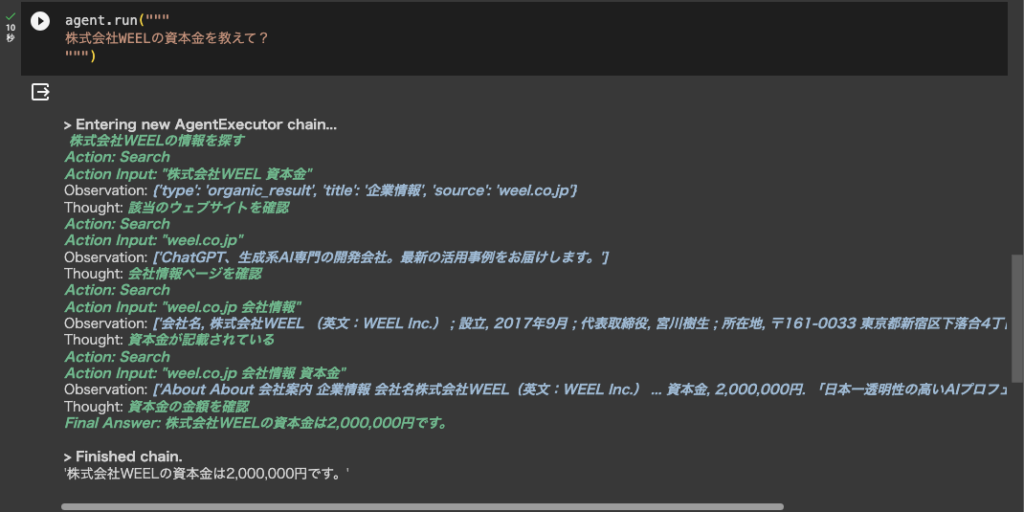
資本金の取得時には何度か検索を繰り返していますね。そして、ホームページのaboutから情報を取得したようです。
■業務内容の取得結果
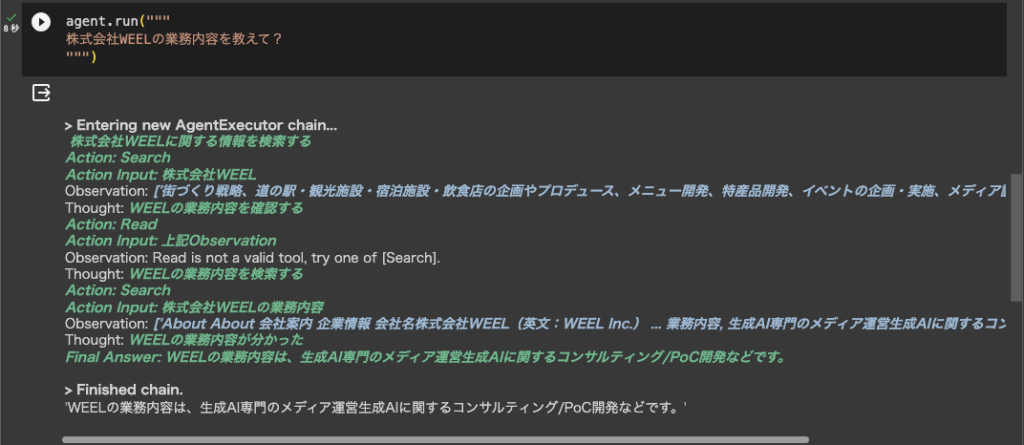
従業員数の取得
では最後に従業員数を取得してみます。
■従業員数の取得結果
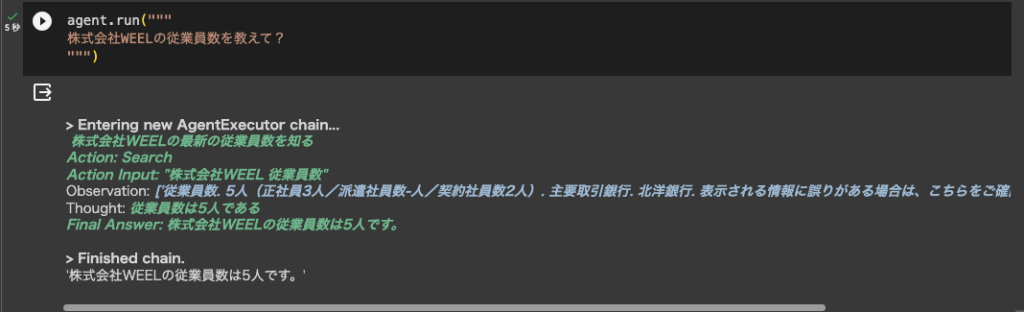
実は何度試してみても弊社の正確な従業員数を取得することはできませんでした。おそらく弊社ホームページ内の企業情報に従業員数が掲載されていないため、同名の別会社の情報を取得してきているのだと思われます。
LangChainを使ってChatGPTを拡張すると、インターネット上から最新情報を取得することができますが、こちらが意図していない結果を返してくることも度々あります。
LangChainのマルチモーダルRAGの使い方
次に、公式のGitに上がっているLangChainのマルチモーダルRAGを試してみました。
今回はPDFファイルからイメージとテキストを分離するというものをやってみます。
まずは必要なパッケージをインストールします。
! pip install -U langchain openai chromadb langchain-experimental
! pip install "unstructured[all-docs]==0.10.19" pillow pydantic lxml pillow matplotlib tiktoken open_clip_torch torch上記コードを実行したあと、セッションの再起動を求められるのでリスタートします。
セッションリスタート後、popplerとtesseractが必要になるので関連するパッケージをインストールします。
次に、PDFファイルを格納するディレクトリを作成し、パスを通します。
このディレクトリ内に、サンプルとしてpdf2.pdfというファイルを置いています。
使用したPDFは公式にもサンプルとして上がっていた下記のものです。
このようなポスターから、テキストだけをうまく抜き出すことができるのでしょうか・・・?

