
【Stable Audio Open】47秒×44.1kHzサウンドエフェクトを生成!
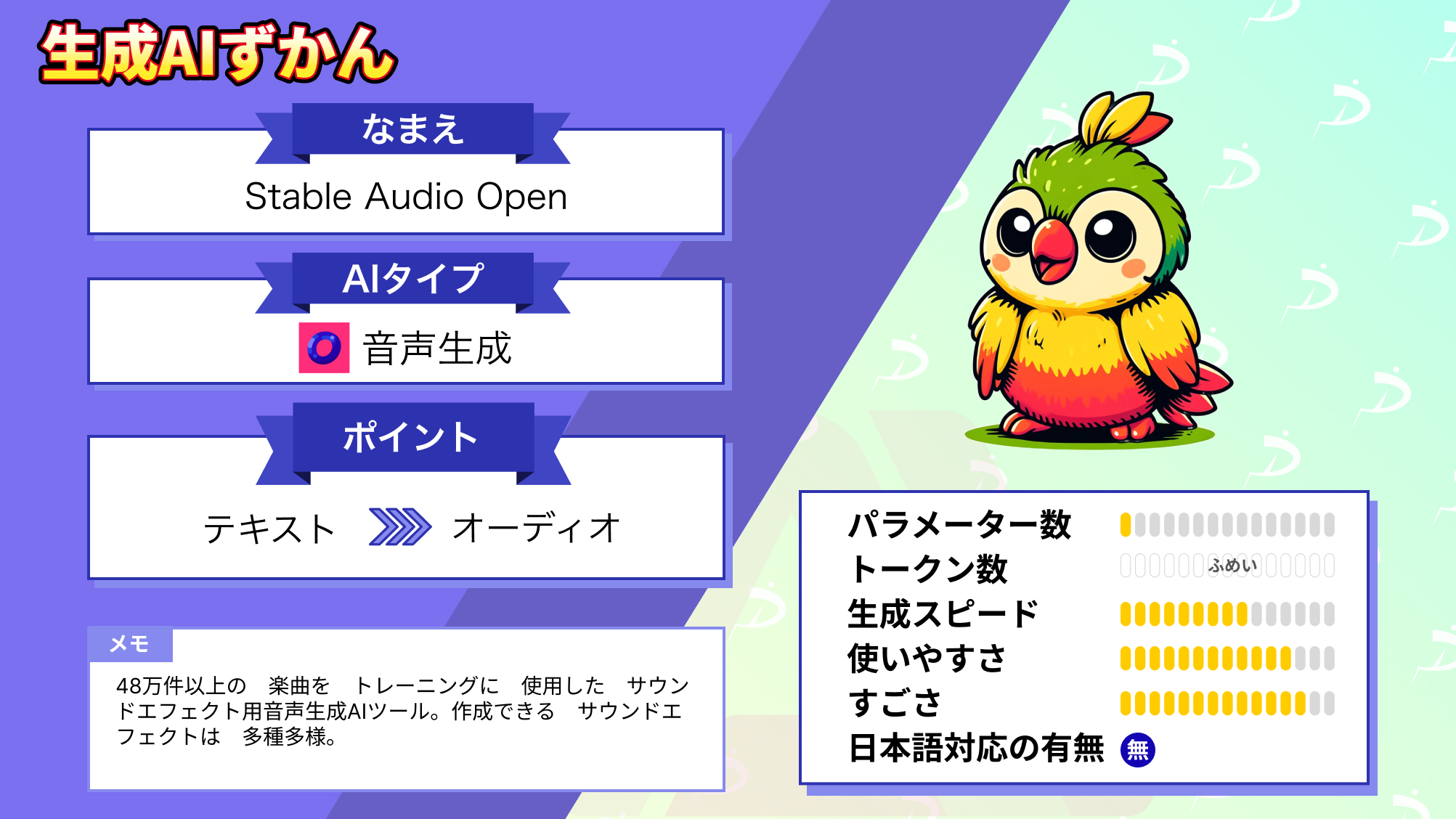
2024年6月5日、ついにStability AIからサウンドエフェクト用の音声生成AI「Stable Audio Open」が発表されました!
