
【Fish Speech 1.4】自然な音声と多言語対応の音声生成AI!機能と使い方、課題を徹底解説

2024年9月11日にFish Audioから最新のAIモデル「Fish Speech 1.4」が登場しました。
まるで本人が話しているかのような自然な音声生成、8言語への対応、そして感情や抑揚まで豊かに表現できるその実力。この記事では、Fish Speech 1.4の驚くべき機能や使い方、そして潜む倫理的課題について詳しく解説します。
最後までお読みいただくことで、新しい音声AIの可能性とその活用方法が見えてくるはずです。
\生成AIを活用して業務プロセスを自動化/
Fish Speech 1.4の概要
Fish Speech 1.4はFishaudioが新たにリリースした深層学習モデルをベースにした音声読み上げモデルです。このモデルの特徴は日本語を含む英語、中国語、ドイツ語、フランス語、スペイン語、韓国語、アラビア語の8言語に対応している点と超低遅延です。
また、Fish Speech 1.4は70万時間の多言語音声データでトレーニングされています。
従来のモデルとFish Speech1.4の違い
従来の音声読み上げモデルと異なるのは、Fish SpeechはVQGAN、LLAMA、VITSなどの深層学習モデルを組み合わせて使用している点です。
従来の音声読み上げモデルでは、音声の録音を繋ぎ合わせて音声を生成していましたが、Fish Speechは、深層学習モデルを用いることで、より自然で表現力豊かな音声を生成することが可能です。
Fish Speechはより多くの計算処理とトレーニングデータを必要とするため、従来のモデルに比べてより人間らしい音声読み上げが可能になっています。
VQGAN:ベクトル量子化を用いた敵対的生成ネットワーク(GAN)の一種で、画像生成に特化したモデル。ベクトル量子化を利用して画像データを離散的なトークンに変換。これにより画像の圧縮と再構成が可能です。また、GANの技術を応用して、生成器と識別器が競い合うことで、よりリアルな画像を生成。主にVQGANは画像生成に用いられる技術ですが、Fish speechでは、VQGANを用いて音声を離散的な表現に変換、それをLLAMAなどの言語モデルで処理することで、高品質な音声合成を実現しています。
