
【CriticGPT】ChatGPTのミスを発見し修正できるチェッカー!

WEELメディア事業部LLMリサーチャーの中田です。
6月27日、「ChatGPTが出力した内容にミスが無いか」をチェックできるAIモデル「CriticGPT」を、OpenAIが公開しました。
このAIモデルはGPT-4をベースとしており、ChatGPTの出力するプログラムコードのミスを検出して、人間の専門家よりも正確なフィードバックを提示してくれるんです!
この記事ではCriticGPTの仕組みや凄さについて解説します。
ぜひ、最後までご覧ください。

CriticGPTによってChatGPTのハルシネーションを低減!
OpenAI社が、ChatGPTの出力プログラム中のエラーを発見し、適切なフィードバックや修正案を提出できるAIモデル「CriticGPT」を公開しました。
CriticGPTはGPT-4をベースとして構築されており、ChatGPTが出力したコードの中から、ハルシネーションに当たる部分を高精度で検出できるそうです。
例えば以下の図では、ChatGPTが生成したコードに対し、CriticGPTが「startswithメソッドの利用は適切ではない」と指摘し、適切な修正案を示しています。

このようにCriticGPTを使うことで、ChatGPTが生成したコードの誤りの発見率を、60%向上させることに成功したとのこと。
また、上記のような「ChatGPTへのフィードバック文」に対し、人間の専門家が書いた場合と、ChatGPT・CriticGPTが書いた場合で比較し、評価者に「どちらの文章が適切か」と質問したところ、64%以上の確率で「ChatGPT・CriticGPTの方が良い」と回答したそうです。
また、コード中に意図的に挿入されたバグをどの程度発見できるかを、人間とChatGPT・CriticGPTで比較したところ、CritcGPTが最も多く発見し、次いでChatGPTが多かったとのことです。
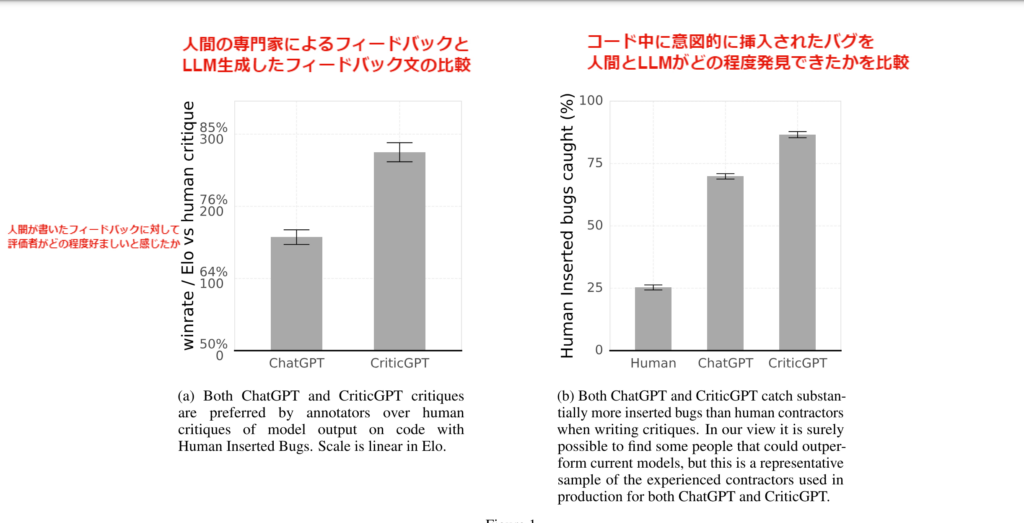
要するに、エラーの発見タスクの性能において、LLMが人間を超えたということになります。
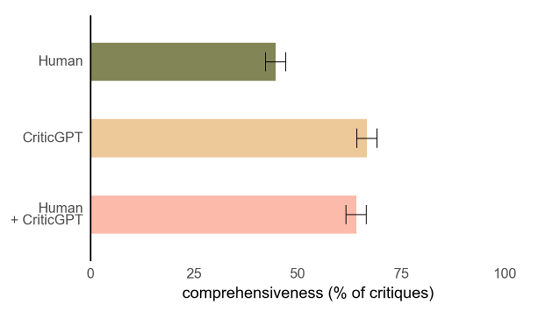
さらに、以下の図からも分かる通り、「人間のみ(緑)」「CriticGPTのみ(オレンジ)」「人間がCriticGPTを使った場合(ピンク)」で「コードに対するフィードバックの完全性」を比較した場合、人間よりもCriticGPTのフィードバックの完全性の方が、高いことが分かります。
なお、ハルシネーション対策として、RAGよりも優秀なチューニング手法について詳しく知りたい方は、下記の記事を合わせてご確認ください。
AIが進化しすぎて人間では手に負えなくなっている
現在、多くのAIシステムはRLHF(Reinforcement Learning from Human Feedback)によって学習されています。
RLHFとは、AIの出力に対して、人間が適切なフィードバックをするシステムです。
ChatGPTも、このRLHFを用いて人間のフィードバックを反映することで、精度を向上させているのです。しかし、AIそのものが高度化するにつれ、「人間がAIにフィードバックをすること自体」が難しくなってきつつあります。
例えば、PhDレベルの科学の質問に対して、LLMは高い精度で回答できますが、これに対して一般の人間では適切なフィードバックを行うのは難しいでしょう。
そこで本研究では、こうした問題に対処し、AIモデルの出力に対して適切なフィードバックを実施するために、「批評家(critic)」モデルを学習して、AIにフィードバックをさせているのです。

