
【Mixtral-8x7B】GPT3.5とLlama2 70Bを上回る性能の無料オープンソースを使ってみた

WEELメディア事業部LLMライターのゆうやです。
Mixtral-8x7Bは、2023年12月11日にMistral AIより公開された最新の大規模言語モデル(LLM)です。
このモデルは、オープンウェイトを備えた高品質のスパース混合エキスパートモデル (SMoE) であり、各トークンの処理に特化した8のエキスパートがタスクを実行し、従来モデルに比べて推論速度が6倍ほど高速です。
また、ほとんどのベンチマークでLlama 70Bを上回っており、GPT-3.5と同等かそれ以上の性能を有しています。
今回は、 Mixtral-8x7Bの概要や使ってみた感想をお伝えします。
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Mixtral-8x7Bの概要
Mixtral-8x7Bは、2023年12月11日にMistral AIより公開された最新の大規模言語モデル(LLM)です。
このモデルは、オープンウェイトを備えた高品質のスパース混合エキスパートモデル (SMoE) であり、各トークンの処理に特化した8のエキスパートがタスクを実行し、従来モデルに比べて推論速度が6倍ほど高速です。
また、ほとんどのベンチマークでLlama 70Bを上回っており、GPT-3.5と同等かそれ以上の性能を有しています。
そんなMixtral-8x7Bの特徴は以下の6点です。
- 高性能: Mixtral 8x7Bは、Llama2 70BやGPT-3.5といった他のLLMと比較して、ほとんどのベンチマークで匹敵または上回る性能を示しています。
- バイアスの軽減: Mixtral 8x7Bは、他のモデルよりもバイアスが少なく、より公平でバランスの取れた回答を提供します。
- 言語サポート: このモデルは、英語、フランス語、ドイツ語、スペイン語、イタリア語に対応しています。
- 実装の柔軟性: Mixtral 8x7Bの設計により、高性能サーバーから控えめなセットアップまで、さまざまなコンピューティング環境に柔軟に適応できます。
- 推論の実行: 推論を実行する主な方法には、Transformersのpipeline()やText Generation Inferenceがあり、モデルを半精度 (float16) または量子化された重みで実行できます。
- デプロイの容易さ: HuggingFaceのエコシステムを利用して、学習および推論のスクリプトと例、テキスト生成のユーティリティとヘルパーなどを活用することができます。
先ほど紹介した「SMoE」(sparse mixture-of-experts)は、フィードフォワードブロックが8つの異なるパラメータグループのセットから選択するデコーダのみのモデルです。
各トークンに対して、2つエキスパートを選択して処理し、その出力を加算的に組み合わせることで、総合的な出力を創り出して回答します。
この手法を用いることで、モデルがトークンごとにパラメーターの合計セットの一部のみを使用するため、コストと待ち時間を制御しながらモデルのパラメーターの数を増やすことができます。
結果として、このモデルは合計467億のパラメータがありますが、トークンごとに使用するパラメータは129億のみなので、3割以下のサイズのモデルと同じ速度、コストで推論を実行できます。
このような画期的な手法を使って構築されたMixtral-8x7Bは、より大きなサイズのモデル(Llama2 70B、GPT-3.5)と比較して遥かに速い速度で、少ないリソースで同等以上の性能を実現しています。
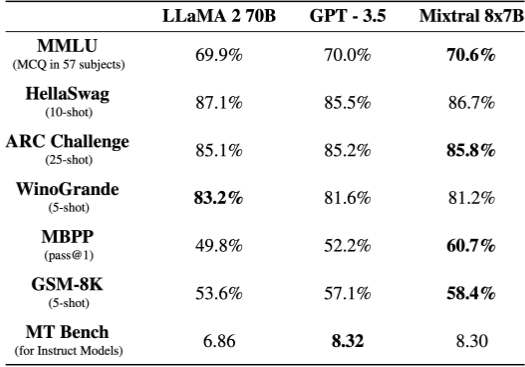
ベンチマーク上ではこのような結果になっていますが、実際の性能はどうなのか気になりますよね。
ここからは、実際に使って比較検証してMixtral-8x7Bの性能を確かめていきます。
まずは使い方から説明します。

Mixtral-8x7Bの使い方
Mixtral-8x7Bは、Google ColabのようなブラウザベースのPython開発環境を使って簡単に実行することができます。
ただし、かなりのメモリを消費するので、Google Colabで実行する場合は、ProでA100 GPUを使用してください。
また、量子化モデルが公開されていおり、そちらは大幅に必要スペックが抑えられています。
今回は、Google Colab ProでV100GPUハイメモリを使用して、指示モデルの量子化モデルであるmixtral-8x7b-instruct-v0.1-GPTQを実装していきます。
まず、必要なパッケージをインストールします。
transformersは最新のものをインストールしてください。
!git clone https://github.com/ggerganov/llama.cpp
%cd llama.cpp
# ⚠️ Checking out the latest (atm) commit from `mistral` branch
# Use `main` once PR is merged
# https://github.com/ggerganov/llama.cpp/pull/4406/commits
!git checkout f1cbfabd642a18f6db0435ea67a3f5c890d801bc
