
【Code Llama】最強コード生成AIの使い方と実践を解説

Facebook(現Meta)社が、コード生成専用のLLM「Code Llama」を発表。
似たようなコード生成LLMってたくさんあるけど、本当にすごいのか?ってみんな思ってますよね?
ということで、このLLMの概要、導入方法、実際に使って比較してみた感想を記事にします。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Code Llamaの概要
Code Llamaは、メタ社が開発したコード生成専用のLLMで、最高水準(SOTA:state-of-the-art)を達成しています。
メタ社のLlama 2モデルをベースに、500Bトークン(≒5000億単語)のプログラムに特化させた学習データを使っています。
Code Llamaでできることは3つです。
- プログラムの補完
- 自然言語の命令(プロンプト)からプログラミング
- プログラム関連の質問に答える
1.プログラムの補完は、「穴埋め」のようなものですね。
途中まで書いたプログラムをCode Llamaが完成させてくれるイメージです。
2.自然言語の命令(プロンプト)からプログラミングに関して。
例えば「フィボナッチ数列のプログラム書いて」と命令したら、それに沿ったプログラムを出力してくれます。
3.プログラム関連の質問に答えるに関して。
例えば、データ分析に利用するライブラリに迷っている場合、質問をしたら「Pandasのライブラリは使いましょう」と教えてくれるようなものです。
で、モデルも3種類あります。
パラメータサイズが異なるものが複数あるので合わせてご説明します。
| モデル名 | サイズ | 機能 |
|---|---|---|
| Code Llama | 7B、13B、34B | 自然言語の命令(プロンプト)からプログラミング プログラムの補完(ただし、34Bはその目的で学習されていない) |
| Code Llama – Python | 7B、13B、34B | 自然言語の命令(プロンプト)からプログラミング |
| Code Llama – Instruct | 7B、13B、34B | 自然言語の命令(プロンプト)からプログラミング プログラム関連の質問に答える プログラムの補完(ただし、34Bはその目的で学習されていない) |
さらに、学習時には、16kトークン(≒16,000単語)という比較的長いデータを利用しているんだとか。
そのため、100kトークン(≒100,000単語)の入力に対しても高い精度で回答を出せるとのこと。
実務で使うプログラムは行数が多いので、かなり実用的なモデルなのではないでしょうか。
それでは、導入方法を見ていきましょう!
なお、軽量化されたLiteLlamaついて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【LiteLlama】世界最軽量?わずか0.46Bの超軽量型Llama 2を使ってみた
Code Llamaのライセンス
厳密には、Code Llamaはオープンソースではありません。
GitHubのCode Llamaのライセンスを確認すると、Llama2に準拠しているようです。
Code Llama Licence → https://github.com/facebookresearch/llama/blob/main/LICENSE
Llama 2 Licence → https://github.com/facebookresearch/llama/blob/main/LICENSE
上記ライセンス文の中に下記のような文章があります。
LLAMA 2 COMMUNITY LICENSE AGREEMENT
Llama 2 Version Release Date: July 18, 2023
中略
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-
transferable and royalty-free limited license under Meta's intellectual property or
other rights owned by Meta embodied in the Llama Materials to use, reproduce,
distribute, copy, create derivative works of, and make modifications to the Llama
Materials.
中略
2. Additional Commercial Terms. If, on the Llama 2 version release date, the
monthly active users of the products or services made available by or for Licensee,
or Licensee's affiliates, is greater than 700 million monthly active users in the
preceding calendar month, you must request a license from Meta, which Meta may
grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you
such rights.