CriticGPTはRLHFで学習されたGPT-4ベースのモデル
まずコードに対して、人間のエンジニアが意図的にエラーを挿入し、そのエラーについてのフィードバックを記述することで、データを構築します。
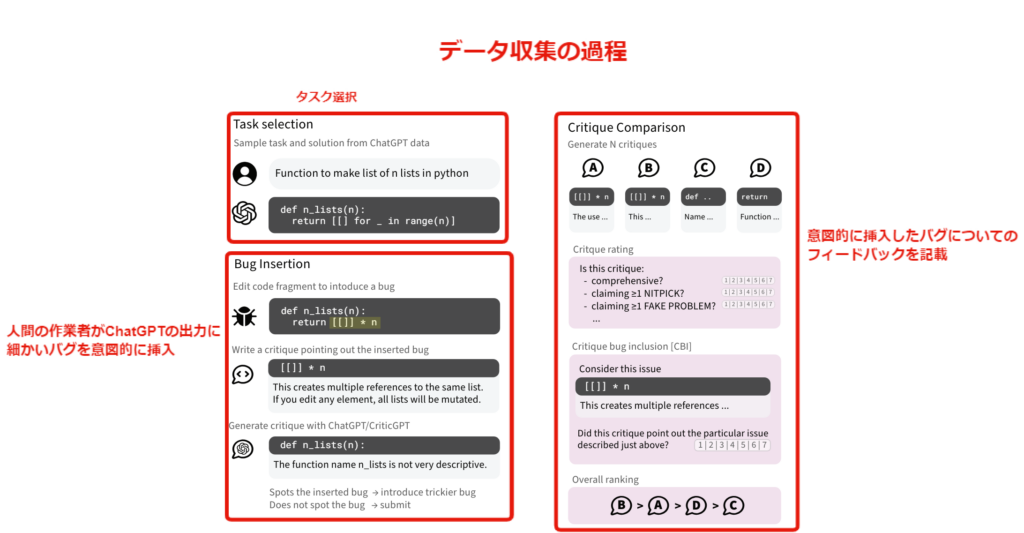
このデータを用いて、GPT-4ベースのCriticGPTを、RLHFで学習します。
CriticGPTの評価では、人間の評価者によるテストで行われます。この評価は、以下の4つの観点で行われます。
- 重要な問題をすべて網羅しているか(comprehensiveness)
- 特定の既知のバグを指摘できるか(critique-bug inclusion, CBI)
- 存在しない問題を指摘していないか(hallucination)
- 批評が建設的で明確か(helpfulness and style)
これらの観点について、人間の評価者が1-7の順序尺度で評価します。評価は、「同じコードに対する4つのフィードバック文を同時に比較する」という形で行われ、評価者は「どのフィードバック文がどのモデルによるものか」は知らされずに評価します。
学習プロセスでは、コードに対してCriticGPTが生成したフィードバック文を人間の評価者が評価し、その評価を用いて報酬モデルを学習します。具体的には、以下の通りです。
- データセット内の各(質問, 回答)ペアに対し、複数のフィードバック文をサンプリング
- 人間の評価者が、サンプリングされたフィードバック文を評価
- 人間の評価から報酬モデルを学習
- 報酬モデルに対してPPOでポリシーを最適化
- 推論時にForce Sampling Beam Search (FSBS)を適用
この報酬モデルを用いて、CriticGPTをさらに洗練させていきます。
FSBSは、criticが生成するフィードバックの長さとハイライトの数のトレードオフを制御する、推論時の探索手法です。報酬モデルのスコアとハイライト数の重み付き和が最大になるようなフィードバックを選択することで、網羅性の高いフィードバックを生成しつつ、ハルシネーションを抑制します。
なお、RAGの進化版のハルシネーション対策手法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