!make LLAMA_CUBLAS=1次に、以下のコードを実行してモデルとトークナイザーをロードします。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)最後に以下のコードを実行することで推論を実行できます。
text = "ここにプロンプトを入力"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))それでは実際に推論を実行していきましょう!
なお、Mistral 7Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Mistral 7B】Llama 2超えの性能を持つLLMらしいので、比較レビューしてみた
Mixtral-8x7Bを実際に使ってみた
以下のプロンプトを入力して自己紹介してもらいます。
Introduce yourself結果は以下のようになりました。
Hello there! I'm an assistant, a helpful AI companion designed to make your life easier and more convenient.
I can assist you with various tasks, answer your questions, and engage in conversation on a wide range of topics.
I'm here to ensure you have a smooth and enjoyable experience. Let me know how I can help you today! こんにちは!私はアシスタントで、あなたの生活をより簡単で便利にするためにデザインされた親切なAIコンパニオンです。
さまざまな作業をお手伝いしたり、質問に答えたり、幅広い話題で会話したりします。
あなたがスムーズで楽しい体験ができるようにお手伝いします。私がどのようにあなたのお役に立てるか、お知らせください!
生成速度は、私の環境が悪いのもありますがあまり速くはなかったですが、回答はとても丁寧です。
実際に使えることがわかったので、ここからはベンチマークでも比較されていたLlama2 70BとGPT-3.5と比較して、出力にどのような差があるのか検証していきます。
Mixtral-8x7Bは本当にLlama2 70BやGPT-3.5と同等の性能を持っているのか検証してみた
ここでは、以下の項目を比較検証します。
・コーディング
・日本語能力
・知識
Mixtral-8x7Bは日本語には対応していなそうですが、どのような結果になるのか気になります。
コーディング
以下のプロンプトを実行して、正しく動作するコードが出力できるか検証します。
Write the code for the regression analysis in Python.Pythonで回帰分析のコードを書いてください。
Mixtral-8x7B
Sure, here's an example of how you can perform a simple linear regression analysis in Python using the `statsmodels` library:
```python
import numpy as np
import pandas as pd
import statsmodels.api as sm
# Load your data into a Pandas DataFrame
data = pd.read_csv('your_data.csv')
# Define the dependent and independent variables
X = data[['independent_variable']]
y = data['dependent_variable']
# Add a constant term to the independent variable
X = sm.add_constant(X)
# Perform the regression analysis
model = sm.OLS(y, X).fit()
# Print out the summary of the results
print(model.summary())
```
In this example, replace `'your_data.csv'` with the path to your data file, and replace `'independent_variable'` and `'dependent_variable'` with the names of your independent and dependent variables, respectively. The code will output a summary of the regression results, including the coefficients for the intercept and independent variable, as well as statistics such as the R-squared value and p-values for the coefficients.
