
【Amphion】テイラースウィフトに中国語の曲を歌わせられる神音声AIツールを使ってみた

WEELメディア事業部LLMライターのゆうやです。
Amphionは、音声、音楽、およびスピーチ生成のためのオープンソースツールキットです。
このツールキットは、あらゆる入力をオーディオに変換する研究のプラットフォームとして提供され、研究の再現性を支援し、初心者の研究者やエンジニアが音声、音楽、スピーチ生成の研究開発分野に参入する助けとなることを目的としています。
その注目度は高く、公開されて間もないツールにも関わらずGithubリポジトリには750以上のスターがついています。
今回は、Amphionの概要と実際に使ってみた感想をお伝えします。
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Amphionの概要
Amphionは、音声、音楽、およびスピーチ生成のためのオープンソースツールキットです。
このツールキットは、あらゆる入力をオーディオに変換する研究のプラットフォームとして提供され、研究の再現性を支援し、初心者の研究者やエンジニアが音声、音楽、スピーチ生成の研究開発分野に参入する助けとなることを目的としています。
Amphionは、以下のような様々な音声生成タスクをサポートされています。
- TTS(Text to Speech:テキストから音声への変換)
- SVS(Singing Voice Synthesis:歌声合成)
- VC(Voice Conversion:声質変換)
- SVC(Singing Voice Conversion:歌声の声質変換)
- TTA(Text to Audio:テキストからオーディオへの変換)
- TTM(Text to Music:テキストから音楽への変換)
また、Amphionには特定の生成タスクに加えていくつかのボコーダーと評価指標も含まれています。
ボコーダーは高品質のオーディオ信号を生成するための重要なモジュールであり、評価指標は生成タスクで一貫した指標を確保するために重要です。
ボコーダーには、GANベースのものやフローベース、拡散ベース、自己回帰ベースのものまで、多様なものがサポートされています。
評価指標には、F0 モデリングやエネルギー モデリング、明瞭度などの評価指標が含まれています。
ここからは、Amphionの使い方について説明します。

Amphionの使い方
Amphionは、現在以下のhugging faceのページからNaturalSpeech2、Singing Voice Conversion、Text To Speech、Text To Audioが使用できます。
また、ローカルにインストールして使用する方法もあるのですが、モデルのトレーニングから行う必要があるため、今回はインストール方法のみ説明して、検証にはhugging faceにあるデモを使用します。
まず、GitHubのリポジトリをクローンします。
git clone https://github.com/open-mmlab/Amphion.git
cd Amphion次に、Pythonの仮想環境を作成します。
conda create --name amphion python=3.9.15
conda activate amphion最後に以下のコマンドであらかじめ用意されているシェルスクリプトを実行することで、必要なパッケージをインストールします。
sh env.shここまで完了したらモデルを使用できますが、ここから先の方法については以下のページで各モデルごとに詳しく説明されているので、こちらをご覧ください。
それでは早速使っていきましょう!