LLAMA:LLAMAはMetaが開発した大規模言語モデルです。LLAMAは自然言語処理の分野で使用されており、対話型AIの基盤技術として研究者向けにオープンソースで提供されています。トレーニングには1.4兆個のトークンを使用し、コモン・クロールやGitHub、ウィキペディアなどからデータを収集しています。Fish Speechでは、離散的に表現された音声を処理し、音声合成を行うのに使用されています。
VITS:音声合成技術の一つで、深層学習を活用してテキストから自然な音声を生成するモデルです。従来の音声合成モデルが持ついくつかの問題を解決するために設計されています。2024年には、確率的時長予測器の導入により、単一のテキスト入力から多様なリズムの音声を生成できるようになり、合成音声の自然さと表現力が向上。また大規模言語モデルとの統合により、テキストの意味的内容が強化され、合成された音声の自然さと感情表現が改善しています。
Fish Speech 1.4のライセンス
Fish Speech 1.4のライセンスはCreative Commons Attribution-NonCommercial-ShareAlike 4.0 Internationalに基づいています。
そのため、商用利用は不可で、もし営利目的で使用する場合には、別途ライセンサーから許可を得る必要があります。非営利目的であれば、個人使用や私的利用は可能です。
改変は可能ですが、改変して配布する場合には、改変されたものにも同じ「CC BY-NC-SA4.0」ライセンスを適用する必要があるので注意してください。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ❌ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ❌ |
| 私的使用 | ⭕️ |
なお、47秒×44.1kHzサウンドエフェクトを生成できるStable Audio Openについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Fish Speech 1.4の使い方
Fish Speech 1.4はオンラインデモが用意されているので、ローカル環境で準備ができなくても利用できます。
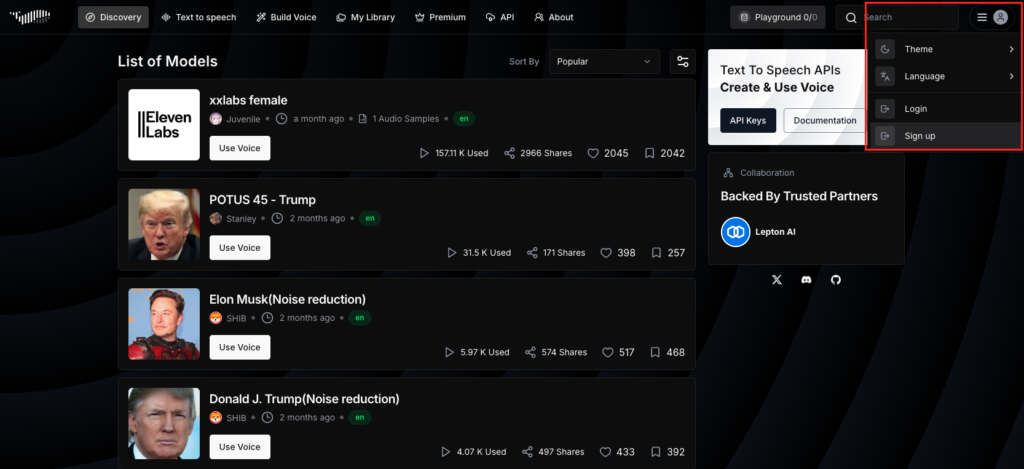