Note that this is just an example of how to perform a simple linear regression analysis in Python using the `statsmodels` library. Depending on your specific needs, you may need to customize the code further (e.g., by transforming the variables or adding interaction terms). Pythonで `statsmodels` ライブラリを使って簡単な線形回帰分析を行う例を示します:
Python
np として numpy をインポートする。
import pandas as pd
import statsmodels.api as sm
# データを Pandas DataFrame に読み込む
data = pd.read_csv(‘your_data.csv’)
# 従属変数と独立変数を定義
X = data[[‘independent_variable’]] # 従属変数と独立変数の定義
y = data[‘dependent_variable’]
# 独立変数に定数項を追加
X = sm.add_constant(X)
# 回帰分析を行う
model = sm.OLS(y, X).fit()
# 結果の要約を出力する
print(model.summary())
“`
この例では、`’your_data.csv’` をデータファイルのパスに、`’independent_variable’` と `’dependent_variable’` をそれぞれ独立変数と従属変数の名前に置き換えてください。このコードは、切片と独立変数の係数、係数のR2乗値やp値などの統計量を含む回帰結果の要約を出力する。
これは `statsmodels` ライブラリを使ってPythonで簡単な線形回帰分析を行う方法の例であることに注意してください。特定のニーズによっては、コードをさらにカスタマイズする必要があるかもしれません(例えば、変数を変換したり、交互作用項を追加したり)。
Llama2 70B
Sure! Here is an example of how to perform a simple linear regression analysis in Python using the scikit-learn library:
```
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# Load the data
df = pd.read_csv('data.csv')
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(df[['x1', 'x2']], df['y'], test_size=0.2, random_state=42)
# Create a LinearRegression object and fit the data
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
# Make predictions on the testing data
y_pred = lr_model.predict(X_test)
# Evaluate the model using mean squared error
mse = ((y_test - y_pred) ** 2).mean(axis=0)
print(f'Mean squared error: {mse}')
# Plot the data and the predicted values
plt.scatter(X_test, y_test, color='blue')
plt.scatter(X_test, y_pred, color='red')
plt.xlabel('Feature 1')
plt.ylabel('Target variable')
plt.show()
```
This code performs the following steps:
1. Loads the data from a CSV file using the `pandas` library.
2. Splits the data into training and testing sets using the `train_test_split` function from scikit-learn.
3. Creates a `LinearRegression` object and fits the data using the `fit` method.
4. Makes predictions on the testing data using the `predict` method.
5. Evaluates the model using the mean squared error (MSE) between the predicted values and the actual values.
6. Plots the data and the predicted values using `matplotlib`.
Of course, this is just a simple example, and there are many ways to improve upon this code, such as tuning hyperparameters, handling missing values, and using more advanced models.もちろんです!scikit-learnライブラリを使って、Pythonで簡単な線形回帰分析を行う例を示します:
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split # データを読み込む
# データを読み込む
df = pd.read_csv('data.csv')
# データをトレーニングセットとテストセットに分割する
X_train, X_test, y_train, y_test = train_test_split(df[['x1', 'x2']], df['y'], test_size=0.2, random_state=42) # 訓練セットとテストセットに分割する。
# LinearRegressionオブジェクトを作成し、データをフィットする
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
# テストデータで予測を行う
y_pred = lr_model.predict(X_test)
# 平均二乗誤差を使ってモデルを評価する
mse = ((y_test - y_pred) ** 2).mean(axis=0)
print(f'平均二乗誤差: {mse}')
# データと予測値をプロットする
plt.scatter(X_test, y_test, color='blue')
plt.scatter(X_test, y_pred, color='red')
plt.xlabel('Feature 1')
plt.ylabel('ターゲット変数')
plt.show()このコードは以下のステップを実行する:
- pandas`ライブラリを使用してCSVファイルからデータをロードする。
- scikit-learn の
train_test_split関数を使用して、データをトレーニングセットとテストセットに分割する。 - 3.
