
Google発の小型×高性能な埋め込みモデル「EmbeddingGemma-300m」の実力とは?

- 308Mパラメータと小型ながら業界最高水準の埋め込み精度を誇る軽量モデル
- オフライン動作が可能で、プライバシー要件の厳しい環境でも利用可能
- sentence-transformersやLangChainとも互換性が高く、RAGやセマンティック検索にもすぐ導入可能
2025年9月4日、Google DeepMindが新たなオープンソースのテキスト埋め込みモデルを発表しました。
今回発表されたモデル「EmbeddingGemma-300m」はわずか308Mパラメータという小型サイズでありながら、文書検索・類似度計算・クラスタリングなどの自然言語処理タスクで業界最高水準の性能を発揮します。
本記事ではEmbeddingGemma-300mの概要から使い方、使ってみた所感についてお伝えします。最後までお読みいただければ、EmbeddingGemma-300mの理解が深まります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
EmbeddingGemma-300mの概要
EmbeddingGemma-300mは、GoogleがGemma 3アーキテクチャを基盤に開発したテキスト埋め込み専用モデル。

入力された文や文書を、意味を保持したベクトルに変換することで、情報検索・分類・クラスタリングなどのタスクを高精度に処理可能です。
EmbeddingGemma-300mはパラメータ数はわずか308Mながら、Massive Text Embedding Benchmarkにおいて500M未満のオープンモデル中トップのスコアを記録しており、特に多言語環境下での検索精度が非常に高いです。
また、同モデルはオフライン実行を前提に開発されており、スマートフォンやノートPCなどのデバイス上でもリアルタイム動作が可能。生成モデルを必要としない分、プライバシーを担保しやすく、個人情報を含む文書データの取り扱いにも最適です。
さらに、sentence-transformersやllama.cpp、transformers.js、LangChainといったAIライブラリ・フレームワークとも高い互換性を持ち、RAGやセマンティック検索の構築にもすぐに組み込める点も特徴的。
特にRAGでは、EmbeddingGemmaは「検索部分」の精度を大きく左右します。生成モデルに渡す前段階での文書の抽出精度を大幅に高め、従来モデルに比べ「的確な回答が返ってくる」ようになります。
オフラインでの実行も可能
EmbeddingGemma-300mの大きな特長のひとつが、オフラインでの実行が可能であること。
オフライン実行ができることで、以下のような場面で活用できるでしょう。
- インターネット接続が不安定な場所での利用
- 個人情報を含むセンシティブなデータをクラウドに送らずに処理したい場合
- プライバシー要件や法的制限によりクラウド利用が困難な時
- 企業内端末やローカルアプリでの内部文書検索や分類
EmbeddingGemmaは、Gemma 3nと同じトークナイザを利用しており、メモリ効率の面でも優れているため、軽量なRAGパイプラインをローカル環境のみで完結させることも可能。
これにより、セキュアかつ低遅延な検索ができます。


