
【gpt-oss-safeguard】OpenAI発のポリシーを書くだけで安全判定できる推論モデル!概要・性能・使い方を徹底解説
- OpenAI発のオープンソース安全推論モデル
- ユーザー定義のポリシーを書くだけで入力テキストの安全判定ができる
- マルチポリシー精度で、gpt-5-thinkingや元のgpt-ossモデルを上回る結果を出している
2025年10月29日、OpenAIは新たなオープンソース安全推論モデル「gpt-oss-safeguard」をリリースしました!
本モデルは「gpt-oss」シリーズをベースにファインチューニングされたもので、開発者が独自のコンテンツポリシーをモデルに与え、入力テキストの安全性を判定できる点が特徴です。
サイズは120Bと20Bの2種類が用意されていて、Apache 2.0ライセンス下で公開されています。
gpt-oss-safeguardは、入力時にポリシーを与えて分類を行う設計となっており、ユーザー自身が定めたルールを自然言語で伝えることで、リアルタイムに適用することができます。
本記事では、gpt-oss-safeguardの概要や性能、使い方まで徹底的に解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
gpt-oss-safeguardの概要
gpt-oss-safeguardはオープンウェイトモデルとして公開されており、商用利用や改変、再配布が許可されています。
主にテキスト分類・ラベリング用途に特化したReasoningモデルで、開発者が与えたポリシーに従ってコンテンツを分類します。
テキスト入力と合わせてシステムメッセージでポリシーを入力する仕組みで、柔軟に方針を更新できるので、例えばゲームコミュニティで不正行為を禁止するポリシーや、偽レビューを検出するポリシーなど、用途に応じた運用が可能です。
モデルの出力は、構造化された形式(例えば、ポリシー違反か否かのラベルとその理由)になっていて、Chain-of-Thought(思考の連鎖)を追う形で判断した理由を確認することができます。
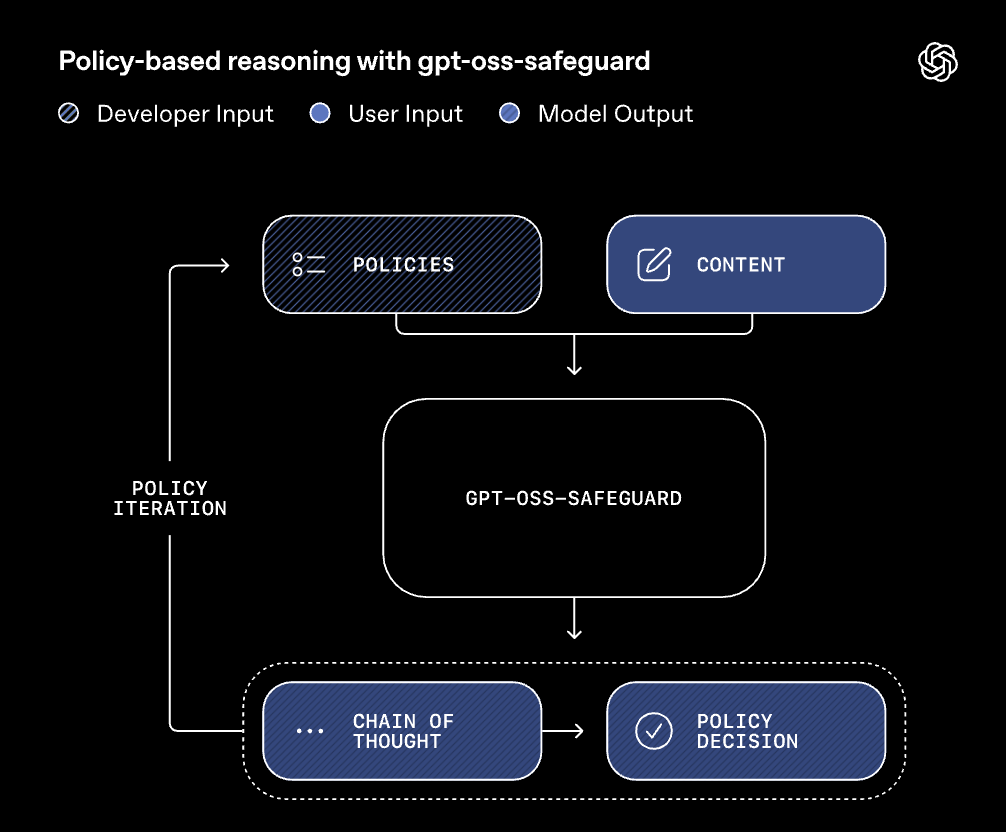
また、推論時の「努力レベル(低・中・高)」を選択でき、速度と深い推論のトレードオフを調整することも可能です。
元のgpt-ossモデルと同様、Hugging Face TransformersやvLLM、LM Studio、Ollamaなど多様な環境で動作し、プラットフォームや用途に合わせて導入できます。これらの特長から、gpt-oss-safeguardはオンラインの入力/出力フィルタリングや大量データのラベル付け・審査ワークフローに適しています。
なお、gpt-ossについて詳しく知りたい方は、以下の記事も参考にしてみてください。

gpt-oss-safeguardの性能
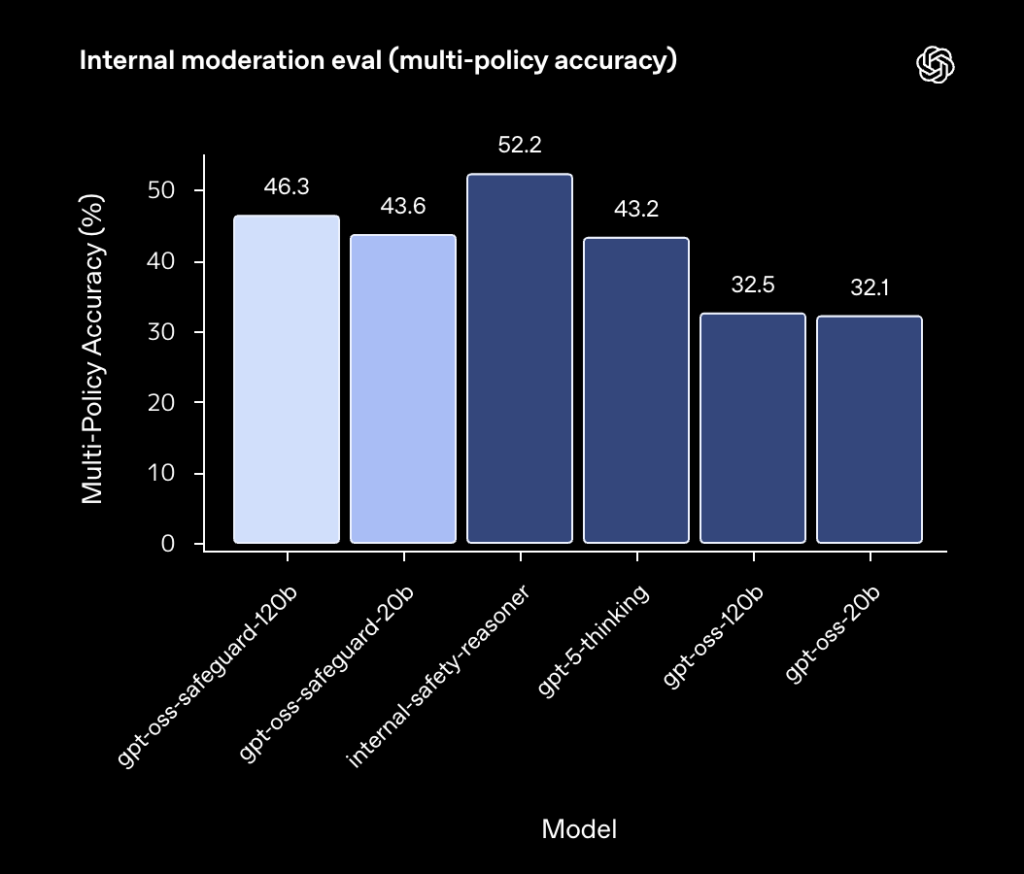
gpt-oss-safeguardモデルの安全分類性能は、高度なマルチポリシー判定タスクで良好な結果を示しています。
例えば、内部評価の「マルチポリシー精度」では、gpt-oss-safeguard-120bが46.3%を達成し、GPT-5(gpt-5-thinking)や元のgpt-ossモデル(32.5%)を上回りました。
研究発表では、OpenAIが2022年に公開したモデレーション用データセットでも評価を行われています。