Stable Audio Openはテキストから最長47秒のオーディオを生成できる画期的なAIツールです。Stability AIといえばこれまでは「Stable Diffusion」で多くの人をAIの虜にしてきましたが、今回のStable Audio Openはミュージシャンや音楽愛好家、開発者など音楽に関わる多くの人々に新たな創造の可能性を提供してくれます。
Stable Audio Openを発表したX(旧Twitter)の投稿は23.7万回表示、1000件を超えるいいね、500件近くがブックマークされており、非常に多くの人々の関心を集めています。
この記事では、Stable Audio Openをgoogle colaboratoryで使用する方法を画像を交えて解説し、実際の使用感をお伝えします。
本記事を最後まで読むことで、google colaboratoryを使ってテキストからオーディオを生成できますので、ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Stable Audio Openの概要
Stable Audio OpenはStable Diffusionを開発した「Stability AI」が開発したテキスト to オーディオの生成AIツールです。
Stable Audio Openを使うことで、最長47秒のオーディオをテキストから生成可能で、これまで以上に楽曲作成のハードルが下がりより多くの人たちがクリエイティブな活動に参加できます。
また、Stable Audio Openはサウンドエフェクトを作成するために最適化されたモデルであり、以前発表されたStable Audioと同様の機能ではありません。
Stable Audioは44.1kHzステレオの最大3分間の音楽を生成可能なのに対して、Stable Audio Openは44.1kHzステレオの最長47秒のサウンドを生成し、音響制作に必要な要素に特化しています。
さらに、Stable Audio Openはフリーサウンドから47万件以上、フリーミュージックアーカイブから1万3000件、計48万件以上の音声データを活用してトレーニングされているため、多種多様なサウンドエフェクトを作成可能です。
音声生成AIツール
Stable Audio Openが発表されるまでにもいくつかの音声生成AIツールがリリースされています。
代表的な音声生成AIツールとして、sunoがあります。sunoはユーザーがテキスト入力した歌詞でヴォーカルまで生成してくれる音声生成AIツール。sunoを使うことで、日本語の楽曲も生成できます。
なお、音声生成AIツールsunoについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
