
【Animagine XL 3.1】エヴァのアスカをAIで完璧に描いてみた
Animagine XL 3.1は、アニメスタイルの画像を高品質で生成するためのテキストから画像を生成するモデルで、前バージョンであるAnimagine XL 3.0の機能強化版です。
このモデルは、全バージョンと比較して、出力の安定性が向上したほか、架空のアニメ風キャラクターだけでなく、実際に存在するアニメキャラの画像も生成できます。
このような画像生成AIの需要や注目度は極めて高く、Hugging Faceではすでに38,000件を超えるダウンロード数になっています。
今回は、Animagine XL 3.1の概要や使ってみた感想をお伝えします。
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Animagine XL 3.1の概要
Animagine XL 3.1は、アニメスタイルの画像を高品質で生成できるtext-to-imageモデルです。
このモデルは、2024年の頭に公開され大きな注目を集めたAnimagine XL 3.0の機能強化版で、より高品質なアニメスタイルの画像を生成できるように改良されました。
また、実際に存在するアニメキャラをより正確かつ高品質に生成できるようになり、アニメファンやコンテンツクリエイターの方たちにとって非常に重宝するモデルになりそうです。
ここまで高精細で忠実にアニメキャラを生成できていると、めちゃくちゃ上手な絵師さんが描いたのかと錯覚してしまいそうですよね!
そんなAnimagine XL 3.1の、Animagine XL 3.0からの主な変更点、改良点を紹介していきます。
学習画像
Animagine XL 3.1では、追加で約870,000枚の画像でトレーニングされており、Animagine XL 3.0と合わせると約210万枚の画像で学習されていることになります。
これにより、Animagine XL 3.0よりクオリティの高い画像を生成できるほか、生成できる画像のパターンも増加しています。
また、Animagine XL 3.1はテキストプロンプトのみで生成できるアニメキャラの一覧が公開されており、以下のページから確認することができます。
cagliostrolab/animagine-xl-3.1/tree/main/wildcard
このページにアクセスすると以下のように2つのテキストファイルがあり、character31.txtがAnimagine XL 3.1で新たに生成できるようになったアニメキャラとプロンプトの一覧で、characterfull.txtが生成できるすべてのアニメキャラとプロンプトの一覧です。
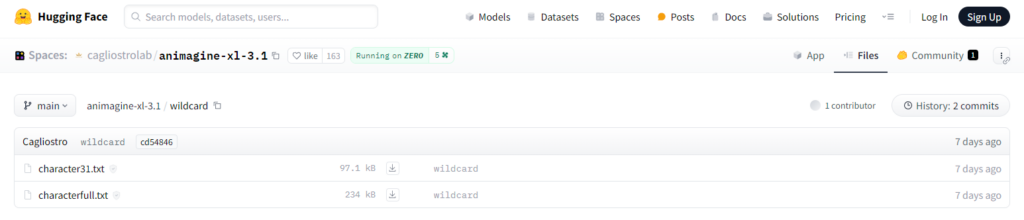
かなりの数のアニメキャラが生成できるよようなので、もしアニメキャラの生成を試される方は、こちらからプロンプトを探して試してみてください。
Aesthetic Tags(美的タグ)の追加
Animagine XL 3.1では新たにAesthetic Tags(美的タグ)が追加されています。
これは、画像の視覚的魅力に基づいてコンテンツのカテゴリ分けを精緻化するためのタグシステムであり、より魅力的で、目的に合った結果が得られるようになります。
具体的には以下のタグがあります。
| 美的タグ | スコア範囲 |
|---|---|
| very aesthetic | > 0.71 |
| aesthetic | > 0.45 & < 0.71 |
| displeasing | > 0.27 & < 0.45 |
| very displeasing | ≤ 0.27 |
これらのタグを使用して得られる画像の比較についてはこの後行います。
ここからは、実際にAnimagine XL 3.1を使用してその性能や機能を確かめていきます。
なお、初期モデルであるAnimagine XL 2.0について知りたい方はこちらの記事をご覧ください。
→【Animagine XL 2.0】解像度が高すぎるアニメ画像を生成できちゃうAIを使って推しの女の子を作ってみた
Animagine XL 3.1のライセンス
Animagine XL 3.0はオープンソースであるため、誰でも無料で利用可能です。
ただ、「Fair AI Public License 1.0-SD」というライセンスのもとで提供されており、モデルの変更を行った場合、その変更と元のライセンスを共有する必要があります。
また、変更されたバージョンがネットワーク経由でアクセス可能な場合、他者がソースコードを入手できるようにする必要があります。
\画像生成AIを商用利用する際はライセンスを確認しましょう/