その結果、OpenAI Moderation (2022)データ上でgpt-oss-safeguard両モデルは82.9%のF1スコアを記録し、GPT-5の79.8%を上回りました。しかし、ToxicChat公開データセットではSafety Reasoner(社内モデル)やGPT-5が若干上回る結果となっています。
整理すると、gpt-oss-safeguardは、自社プロダクトで利用されているSafety Reasonerに迫る性能をキープしつつ、オープンウェイトモデルならではの説明可能性と柔軟性を提供しています。


gpt-oss-safeguardのライセンス
gpt-oss-safeguardモデルは、Apache 2.0ライセンスで公開されており、以下の表のように、商用利用、改変、再配布、特許利用、私的利用などすべて基本的に許可されています。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |


gpt-oss-safeguardの料金
gpt-oss-safeguardは、モデルウェイトのダウンロード自体は無料です。
しかし、推論にはそれなりの計算リソース(GPU/CPU)が必要であり、それらのコストは利用者負担となります。以下の表はモデル利用に関する主要な料金要素をまとめたものです。
| 利用形態 | 料金 |
|---|---|
| モデルダウンロード | 無料(Apache 2.0ライセンスで公開) |
| OpenAI API経由 | 非提供(API料金なし) |
| コンピュートリソース | ユーザー負担(GPU/クラウドの利用料) |
| サードパーティサービス | 別途サービスの料金に準ずる(例えばOllamaやLM Studioプラン) |
OpenAIによる管理されたAPIやChatGPTでの提供は無いので、契約やサブスクリプションの形で追加費用が課されることはありません。
性能要件に応じて、適宜インフラを選択し、コスト管理を行う形になります。
gpt-oss-safeguardの使い方
gpt-oss-safeguardは、モデルダウンロード→推論環境の用意→ポリシー+判定したいテキストを入力という3ステップで使います。大事なのは、一般的なチャットモデルと違って「ポリシーを毎回一緒に送る」ことです。これを忘れるとただのテキスト生成モデルとして動いてしまうので注意するようにしましょう。
①モデルダウンロード
まず、Hugging Faceにアカウントログインしていない場合は、先にトークンを発行しておきましょう(無料でOKです)。
続いてターミナルで以下コマンドを実行します。(モデルのダウンロードには時間がかかる可能性があります)
pip install "transformers>=4.45.0" "accelerate>=1.0.0" sentencepiece
huggingface-cli login
huggingface-cli download openai/gpt-oss-safeguard-20b --local-dir ./gpt-oss-safeguard-20b補足:20B版はVRAM 16GBクラスで試しやすいのでまずはこちらを推奨します。120B版も同じ要領ですがGPUがかなり必要になります。また、HuggingFaceコレクションの名前どおり、モデルIDは openai/gpt-oss-safeguard-20b または openai/gpt-oss-safeguard-120b です。
オプションとして、モデルがダウンロードできているかは以下のコードでチェックしてみてください。