LinearRegressionオブジェクトを作成し、fitメソッドを使ってデータをフィットする。 - predict` メソッドを使ってテストデータの予測を行う。
- 予測値と実測値の平均二乗誤差(MSE)を用いてモデルを評価する。
- matplotlib`を用いてデータと予測値をプロットする。
もちろん、これは単純な例であり、ハイパーパラメータの調整、欠損値の処理、より高度なモデルの使用など、このコードを改良する方法はたくさんある。
GPT-3.5
Certainly! Here's a basic example of performing a linear regression analysis in Python using the popular `scikit-learn` library:
```python
# Import necessary libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# Generate some sample data
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Create a linear regression model
model = LinearRegression()
# Fit the model to the training data
model.fit(X_train, y_train)
# Make predictions on the test data
y_pred = model.predict(X_test)
# Calculate model performance metrics
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# Print the coefficients and performance metrics
print("Coefficients:", model.coef_)
print("Intercept:", model.intercept_)
print("Mean Squared Error:", mse)
print("R-squared:", r2)
# Plot the data points and regression line
plt.scatter(X_test, y_test, color='blue')
plt.plot(X_test, y_pred, color='red', linewidth=2)
plt.xlabel('X')
plt.ylabel('y')
plt.title('Linear Regression')
plt.show()
```
In this example:
1. We generate some sample data with a linear relationship between X and y, with some random noise.
2. The data is split into training and testing sets using `train_test_split`.
3. We create a `LinearRegression` model and fit it to the training data.
4. We make predictions on the test data and calculate performance metrics like Mean Squared Error and R-squared.
5. Finally, we visualize the data points and the regression line using Matplotlib.
You can adapt this code to your specific dataset and regression analysis needs. There are also other regression techniques available in scikit-learn, such as polynomial regression, ridge regression, and lasso regression, which you can explore depending on your data and requirements.確かに!以下は、人気のある `scikit-learn` ライブラリを使ってPythonで線形回帰分析を行う基本的な例です:
“python
# 必要なライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# サンプルデータを生成
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# データをトレーニングセットとテストセットに分ける
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 線形回帰モデルを作成する
model = LinearRegression()
# モデルを学習データにフィットさせる
model.fit(X_train, y_train)
# テストデータに対して予測を行う
y_pred = model.predict(X_test)
# モデルのパフォーマンスメトリックスを計算する
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 係数とパフォーマンスメトリクスの表示