では、PDFからイメージとテキストを分離します。
クリックで表示
!pip install onnxruntime==1.15.1
!pip install nltk
import nltk
nltk.download('averaged_perceptron_tagger_eng') # Download the missing data
nltk.download('punkt')
nltk.download('punkt_tab')
!sudo apt-get update
!sudo apt-get install poppler-utils tesseract-ocr libtesseract-dev
!export PATH=$PATH:/path/to/tesseract
!pip install pytesseract
# Import the pytesseract library
import pytesseract
from unstructured.partition.pdf import partition_pdf
path = "./pdf/"
raw_pdf_elements = partition_pdf(
filename=path + "pdf2.pdf",
extract_images_in_pdf=True,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
image_output_dir_path=path,
# Specify the OCR language (e.g., 'eng' for English)
ocr_languages="eng"
)
tables = []
texts = []
for element in raw_pdf_elements:
if "unstructured.documents.elements.Table" in str(type(element)):
tables.append(str(element))
elif "unstructured.documents.elements.CompositeElement" in str(type(element)):
texts.append(str(element))
print(texts)以下が出力結果です。

順番はバラバラですが、PDFファイル内のテキストを抽出し出力することができました。
LangChainで最新モデルを指定する方法
LangChainをOpenAIのモデルと連携する際は、ChatOpenAIのmodel引数にモデルIDを指定します。環境構築とOPENAI_API_KEYの設定が完了したら、以下のコードを入力してください。
ChatOpenAI(model='gpt-5')LangChainとLlamaIndexの違い
LangChainとよく比較されるフレームワークにLlamaIndexがあります。比較表でそれぞれの特徴を整理しておきましょう。
| 比較項目 | LangChain | LlamaIndex |
|---|---|---|
| 主な強み | エージェント構築・ツール連携・ワークフロー制御 | データ接続・RAG構築・検索精度の最適化 |
| エージェント機能 | LangGraphによる高度な状態管理・グラフ制御 | LlamaIndex Workflowsによるイベント駆動型パイプライン |
| ドキュメントローダー | 100以上の外部サービス対応 | 100以上のフォーマット対応、LlamaHubで拡張可能 |
| 監視・評価 | LangSmithで一気通貫対応 | 外部ツール連携が基本 |
| 向いているケース | 複数ツールを使うエージェント、本番重視のアプリ | RAG中心、検索精度が最重要の用途 |
生成AIの機能を拡張できるLlamaIndexについて知りたい方はこちらをご覧ください。

