
【Fuyu-8B】超小型なのにGPT-4Vと同じ性能を持つマルチモーダルAI

みなさん、有料版のChatGPTが画像入力に対応したGPT-4Vはご存知ですよね?
ですが、それよりもすごいAIが登場しています!名は「Fuyu-8B」という、GPT-4比で180分の1程度のパラメーターしかもたないマルチモーダルAIです。
このFuyu-8Bは小型にも関わらず、フローチャートやグラフを理解してくれます。しかもモデル自体は無料で配布されているのです。
当記事ではFuyu-8Bのしくみ・性能・使い方を実践付きで紹介していきます。
Pythonコードで実際にマルチモーダルAIを動かしてみたい方は必読です。ぜひ、最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Fuyu-8Bの概要
Fuyu-8BはAdept AIがリリースする(ライセンスはCC-BY-NC)マルチモーダルAIです。パラメーター数にして80億と小型で、テキスト・画像間の変換に特化しているのが特徴です。
そんなFuyu-8Bには「山椒は小粒でもぴりりと辛い」という言葉が似合うような、すごいところが3つあります。次でみていきましょう!
Fuyu-8Bの強みは以下の3つになります。
シンプル:モデルのしくみ&学習の手順が単純で、容易に理解ができます。したがって拡張がしやすく、Few-Shotやファインチューニング次第で自分好みにカスタマイズできるのも強みです。
専門的な画像にも対応:フローチャート・グラフ・UIなど、専門性の高い画像でも処理してくれます。画像の解像度を選ばないのも強みです。
高速回答が可能:大きな画像でも100ミリ秒以内で回答が返せます。
Fuyu-8Bで以上の強みを実現するにあたって、画像の入力部分に工夫がなされています。次の項目でその原理をみていきましょう。
Fuyu-8Bの仕組み
Fuyu-8Bはなんと、画像も文字も同じ方法で処理します。まずはFuyu-8Bのしくみを表した以下の図をご覧ください。
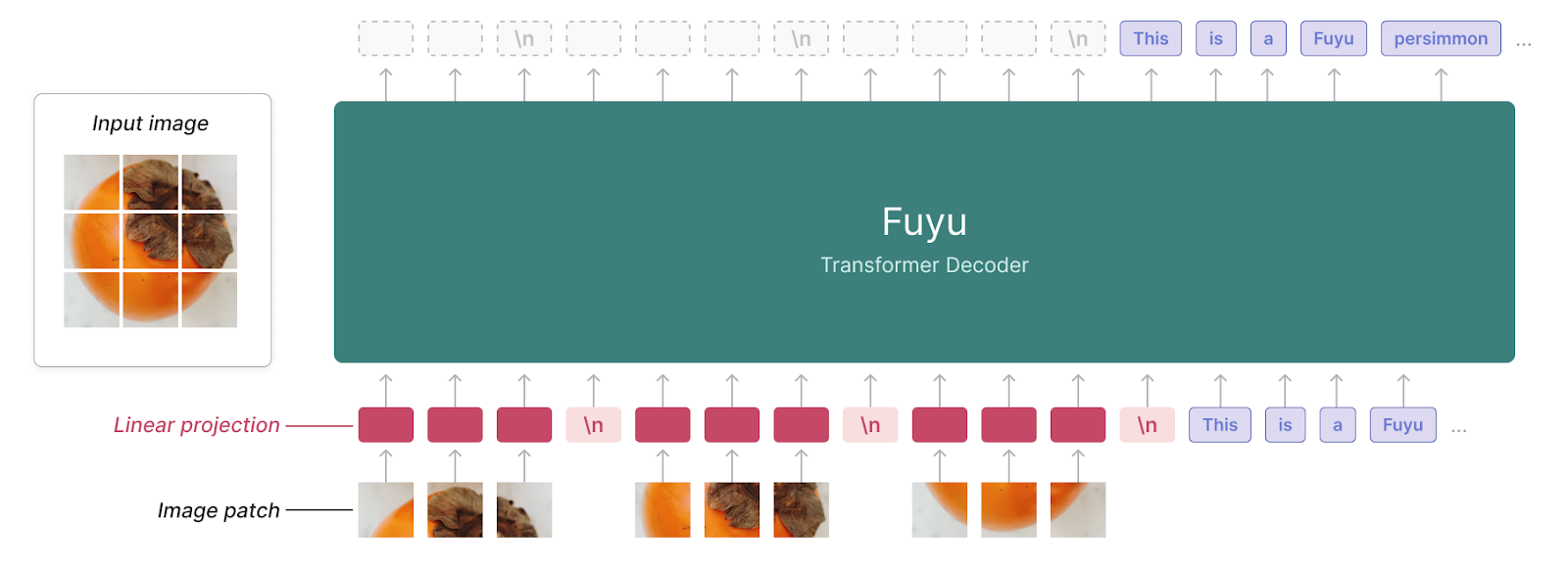