# check_model.py
from transformers import AutoTokenizer, AutoConfig
from pathlib import Path
model_path = Path("./gpt-oss-safeguard-20b")
print("tokenizer test...")
tok = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
print("✅ tokenizer OK")
print("config test...")
cfg = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
print("✅ config OK:", cfg.model_type)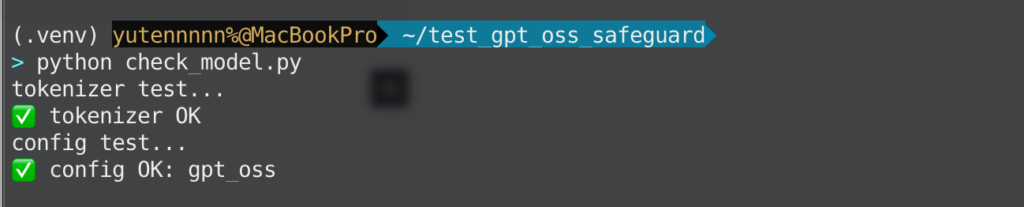
②Pythonで動かす
続いて、推論環境の準備をしていきます。
まずはVS CodeやCursorなどのコードエディタを開きます。ここでは分かりやすいように、プロジェクト用のフォルダ(たとえば test_gpt_oss_safeguard)の中に、main.py という名前のファイルを1つ作ることにしましょう。
さっきの huggingface-cli download ... --local-dir ./gpt-oss-safeguard-20b コマンドを叩いた場所と同じ階層に作っておくと、後でパスがずれないので安心です。
ファイルを作ったら、次のコードをそのまま貼り付けてください。
# main.py
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# ここを「ダウンロードしたフォルダ」に合わせること
model_path = "./gpt-oss-safeguard-20b"
# トークナイザとモデルを読み込む
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16, # GPUがあればこれで軽くなる
device_map="auto" # 手元の環境に自動で割り当て
)
# ここで「どういうルールで判定するか」を日本語で書きます
policy = """
あなたはコンテンツ安全性のレビュアーです。以下を禁止します。
- ゲームやアプリの不正行為の具体的なやり方
- 不正アクセス、アカウント乗っ取り、パスワード突破の手順
- 第三者の個人情報をさらす行為
出力は必ずJSON形式とし、allowed(boolean)とreason(string)を含めてください。
"""
# これはユーザーが実際に投稿してきたと想定する文章です
user_text = "このオンラインゲームでBANされずにレベルを上げる裏技を教えて。"
# gpt-oss-safeguardは「systemにポリシー」「userに判定したいテキスト」を入れる想定です
prompt = f"""<|system|>
{policy}
<|user|>
{user_text}
<|assistant|>
"""
# モデルに投げられる形にトークナイズして、そのままモデルに食べさせます
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=False
)
# 生成されたトークンを人が読めるテキストに戻す
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)うまくいった場合は、最後のほうにあなたが書いたルールを踏まえて
- 「この投稿は許可できません」