Llamaindexを使った開発について知りたい方はこちらをご覧ください。

LangChainを使う上での課題・注意点
LangChainは便利ですが、油断すると思わぬコストやバグを招きます。ここでは、代表的な落とし穴を3つ挙げ、その回避策を簡潔に説明しますので、参考にしてください。
依存関係の衝突とバージョン迷子
LangChain v0.3系は、Pydantic v2系を前提とするため、旧版ライブラリが混在している環境では ImportErrorが発生してしまいます。pip install -U langchain –upgrade-strategy eager で依存を一括更新して、requirements.txt を固定化することが必須となりますので覚えておきましょう。CIで pip check コマンドを回して衝突を早期検知し、DockerやPoetryを使って再現性を担保しましょう。
エージェントの無限ループとトークン爆増
ReAct系エージェントは誤ったツール選択や曖昧なプロンプトで思考ループに陥り、APIコストが青天井状態になることがあります。
max_iterations を5〜10に制限しておいて、LangSmith側でトークン閾値超過時にアラートを飛ばす設定を推奨します。Toolの戻り値に想定外なパターンが来た場合は、ガードレールで強制終了させると安全です。
RAGの情報鮮度と機密データ管理
ベクトルDBに旧データが残ったまま更新を怠ると、鮮度の低い回答でユーザー体験を損なってしまいます。また、社内文書をまるごとクラウドにアップすると情報漏洩リスクが高まる点にも要注意です。
対策として、metadata.last_updated で日付フィルタを設定し、社外持ち出し不可ファイルはオンプレWeaviateなどに格納しておきましょう。さらに、アクセス権と暗号化をポリシー化したうえで定期的に再埋め込みを行いましょう。
LangChainの活用事例
LangChainは個人開発からエンタープライズまで幅広く採用されています。ここからは公式ブログに掲載されている事例をもとに、LangChainの活用事例をご紹介します。
Cisco Outshiftが開発したAIプラットフォームエンジニア「JARVIS」
Ciscoのイノベーション部門Outshiftは、LangGraphとLangSmithを活用した分散マルチエージェントシステム「JARVIS」を開発しました。
15以上のサブエージェント、40のツール連携、10の自動化ワークフローを備え、CI/CDパイプラインのセットアップを1週間から1時間未満に短縮したそうです。開発者はJiraチケットでタスクを割り当てるだけで、JARVISが自律的に実行し、不明点があれば人に確認を求める仕組みです。LangSmithのトレースと評価ループで継続的に精度を改善しています。(※2)
Webtoon Entertainmentが構築した作品理解AI「WCAI」
NASDAQ上場のデジタルエンタメ企業Webtoonは、LangGraphベースのエージェントワークフロー「WCAI(Webtoon Comprehension AI)」を構築しました。
膨大な作品ライブラリに対し、キャラクター・ストーリー・文脈をAIが深く理解し、マーケティング・翻訳・レコメンドの各チームが自然言語ですぐにインサイトを取得できる環境を実現しています。従来のエピソード手動確認を置き換え、チームがクリエイティブや戦略立案に集中できるようになったそうです。(※3)
LangChainと組み合わせて使える自律型AIエージェントツールを比較したい方は、以下の記事もご覧ください。

NVIDIAが公開したエンタープライズ検索「AI-Q Blueprint」
NVIDIAは2026年3月、LangChain・LangGraph・Deep Agentsを統合したエンタープライズ向けディープリサーチシステム「AI-Q Blueprint」を公開しました。
フロンティアモデルがオーケストレーションを担当し、NVIDIAのNemotronモデルがリサーチ処理を行うハイブリッド構成により、クエリコストを50%以上削減しつつDeepResearch Benchで1位を獲得しています。Dell、IBM、ServiceNowなど多数のパートナー企業にも採用されています。(※4)
上記事例の他に、国内でもRAGを活用した社内ナレッジ検索や、Agentsを使った業務自動化の導入が進んでいます。
LangChainに関するよくある質問(FAQ)
LangChainでLLMを使いやすく拡張しよう!
LangChainは、LLMの機能を高機能化するライブラリで、、LLMの能力をさらに拡張するためのツールです。
このライブラリにより、現在のLLM単体ではできない機能を拡張させ、効率化を高めることができます。主な機能として、言語モデルのカスタマイズ(Models)、外部ツールとの連携(Indexes)、テンプレートでの効率化(Prompts)、対話履歴の記憶(Memory)などが挙げられます。
使用例として、「Document Loader」機能を使ってPDF文書の内容を検索する方法とChatGPTの拡張をご紹介しました。LangChainを利用するには、OpenAIやSerpAPIなどのAPIキーの取得が必要で、無料の範囲であれば利用は可能ですが、使用量によっては料金がかかる場合があります。LangChainは競合他社より大きなアドバンテージを得るのに大いに役立つのでぜひ試してみてはいかがでしょうか。

最後に
いかがだったでしょうか?
LangChain導入で社内の生成AI活用を次のステージへ。開発効率・信頼性・運用性を一気に底上げできます。今こそ差がつく導入戦略を検討してみませんか。
「生成AIで新しいプロダクトを作りたい」「もっと本格的に生成AIを業務に組み込みたい」とお考えの方は、ぜひ株式会社WEELにご相談ください。
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
アイデア段階でも構いません。まずは無料相談でお気軽にご相談ください。
➡︎生成AIを活用したプロダクト開発・業務効率化について相談する

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