デモページに移ったら、まずはサインアップをする必要があります。
画面右上の人型をクリックすると「login」と「sign up」が出てきます。この時初めてアクセスするユーザーも「login」をクリックしましょう。
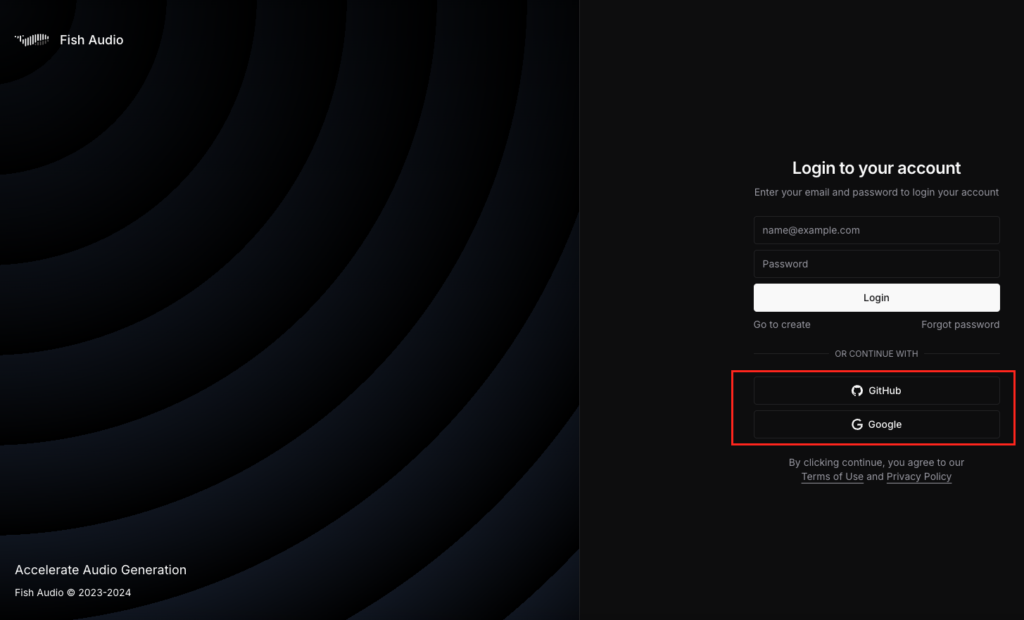
そうすると、loginページでGoogleアカウントもしくはGitHubアカウントでログインができます。
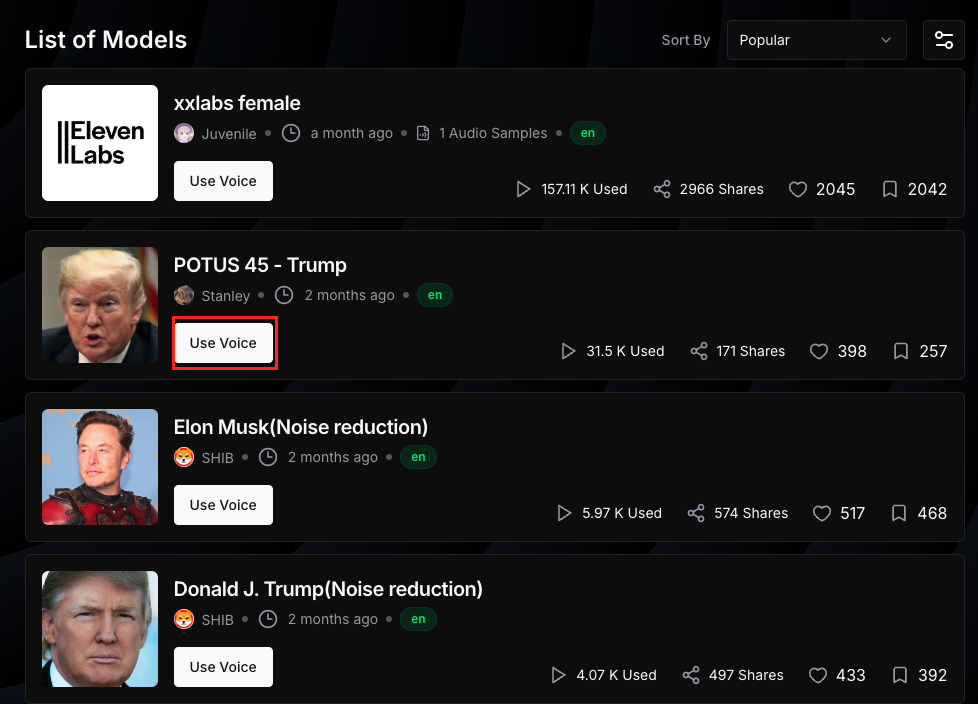
ログインができたら、使用したい人物の音声を選択しましょう。「Use Voice」を選択すればOKです。
あとはYour Textと書かれている部分に読み上げてほしい内容を入力するだけです。
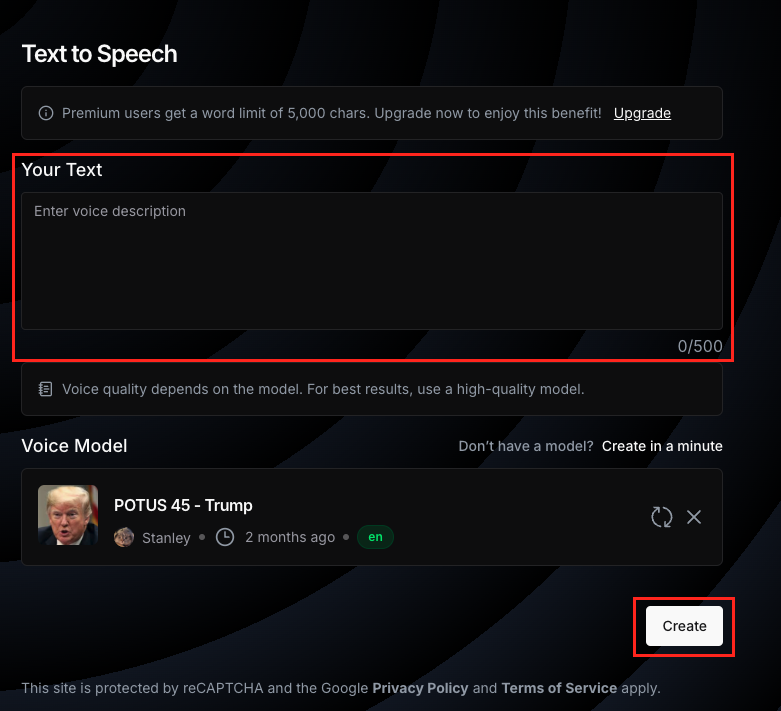
生成後は画面向かって右側に生成されたものが表示されているので、そちらを再生すればOKです。音量が結構大きいので注意が必要です。
Fish SpeechをGoogle Colaboratoryで実装する方法
Fish SpeechはGoogle Colaboratoryでも実装が可能で、WindowsとLinux用のコードはGitHubに用意されています。
ただ、筆者がMacを使っているせいかわかりませんが、ipynbファイルにおいて、GitHubのサンプルコードだとエラーになってしまいます。可能な限り修正しながら実装をしていきたいと思います。
Fish Speechを実行した時の環境は以下です。Google Colaboratoryで実装する場合にはランタイムをGPUに変更する必要があります。
Fish Speechの実行ではあまりGPUを使わないため、無料プランでも十分利用できます。
■Pythonのバージョン
Python 3.10以上
■使用ディスク量
35.7GB
■GPU RAMの使用量
1.8GB
■システムRAMの使用量
4.4GB
ロケールの設定はこちら
import locale
locale.setlocale(locale.LC_ALL, 'en_US.UTF-8')モデルのダウンロードはこちら
!huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4リポジトリのクローンはこちら