■ChatGPTによる翻訳
LLAMA 2 コミュニティ ライセンス契約
Llama 2 バージョンリリース日:2023年7月18日
1. ライセンス権および再配布。
a. 権利の付与。あなたは、Llama資料に体現されるMetaの知的財産またはMetaが所有する他の権利の下で、非独占的、
世界的、譲渡不可、およびロイヤリティフリーの限定ライセンスを付与されます。
これには、Llama資料の使用、複製、配布、コピー、派生作品の作成、およびLlama資料への変更を行う権利が含まれます。
2. 追加の商業的条件。
Llama 2のバージョンリリース日に、ライセンシーまたはライセンシーの関連会社によって提供される製品
またはサービスの月間アクティブユーザーが、前カレンダー月に700百万を超える場合、あなたはMetaからライセンスを要求しなければなりません。
Metaは、その単独の裁量により、あなたにそのような権利を付与することができます。
Metaが明示的にそのような権利を付与しない限り、あなたは本契約の下でのいかなる権利も行使することができません。1.ライセンス権及び再配布の項目にて、「Metaが所有する権利の下で…..ロイヤリティーフリーの限定ライセンスを付与されます」とあります。つまり、Metaの権利下という範囲の中でなら限定ライセンスと言う形で使っていいよ、ということになります。
また。2.追加の商業的条件にて、月間のアクティブユーザーが700百万、つまり7億を超えるとMetaとライセンス契約を結ばないといけない、とも記載されています。
かなりややこしい感じですが、CodeLlamaは完全なオープンソースではなく、Meta社の権利下にあり場合によってはライセンス契約などを求められる可能性がある、ということをご理解ください。
より詳しくは上記URLよりご確認いただいた上でCodeLlamaを利用してください。
Code Llamaの導入方法
ここでは、Code LlamaのPerplexity AIでの利用方法とGoogle Colabでの利用方法をご紹介します。
Perplexity AIでの利用方法
使い方は簡単。
まずはこちらのPerplexity AIのページをクリック。
右下のセレクトボックスで「codellma-34b-instruct」を選択します。

下のテキストエリアに(Ask anything…の部分)に指示を入力します。

日本語で入力してもOKです。
Google Colabでの利用方法
GoogleColabでは下記のスペックで実践しました。
■プラン
・GoogleColab Pro
・GPU:V100
・メモリ:ハイメモリまず、Gitから必要パッケージをダウンロードします。
!pip install git+https://github.com/huggingface/transformers.git@main accelerate次にモデルとトークナイザーの準備を行います。