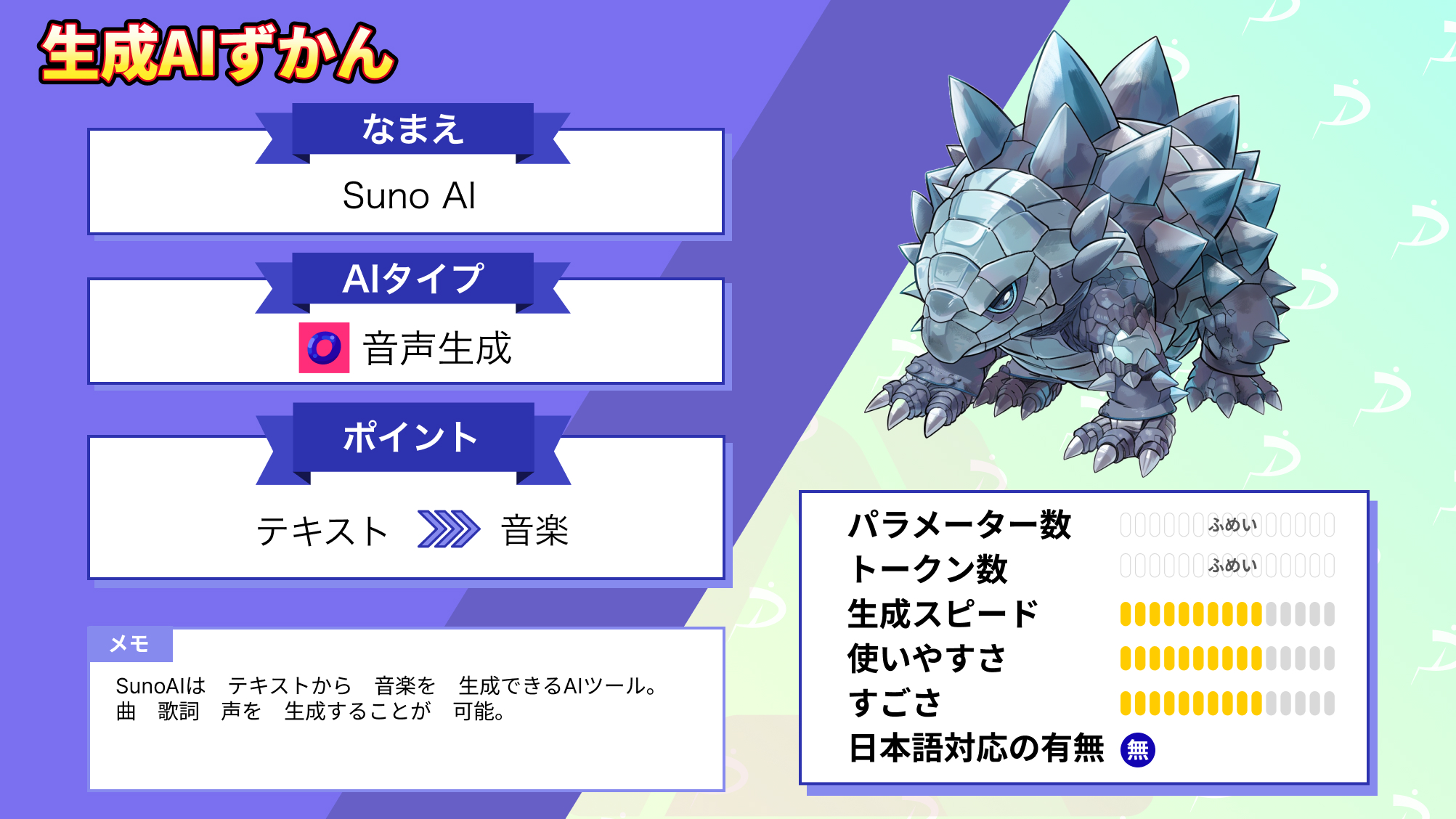
suno以外にもUdioも音声生成AIツールで、こちらは無料で1200曲作ることができます。Udioは音質がよくヴォーカルの生っぽさを表現できるようになっており、J-popなどの日本の音楽スタイルを指定することも可能です。
Stable Audio Openのライセンス
Stable Audio OpenのライセンスはStable AI Non-Commertioal Research Community Licenseです。
基本的には商用利用不可ですが、メンバーシップに加入もしくはStability AIから商用ライセンスを取得している場合には商用利用が可能です。
また、改変や配布、私的利用についても非商用利用の範囲内で許可されています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ❌ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | 不明(記載なし) |
| 私的使用 | ⭕️ |
Stable Audio Openの商用利用
Stable Audio Openを商用利用する場合には、Stability AIのメンバーシップに加入する必要があります。
Stability AIのメンバーシップは3つに分けられており、次の表の通りです。
| Non-Commercial | Professional | Enterprise | |
|---|---|---|---|
| 費用 | 無料 | 20ドル/月 | カスタム価格 |
| 用途 | 個人利用・研究用 | 年間収益100万ドル未満のクリエイターおよび開発者 | 大規模企業向け |
| 商用利用 | 不可 | 可 | 可 |
なお、Stability AIがリリースしている画像生成AIについて、詳しく知りたい方は下記の記事を合わせてご確認ください。

Stable Audio Openの使い方
ここからは実際にgoogle colaboratoryを使用して、Stable Audio Openを使用します。
Stable Audio Openを動かすのに必要な動作環境
Stable Audio Openを実装した際のgoogle colaboratoryの動作環境情報です。実装する際には、GPUを使用した方が高速なので、google colaboratoryの画面から「ランタイム」→「ランタイムのタイプを変更」→「T4 GPU」を選択しておきましょう。
■Pythonのバージョン:Python 3.8以上
■使用ディスク量:35.8GB
■システムRAMの使用量:7.3GB
■GPU RAMの使用量:12.9GB
HuggingFaceの登録