!git clone https://github.com/fishaudio/fish-speech.git必要ライブラリのインストールはこちら
!pip install -r /content/fish-speech/docs/requirements.txt不足ライブラリのインストールはこちら
!pip install numpy==1.26.4 transformers>=4.35.2 datasets==2.18.0 lightning>=2.1.0 hydra-core>=1.3.2 tensorboard>=2.14.1 natsort>=8.4.0 einops>=0.7.0 librosa>=0.10.1 rich>=13.5.3 gradio>=4.0.0 wandb>=0.15.11 grpcio>=1.58.0 kui>=1.6.0 uvicorn>=0.30.0 loguru>=0.6.0 loralib>=0.1.2 pyrootutils>=1.0.4 vector_quantize_pytorch>=1.14.24 resampy>=0.4.3 einx[torch]==0.2.2 zstandard>=0.22.0 pydub faster_whisper modelscope==1.17.1 funasr==1.1.5 opencc-python-reimplemented==0.1.7 silero-vad ormsgpack fsspec==2024.6.1
!pip install --upgrade datasets
!pip install tritonwebUIの実行はこちら
!python fish-speech/tools/webui.py \
--llama-checkpoint-path /content/checkpoints/fish-speech-1.4 \
--decoder-checkpoint-path /content/checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth \
--compile上記のコードを使えばGoogle ColaboratoryでFish Speechを使うことができますが、Google Colaboratoryでgradioを使う際には、ローカルURLにアクセスできるようにする必要があります。