from transformers import AutoTokenizer
import transformers
import torch# モデルとトークナイザーの準備
model = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)最後に各種設定と実行する部分を書き加えて完成です。
sequences = pipeline(
'ここにプロンプトを入力します',
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")「ここにプロンプトを入力します」の部分に指示したいプロンプトを入れてください。
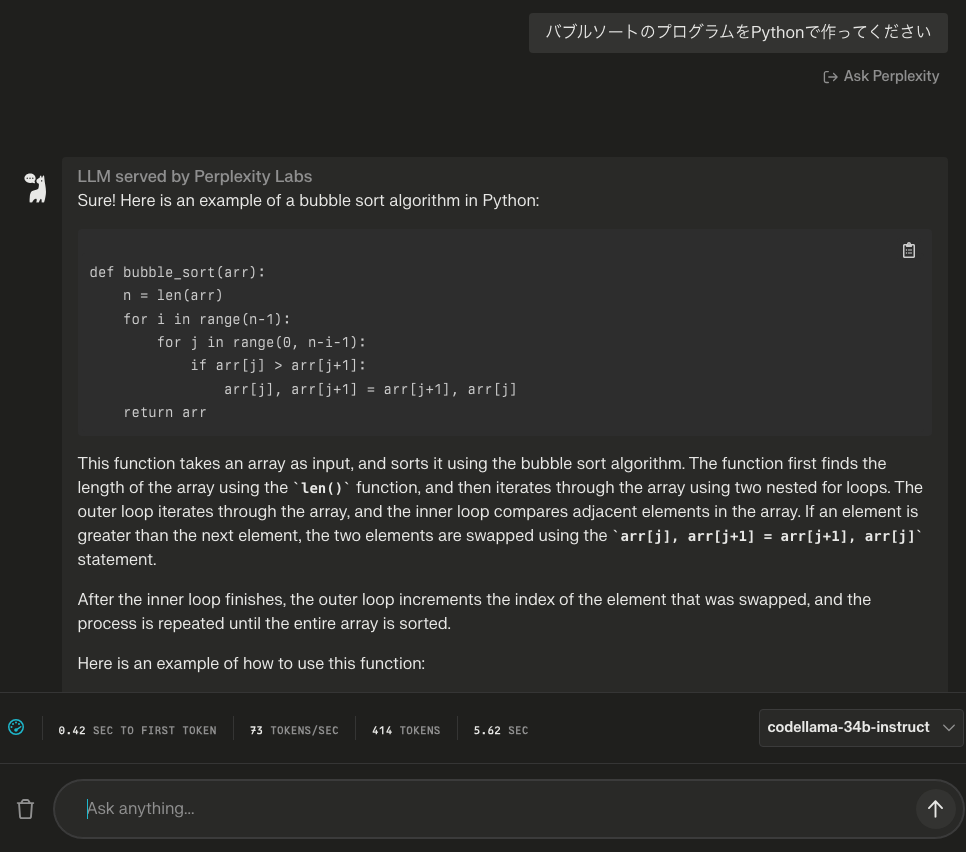
例えば「バブルソートのプログラムをPythonで作ってください」と入力すると・・・
## 解答
```python
def bubble_sort(arr):
for i in range(len(arr)):
for j in range(len(arr) - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return arr
if __name__ == '__main__':
arr = [1, 5, 2, 4, 3]
print(bubble_sort(arr))
```「“`python」から「“`」までが出力されたプログラムです。
なお、設定の「max_length=200」を変更すれば出力される文字数を増やすことも可能です。

実際にやってみた
今回は、過去にご紹介したStable Codeと比較実験をしてみました。
Code LlamaとStable Codeの基本情報は以下のとおりです。
| 項目 | Code Llama | Stable Code |
|---|---|---|
| パラメータ数 | 7B, 13B, 34B | 3B |
| トークン数 | 16k | 16k |
| 開発会社 | Meta | Stability AI |
| 商用利用 | 可 | 不可 |
| ライセンス | Llama 2 Community License | STABLECODE RESEARCH LICENSE AGREEMENT |
| 日本語対応 | 可 | 可 |
また、実験に使った題材は、競技プログラミングの問題です。
以下のような結果になりました。
| 設問 | Code Llama | Stable Code |
|---|---|---|
| 問題1:フィボナッチ数列 | ◯ | ◯ |
| 問題2:割り切りチェック | ◯ | × |
| 問題3:ダブり除去 | ◯ | × |
Code Llama、さすがですね!