なお、感情表現ができる音声生成AIEmotiVoiceについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【EmotiVoice】AIがついに感情を手に入れる。感情表現ができる音声生成AIに実際に喋ってもらった
Amphionを実際に使ってみた
ここからは実際に各ツールを使用して、性能を確かめていきます。
Text To Speech
まずはText To Speechから使ってみます。
以下のプロンプトを入力します。
Hello, my name is Ellie. My favorite food is apple and my least favorite food is tomato.こんにちは、私の名前はエリーです。好きな食べ物はリンゴで、嫌いな食べ物はトマトです。
次に、Target Speakerのところで自分の好きな人物を選択して生成される音声のスピーカーを決めます。
ここはあらかじめ用意された人しか選べないようです。今回はJohn Van Stanを選択します。
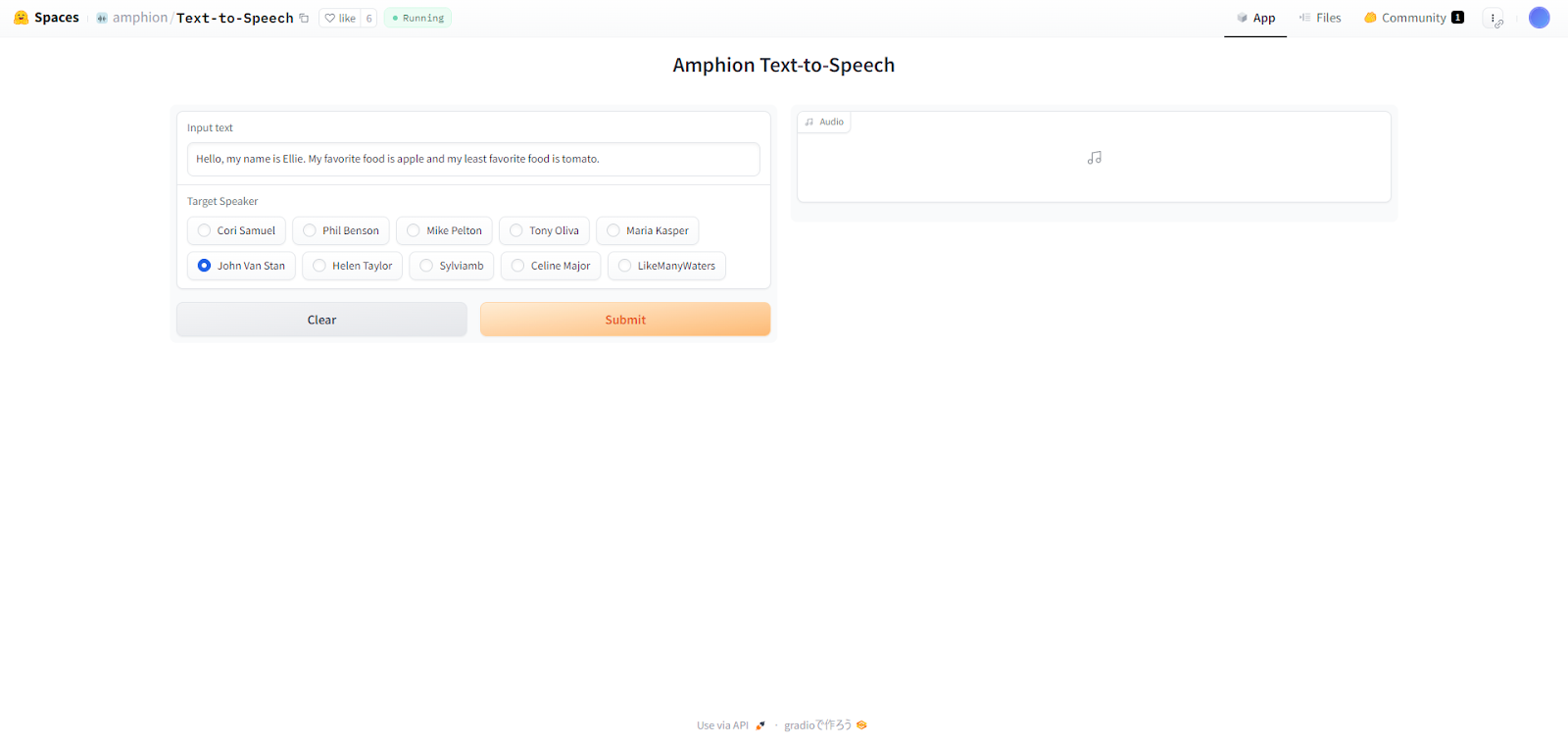
これでSubmitをクリックして実行します。
以下の音声が生成されました。
若干機械音声感が否めませんが、十分自然な音声を生成してくれました。
NaturalSpeech2