Stable Audio Openを使用するにはHuggingFaceに登録をして、トークン設定をする必要があります。
Stable Audio OpenのHuggingFaceにアクセスした際に、以下の画像のように表示されている場合にはサインアップもしくはログインをしましょう。
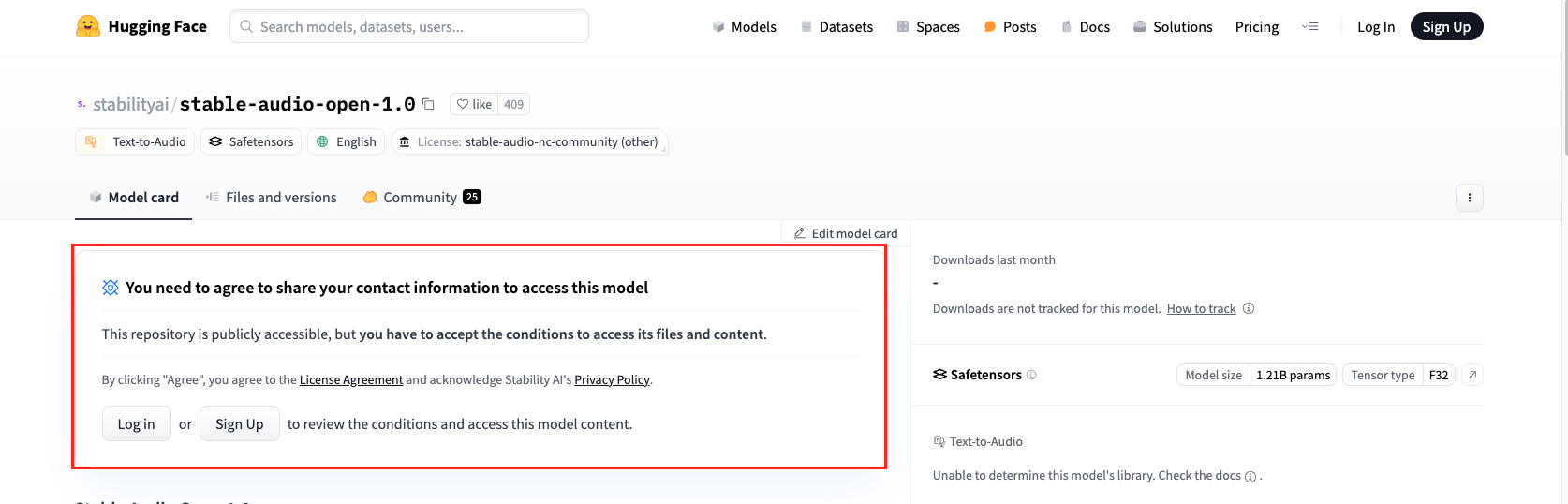
ログインすることで、上記赤枠がなくなり、Stable Audio Openを使うために氏名・組織名などの入力画面が表示されるのでそれらを入力することでStable Audio Openを使えます。
HuggingFaceのトークン設定
HuggingFaceにログインしたら、トークン設定を行います。
画面右上のアカウントボタンをクリックして、「Settings」を選択。
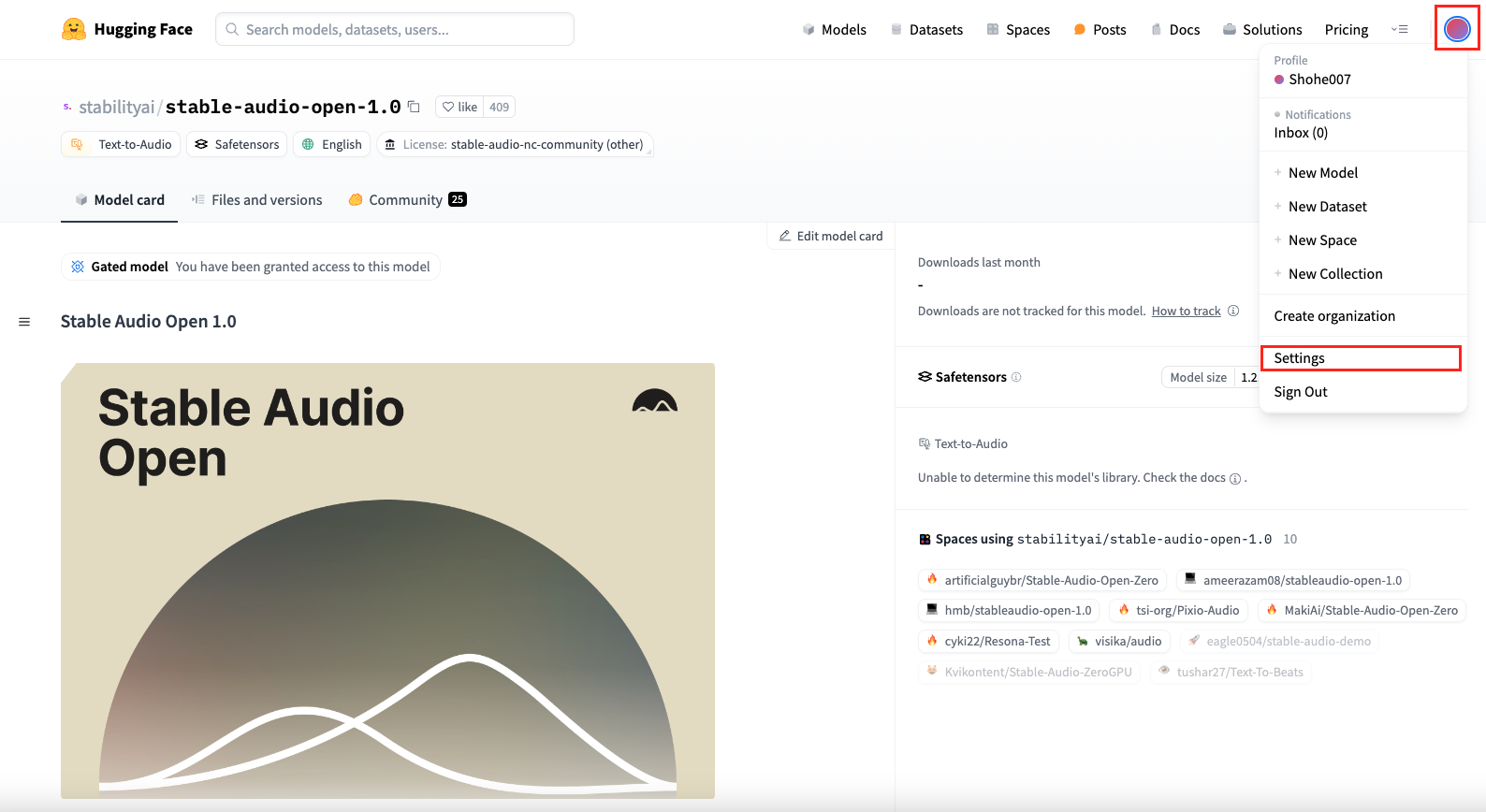
「Access Tokens」をクリック。
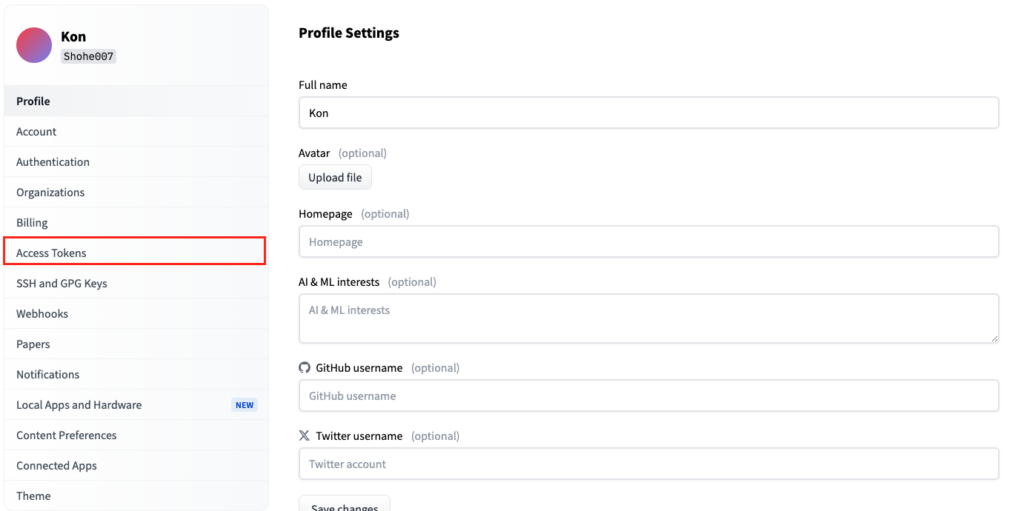
「New token」をクリックして、トークン名を入力、タイプは「read」を選択して「Generate token」をクリックすると、トークンを設定できます。
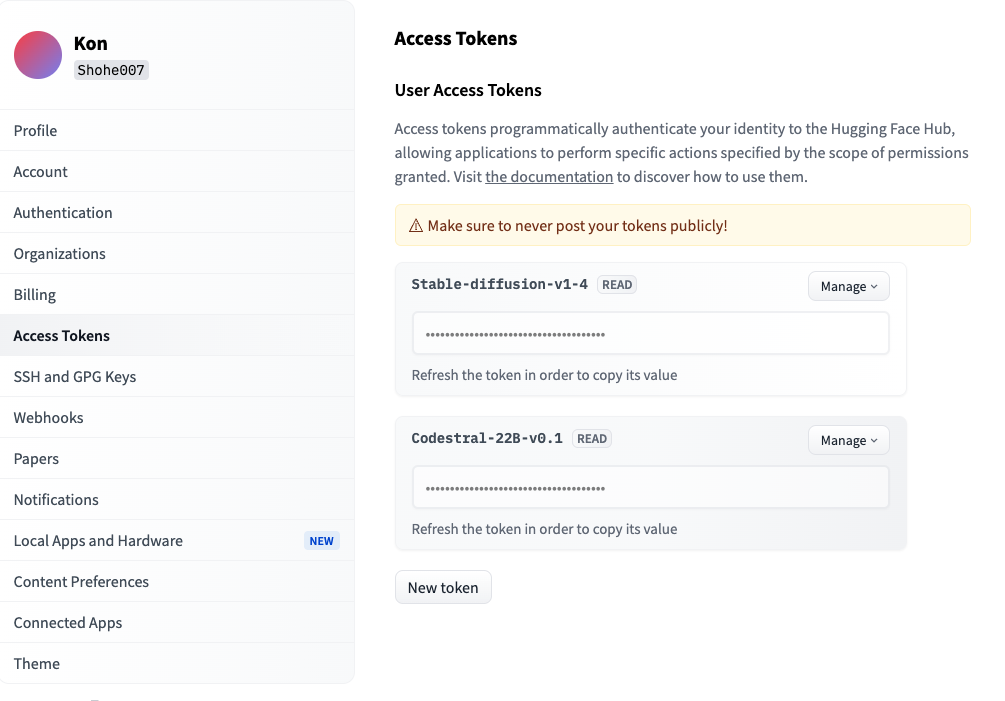
作成されたトークンはこの時しかコピペをすることができないため、忘れずにコピペをしておきましょう。万が一コピペし忘れた場合には、新たにトークンを設定する必要があります。
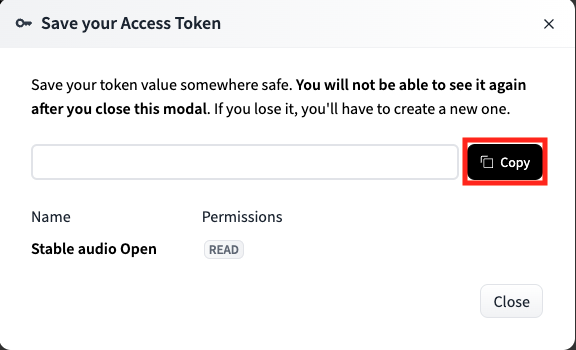
これでStable Audio Openを使用する準備ができました。次からは実際にgoogle colaboratoryで実装します。
Stable Audio Openをgoogle colaboratoryで実装
まずは必要なライブラリをインストールします。
必要ライブラリのインストールコードはこちら
# 必要なライブラリのインストール
!pip install transformers soundfile huggingface_hub
!pip install stable-audio-toolsこのインストールには少し時間がかかるので、気長に待ちましょう。私が実際に実行した時には3分くらいかかりました。インストールが全て完了するとセッションの再起動を求められるので、再起動を行います。
全てのインストールが完了したら、先ほどコピペしたHuggingFaceのトークンを設定します。
HuggingFaceのトークン入力コードはこちら
from huggingface_hub import login