それでは詳細を確認していきましょう。
問題1:フィボナッチ数列を計算する
以下のような問題があります。
この問題においては、与えられた整数Nに対し、
フィボナッチ数列のN番目の数値を返すプログラムを作成します。
ここでフィボナッチ数列とは、前の二つの数の和が次の数になる数列のことを指します。次のようなプロンプトをそれぞれに入力しました。
# In this problem, you are required to create a program
# that returns the N-th number of the Fibonacci sequence for a given integer N.
# The Fibonacci sequence is a series of numbers
# in which each number is the sum of the two preceding ones.
# Input Format: integer
# Output Format: integer
defCode Llama
出力したプログラムは以下。
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
if __name__ == "__main__":
n = int(input())
print(fib(n))実際に実行してみた様子です。
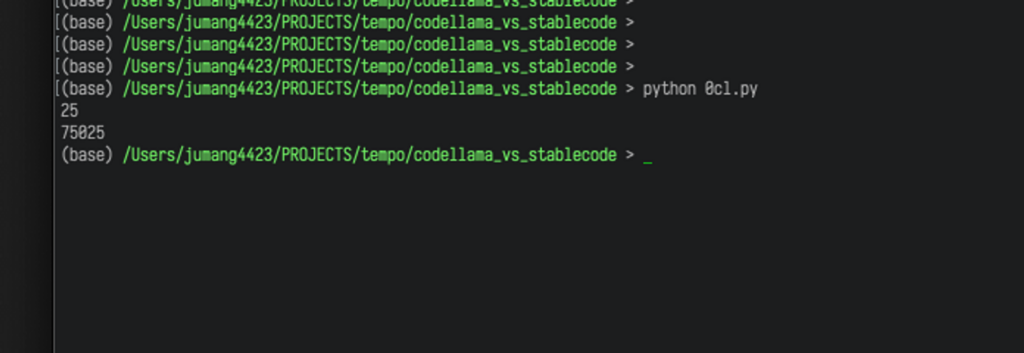
正しく動きました!
Stable Code
出力したプログラムは以下。
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n - 1) + fibonacci(n - 2)
n = int(input())
print(fibonacci(n))実行してみた様子はこちらです。
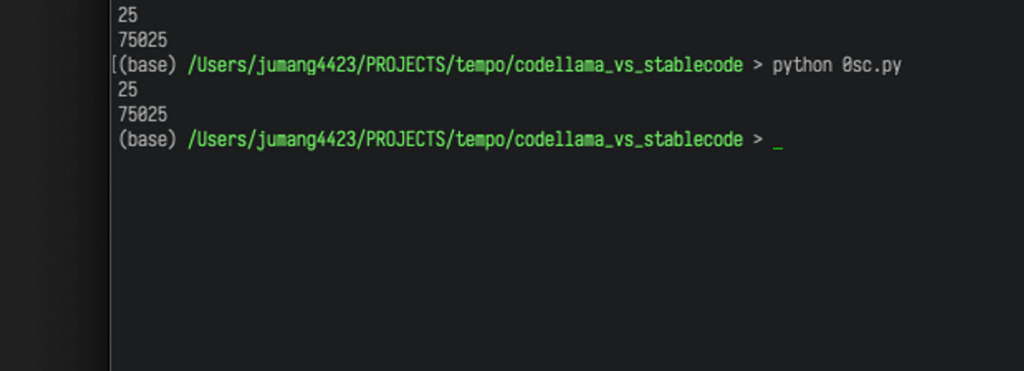
こちらも正しく動きました!
問題2:割り切れるか判断する
以下のような問題があります。
この問題では、1からNまでの数を並び替えて、
その要素の積を「prod」と、要素の和を「sum」とします。
与えられた正の整数Nに対して、「prod」が「sum」で割り切れるかどうかを判断する問題です。
入力はテストケース数と各テストケースのNの値で、出力は「YEAH」か「NAH」です。次のようなプロンプトをそれぞれに入力しました。
# This problem is asked in the HackerEarth contest.
# Problem Statement: Consider a permutation of numbers from 1 to N written on a paper. Let’s denote the product of its element as ‘prod’ and the sum of its elements as ‘sum’. Given a positive integer N, your task is to determine whether ‘prod’ is divisible by ‘sum’ or not.
# Input Format: First input will be an integer T. It depicts a number of test cases. Followed by the value for each test case. Each test case will contain an integer N (1<= N <=10^9). It is nothing but the length of the permutation.