引用:adept/fuyu-8b · Hugging Face
この図ではFuyu-8Bに柿の画像を入力しています。すると柿の画像は小分けの断片にされて単純化(Linear projection)されます。これで画像は行列(図では3×3)になりました。
あとは英単語と同じで、各列の断片が左から順にデコーダー(生成を行う部分)へと入力されて、列の右端で改行を受けます。次列以降の入力も同様です。
この入力機構の採用によって、Fuyu-8Bはデコーダーのみという極めて単純なモデルとなりました。
加えて高解像度の画像であっても、長文同様の処理を実現。画像の学習時には、低画質→高画質といった、ステージ分けが不要です。
Fuyu-8Bの性能
Fuyu-8Bはバニラ(ファインチューニングなし)の状態でも、しっかり画像を識別してくれます。ここからはFuyu-8Bの実力をみていきましょう。
まず下のバースデーケーキの画像を、バニラのFuyu-8Bに提示すると……
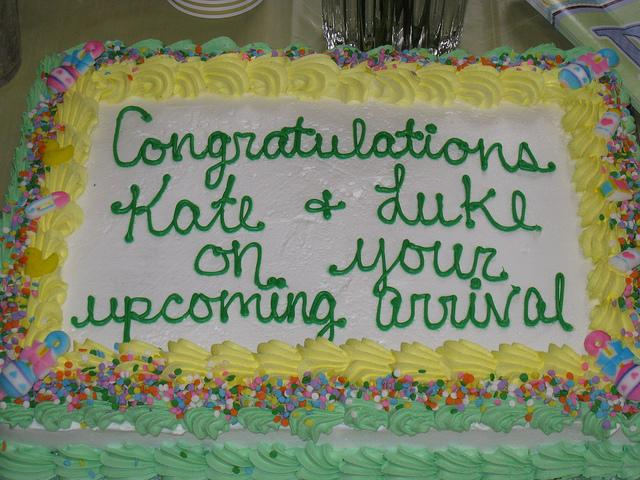
引用:Fuyu-8B: A Multimodal Architecture for AI Agents
Fuyu-8Bの回答
A cake with writing on it that says congratulations kate and luke on your upcoming arrival.
(和訳:ケーキにはこう書かれている。おめでとう、ケイトとルーク。)このようにFuyu-8Bは画像がケーキであるということ、そしてケーキ上の文言を理解してくれました!
またFuyu-8Bに男女の平均余命の変動を示したグラフを与えて、質問してみたところ……
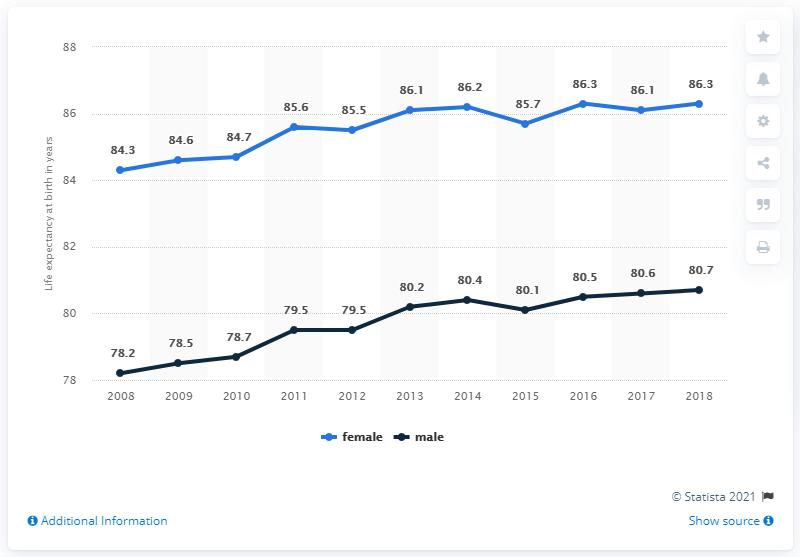
引用:Fuyu-8B: A Multimodal Architecture for AI Agents
質問:“What is the highest life expectancy at birth of males?”