login()上記のコードを実行すると、以下の画像が表示されるのでTokenと書かれているところに、ペーストします。「Add token as git credential?」のチェックは外しておいて大丈夫です。
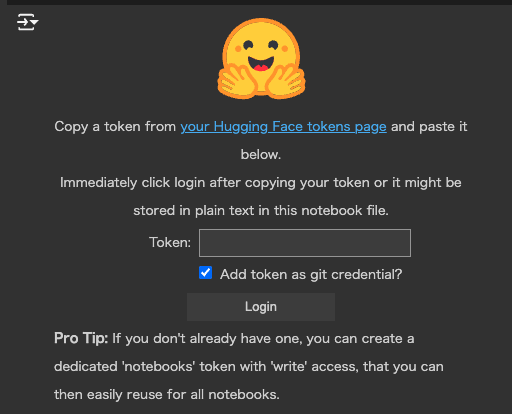
これで準備完了なので、実際にサウンドエフェクトを生成します。
Stable Audio Openのコードはこちら
import torch
import torchaudio
from einops import rearrange
from stable_audio_tools import get_pretrained_model
from stable_audio_tools.inference.generation import generate_diffusion_cond
device = "cuda" if torch.cuda.is_available() else "cpu"
# Download model
model, model_config = get_pretrained_model("stabilityai/stable-audio-open-1.0")
sample_rate = model_config["sample_rate"]
sample_size = model_config["sample_size"]
model = model.to(device)
# Set up text and timing conditioning
conditioning = [{
"prompt": "128 BPM tech house drum loop",
"seconds_start": 0,
"seconds_total": 30
}]
# Generate stereo audio
output = generate_diffusion_cond(
model,
steps=100,
cfg_scale=7,
conditioning=conditioning,
sample_size=sample_size,
sigma_min=0.3,
sigma_max=500,
sampler_type="dpmpp-3m-sde",
device=device
)
# Rearrange audio batch to a single sequence
output = rearrange(output, "b d n -> d (b n)")
# Peak normalize, clip, convert to int16, and save to file
output = output.to(torch.float32).div(torch.max(torch.abs(output))).clamp(-1, 1).mul(32767).to(torch.int16).cpu()