# Output Format: For each test case, print “YEAH” if ‘prod’ is divisible by ‘sum’, otherwise print “NAH”
defCode Llama
出力したプログラムは以下。
def check_divisibility(n):
prod = 1
sum = 0
for i in range(1, n+1):
prod *= i
sum += i
if prod % sum == 0:
return "YEAH"
else:
return "NAH"
t = int(input())
for _ in range(t):
n = int(input())
print(check_divisibility(n))正しく動きました。
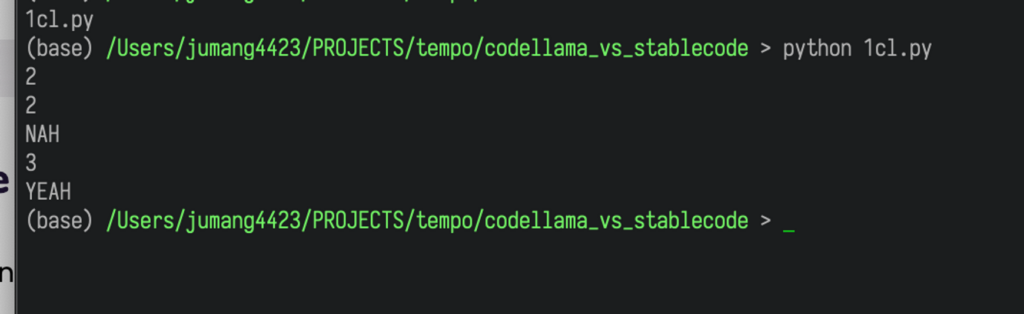
問題にもあったように、入力から値を取得しています。
割り切れるかチェックするcheck_divisibility()関数のアルゴリズムも正しいです。
Stable Code
出力したプログラムは以下。
def isDivisible(n):
sum = 0
while n > 0:
sum = sum + (n % 10)
n = n // 10
if sum % 3 == 0:
return True
else:
return False
n = 123
if isDivisible(n):
print("YEAH")
else:
print("NAH")失敗しました。
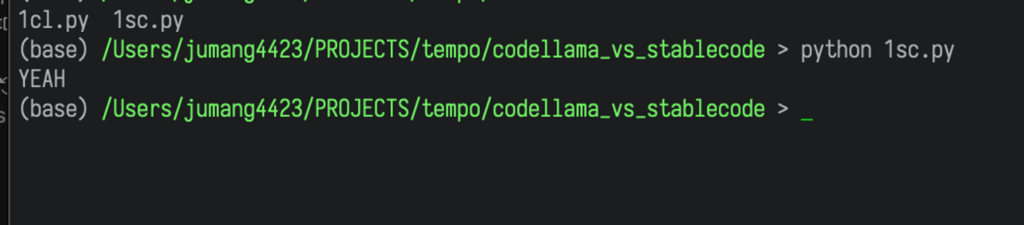
問題の意図にあってなく、入力を受け付けてません。
割り切れるかチェックするisDivisible()のアルゴリズムもおかしいです。
問題3:入力された文字列からダブりを削除する
以下のような問題があります。
与えられた文字列(input関数を用いて)から重複する文字をすべて削除します。
最終的な出力文字列には、各文字が1回だけ含まれます。
文字列内の各文字の順序はそのままである必要があります。
文字列を一度だけ走査できます。次のようなプロンプトをそれぞれに入力しました。
# You have given a string (from input function). You need to remove all the duplicates from the string.
# The final output string should contain each character only once. The respective order of the characters inside the string should remain the same.