EmbeddingGemma-300mの性能
EmbeddingGemma-300mは、308Mパラメータという小型サイズでありながら、性能は非常に高いです。
下の画像は複数の埋め込みモデルを「モデルサイズ」と「多言語ベンチマークスコア」の2軸で比較したものです。
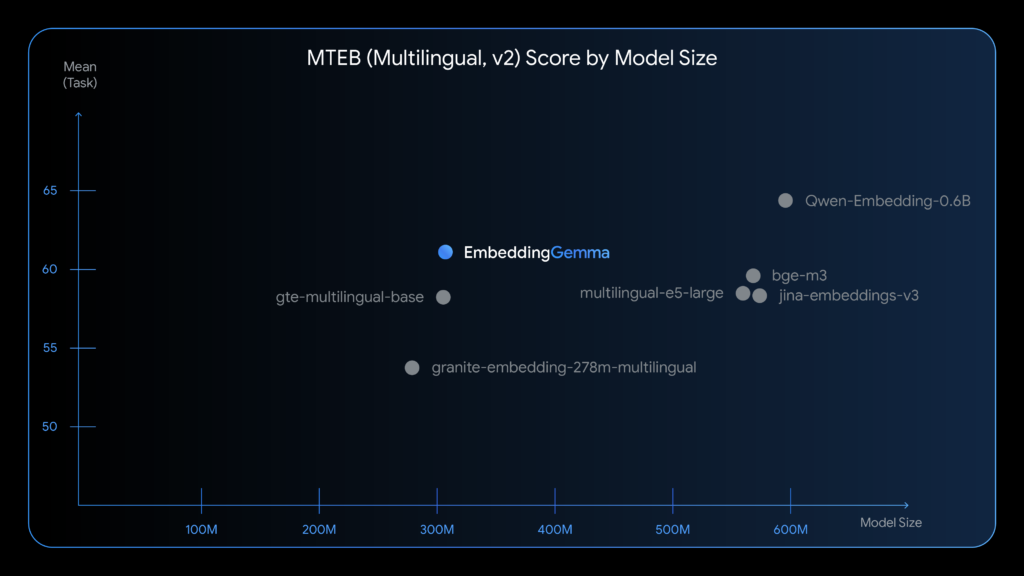
グラフを見てみると多言語対応のベンチマーク「MTEB Multilingual v2」において、同等サイズの他モデルを上回るスコアを記録しています。
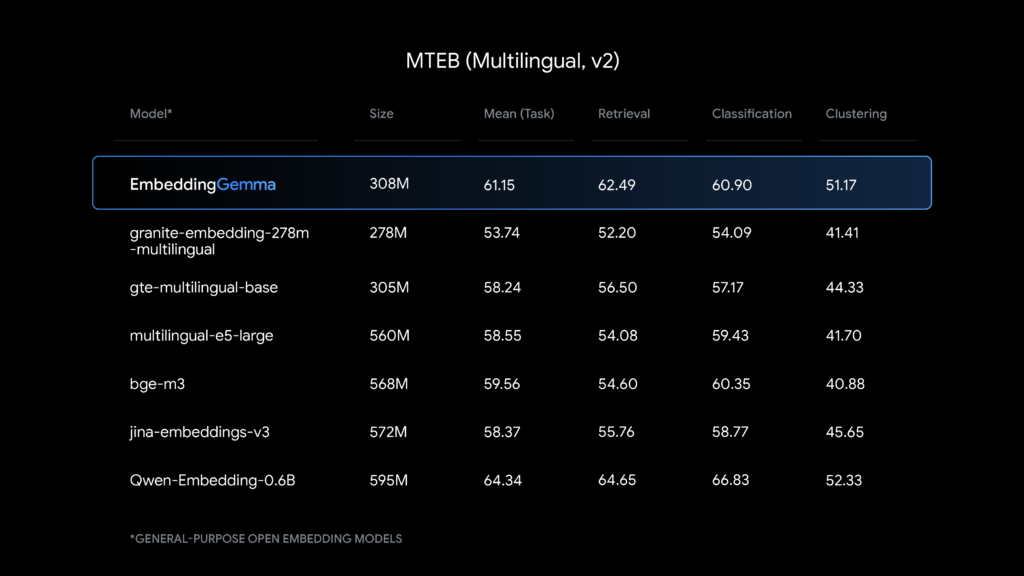
上記の画像もMTEB Multilingual v2の比較結果です。EmbeddingGemma-300mが小型モデルながら、より大きいモデルよりも平均的な性能が高いことがわかります。
つまり、EmbeddingGemma-300mは小型ながら高性能を発揮できるモデルということです。
EmbeddingGemma-300mのライセンス
EmbeddingGemma-300mのライセンスはGemmaです。※1
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️※条件付き |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
上記はEmbeddingGemma-300mのライセンスについてです。基本的には記載の内容は全て可能ですが、配布だけ注意が必要です。配布を行う場合には、以下の事項を明記する必要があります。
- 禁止用途(Prohibited Use Policy)の遵守を明記
- 再配布相手に本ライセンス全文の提供
- 変更したファイルには「改変済み」であることを明記
- 再配布時には “Gemma is provided under…” の注意文を含む「NOTICE」ファイルを同梱
なお、Appleの次世代オンデバイスAI【FastVLM-0.5B】について詳しく知りたい方は、下記の記事を合わせてご確認ください。