print(“Coefficients:”, model.coef_)
print(“切片:”, model.intercept_)
print(“平均二乗誤差:”, mse)
print(“R2乗:”, r2)
# データ点と回帰直線をプロットする
plt.scatter(X_test, y_test, color=’blue’)
plt.plot(X_test, y_pred, color=’red’, linewidth=2)
plt.xlabel(‘X’)
plt.ylabel(‘y’)
plt.title(‘線形回帰’)
plt.show()
“`
この例では
1. Xとyの間に線形関係があり、ランダムなノイズを含むサンプル・データを作成します。
2. 2. `train_test_split` を用いて、データをトレーニングセットとテストセットに分割する。
3. 3. `LinearRegression` モデルを作成し、訓練データに当てはめる。
4. テストデータに対して予測を行い、Mean Squared ErrorやR-squaredのようなパフォーマンス指標を計算する。
5. 最後に、Matplotlib を使ってデータ点と回帰直線を可視化する。
このコードは、あなたの特定のデータセットや回帰分析のニーズに合わせることができる。scikit-learnには、多項式回帰、リッジ回帰、ラッソ回帰など、他の回帰テクニックもあり、データや要件に応じて探索することができます。
結果は、Mixtral-8x7BとGPT-3.5は正しく動作するコードを出力しましたが、Llama2 70Bのみそのままでは動かないコードを出力しました。
Llama2 70Bのものは、ライブラリがインポートされていなかったりと初歩的なミスが目立ちます。
この結果からも、Mixtral-8x7BはLlama2 70B以上の性能を持っており、GPT-3.5と同等であることが伺えます。
日本語能力
以下のプロンプトを入力して、どのような出力をするか検証します。
日本語でクライアントに送信する丁寧語・謙譲語を正しく使用したビジネスメールを作成してください。Mixtral-8x7B
Subject: 【重要】お客様にお帰りします
こんにちは、XYZ Corporationです。
今回は、新しい製品のご案内をさせていただきまして、心よりお待ちしておりました。
弊社の新規開発プロダクトである「ABC123」という製品をご紹介致しています。この製品は、最新テクノロジーを取り入れ、より効率的で便利な作業を実現し、あなたの事業に大きく貢献することができると信じています。
弊社では、常に顧客のニーズと期待に応えることが一番大切であり、この製品もそれに応じて開発されております。ご了承いただけましたら、商談の場を用意いたし、製品のデモンストレーションなどを行い、より詳しくご紹介致します。
今後和室での出会いを心よりお待ちしております。何卒、この機会に、ぜひお時間を頂戴していただけますと幸いでございます。
あなたのお役に立てることができれば、一日も早く、私たちとお話をさせていただきたいと思っております。
最後に、今回は特別に、製品の試用期間を30日間プレゼントいたします。これにより、安心して製品の価値を実感できることができます。
お手続きは簡単です。下記URLから登録フォームに入力いただければ、即座に30日間のトライアル期間が開始されます。
[www.xyzcorp.co.jp/tryabc123]
何卒、お手数をかける場合もございますが、こちらの機会にお試しください。
今後とも、XYZ Corporationとのお付き合いを、どうぞよろしくお願いいたします。
敬具
[Your Name]
[Your Position]
[Your Email Address]
[Your Phone Number]Llama2 70B
丁寧語・謙譲語を正しく使用したビジネスメールの例
sujet: ビジネスの件
Dear [名前],
こんにちは!私は[会社名]の[役職]です。
先日、あなたと[会社名]との間で発生したお客様の口コミュニケーションについて、私たちは問題がありました。私たちは、お客様のニーズに対して最善を尽くしていますが、時々、会社の要求に対して適切な対応ができない場合があります。
私たちは、この問題に対して、よりよいコミュニケーションを取り揃えるための対策を講じています。まず、お客様に対して、より明確なメッセージを送信することにします。次に、会社の要求に対して、より適切な対応を取り揃えることにします。
また、私たちは、お客様のニーズに対して、より優れたサービスを提供するために、内部的なプロセスを強化することにします。これにより、私たちは、お客様に対して、より迅速で、より効率的なサービスを提供することができます。
また、私たちは、お客様との間でのコミュニケーションを強化するために、定期的なミーティングを設定することにします。これにより、私たちは、お客様のニーズに対して、より直接的に対応することができます。
以上、私たちは、お客様のニーズに対して、より優れたサービスを提供するために、努力を重ねています。また、これらの対策により、私たちは、お客様との間でのコミュニケーションを強化することができます。
ありがとうございます。
Sincerely,
[Your Name]
[会社名]
Note: このメールは、丁寧語・謙譲語を使用していますが、GPT-3.5
もちろん、ビジネスメールの例を提供します。以下のビジネスメールは、クライアントに対して丁寧語と謙譲語を使用したものです。状況に応じて内容をカスタマイズしてください。
```
件名: ご提案書のご検討について
お世話になっております、[あなたの名前] と申します。[あなたの会社名] の[あなたの役職] でございます。