そのため、webui.pyの一番最後に、share=Trueを追加する必要があります。share=Trueを追加して、WebUIのコードを実行すると、URLが2つ出てきます。
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://7369aca89cfd6f2317.gradio.live
Running on public URLにアクセスすると以下のような画面が表示され、GradioでFish Speechを使うことができます。
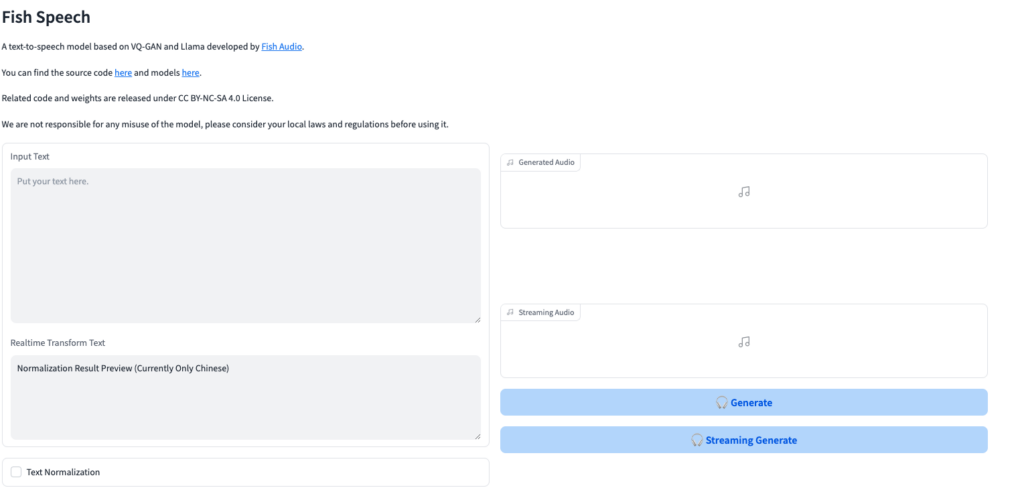
gradioの画面でInput Textに読み上げてもらいたいテキストを入力します。
その後、Streaming Generateをクリックすることで、入力したテキストの読み上げを聞くことができます。
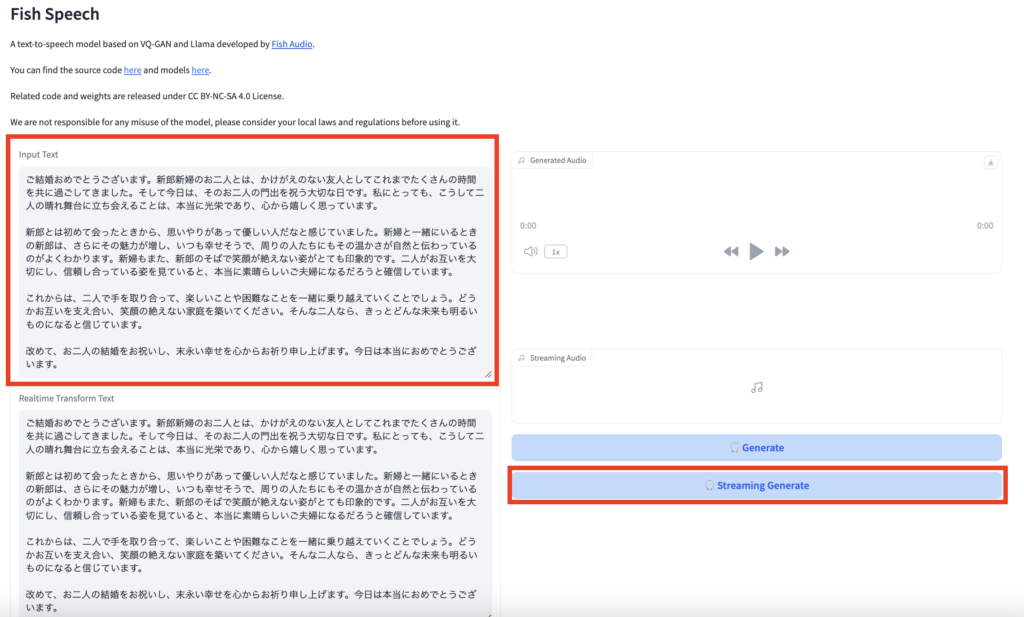
日本語だと音読み・訓読みが怪しい部分がありますが、それ以外はかなり自然な音声読み上げになっています。
ONE PIECEよりサンジとルフィのセリフを読み上げてもらった
Fish Speechはいろんな人物の声でテキストを読み上げることができます。
そこで、本記事の検証では、名台詞をいろんな人にしゃべってもらおうと思います。今回用意したセリフはこちら。
「誰にでもできる事とできねェ事がある お前にできねェ事はおれがやる おれにできねェ事をお前がやれ!!!」
「おれは助けてもらわねェと 生きていけねェ自信がある!!!」
ONE PIECEよりサンジとルフィのセリフをドナルド・トランプとブリトニースピアーズの声でそれぞれ読み上げてもらいます。
まずはドナルド・トランプでサンジのセリフです。
次にブリトニースピアーズでサンジのセリフです。
次はドナルド・トランプでルフィのセリフです。
最後にブリトニースピアーズでルフィのセリフです。
外国人が日本語を話しているかのようなリアリティがありますね。では、外国人に英語を喋ってもらうとどうなるのでしょうか。
イーロンマスクに次のセリフを喋ってもらいます。
英文:The time is always right to do what is right.