次に、先ほど生成された音声をベースにNaturalSpeech2を使用します。
NaturalSpeech2は、サンプルとなる音声と生成したいテキストプロンプトを入力することで、テキストプロンプトをサンプルと同じ音声で読み上げてくれます。
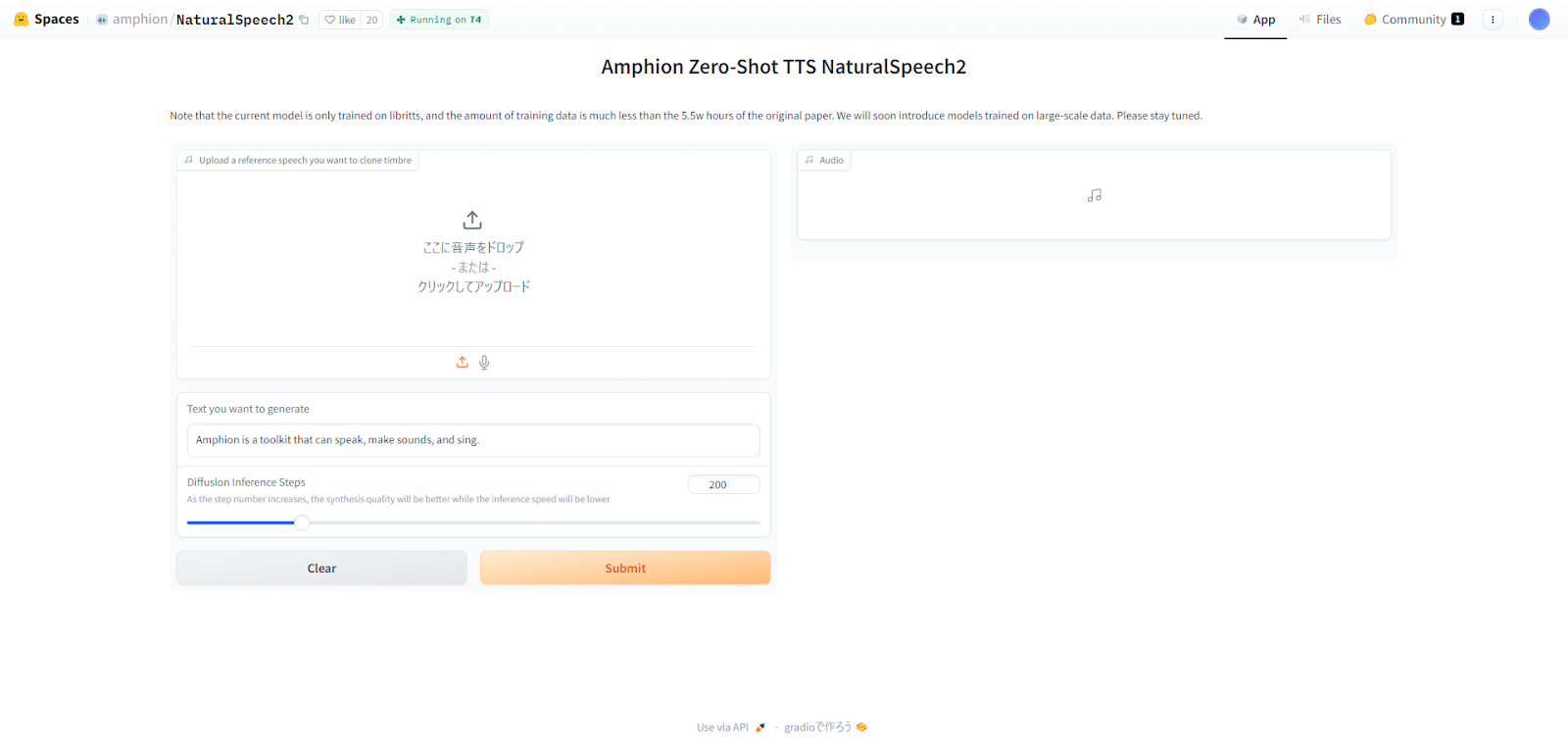
なお、現在こちらで使用できるモデルはトレーニングデータを大幅に絞られたモデルであることに注意してください。
大規模データで学習されたモデルはもうすぐ公開されるとのことです。
先ほど生成した音声を入力して、以下のテキストを読み上げてもらいます。
Amphion is a toolkit that can speak, make sounds, and sing.アンフィオンは言葉を話し、音を出し、歌うことができるツールキットです。
かなり生成に時間がかかりましたが、結果はこのようになりました。
サンプルで入力した音声とほぼ同じ音声で読み上げてくれています。
トレーニングが制限されていながらこの性能なら、十分使い物になると思います。
Singing Voice Conversion
続いて、Singing Voice Conversionを使用します。
こちらは、歌声の声質変換をしてくれるツールです。
このツールは、ドライ ボーカルを入力することで最大限性能を引き出すことができます。
