
Claude Mythos Previewとは?Anthropic最強AIの能力・安全性・Project Glasswingを徹底解説

- Claude Mythos Previewは限定公開の高性能LLMで、防衛的サイバーセキュリティ用途に特化
- Anthropicの一部評価ではゼロデイ脆弱性の発見・悪用まで自律実行可能な水準
- 高性能ゆえにデュアルユースリスクが高く、Project Glasswing経由で制限提供
Anthropicが2026年4月に新たなLLMについて発表をしました!
今回発表された「Claude Mythos Preview」は、従来の大規模言語モデルの枠を超え、特にサイバーセキュリティ領域において飛躍的な能力向上を示した次世代モデルです。ソフトウェアの脆弱性発見やエクスプロイト生成といった高度なタスクにおいて、人間専門家級に近づく、または一部で上回る可能性を示したと説明しています。
実際に本モデルは、主要なOSやブラウザに存在する未知の脆弱性を含め、数千件規模の深刻な問題を発見しており、従来のAIモデルとは一線を画す能力を持つことが明らかになっています。
一方で、こうした強力な能力は「どこまで実務で活用できるのか」「既存のLLMと何が異なるのか」「リスクとどのように向き合うべきか」といった新たな論点も生み出しています。特に、攻撃・防御の両面で利用可能なデュアルユースな性質は、これまでの生成AIとは異なる慎重な取り扱いを求められるポイントと言えるでしょう。
そこで本記事では、Claude Mythos Previewの概要や特徴、従来モデルとの違いを整理しながら、どのようなユースケースで価値を発揮するのかを解説します。最後までお読みいただければ、Claude Mythos Previewがなぜ限定公開という形を取っているのか、その背景にある技術的・社会的インパクトまで理解できるはずです。
\生成AIを活用して業務プロセスを自動化/
Claude Mythos Previewの概要
Claude Mythos PreviewはAnthropicが2026年4月に発表した大規模言語モデルです。Anthropicの前フロンティアモデルであるClaude Opus 4.6と比較して、多くの評価ベンチマークで大幅なスコア向上を記録しており、AIの能力水準を新たな段階に引き上げたモデルとして位置づけられています。
従来のサイバーセキュリティ対策では、脆弱性の発見に多くのコスト・労力・専門知識が必要でした。
Claude Mythos Previewでは、こうした作業を最小限の人間による誘導でほぼ自律的にこなすことが一部の評価からわかっています。
ただし、同じ能力が攻撃目的に転用されるリスクも高く、Anthropicはその点を明確に認識したうえで一般公開ではなく信頼できる限定パートナーへの提供という判断を取っています。
| 比較項目 | Claude Mythos Preview | Claude Opus 4.6 |
|---|---|---|
| 一般公開 | なし(限定パートナーのみ) | あり |
| 主な用途 | 防衛的サイバーセキュリティ | 汎用 |
| SWE-bench Verified | 93.9% | 80.8% |
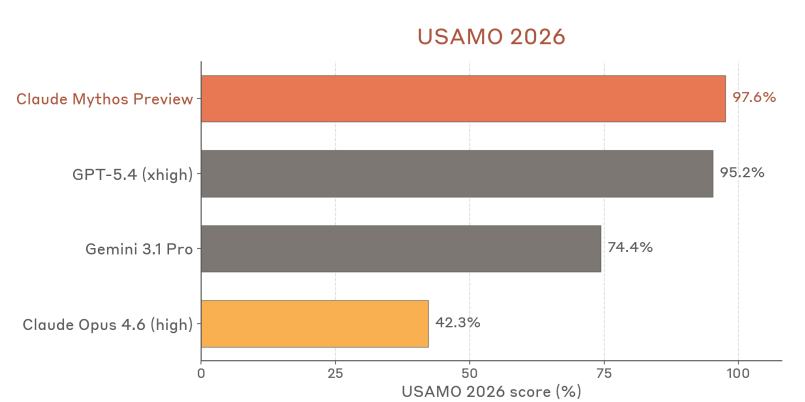
| USAMO 2026 | 97.6% | 42.3% |
| RSP対応 | RSP v3.xフレームワーク適用 | RSP v2.x適用 |
Claude Mythos Previewの仕組み
Claude Mythos Previewは、インターネット上の公開情報、パブリック・プライベートデータセット、そして他のモデルが生成した合成データを組み合わせた独自のデータセットで訓練されています。