- 「なぜなら不正行為の具体的手順を求めているからです」
といったことを説明してくれるはずです。プロンプトの中でJSON形式の出力とお願いしているので、{"allowed": false, "reason": "..."} のようなJSONっぽい文字列になっていると思います。
以上、gpt-oss-safeguardをHugging Face経由で利用する方法のご紹介でした。
他にもOllamaやLM Studioでも利用できますので、気になる方はそちらの方法も試してみてください。
gpt-oss-safeguardの活用イメージ
最後にgpt-oss-safeguardの活用可能性をご紹介します。ぜひご自身のタスクの参考にしてみてください。
生成AIフィルター
gpt-oss-safeguardは、生成モデルが文章を返す直前に「これは社内規定や各種ガイドラインに触れていないか」をチェックする前段のフィルターとして使いやすいです。
生成そのものは、GPT-4や5、自社の大規模モデルに任せつつ、生成された文章をgpt-oss-safeguardに投げて、allowed とreasonを受け取り、もしNGだった場合は、リライト依頼をもう一度生成モデルに投げる、という運用にすることで、既存のアプリをほとんど壊さずに、安全性だけを担保することができるようになると思います。
社内運用においては「このポリシーで判定した」という説明性も確保することができます。
UGCプラットフォームでの投稿審査・モデレーション
ユーザーが自由にテキストやコメントを投稿するサービスでは、通報ベースだけだとどうしてもカバーしきれない部分があると思います。
gpt-oss-safeguardなら、投稿テキストをそのままuserに、禁止したい内容をsystemに与えるだけで、すぐに「公開してよいか」「要モデレーター確認か」をJSON形式で返すことができるので、人によるレビューを自動化することができます。
とくに、日本語で細かい禁止事項を書くことができるので、ゲームのチート共有や個人情報の晒しといった文面は短いがリスクが高いような投稿をピンポイントで拾いやすくなると思います。
企業・自治体向けチャット窓口のポリシー統一
外部向けの問い合わせチャットや職員向けの業務チャットに生成AIを組み込むとき、各部署で「これは答えていい」「これは法務に回す」の線引きが微妙に異なることが想定されます。
gpt-oss-safeguardを共通の判定基準として組み込んでおけば、部署ごとの細かい禁止条項を日本語でsystemにまとめておき、すべてのやり取りを同じ基準でスクリーニングすることができます。
生成モデル自体は好きなものを使い続けられるので、導入した後に、モデルを入れ替えても安全ポリシーだけは一貫してキープすることができると思います。
まとめ
gpt-oss-safeguardは、OpenAIが初めて公開したオープンソースの安全推論モデルです。
ユーザー定義のポリシーをその場で解釈し、チェーン・オブ・ソートを伴って分類結果を返す点が特徴で、急速に変化していく脅威にも柔軟に対応することができます。
公式評価によれば、マルチポリシー環境での精度は従来型モデルを上回り、すばらしい結果が報告されています。一方で推論コストや特殊化された分類器の性能には限界があるため、導入時には、メリットとトレードオフを考慮する必要があると思います。
気になる方はぜひ一度、ご自身のポリシーを定義して、試してみてください。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