以下の歌声を入力して、Target SingerをAdeleにして実行してみます。
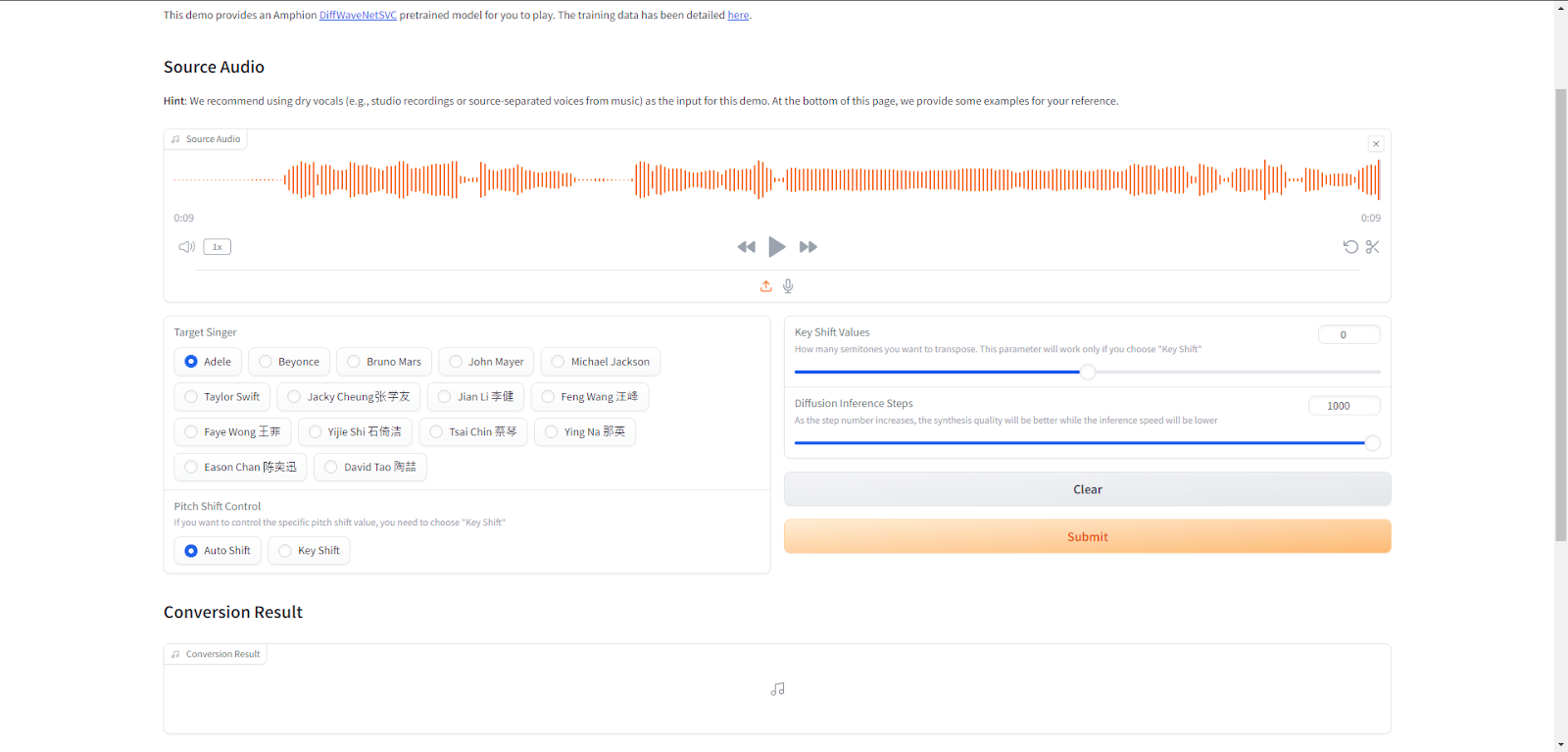
結果はこのようになりました。
男性の歌声だったのが、まるで本物のAdeleのような歌声になりました。
インターネット上でここまでの性能の音声生成ができるのは驚きです。
Text to Audio
最後にText to Audioを使用します。
このツールは、テキストプロンプトから連想される音声を生成するツールです。
以下のプロンプトを入力して音声を生成します。
birds singing and a man whistling鳥のさえずりと男の口笛
結果は、このような音声が生成されました。
正直どれが鳥のさえずりでどれが口笛か分からないですが、概ねテキストプロンプト通りの音声が生成されました。
これはすごいですね!
これで使えるツールは一通り試しましたが、どれも高品質な音声を生成してくれました。
このツールと他の音声生成AIで違う点は、特定の人物の声を模倣して音声を生成できてしまうところです。
これは悪用される恐れがあるので、早急に対策が必要だと感じました。
最後に、OpenAIのTTSとAmphionのTTSを比較してみようと思います。
AmphionのTTSをOpenAIのTTSと比較してみた