訓練プロセスでは重複除去や分類などのデータクリーニングが施されており、ClaudeBotというウェブクローラーを通じて公開Webサイトから訓練データを収集。
事前訓練の後、Anthropicが策定した「Claude’s constitution」に記述された価値観や行動規範に沿った振る舞いを身につけるための大規模な事後訓練とファインチューニングが行われています。これがモデルの安全性・整合性を高める基盤となっています。
Claude Mythos Previewはテキスト出力に対応したモデルです。Anthropicの評価設定ではadaptive thinkingが使用されており、コンテキスト長も最大1Mトークン以下で検証。さらに多言語対応モデルでもあり、基本的にはユーザーの入力言語に合わせて応答します。
Project Glasswing
Project Glasswingは、Claude Mythos Previewの発表と同時に立ち上げられた、世界で最も重要なソフトウェアのセキュリティを確保するための業界横断協力プログラムです。Anthropicが主導し、世界の主要テクノロジー企業・金融機関・オープンソース団体が連携しています。

参加パートナーには、Amazon Web Services(AWS)、Apple、Broadcom、Cisco、CrowdStrike、Google、JPMorganChase、Linux Foundation、Microsoft、NVIDIA、Palo Alto Networksが名を連ねています。
各パートナー企業はClaude Mythos Previewへのアクセス権を取得し、自社システムの脆弱性発見・修正に活用することができます。

| 項目 | 内容 |
|---|---|
| 目的 | 世界の重要ソフトウェアインフラのセキュリティ強化 |
| 主要パートナー | AWS、Apple、Broadcom、Cisco、CrowdStrike、Google、JPMorganChase、Linux Foundation、Microsoft、NVIDIA、Palo Alto Networks |
| モデルアクセス条件 | 防衛的サイバーセキュリティ目的に限定 |
| Anthropicの投資 | パートナー向けに$100Mの利用クレジットを提供 |
| オープンソース支援 | Linux FoundationのAlpha-OmegaとOpenSSFに250万ドル、Apache Software Foundationに150万ドル |
研究プレビュー期間中、パートナー企業にはモデル利用クレジットを提供。
料金は入力100万トークンあたり25ドル、出力100万トークンあたり125ドルとなっており、Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundryを通じてアクセスできるようになっています。
スマートフォンでも動作するGoogleの最強オープンモデルであるGemma 4について、詳しく知りたい方は以下の記事も参考にしてみてください。

Claude Mythos Previewの特徴
Claude Mythos Previewの最大の特徴は、サイバーセキュリティ能力において従来のAIモデルとは一線を画す性能を発揮していることです。
同時に、コーディング・数学・推論・マルチモーダルといった汎用能力においても、競合モデルを大きく引き離すベンチマーク結果を示しています。
ベンチマークの数値などについては、System Card:Claude Mythos Previewを参考にしています。
| 評価ベンチマーク | Claude Mythos Preview | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 93.9% | 80.8% | — | 80.6% |