和訳:正しいことをするのに、時を選ぶ必要などない。
さらにこちらも喋ってもらいましょう。
英文:That’s one small step for [a] man, one giant leap for mankind.
和訳:これは一人の人間にとっては小さな一歩だが、人類にとっては偉大な跳躍である。
かなり自然な音声読み上げになりました。機械っぽさがないので、Fish Speechを電話越しなどで使われたら、まるで本人が喋っているような気になってしまいますね。
現在のオンラインデモではまだ日本人モデルが少ないので、日本人で試すことはできませんが、ローカル環境で音声をアップロードすることで、日本人の音声でテキストを読み上げることもできます。
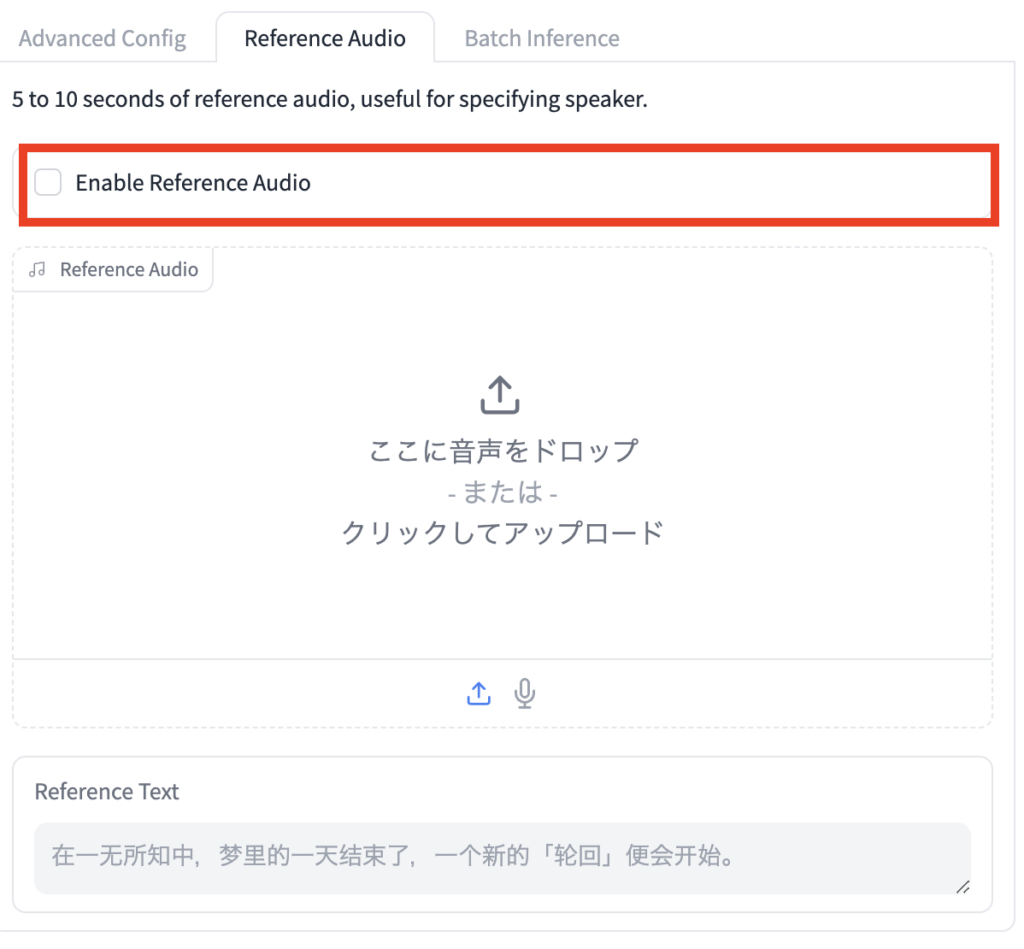
Gradioにアクセスして、ページ下にスクロールし、「Reference Audio」があるので、そのタブをクリック
下の画像のように表示されるので、ここに音声ファイルをドラッグ&ドロップします。
あとは「Enable Reference Audio」にチェックを入れて、読み上げてほしいテキストを入力して、Streaming GenerateをクリックすればOKです。
なお、まるで人間が喋っているようなオープンソースのTTSモデルのParler TTSについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

ディープフェイクと音声なりすましへの懸念
高度なTTSであるFish Speech 1.4は、まるで本人が話しているかのような自然な音声を生成できましたが、その一方でディープフェイクやなりすましといった倫理的な問題にも注意が必要です。
例えば、この技術を悪用して他人になりすまし、詐欺や情報操作を行う可能性があります。また、本人の許可なく音声を模倣することはプライバシーの侵害や著作権の問題を引き起こす恐れがあります。
ディープフェイクや音声なりすましへの対策
ブロックチェーン
デジタルコンテンツの作成日時や変更履歴を不変の記録としてブロックチェーン上に保存することで、コンテンツの真正性を証明できます。これにより、偽造された音声や映像がオリジナルでないことを確認でき、ディープフェイクの識別に役立ちます。