EmbeddingGemma-300mの使い方
では実際にEmbeddingGemma-300mを使っていきます。Google Colaboratoryで実装です。
EmbeddingGemma-300mはGated Modelなので、Hugging Faceのページで「You have been granted access to this model」と表示されていれば使用可能です。表示されていない場合には、アクセス申請を行いましょう。
実行時のgoogle colaboratoryの環境
◆システムRAM:3.8 / 53.0 GB
◆GPU RAM:5.0 / 22.5 GB
◆ディスク:41.4 /112.6 GB
◆使用GPU:L4
◆プラン:無料
まずはライブラリのインストールです。
!pip install -U sentence-transformers次にHugging Faceのトークンを入力し、認証を受けます。
from huggingface_hub import login
login("********")あとはモデルのダウンロードと実行です。
サンプルコードはこちら
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer("google/embeddinggemma-300m")
query = "火星はどんな惑星?"
docs = [
"金星は地球に似たサイズを持つ惑星です。",
"火星は赤みを帯びた外観をしており、赤い惑星と呼ばれます。",
"木星は太陽系最大の惑星であり、大きな赤い斑点があります。"
]
# クエリと文書をベクトル化
query_embedding = model.encode_query(query)
doc_embeddings = model.encode_document(docs)
# コサイン類似度でスコア計算
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
for i, doc_emb in enumerate(doc_embeddings):
score = cosine_similarity(query_embedding, doc_emb)
print(f"Doc {i}: 類似度 = {score:.4f}")結果はこちら
Doc 0: 類似度 = 0.5485
Doc 1: 類似度 = 0.6974
Doc 2: 類似度 = 0.5719今回のサンプルコードではセマンティック検索を行っており、自然言語の検索クエリに対して、最も意味の近い文書を見つける処理を行うものです。
その結果、Doc 1が最も火星に近い文章であるという結果になっています。
EmbeddingGemma-300mで埋め込みモデルの力を検証してみる
では次にEmbeddingGemma-300mの性能を検証してみたいと思います。
検証する内容としては次の3つです。
- 日英ペアの意味類似チェック
- 多言語のニュース記事のクラスタリング
- クエリに対してFAQから最適な回答を選ぶ
まずは日英ペアの意味類似チェックからです。
サンプルコードはこちら
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
model = SentenceTransformer("google/embeddinggemma-300m")
# 日本語 ↔ 英語 のペア
pairs = [
("私は猫が好きです", "I like cats"),
("今日は暑いですね", "It's hot today"),
("明日会議があります", "I have a meeting tomorrow"),
("私はPythonが得意です", "Bananas are delicious"),
]
# 類似度を計算
for i, (ja, en) in enumerate(pairs):
ja_emb = model.encode_query(ja)
en_emb = model.encode_document([en])[0]
score = cosine_similarity([ja_emb], [en_emb])[0][0]
print(f"[{i+1}] 「{ja}」 × 「{en}」 → 類似度: {score:.4f}")
結果はこちら
[1] 「私は猫が好きです」 × 「I like cats」 → 類似度: 0.8012
[2] 「今日は暑いですね」 × 「It's hot today」 → 類似度: 0.6403
[3] 「明日会議があります」 × 「I have a meeting tomorrow」 → 類似度: 0.5921
[4] 「私はPythonが得意です」 × 「Bananas are delicious」 → 類似度: 0.4168適切なものが類似度高くなっているのがわかります。
次に多言語のニュース記事のクラスタリングです。
サンプルコードはこちら
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# モデルのロード
model = SentenceTransformer("google/embeddinggemma-300m")
# 多言語ニュース文(翻訳済み見出し)
texts = [
"地震が東京を襲う", # 日本語
"Earthquake strikes Tokyo", # 英語
"东京发生地震", # 中国語
"Terremoto sacude Tokio", # スペイン語
"大谷翔平が本塁打", # 日本語
"Shohei Ohtani hits home run", # 英語
"Shohei Ohtani conecta jonrón", # スペイン語
]
# 埋め込み取得
embeddings = model.encode(texts)
# クラスタリング
kmeans = KMeans(n_clusters=2, random_state=0).fit(embeddings)
# 結果表示
for i, text in enumerate(texts):
print(f"[{kmeans.labels_[i]}] {text}")結果はこちら
[0] 地震が東京を襲う
[0] Earthquake strikes Tokyo
[0] 东京发生地震
[0] Terremoto sacude Tokio
[1] 大谷翔平が本塁打
[1] Shohei Ohtani hits home run
[1] Shohei Ohtani conecta jonrón地震に関するニュースが[0]、大谷選手のニュースが[1]にクラスタリングされていることがわかります。
最後にクエリに対してFAQから最適な回答を選ぶです。
サンプルコードはこちら
faq = [
"配送には何日かかりますか?",
"返品は可能ですか?",
"支払い方法には何がありますか?",
"注文のキャンセルはできますか?",
]
query = "クレジットカードで払えますか?"
faq_embed = model.encode_document(faq)
query_embed = model.encode_query(query)
sims = cosine_similarity([query_embed], faq_embed)[0]
best_idx = sims.argmax()
print(f"質問: {query}")
print(f"最も近いFAQ: {faq[best_idx]} (類似度: {sims[best_idx]:.4f})")結果はこちら
質問: クレジットカードで払えますか?
最も近いFAQ: 支払い方法には何がありますか? (類似度: 0.4794)こちらも適切な回答を得られています。また、文章の量が少ないからかもしれませんが、かなり高速でした。
なお、Microsoft初の自社モデル【MAI-Voice-1/MAI-1-preview】について詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事ではEmbeddingGemma-300mの概要から使い方、使ってみた所感についてお伝えしました。
EmbeddingGemma-300mは小型かつ高性能、そして多言語対応という3拍子揃った埋め込みモデルです。オープンライセンスで提供され、Google Colab上で手軽に試すことができるので、PoCや検証のみならず、商用アプリなどの開発にも使えそうです
ぜひ皆さんも本記事を参考にEmbeddingGemma-300mを使ってみてください!

最後に
いかがだったでしょうか?
EmbeddingGemmaを使ったRAG構築や業務活用のご相談はお気軽に。導入事例やPoC支援も無料で対応中です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