| SWE-bench Pro | 77.8% | 53.4% | 57.7% | 54.2% |
| SWE-bench Multilingual | 87.3% | 77.8% | — | — |
| Terminal-Bench 2.0 | 82% | 65.4% | 75.1% | 68.5% |
| GPQA Diamond | 94.5% | 91.3% | 92.8% | 94.3% |
| USAMO 2026(数学) | 97.6% | 42.3% | 95.2% | 74.4% |
| MMMLU(多言語) | 92.7% | 91.1% | — | 92.6% |
| CyberGym(脆弱性再現) | 0.83 | 0.67 | — | — |
サイバーセキュリティ能力の圧倒的な飛躍
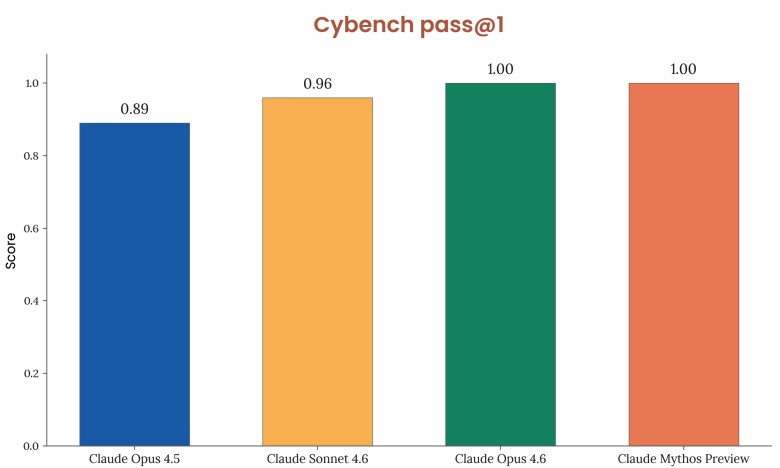
Claude Mythos Previewは、これまでに評価されたAIモデルの中で最もサイバー能力の高いモデルです。内部評価スイートのほぼ全項目を満たし、既知のCTF形式のベンチマークはほぼ飽和状態にあります。
特筆すべきは、Cybenchでのスコア100%(pass@1)、CyberGymでのスコア0.83(Claude Opus 4.6は0.67)という実績です。
コーディング・ソフトウェアエンジニアリング
ソフトウェアエンジニアリングの分野でも、Claude Mythos Previewは圧倒的な実力を発揮。SWE-bench Verifiedでは93.9%のスコアを達成しており、Claude Opus 4.6の80.8%を大幅に上回っています。
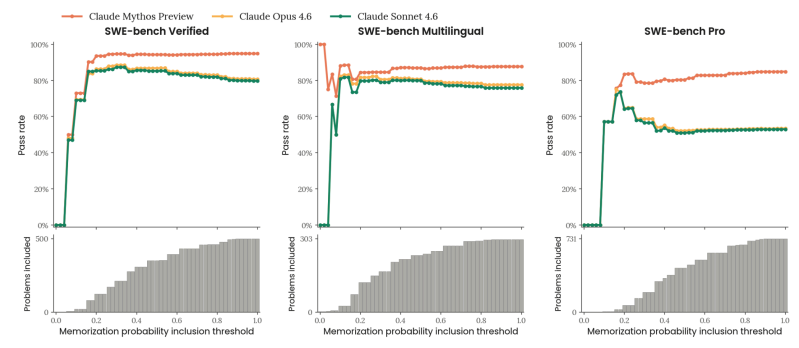
マルチファイル・大規模リポジトリを対象としたSWE-bench Proでも77.8%を記録しています。これはGPT-5.4の57.7%やGemini 3.1 Proの54.2%と比較して高いスコアです。
数学・推論・知識ベンチマーク
数学領域では、2026年のUSAMOで97.6%という突出したスコアを記録しています。これは複数の証明問題を含む6問構成の競技数学であり、GPT-5.4の95.2%、Gemini 3.1 Proの74.4%を上回るものです。
GPQA Diamondでは94.5%を達成しています。長文コンテキスト処理を評価するGraphWalksでは、BFS 256K-1M問題で80.0%を記録しており、GPT-5.4の21.4%を大幅に上回っています。
マルチモーダル・エージェント能力
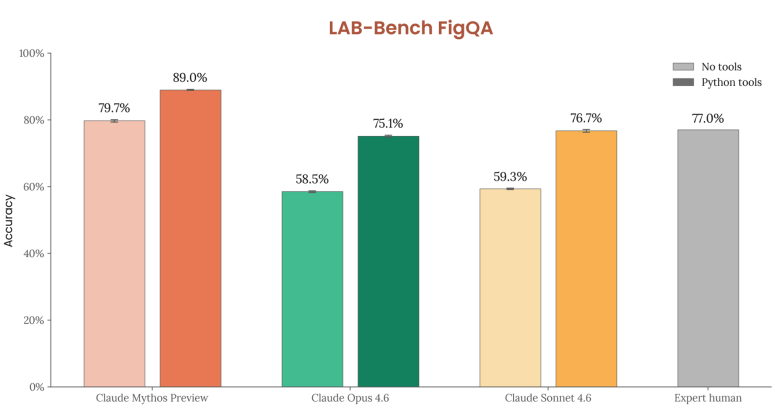
マルチモーダル領域では、生物研究論文の科学的図表を理解するLAB-Bench FigQAで89.0%、GUI操作を評価するScreenSpot-Proで92.8%を記録しています。
図表理解・グラフ読み取りを評価するCharXiv Reasoning with toolsでは93.2%と高水準を示しています。
エージェント能力を評価するOSWorldでは79.6%を達成しており、実際のUbuntu環境でファイル管理・Web操作・文書編集などのタスクを自律的に完了できることが示されています。人間の知識の限界に挑むHumanity’s Last Exam(HLE)では、ツールなしで56.8%、ツールありで64.7%のスコアを記録しています。


Claude Mythos Previewの安全性・制約
Claude Mythos PreviewはAnthropicの「責任あるスケーリングポリシー(RSP)v3系」に基づいて評価・管理されています。