(和訳:男性の平均余命のうち、最高のものは?)
Fuyu-8Bの回答
The life expectancy at birth of males in 2018 is 80.7
(和訳:2018年の男性の平均余命は80.7歳である。)Fuyu-8Bは見事にグラフを読み取って、的確な答えを教えてくれます。
ちなみにより複雑かつ専門的な図式でも、回答が可能です。以下のとおり、生き物の相関図をFuyu-8Bに見せて質問してみると……

引用:Fuyu-8B: A Multimodal Architecture for AI Agents
質問:“If in the food web shown in the diagram, Douglas fir tree needles are absent, which organism would starve?”
(和訳:図のような食物網の中で、ダグラスモミ=太枠・図中Cの木の葉がないとしたら、どの生物が飢餓に陥るだろうか?)
Fuyu-8Bの回答
Red tree vole
(和訳:アカネズミ=図中M)Fuyu-8Bは矢印の向かう先が捕食者であることを理解して、答えを返してくれていますね。
以上のとおりFuyu-8Bは、素の状態でも十分に高精度なのです。
実際にファインチューニングなしのFuyu-8Bと競合のマルチモーダルAIとで、性能を比較した結果も出ています。以下の表がその結果、4種類の画像識別テストのスコアです。
| 画像識別テスト | Fuyu-8B | Fuyu-Medium | LLaVA 1.5 (13.5B) | QWEN-VL (10B) | PALI-X (55B) | PALM-e-12B | PALM-e-562B |
|---|---|---|---|---|---|---|---|
| VQAv2 | 74.2 | 77.4 | 80 | 79.5 | 86.1 | 76.2 | 80.0 |
| OKVQA | 60.6 | 63.1 | n/a | 58.6 | 66.1 | 55.5 | 66.1 |
| COCO Captions | 141 | 138 | n/a | n/a | 149 | 135 | 138 |
| AI2D | 64.5 | 73.7 | n/a | 62.3 | 81.2 | n/a | n/a |
このようにFuyu-8Bは、同社の中型モデル「Fuyu-Medium」や競合他社の大型モデルと比べても、遜色のないスコアを叩き出しています。
とくにパラメーター数にして70倍大きい、Googleの「PALM-e-562B」に肉薄する結果が残せているのは驚きですね。
そんな期待のマルチモーダルAI・Fuyu-8Bの使い方を、次の見出しでみていきましょう。
参考記事:Fuyu-8B: A Multimodal Architecture for AI Agents

Fuyu-8Bの使い方
Fuyu-8BはHugging Faceにて無料配布されています。まずは以下の注意書きをご確認ください。
用途の制限:Fuyu-8Bは研究目的でのみ使用できます。バニラのモデルであるため、望ましくない出力を制限したいのであれば別途、後処理の追加やサンプリング手法の選択が必要です。
苦手分野:Fuyu-8Bは現実世界での出来事や実在の人物を正しく識別するための訓練を受けていません。
免責事項:顔や人物全般が正しく生成されないこともあります。また社会的偏見を含んだ回答が生成されうる点にもご留意ください。
モデル一式の読み込ませ方
Fuyu-8Bをロードするには、Pythonの開発環境とモデルを使うためのライブラリTransformers、そして画像処理ライブラリPillow(PIL)が必要です。
一式が用意できたら、あとは以下のソースコードを実行するだけでFuyu-8Bが使えます。
from transformers import FuyuForCausalLM, AutoTokenizer, FuyuProcessor, FuyuImageProcessor
from PIL import Image
#モデルとトークナイザとプロセッサの読み込み
pretrained_path = "adept/fuyu-8b"
tokenizer = AutoTokenizer.from_pretrained(pretrained_path)
image_processor = FuyuImageProcessor()
processor = FuyuProcessor(image_processor=image_processor, tokenizer=tokenizer)
model = FuyuForCausalLM.from_pretrained(pretrained_path, device_map="cuda:0")次の見出しでFuyu-8Bの動かし方もみておきましょう!