まず初めに、[クライアントの会社名] 様におかれましては、長らくのご愛顧を賜り、誠にありがとうございます。心より感謝申し上げます。
さて、[クライアントの会社名] 様におかれましては、[前回の提案/プロジェクト] に関して、大変ご協力いただきまして、誠にありがとうございました。ご好評いただき、私どもも大変光栄に存じます。
今般、新しいプロジェクトについて、ご提案をさせていただきたく存じます。ご多用中恐縮ではございますが、何卒お時間をいただき、ご検討賜りますようお願い申し上げます。
ご提案書を添付いたしましたので、ご不明点やご質問等がございましたら、どうぞお気軽にお知らせいただけますと幸いです。また、ご提案に対するご意見やご要望も、大変貴重に存じますので、どうぞご遠慮なくお知らせください。
[クライアントの会社名] 様との一層のお取引を心より願っております。何かお手伝いできることがございましたら、どうぞお知らせください。
何卒、よろしくお願い申し上げます。
敬具
[あなたの名前]
[あなたの連絡先情報]
[あなたの会社名]
```
このメールは、クライアントに対して敬意を表し、感謝の意を示すとともに、新しい提案をすることを丁寧に伝えるものです。メールの内容は具体的な提案に合わせてカスタマイズしてください。結果は、やはりGPT-3.5が最も良いビジネスメールを出力してくれました。
Mixtral-8x7Bは、日本語に対応していないとのことでしたが、少し変な日本語になっていますが、Llama2 70Bよりも自然な日本語でビジネスメールを作成してくれました。
どうやら本当にLlama2 70Bより高い性能を持っているようです。
知識
以下のプロンプトを入力して、正しい情報を出力するか検証します。
Give me a ranking of the top 5 mountain elevations in Japan.日本の山の標高ランキングTOP5を教えて
Mixtral-8x7B
Here are the top 5 mountains by elevation in Japan:
1. Mount Fuji - 3,776 meters (12,389 feet)
2. Mount Kita - 3,193 meters (10,476 feet)
3. Mount Orizaba - 3,189 meters (10,463 feet)
4. Mount Hotaka - 3,190 meters (10,466 feet)
5. Mount Ainodake - 3,186 meters (10,453 feet)
Mount Fuji is the highest mountain in Japan and also a famous cultural symbol of the country.
The other four mountains are located in the Japanese Alps, which is a popular destination for mountaineering and hiking. 日本の標高上位5山を紹介しよう:
- 富士山 – 3,776メートル(12,389フィート)
- 北岳 – 3,193メートル(10,476フィート)
- オリサバ山 – 3,189メートル(10,463フィート)
- 穂高岳-3,190メートル(10,466フィート)
- 間ノ岳 – 3,186メートル(10,453フィート)
富士山は日本で最も高い山であり、日本の有名な文化的シンボルでもある。
他の4つの山は日本アルプスに位置し、登山やハイキングの人気スポットである。
Llama2 70B
Sure, here are the top 5 mountain elevations in Japan, ranked in order of their height:
1. Mount Fuji - 3,776 meters (12,388 feet)
2. Mount Kita - 3,193 meters (10,476 feet)
3. Mount Hotaka - 3,186 meters (10,453 feet)
4. Mount Yari - 3,141 meters (10,305 feet)
5. Mount Shirouma - 3,077 meters (10,095 feet)
Note: These elevations are based on the heights of the mountains' summits above sea level.では、日本の山の標高トップ5を高い順にランキングしてみよう:
- 富士山 – 3,776メートル
- 北岳 – 3,193メートル(10,476フィート)
- 穂高岳 – 3,186メートル(10,453フィート)
- 槍ヶ岳-3,141メートル(10,305フィート)
- 白馬岳 – 3,077メートル(10,095フィート)
注:これらの標高は、各山の山頂の海抜に基づいている。
GPT-3.5
Certainly! Here are the top 5 highest mountains in Japan as of my last knowledge update in January 2022, listed in order of elevation:
1. Mount Fuji (富士山) - 3,776.24 meters (12,389 feet): Mount Fuji is the highest peak in Japan and is an iconic symbol of the country.