このフレームワークでは、モデルの能力がどの脅威モデルのしきい値を超えているかを定期的に評価し、それに応じたリスク軽減策を実施することが定められています。
安全性評価は社内チームだけでなく、政府機関を含む外部テスターも参加して実施。
評価領域はサイバーセキュリティ、制御喪失、CBRN関連リスク領域、有害な操作にわたっています。
| リスク区分 | 評価結果 | 適用された対策 |
|---|---|---|
| CB-1(既知の化学・生物兵器) | しきい値を超えている可能性あり | リアルタイム分類器ガード・アクセス制御を適用 |
| CB-2(新規化学・生物兵器) | しきい値を超えていない | CB-1と同等の対策を適用 |
| 自律性脅威モデル1(初期ミスアライメント) | 適用あり・リスクは非常に低い | アライメント評価・継続的モニタリング |
| 自律性脅威モデル2(AI R&Dの自動化) | 適用なし | 継続監視 |
| サイバー悪用リスク | 高(このため一般公開を制限) | プローブ分類器・限定パートナーアクセス |
目標整合性の観点では、Claude Mythos Previewはこれまでにリリースされたモデルの中で最も整合性が高いとの評価です。
ビジョン×コーディング特化型マルチモーダルモデルであるGLM-5V-Turboについて、詳しく知りたい方は以下の記事も参考にしてみてください。
【課題別】Claude Mythos Previewが解決できること
Claude Mythos Previewは、現在のソフトウェアセキュリティや開発現場が抱える複数の構造的な課題に対応できる可能性を持っています。
| 課題 | 解決できること | 解決が難しいこと |
|---|---|---|
| セキュリティ脆弱性の特定 | ゼロデイ脆弱性の自律的発見・PoC生成 | 適切に設定・パッチ済み環境での新規発見 |
| 大規模コードレビュー | マルチファイル・複数言語対応の自動修正 | ビジネスロジックの深い理解が必要な判断 |
| 研究・知識処理 | 科学論文・複雑な図表の高精度な理解・要約 | 最新の非公開研究・高度な仮説生成 |
| 数学的証明 | 競技数学レベルの問題解決・証明生成 | 未解決の数学的難問(完全な解決は困難) |
セキュリティ脆弱性の発見・修正コストを削減できる
ソフトウェアのセキュリティ診断は、これまで専門エンジニアによる手動の調査や膨大なテストが必要でした。Claude Mythos Previewはこの作業を大幅に自律化できる可能性が高いです。
例えば、OpenBSDに27年間存在し続けたゼロデイ脆弱性やFFmpegに16年間残っていた脆弱性をClaude Mythos Previewが発見した事例が報告されています。
自動セキュリティテストツールが繰り返し実行しても一度も検出できなかったコード行の問題を特定したケースもあります。従来の自動ツールが見逃していた類の脆弱性に対しても高い精度を発揮しており、診断コストの削減と品質向上の両立が期待されます。
複雑なソフトウェア開発課題を自律的に解決できる
SWE-bench ProやTerminal-Bench 2.0での高スコアが示すように、大規模・複雑なソフトウェア課題を最小限のヒントで解決する能力があります。
複数ファイルにまたがる変更、9言語での対応、コマンドライン環境でのリアルタイム作業など、現場に近い条件での高い成功率を達成。
もしClaude Codeと統合した場合には、ソフトウェアの読み込み・実行・テスト・デバッグをエージェントが自律的に繰り返す「エージェント型コーディング」も実現するでしょう。
これにより開発者が直接コードを書く時間を大幅に削減できます。
専門的な研究・知識処理を高精度かつ高速に実行できる