torchaudio.save("output.wav", output, sample_rate)今回作成したサウンドエフェクトはgoogle colaboratoryのファイルに保存されるようになっています。必要に応じてダウンロードしてください。
Stable Audio Openは多様なサウンドエフェクトを作成できるのか?
Stable Audio Openは多くのサウンドをトレーニングに使用していることから、多種多様なサウンドエフェクトを作成できます。ここでは実際にプロンプトを調整しつつ、どのようなサウンドエフェクトが作られるのかを検証します。
実行するコードはこちら
import torch
import torchaudio
from einops import rearrange
from stable_audio_tools import get_pretrained_model
from stable_audio_tools.inference.generation import generate_diffusion_cond
device = "cuda" if torch.cuda.is_available() else "cpu"
# モデルのダウンロード
model, model_config = get_pretrained_model("stabilityai/stable-audio-open-1.0")
sample_rate = model_config["sample_rate"]
sample_size = model_config["sample_size"]
model = model.to(device)
# プロンプトのリストを作成
prompts = [
"128 BPM tech house drum loop",
"calm ambient music with nature sounds",
"heavy metal guitar riff",
"ocean waves crashing",
"birdsong in a forest",
"sci-fi spaceship engine hum",
"thunderstorm with rain",
]
# 各プロンプトでサウンドを生成
for i, prompt in enumerate(prompts):
# コンディショニングの設定
conditioning = [{
"prompt": prompt,
"seconds_start": 0,
"seconds_total": 30
}]
# ステレオオーディオの生成
output = generate_diffusion_cond(
model,
steps=100,
cfg_scale=7,