2. Kita-dake (北岳) - 3,193.41 meters (10,476 feet): Kita-dake is the second-highest peak in Japan and is located in the Southern Alps (Minami Alps).
3. Mount Hotaka (穂高岳) - 3,190.66 meters (10,468 feet): Mount Hotaka is another prominent peak in the Northern Alps (Kita Alps).
4. Mount Yari (槍ヶ岳) - 3,180.45 meters (10,433 feet): Mount Yari is located in the Northern Alps and is known for its distinctive spear-like shape.
5. Mount Akaishi (赤石岳) - 3,120.71 meters (10,240 feet): Mount Akaishi is part of the Southern Alps (Minami Alps) and offers challenging climbs and beautiful alpine scenery.
Please note that elevation measurements may vary slightly depending on the source, and it's a good idea to check for the most up-to-date information if you plan to visit or explore these mountains.以下は、私の最終更新情報である2022年1月時点での、日本の最も高い山のトップ5を標高の順に示したものです。
- 富士山 (Mount Fuji) – 3,776.24メートル (12,389フィート):富士山は日本で最も高い山であり、国の象徴的な存在です。
- 北岳 (Kita-dake) – 3,193.41メートル (10,476フィート):北岳は日本で2番目に高い山であり、南アルプス(南アルプス)に位置しています。
- 穂高岳 (Mount Hotaka) – 3,190.66メートル (10,468フィート):穂高岳は北アルプス(北アルプス)に位置し、印象的な山で知られています。
- 槍ヶ岳 (Mount Yari) – 3,180.45メートル (10,433フィート):槍ヶ岳は北アルプスにあり、その特徴的な槍のような形状で知られています。
- 赤石岳 (Mount Akaishi) – 3,120.71メートル (10,240フィート):赤石岳は南アルプス(南アルプス)の一部で、挑戦的な登山と美しい高山の景色が楽しめます。
標高の測定値は情報源によってわずかに異なることがあるため、これらの山を訪れる予定がある場合は、最新情報を確認することをお勧めします。
こちらは全モデル不正解です。
日本の山の正しい標高ランキングTOP5は、
- 富士山(3,776m)
- 北岳(3,193m)
- 奥穂高岳(3,190m)
- 間ノ岳(3.190m)
- 槍ヶ岳(3,180m)
です。
特にMixtral-8x7Bの出力した回答は、オリサバ山という日本の山ではないものが混じっており、調べてみるとメキシコの火山のようです。
日本語のデータはほとんど学習されていないようなので、日本に関する知識は少ないようです。
今回の検証の結果をまとめると、Mixtral-8x7Bは確かにLlama2 70Bより良い回答を出力し、GPT-3.5と同等と言っても差し支えない程の性能を有していることがわかりました。
このモデルは、現在公開されているオープンソースモデルの中では最高クラスの性能を有しています。
まとめ
Mixtral-8x7Bは、2023年12月11日にMistral AIより公開された最新の大規模言語モデル(LLM)です。
このモデルは、オープンウェイトを備えた高品質のスパース混合エキスパートモデル (SMoE) であり、各トークンの処理に特化した8のエキスパートがタスクを実行し、従来モデルに比べて推論速度が6倍ほど高速です。
また、ほとんどのベンチマークでLlama2 70Bを上回っており、GPT-3.5と同等かそれ以上の性能を有しています。
実際に使ってみた感想は、ベンチマーク結果の通り、Llama2 70Bより高い性能を示し、GPT-3.5と同等と言っても差し支えないと感じました。
将来、このような画期的なAIがさらに発展することで、映画「トロン・レガシー」のような世界観が現実のものになるかもしれませんね!

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