GPQA DiamondやCharXiv Reasoningでの高スコアは、専門分野の知識処理においても高い能力を持つことを示しています。生物研究論文の科学的図表の理解や、2,300件以上の実際の科学チャートを使った推論評価など、研究分野での実用的な活用が見込まれます。
また、BrowseCompで86.9%のスコアを記録しており、Webから見つけにくい情報を検索・取得する能力も高く評価されています。トークン消費量もClaude Opus 4.6比で約5分の1と効率的です。
【業界別】Claude Mythos Previewの活用シーン
Claude Mythos Previewは現在、防衛的サイバーセキュリティ目的に限定して提供されています。
ただし、その能力の広さからは、将来的にさまざまな業界での活用が期待されます。以下では現在の限定利用の範囲と将来の可能性を含めて考えていきます。
サイバーセキュリティ・インフラ保護
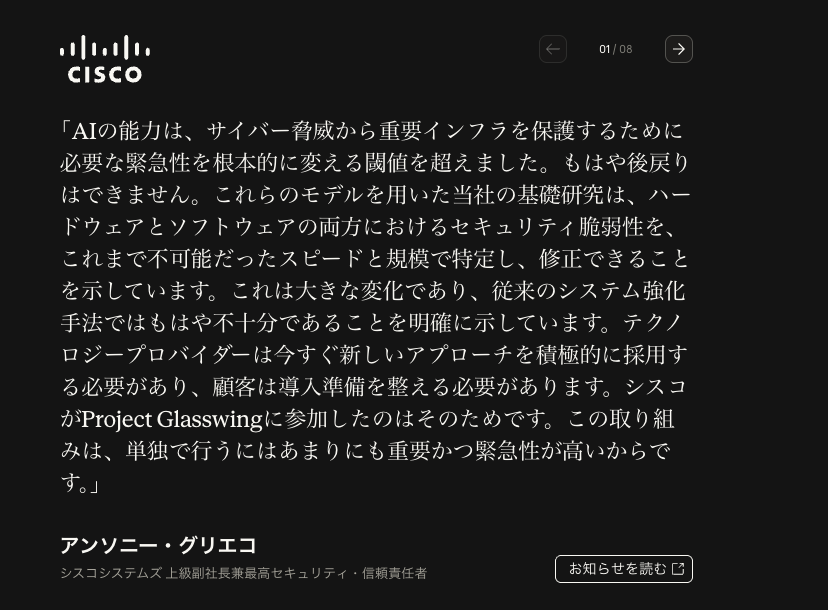
Project Glasswingのパートナー企業は、自社システムや担当するインフラへの脆弱性診断にClaude Mythos Previewを活用しています。
基盤システムやソフトウェアのセキュリティ脆弱性を、従来不可能だったスピードと規模で特定・修正できることが確認できます。
ソフトウェア開発
コーディングベンチマークでの圧倒的なスコアから、ソフトウェア開発の自動化支援への活用が期待されます。
大規模オープンソースプロジェクトへのコントリビューション、マルチ言語コードベースのリファクタリング、自動的なバグ修正パイプラインの構築などでの活用が想定できます。
ただし、現時点でこれらの用途への一般公開は行われておらず、将来的にサイバーセキュリティ以外の用途へアクセスが拡大するかどうかは、現時点では明らかにされていません。
研究・学術分野
GPQA DiamondやUSAMO 2026などのスコアから、自然科学・数学の研究支援における活用が見込まれます。
LAB-Bench FigQAでの89.0%というスコアは、生物学研究論文の図表解析における実務的な有用性を示しています。
また、Humanity’s Last Examでのスコア64.7%は、人類の知識の限界に迫るような問題設定でも有意なパフォーマンスを発揮。高度な研究解析・文献調査・仮説整理などへの活用が期待できるでしょう。
1Mトークン対応のエージェント型LLMであるQwen3.6-Plusについて、詳しく知りたい方は以下の記事も参考にしてみてください。

よくある質問


Claude Mythos登場のインパクトは大きい!
Claude Mythos Previewは、Anthropicが開発した中でも特に高い性能を持つフロンティアモデルであり、コーディングや推論、サイバーセキュリティなど複数の領域で従来モデルを上回る結果が報告されています。
同時に、その高度な能力に伴うリスクにも対応するため、限定公開や安全性評価の強化といった慎重な運用が採られており、AI活用とリスク管理を両立する新たなアプローチとして注目されています。
今後はこうした取り組みを通じて、安全性を担保しながら実運用への適用範囲が徐々に拡大していく可能性もあり、AIの社会実装における重要な転換点となることが期待されます。

最後に
いかがだったでしょうか?
Claude Mythos Previewは、AI能力の飛躍的な向上とそれに伴うリスク管理という現代AIが直面する課題を象徴するモデルです。一方で、AI能力の急速な進歩に対して十分な安全メカニズムを整備できるかどうかは、Anthropic自身も課題として認識しています。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