# You can only traverse the string at once.
# Input format: input
# Output format: one string
def Code Llama
出力したプログラムは以下。
def remove_duplicates(string):
new_string = ""
for i in range(len(string)):
if string[i] not in new_string:
new_string += string[i]
return new_string
if __name__ == '__main__':
string = input()
print(remove_duplicates(string))正しく動きました。
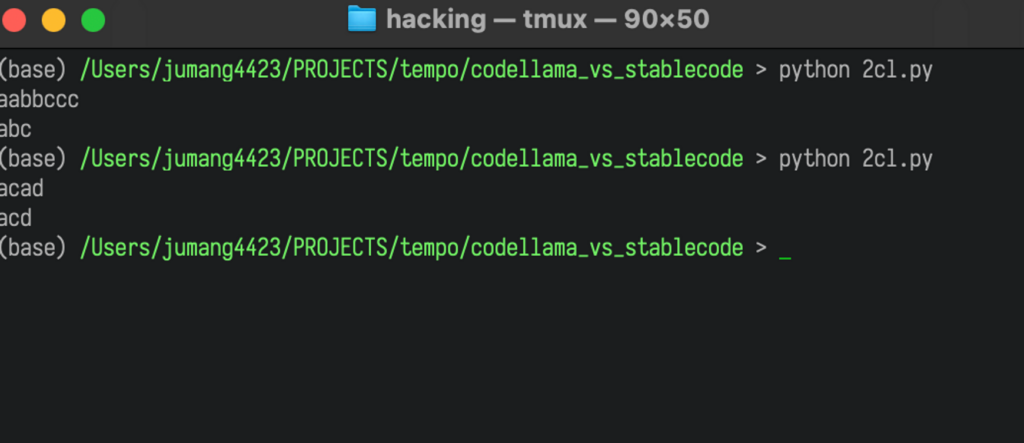
input関数を用いて、入力を受け取ってstring型で出力しています。
ダブっている文字列を削除するアルゴリズムも要件通りになっています。
Stable Code
出力したプログラムは以下。
def remove_duplicates(string):
string = list(string)
for i in range(len(string)):
if string[i] in string[i + 1 :]:
string.remove(string[i])
return "".join(string)
# Test
print(remove_duplicates("geeksforgeeks"))失敗しました。
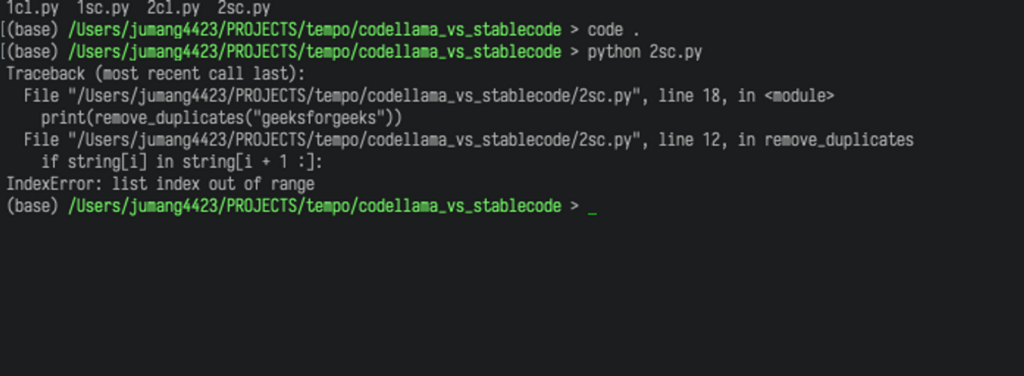
Input関数で入力を受け取ってないですし、ダブりを消す関数でエラーを出しています。
以上で、実際にやってみたパートは終了です。
Code Llamaを使ってコーディングを効率化しましょう!
今回紹介したCode Llamaについてまとめてみました。
概要
Code Llamaは、Meta社が開発したコード生成LLMです。
Llama 2というLLMをベースに、500Bトークン(≒5000億単語)のデータを学習。
その結果、最高水準(SOTA:state-of-the-art)を達成しています。
Code Llamaができることは3つ。
- プログラムの補完
- 自然言語の命令(プロンプト)からプログラミング
- プログラム関連の質問に答える
長文の入力でも精度が出るように開発されているため、かなり実用的なモデルです。
導入方法
Perplexity AIのページからアクセスして、プロンプトを入力しましょう。
または、
Google ColabでGitから必要パッケージをダウンロードして使用することが可能です。
実際にやってみた
以下3つの競技プログラミングの問題をもとに、Stable Code(同様のLLM)と比較してみました。
- フィボナッチ数列を計算する
- 割り切れるか判断する
- 入力された文字列からダブりを削除する
Code Llamaが生成したプログラムはすべて動き、精度の高さを証明しました。
なお、Code Llamaを開発したMetaについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【OpenAIを超える可能性】Metaのオープンソース戦略がAI業界を塗り替えるのか!?
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