CriticGPTを使いこなせる人間が最強のエンジニアになれる
本研究では、人間やChatGPTよりも、CriticGPTの方が高い精度でフィードバックを行えることが分かりました。ただ、人間がCriticGPTを使用してタスクを実行した場合、CriticGPT単体よりも多く、かつ正確にバグを発見できたとのことです。
以下の図は、「コードに対するフィードバックに含まれるハルシネーションの割合」を比較したものです。これを見ると、人間がCriticGPTを使った場合に、ハルシネーションが最も低くなることが分かります。
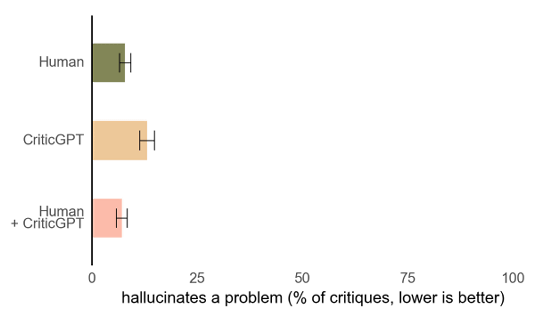
そのため、もしもChatGPTのサービスにCriticGPTが搭載されたら、ChatGPTのコード生成精度が格段にアップするかもしれないですね。
例えば、以下のようなユースケースが考えられるでしょう。
- ユーザーがChatGPTに指示を与える
- ChatGPTがコードを生成
- ユーザーがCriticGPTを用いてコードを修正
- より洗練されたコードが生成される
ChatGPTによって生成されたコードを使用したら、重大なシステムエラーに繋がったという事例は意外と多いため、是非とも実装されてほしいです。
また、CriticGPTを使いこなせるエンジニアは、これまで以上に正確にバグを発見できるようになり、作業効率が大幅にアップするでしょう。
なお、OpenAIが発表した「ChatGPTの正しい動作」に関する指針について詳しく知りたい方は、下記の記事を合わせてご確認ください。

CriticGPTによってChatGPTはもっと進化する
本記事では、ChatGPTが出力したバグを発見できる「CriticGPT」について解説しました。
CriticGPTがChatGPTに本格実装されれば、より品質の高いコードが生成されるようになり、コーディング作業が捗るでしょう。
個人的には、人間がCriticGPTを使った場合が最も良いとのことなので、CriticGPTを使いこなせるエンジニアが市場価値を高めていくのかなと感じました。
最後に
いかがだったでしょうか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