conditioning=conditioning,
sample_size=sample_size,
sigma_min=0.3,
sigma_max=500,
sampler_type="dpmpp-3m-sde",
device=device
)
# オーディオバッチを単一シーケンスに再配置
output = rearrange(output, "b d n -> d (b n)")
# ピークノーマライズ、クリップ、int16に変換し、ファイルに保存
output = output.to(torch.float32).div(torch.max(torch.abs(output))).clamp(-1, 1).mul(32767).to(torch.int16).cpu()
file_name = f"output_{i}.wav"
torchaudio.save(file_name, output, sample_rate)
print(f"Generated and saved: {file_name}")
# すべてのファイルをダウンロード可能にする
from google.colab import files
for i in range(len(prompts)):
files.download(f"output_{i}.wav")
上記のコードではプロンプトをリストとして保持しておき、for文で一気にサウンドエフェクトを作成、保存。
サウンドエフェクトの作成が完了したら、実際に聴き比べてみるとプロンプト1文でかなり変化することがわかります。
プロンプト以外にも調整できるパラメータがあり、それぞれを調整することでまた変わったサウンドエフェクトを作成可能です。
例えば、step数を変更することでより高品質のサウンドエフェクトが作成される可能性がありますが、その分生成時間がかかります。現在のstep数は100になっていますが、調整することで異なるサウンドを作成できます。
また、現在のコンディショニング強度は「cfg_scale=7」になっていますが、強度を上げたり下げたりしてすることでどのようにサウンドが変化するかを楽しんでみてください。
step数とコンディショニング強度を変更したコードはこちら
# 各プロンプトでサウンドを生成
for i, prompt in enumerate(prompts):
# コンディショニングの設定
conditioning = [{
"prompt": prompt,
"seconds_start": 0,
"seconds_total": 30
}]
# ステレオオーディオの生成
output = generate_diffusion_cond(
model,
steps=200,
cfg_scale=10,
conditioning=conditioning,