OpenAIのTTSはAPIから利用できますが、以下のHugging Face Spaceでから利用すると簡単です。
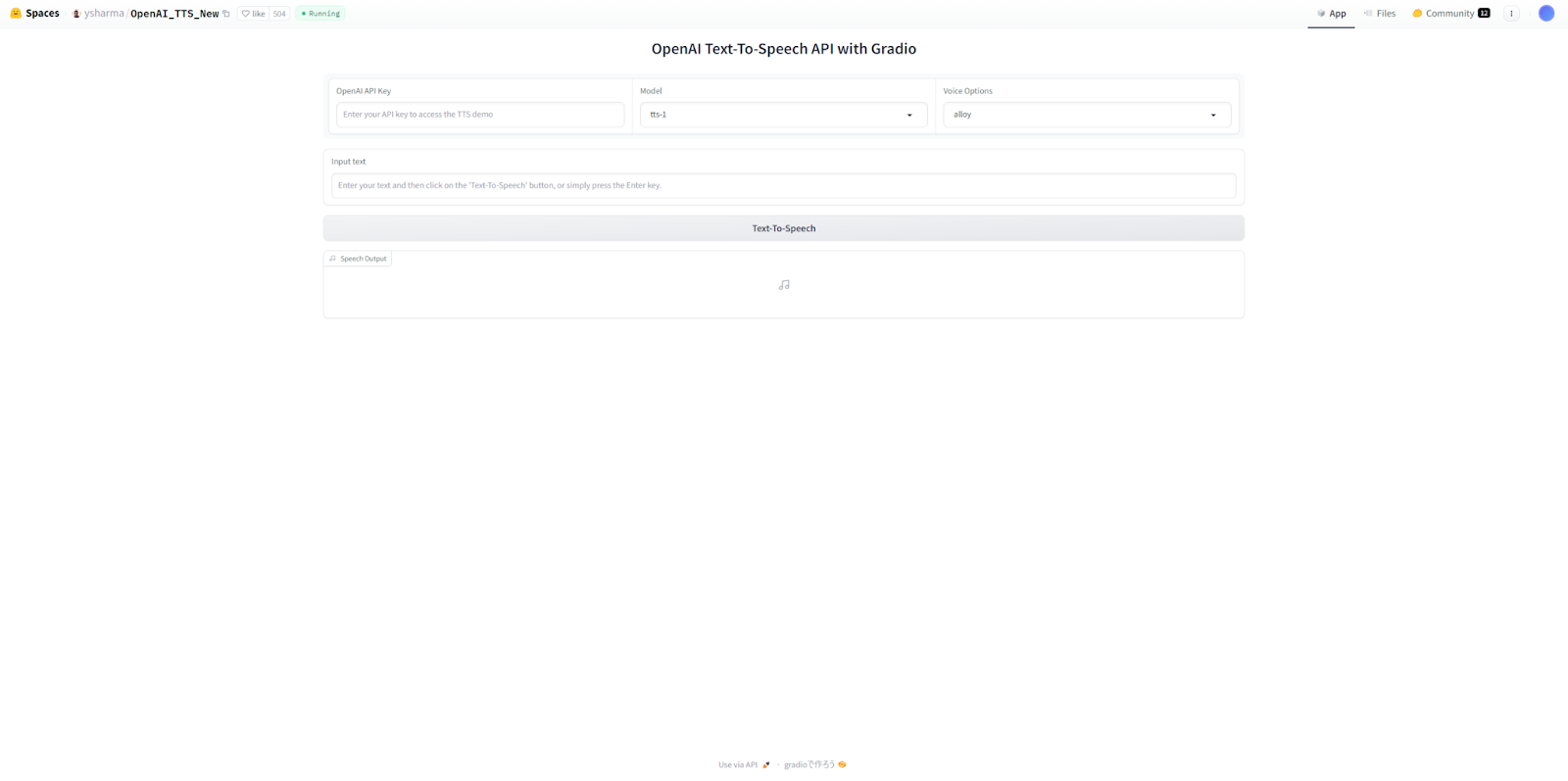
ここでOpenAI API Keyとテキストプロンプトを入力して実行するだけです。
先ほどAmphionTTSで入力したプロンプトを入力してみます。
Hello, my name is Ellie. My favorite food is apple and my least favorite food is tomato.結果はこのようになりました。
こちらの方がAmphionTTSより自然で本物の人間に近い音声になっています。
やはりまだOpenAIには勝てないようですね。
最後に日本語でも出力できるかやってみます。
先ほど入力したテキストプロンプトの日本語訳を入力します。
こんにちは、私の名前はエリーです。好きな食べ物はリンゴで、嫌いな食べ物はトマトです。結果はこのようになりました。
Amphion TTS
OpenAI TTS
OpenAI TTSは、日本語でも問題なく自然な音声を出力してくれましたが、Amphion TTSは意味不明な音声になっており、日本語には対応していないことが伺えます。
このように性能面ではまだOpenAI TTSには至らないものの、AmphionにはOpenAI TTSにはない数多くの機能があり、今後も開発が続けられるので、今後のアップデートに期待しましょう!
なお、自分の声をあらゆる言語に変換できる最強翻訳AICoqui-AI XTTSについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Coqui-AI XTTS】自分の声をあらゆる言語に変換できる最強翻訳AI
まとめ
Amphionは、音声、音楽、およびスピーチ生成のためのオープンソースツールキットです。
このツールキットは、あらゆる入力をオーディオに変換する研究のプラットフォームとして提供され、研究の再現性を支援し、初心者の研究者やエンジニアが音声、音楽、スピーチ生成の研究開発分野に参入する助けとなることを目的としています。
実際に使ってみた感想は、プロンプトや設定に忠実な音声を高品質で生成してくれましたが、特定の人物の声を模倣して音声を生成できてしまうので、悪用されないように対策が必要だと感じました。
ただ、OpenAI TTSとの比較ではまだまだ性能面では追いついていないことが分かったので、今後のアップデートに期待しましょう。
このツールがさらに進化すれば、完全に人間の声を模倣しさまざまな音声や音楽を生成するようになるかもしれませんね。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