C2PA
Coalition for Content Provenance and Authenticity(C2PA)は、コンテンツの出所と真正性を保証するための技術標準を策定しています。これにより、デジタルコンテンツにメタデータを埋め込み、ユーザーやプラットフォームがコンテンツの信頼性を判断しやすくします。ディープフェイクによる偽情報の拡散を防ぐ重要な取り組みです。
AI音声技術は多くの可能性を秘めていますが、その利便性を享受するためには倫理的な課題にも目を向ける必要があります。技術の進歩とともに、私たち一人ひとりが適切な利用と慎重な対応を心がけることで、AI技術の恩恵を最大限に活用できるでしょう。
なお、ディープフェイクについて詳しく知りたい方は以下からご覧ください。

Fish Speech 1.4の未来と活用の可能性
Fish Speech 1.4は、8言語への対応や感情・抑揚の豊かな表現力を持ち、まるで本人が話しているかのような自然な音声生成を実現しています。VQGAN、LLAMA、VITSといった先進的な深層学習モデルを組み合わせることで、従来のモデルを大きく超える性能を発揮しています。
しかし、その高度な機能ゆえに、ディープフェイクやなりすましといった懸念も浮上しています。ブロックチェーン技術やC2PAの取り組みなど、信頼性と安全性を確保するための対策が求められています。
今後の展望としては、以下の点が期待されます。
- さらなる音声品質の向上: 技術の進歩により、より自然で多様な音声表現が可能になる。
- 日本語モデルの充実: 日本人モデルの拡充により、日本語ユーザーの利便性が高る。
- 商用利用への道筋: ライセンスや倫理的課題の解決により、ビジネス分野での活用が進む。
- セキュリティ対策の強化: ディープフェイク対策技術の発展により、安全で信頼性の高い音声生成AIが実現。
Fish Speech 1.4のポテンシャルを最大限に活用するためには、技術的な進歩だけでなく、倫理的な配慮と適切な対策が不可欠です。今後もこの分野の発展から目が離せません。ぜひ一度試してみて、その可能性を体感してみてください。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