sample_size=sample_size,
sigma_min=0.3,
sigma_max=500,
sampler_type="dpmpp-3m-sde",
device=device
)実際にStable Audio Openでサウンドエフェクトを作成してみましたが、プロンプトやstep数の調整などによって多種多様なサウンドを作成できることがわかりました。効果音を手早く複数作成したい場合などには、強力なAIツールになりえます。
Stable Audio Openを元に動画作成
また、Stable Audio Openを使えば全てをAIツールで完結できる動画を作成可能です。
Stable Audio Openでサウンドエフェクトを作成し、サウンドエフェクトを作成するのに使用したプロンプトに一致する画像をDALL-E3で作成します。
その次に、作成した画像をRunWay gen-2で動かして、動画編集ソフトで作成したサウンドエフェクトとRunWay gen-2で作成した画像を組み合わせることでサウンドエフェクト付きの動画を作成できます。
完成した動画はこちら
このような動画を誰でも簡単に作成できるようになるので、生成AIツールを使ったクリエイティブな活動は今後ますます盛んになりそうですね!
なお、画像生成AIツールDALL-E3について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事では、Stable Audio Openをgoogle colaboratoryで使用する方法についてお伝えをしました。google colaboratoryを使用することで、自身のパソコンにGPUが搭載されていなくても、手軽に生成AIツールを活用できます。
これまでも楽曲制作の生成AIツールはありましたが、サウンドエフェクトに特化した生成AIツールはありませんでした。Stable Audio OpenとStable OpenやUdio、sunoなどを組み合わせて使うことで、これまでにない楽曲を生成できるかもしれませんね。
ぜひStable Audio Openを使ってサウンドエフェクトを生成してみてください。
最後に
いかがだったでしょうか?
ChatGPTやStable Diffusionなど使い勝手の良いAIサービスは沢山あります。1度使ってみて、もっとこうしたい、こう言った使い方をしたいと言った方に向けてカスタマイズを勧めております。
もし、自社で生成AIを活用したいという場合は
1. 汎用的な生成AIツールを導入し、定着させる
2. 業務を生成AIに解けるタスクまで分解し、自動化する
のどちらかが良いと思います。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