Animagine XL 3.1の使い方
Animagine XL 3.1は、Hugging Face Spaceでオンラインデモを使用できるほか、ローカルやGoogle Colabに実装して使用することもできます。
オンラインデモは以下のリンクから利用できます。
cagliostrolab/animagine-xl-3.1
ここからは、ローカルやGoogle Colabで実装する方法を紹介します。
まず、必要なライブラリをインストールします。
pip install diffusers transformers accelerate safetensors --upgrade次に、モデルをロードします。
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"cagliostrolab/animagine-xl-3.1",
torch_dtype=torch.float16,
use_safetensors=True,
)
pipe.to('cuda')ここまで完了したら、以下のコードを実行して画像を生成します。
prompt = "1girl, souryuu asuka langley, neon genesis evangelion, solo, upper body, v, smile, looking at viewer, outdoors, night"
negative_prompt = "nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]"
image = pipe(
prompt,
negative_prompt=negative_prompt,
width=832,
height=1216,
guidance_scale=7,
num_inference_steps=28
).images[0]
image.save("./output/asuka_test.png")これで実装は完了です。
また、Google Colabで使用する場合は、公式からデモノートブックが公開されているので、こちらでも使用できます。
cagliostrolab/animagine-xl-3.1/blob/main/demo.ipynb
今回はGoogle ColabでV100GPUを使用して実装しました。
それでは、試しに以下のプロンプトを入力して、画像を生成させてみます。
prompt
1girl, cyberpunk hacker, neon visor, typing on holographic keyboard, neon-lit room, digital world projection, technology intriguenegative prompt
nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]結果は約8秒ほどで以下の画像を生成してくれました。

プロンプト通りの非常に高品質な画像ですね!
アニメキャラを動かすAI手法を知りたい方は、以下の記事もご覧ください。

Aesthetic Tags(美的タグ)
先ほどのプロンプトにAesthetic Tagsを追加して再度実行してみます。
very aesthetic

aesthetic

displeasing

very displeasing

正直そこまで差はないように感じますが、very aestheticとvery displeasingを比較すると、very aestheticのほうが高精細だと感じます。
Animagine XL 3.1を動かすのに必要な環境
■Pythonのバージョン
Python 3.8以上
■必要なパッケージ
- diffusers
- transformers
- accelerate
- safetensors

Animagine XL 3.1をAnimagine XL 3.0と比較してみた!
ここからは、Animagine XL 3.1とAnimagine XL 3.0に同じプロンプトを入力し、出力にどれほどの差が出るか検証します。
入力するプロンプトは基本的に同じですが、それぞれ最大限高品質な画像が生成できるように、品質に関するタグを入力します。
以下のプロンプトを入力します。
Animagine XL 3.1
prompt
masterpiece, best quality, very aesthetic, 1girl, souryuu asuka langley, neon genesis evangelion, plugsuit, pilot suit, red bodysuit, sitting, crossing legs, black eye patch, cat hat, throne, symmetrical, looking down, from bottom, looking at viewer, outdoorsnegative prompt
nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]Animagine XL 3.0
prompt
masterpiece, best quality,1girl, souryuu asuka langley, neon genesis evangelion, plugsuit, pilot suit, red bodysuit, sitting, crossing legs, black eye patch, cat hat, throne, symmetrical, looking down, from bottom, looking at viewer, outdoorsnegative prompt
lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]こちらは、エ〇ァンゲリオンに登場するア〇カを生成させるプロンプトですが、結果はどうなるでしょうか。
見ていきましょう!
Animagine XL 3.1

Animagine XL 3.0

結果はどちらもプロンプトを正しく理解して画像を生成してくれました。
しかし、Animagine XL 3.0の生成した画像の女の子は、ア〇カかと言われれば少し違う感じがします。
一方のAnimagine XL 3.1の生成した画像は、顔もプラグスーツも完全に再現されており、画像の品質もこちらのほうが良いため、確実に前バージョンよりも進化していることが分かります。
これほどまでに詳細にアニメキャラの画像を生成できるこのモデルは、今後実際のアニメやゲームの制作に活用できるほどの性能を有していると感じました。
なお、Animagine XL 3.0について知りたい方はこちらの記事をご覧ください。
→【Animagine XL 3.0】誰でも簡単にアニメ美少女の画像を生成できる神AI!使い方や料金、使ってみた感想を紹介
Animagine XL 3.1は最高のアニメ画像生成AI
Animagine XL 3.1は、アニメスタイルの画像を高品質で生成するためのテキストから画像を生成するモデルで、前バージョンであるAnimagine XL 3.0の機能強化版です。
このモデルは、単に性能が向上しただけでなく、実際に存在するアニメキャラをより正確かつ高品質に生成できるようになり、アニメファンやコンテンツクリエイターの方たちから大きな注目を集めています。
また、Animagine XL 3.0にはなかったタグが追加されており、よりユーザーの目的に沿った品質の画像を生成できるようになりました。
実際に使ってみたところ、簡単に実装でき、画像もプロンプト通りの高品質な画像を生成してくれました。
この記事を読んで気になった方は是非試してみてください!

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