質問の方法と例
Fuyu-8Bに向けた質問とその回答の例を3つ示します。以下のソースコードをご覧ください。
【質問・回答の例1】
#プロンプト「coco-styleのキャプションを書いて」とバスの画像を提示
text_prompt = "Generate a coco-style caption.\n"
image_path = "bus.png"
# https://huggingface.co/adept-hf-collab/fuyu-8b/blob/main/bus.png
image_pil = Image.open(image_path)
model_inputs = processor(text=text_prompt, images=[image_pil], device="cuda:0")
for k, v in model_inputs.items():
model_inputs[k] = v.to("cuda:0")
generation_output = model.generate(**model_inputs, max_new_tokens=7)
generation_text = processor.batch_decode(generation_output[:, -7:], skip_special_tokens=True)
#結果の表示
assert generation_text == ['A bus parked on the side of a road.']【質問・回答の例2】
#プロンプト「バスは何色ですか?」とバスの画像を提示
text_prompt = "What color is the bus?\n"
image_path = "bus.png"
#画像URL: https://huggingface.co/adept-hf-collab/fuyu-8b/blob/main/bus.png
image_pil = Image.open(image_path)
model_inputs = processor(text=text_prompt, images=[image_pil], device="cuda:0")
for k, v in model_inputs.items():
model_inputs[k] = v.to("cuda:0")
generation_output = model.generate(**model_inputs, max_new_tokens=6)
generation_text = processor.batch_decode(generation_output[:, -6:], skip_special_tokens=True)
#結果の表示
assert generation_text == ["The bus is blue.\n"]【質問・回答の例3】
#プロンプト「男性の平均余命のうち、最高のものは?」とグラフを提示
text_prompt = "What is the highest life expectancy at birth of male?\n"
image_path = "chart.png"
#画像URL:https://huggingface.co/adept-hf-collab/fuyu-8b/blob/main/chart.png
image_pil = Image.open(image_path)
model_inputs = processor(text=text_prompt, images=[image_pil], device="cuda:0")
for k, v in model_inputs.items():
model_inputs[k] = v.to("cuda:0")
generation_output = model.generate(**model_inputs, max_new_tokens=16)
generation_text = processor.batch_decode(generation_output[:, -16:], skip_special_tokens=True)
#結果の表示
assert generation_text == ["The life expectancy at birth of males in 2018 is 80.7.\n"]Fuyu-8Bに質問する際にはコツがあって、プロンプトの終わりに\nを入れると質問への理解度が上がるそうです。
また回答時にはしばしば、Fuyu-8B独自のトークンが出力されます。具体的には以下の3つが、Fuyu-8B独自のものです。
|SPEAKER|:画像断片を埋め込むための空欄を示すトークン
|NEWLINE|: 画像断片の改行を意味するトークン
\x04:回答開始を意味するトークン
次からは実際にFuyu-8Bを動かしてみて、その性能を体感していきます。
ちなみにFuyu-8Bと競合するマルチモーダルAI・LLaVA 1.5については、以下の記事が詳しく解説しております。
→【LLaVA 1.5】オープンソース版GPT4-Vの使い方~比較レビューまで
Fuyu-8Bを実際に使ってみた
2~3日以内に、更新します!
ブックマークをしてお待ちください。
Fuyu-8Bの推しポイントである幅広い画像への対応は本当なのか?
2~3日以内に、更新します!
ブックマークをしてお待ちください。
まとめ
当記事では小型ながら高精度なマルチモーダルAI・Fuyu-8Bについて紹介してきました。Fuyu-8Bの強みをもう一度、以下に示します。
- モデルのしくみ&学習の手順がシンプル
- 画像の専門性や画質を問わず処理が可能
- 高速回答が可能
Fuyu-8Bでは入力のしくみを工夫することで、以上の強みを実現しています。
画像を小分けにして文字列のように入力していくのがポイントで、高画質の画像であっても長文のように難なく処理ができてしまうのです。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

